Face Recognition Performance, Bias, and the Limits of Technical Fixes
Christopher Gatlin was arrested for a brutal assault he didn’t commit after AI Face Recognition Technology (FRT) said he matched the suspect. He spent 17 months behind bars, and clearing his name took two years. As of March 2026, there were at least nine documented U.S. wrongful arrests tied to face recognition misidentification, mostly involving Black people. From 2012 to 2020 Rite Aid customers, disproportionately in non-white neighborhoods, were flagged by FRT as shoplifters, confronted, and sometimes expelled, including the searching of an 11 year old girl, all on the basis of bad matches.
Errors made by FRT are one cause of these harms, and these systems are known to make more errors on certain populations, including Black people, women, East Asians, and older people. But the way these systems are used by humans is a key component of these errors. Christopher Gatlin was identified based on a grainy photo of a hooded, partially obscured face, which could not be expected to lead to reliable identification. Moreover, police arrested him despite a lack of corroborating evidence. Harms caused by Rite Aid were due in part to a decision to mainly deploy face recognition in disproportionately non-white communities, as well as a lack of proper user training and the use of poor quality photos.
At the same time, face recognition does provide real benefits. In controlled, cooperative settings such as unlocking phones, banking apps, or passport verification, modern systems can be highly accurate. NIST evaluations show dramatic improvement over time, with errors occurring about one time in 1,000, depending on conditions. Millions of Americans use face recognition daily for convenience and security.
In tasks involving uncontrolled settings with uncooperative subjects however, such as identifying people from surveillance images, accuracy is much lower and more difficult to measure. Law enforcement and child-protection organizations have still used face recognition to identify suspects, locate missing children, and support trafficking investigations, but the potential from harms from inaccurate results in high stakes settings is much greater. Furthermore, the effect of biased performance is magnified in these uncontrolled settings, in which the number of errors seems to be much greater for some subpopulations. This report focuses on the causes of this bias, its potential harms and possible steps to reduce these harms. The use of face recognition in mass surveillance obviously raises other serious potential concerns, but these are outside the scope of this report.
Harms from FRT result both from technical errors and flaws in the ways humans use these systems. This suggests two parallel strategies for reducing the negative effects of biased face recognition. One approach is to reduce the bias in face recognition systems directly. Bias can occur due to training FRT using biased datasets that do not accurately reflect the demographics of the overall population. This can be difficult to eliminate due to the massive scale of data used to train FRT, which makes it difficult to control or even understand the demographics of the data. But further efforts can be made to reduce demographic bias in the data. Numerous other external factors that are more difficult to control may also create biased performance. Consequently, in the near term it may be practical to reduce, but not to completely eliminate biased performance.
A complementary approach to reducing harms from biased face recognition is to ensure that FRT are used appropriately by human operators. This solution is much easier to implement in the near term than the previous technical solution. It is not sufficient, however, simply to ensure there is a human in the loop confirming the results of FRT, since often FRT are more accurate than humans, their errors occur on challenging cases, and people may be unable to correct these errors. Behavioral policy interventions range from research aimed at better measuring bias and understanding when FRT results are not trustworthy to clear standards for how human operators use and interpret the results of FRT and restricting the use of FRT when potential harms outweigh the benefits.
In this report we provide an overview of face recognition performance and differential performance between different demographic groups. We summarize results from the National Institute of Standards and Technology assessing performance of numerous commercial face recognition systems. And we provide an overview of potential policies to reduce harms from face recognition bias.
Acknowledgements
Our understanding of this topic has benefitted greatly from conversations with Kevin Bowyer, Leah Frazier, Patrick Grother, Anil Jain, Brendan Klare, Alice O’Toole, Jonathan Phillips, Jay Stanley, and Nathan Wessler. We also received insightful comments and suggestions from Clara Langevin and Caroline Siegal Singh. Any failure in understanding is due to the authors.
Contents
Introduction
Face Recognition Technology Has Caused Significant Harms
Improper development or use of face recognition technology (FRT) can lead to serious harms. One such example occurred in 2020 when Christopher Gatlin was arrested for a brutal assault he didn’t commit after a face recognition system proposed him as a possible match for the suspect. He spent 17 months behind bars, and clearing his name took two years. Porcha Woodruff, eight months pregnant, spent 11 hours in detention for a carjacking after another bad match, even though surveillance footage showed the suspect was not pregnant. As of March 2026, there are at least nine documented U.S. wrongful arrests tied to face recognition misidentification.
In another example of this dynamic, Rite Aid, a major pharmacy chain, deployed face recognition technology widely in stores to spot alleged serial shoplifters. Impacted customers, disproportionately in non-white neighborhoods, were flagged, confronted, and sometimes banned from stores, including searching an 11 year old girl, all on the basis of bad facial recognition matches. Federal regulators later banned the company from deploying facial recognition technology in stores for five years, noting higher false-positive rates in stores serving predominantly Black and Asian communities and improper pre-deployment safeguards (more details here).
These instances of incorrect matching and arrests have mostly involved non-white people. But, while errors may be more prevalent among these populations, as FRT use grows it can increasingly affect all people. For example, police recently released a white Tennessee grandmother who had been wrongly jailed for nearly six months based on FRT results. She was arrested while babysitting four children, accused of committing bank fraud in North Dakota, although she had never been there. Unable to pay her bills, she lost her home.

Figure 1. On the left is a surveillance photo taken at a crime scene. On the right is the image of Robert Williams that was incorrectly matched to this photo by an automatic face recognition system.
The harms described above were instigated by flawed matches produced by FRT—computational models that perform face recognition. However, these models always form part of a larger system in which humans apply FRT to some task. The failures were not just the product of a bad model, but of human failure to follow effective procedures. In many cases, face recognition searches are performed using low resolution images, with faces partially obscured. Figure 1 shows the surveillance photo used to identify Robert Williams, who was wrongly arrested for theft on the basis of this image. He later stated, “My daughters can’t unsee me being handcuffed and put into a police car.” In some cases, police have violated accepted practice with suggestive remarks that prompt witnesses to confirm the results of automatic face recognition technology. In the Rite Aid case, poor employee training, the use of low quality images, and many other deployment decisions contributed to a large number of mistaken identifications.
Face Recognition Technology is Increasingly Widely Used
Face recognition technology has become increasingly accurate and widely adopted. It is estimated that 131 million Americans use face recognition on a daily basis for applications such as unlocking their phones or banking apps, providing convenience and improving security. FRT usage is especially prevalent in applications in which the person being recognized cooperates with the system. In controlled, cooperative settings, face recognition systems have improved rapidly, with error rates roughly halving every two years in some evaluations. Under ideal conditions, top-performing systems may make a mistake only once in several hundred attempts.
Face recognition is also increasingly used by law enforcement agencies to identify uncooperative subjects, identify criminal suspects, and find missing children. Its use in surveillance is also growing. For example, Immigration and Customs Enforcement (ICE) is using FRT to identify people and determine their immigration status. In these applications, FRT often successfully identifies individuals, but their accuracy is not as high, and the potential for harmful errors increases. An incorrect match in this instance can potentially result in wrongful detention or deportation of American citizens. As face recognition use grows, so will its benefits and harms, making it an urgent matter to understand its properties, impact, and effective policy interventions.

Figure 2. Each column shows a pair of images of the same person. Experimental subjects find the images on the left easiest to match, while it is most difficult to determine that the images on the right come from the same individual.
Face Recognition Difficulty Varies Significantly
The difficulty of face recognition problems varies tremendously depending on the setting. Figure 1 has already shown a difficult operational setting, in which a poor quality surveillance image must be matched. A human examining these images has a hard time telling whether they are of the same person. Figure 2 shows that even when images are of good quality, it is not always easy to tell whether they come from the same person, due to changes in things like hairstyle.
What Do We Mean by Bias in Face Recognition?
Bias in face recognition has been the subject of significant public concern and extensive research over the past decade, particularly as these systems have been deployed in high-stakes settings such as law enforcement and surveillance. This report examines the nature, causes, and consequences of this bias, and in this introduction we begin with a brief discussion of what we mean by “bias”.
Face recognition is meant to solve a problem that has an objectively correct solution; do these two images come from the same person? We say the system displays bias against certain demographic groups if it makes more errors on these groups than on the general population. We will use the terms “bias” and “differential performance” interchangeably.
FRT have consistently shown worse performance on women than men and worse performance on Black people than on white people, and many FRT display worse performance on East Asian people than white Americans. One way that bias can occur is through training FRT models using unbalanced data that better represents some groups. When this occurs, bias can be mitigated by augmenting the training set to represent different groups more equally.
However, defining demographic subgroups exactly can be difficult, making it hard to balance data. Studies that compare performance on men and women generally ignore subtleties of gender identity. Groups of Black or white people used in studies certainly contain many individuals of mixed race and, for example, Black people in the United States might have a different distribution of traits than Black people from East Africa. Different studies sample demographic subgroups in different ways, and therefore may not be evaluating exactly the same questions.
Moreover, it is unclear how best to define demographic subgroups. For example, is it more fruitful to measure differential performance between white and Black people, or between light-skinned and dark-skinned people? Black people can differ from white people not just in skin tone but also in structural properties of their face. At this time, it is unclear which aspects of appearance account for differential performance and how this would align with all possible subgroups. Most studies have been limited to a few broad demographic categories and it is not known, for example, whether performance would differ between specific nationality groups within a similar region such as Vietnamese and Korean people.
Outline of the Rest of the Report
This article aims to provide necessary background to assess the trajectory and risks of bias in face recognition technology. We do not address other important concerns about FRT, such as maintenance of privacy and the use of FRT in mass surveillance.
In the next section we will briefly describe how face recognition systems work. We will then discuss the world-wide scope of face recognition. Next we summarize the accuracy of FRT and how this has progressed. We then discuss the nature of bias in FRT, and consider the causes of this bias. Next we consider FRT as part of a socio-technical system, and the impact of human users on FRT harms. Finally, we suggest possible policy interventions to reduce these harms.
This report makes the following points:
1. Improvements in accuracy have not eliminated bias.
Face recognition systems have become significantly more accurate in recent years, but they continue to exhibit differential performance across demographic groups.
2. Bias is difficult to measure and difficult to fully eliminate.
In real-world, uncontrolled settings, bias is harder to quantify and may be larger than benchmark results suggest. While technical interventions can reduce disparities, there is no simple or complete solution.
3. Harms arise from both technical errors and how systems are used.
Errors in face recognition can lead to significant harms, including wrongful arrests and other adverse outcomes. These harms are often amplified by deployment decisions, such as where systems are used and how results are interpreted.
4. Face recognition should be understood as a sociotechnical system.
Bias and harm arise not only from the underlying models, but also from human judgment and organizational practices. Inappropriate use of face recognition results can be more significant than technical error.
5. Policy interventions can reduce harms even without perfect technical solutions.
Effective policies include improving transparency and evaluation, supporting research on real-world performance. Furthermore, just having humans check the results of FRT is not sufficient to avoid errors; this requires establishing clear, detailed protocols governing when and how face recognition may be used.
6. Governance of use is as important as improving the technology.
Auditing data and system outputs, developing tools that signal when results are unreliable, and enforcing strict use protocols can significantly reduce the risk that errors lead to harmful outcomes.
Glossary
How Face Recognition Works
Face recognition is based on machine learning, and highly dependent on the use of large-scale data sets. This data is difficult to carefully control or characterize.
Face Recognition refers to the process of automatically identifying a person from a photo. It is divided into two tasks. In verification (or one-to-one matching), two images of faces are compared to provide a yes/no answer to the question of whether they come from the same person. This is used, for example, in border control, when a live image of someone may be compared to their passport photo. In identification (or one-to-many matching), a single probe face image is compared to a potentially large gallery of images to determine which, if any faces in the gallery match the probe image. The gallery might contain, for example, mug shot images of people who have been arrested, driver’s license photos, images of people who have been barred from access to casinos, or a large collection of images scraped from the internet. A system performing identification might declare that it finds no match, return a single match, or return a potentially large collection of images that might resemble the probe image. In the latter case it is expected that these potential matches will be assessed by the user to identify valid matches. FRT may also return a confidence level about the correctness for each match, although these may not correspond to the true probability that the match is right.
A Brief History of Face Recognition
The first fully automatic face recognition system was developed 50 years ago as the subject of the PhD thesis of Takeo Kanade, who went on to become one of the pioneers in the field of computer vision. It identified landmarks on the face, such as the corner of the mouth, and used their position to compare images. Early methods like this, based on face geometry, had limited effectiveness. Scientists began to develop more useful and accurate face recognition systems through the growing use of machine learning, beginning in the late 1990s. These methods are trained with numerous face images, called a training set, to automatically extract representations of faces that can be used to compare them more robustly.
Progress accelerated rapidly as researchers began to appreciate the power of using an approach known as neural networks, which allowed them to leverage massive datasets of faces to “teach” the computer how to recognize new faces. While neural networks were used by FRT by the late ’90s, their use became dominant in the mid-2010s after further breakthroughs in machine learning with large neural networks, a technique known as deep learning. Since the mid-2010s, improvements in model architectures, training methods, and data scale have driven substantial gains in measured accuracy, especially on standardized benchmarks. At the same time, these advances have enabled rapid adoption of face recognition across a range of applications, from smartphone authentication to large-scale identification systems used by governments and private firms, even as performance in real-world settings remains highly dependent on context.
How Face Recognition Models Are Trained
To perform accurately, an FRT must be able to determine that two images of the same person are similar, even if the images are taken at different times, from different viewpoints, under different lighting conditions. This is done by training the machine learning model to extract a representation that captures facial properties that can distinguish one person from another, but that are not significantly affected by viewing conditions or even some aging. The similarity between two faces can be given a numerical score that represents the degree of difference between the representation of each face.
In its simplest form, training occurs by incrementally adjusting the parameters of a neural network. In most current publicly available systems these parameters consist of tens of millions of numbers that control the network’s behavior. If it is shown two images of the same person, the parameters are adjusted to increase the similarity score. If the images are of two different people, parameters are changed to lower the score. Once the model is trained, if two images produce a similarity score above a chosen number, known as the cutoff, the system declares the two images to be the same person; if it falls below that cutoff, the system says they are different.
Once the model has been trained, it can perform identification using a gallery of faces by comparing a representation of the probe to representations of the gallery images. That is, it can verify or identify images of people who were not in the training set, because it has learned a general representation that should apply to any faces.
The large data sets used in training are typically scraped from the internet. For example, one influential early data set, Labeled Faces in the Wild, made use of face images detected in Yahoo! news stories, with identifying captions. A number of large scale datasets containing millions of images have been developed using photos of celebrities available on the internet. Some companies, such as Meta and Google have made use of internal data that users have uploaded and labeled; these training data sets may contain more than 100 million images. Clearview, a face recognition company, claims to use data sets of more than 70 billion face images scraped from the internet. Given the high cost and diminishing returns of training with so many images it is unlikely that all of these images are used for training, and this large corpus is more likely to be used to form the gallery.
Academic FRT generally train on datasets of images of public figures, such as the MS-Celeb-1M dataset, which contains ten million images of about 100,000 individuals. These massive datasets capture how a person’s appearance can vary with age, lighting, viewpoint, expression, and other conditions, which helps improve accuracy of systems trained on the datasets. Commercial systems do not generally provide details of their training sets, but it is expected that they include similarly large sets of images scraped from the internet, or provided by users, as in the case of Google and Meta. However, because these data sets are assembled at enormous scale—often from uncontrolled sources—they are difficult to audit, regulate, or correct when they embed systematic biases.
Face Recognition in Use Today
Face recognition use is increasing rapidly, becoming more prevalent in numerous high-stakes applications.
The global face recognition market was almost nine billion dollars in 2025, with projected growth to over 30 billion by 2034. Over a third of this market is in the U.S., but there is wide adoption of FRT around the world. One of the primary applications of face recognition is to efficiently and reliably identify people. This can make access to financial systems more secure, potentially preventing identity theft. It can also make hospital admissions quicker and more accurate, and speed up passport verification. In these applications, a human subject opts-in to using the FRT, cooperating to allow consistency in viewpoint, avoiding unusual facial expressions, and enabling controlled lighting. This leads to highly accurate systems. In many cases, such as using FRT to unlock cell phones, users opt-in to the technology for added convenience and device security. When entering the country, U.S. citizens may opt-in to face recognition systems, and their photos are deleted after 12 hours, while non-citizens are required to participate, with photos retained for 75 years.
Face recognition is also widely used in surveillance and law enforcement. Ten percent of U.S. police departments use FRT. The NYPD made 2,878 arrests resulting from FRT in the first five years of its use. The Metropolitan Police in London report 100 arrests using FRT in conjunction with mounted security cameras, including a suspect accused of kidnapping. Police in New Delhi used FRT to identify almost 3,000 missing children, and FRT has been used to identify refugee children who have been separated from their family. The National Center for Missing & Exploited Children (NCMEC) has used a tool called Spotlight, which makes use of FRT, to identify children who are victims of sex trafficking. In 2023, the FBI worked with NCMEC to identify or arrest 68 suspects of trafficking. A large number of retail stores use FRT to track customers to understand traffic patterns, and despite the Rite Aid case, retailers such as Wegmans still use FRT to spot accused shoplifters. Immigration and Customs Enforcement (ICE) is using FRT to identify people and determine their immigration status.
Face recognition has been widely used for surveillance of the Uyghur population by the Chinese government., FRT are used by the Israeli government to track and surveil Palestinians.
These applications of face recognition can solve crimes, enhance security and make access more convenient, but also raise troubling concerns about mass surveillance, repression of civil liberties, and high-stakes errors which materially harm people. In surveillance and criminal investigations, subjects are not cooperative, and probe images used are often of poor quality, as illustrated in Figure 1, which produces much higher error rates. An awareness of mass surveillance can also have a chilling effect on people’s ability and willingness to participate in Constitutionally protected activities such as protest or dissent.
As face recognition has grown more practical, a large number of companies have developed and marketed FRT. This includes large tech companies such as Amazon, Microsoft, Toshiba, NEC and Apple, and smaller companies that focus more narrowly on face recognition, biometrics and security, such as Clearview, Idemia, and Rank One Computing. Clearview is one of the most widely used by federal and local law enforcement in the U.S.
Early in the development of face recognition technology, the best performing systems were produced by academics and used openly available architectures and data. However, with its rapid commercial growth, state of the art FRT are generally developed by companies that provide little transparency about how they work or what data they use. As we will discuss in more detail, the National Institute of Standards and Technology evaluates the performance of some of these systems, but this evaluation is voluntary and not all companies participate.
Face Recognition Performance Across Different Conditions
Face recognition performance has improved rapidly, but recognition can still be quite difficult in many settings.
Two types of errors can occur in face recognition. With false positives, a FRT incorrectly states that two images come from the same individual. With false negatives, the system incorrectly states that two images do not come from the same individual. The cutoff is what determines the balance between false positives and false negatives. Tightening it makes the system more cautious about declaring a match (reducing false positives) but also more likely to miss legitimate matches (increasing false negatives).

Figure 3. The ACLU found that Amazon’s face recognition system matched 28 members of Congress to mugshots of other people.
The significance of this cutoff is illustrated well by the American Civil Liberty Union’s (ACLU’s) evaluation of Amazon’s FR system, “Rekognition” and the subsequent controversy. The ACLU reported that they had tested Rekognition, and that it incorrectly identified 28 members of Congress with people who had committed crimes (Figure 3). A significantly disproportionate number of these false matches were people of color. Amazon responded by arguing that although the ACLU had used the default cutoff, or confidence threshold, of 80% for Rekognition, this was more appropriate for finding celebrities on social media, and that their documentation recommended a much more stringent cutoff of 99% for use in high stakes applications such as law enforcement. Amazon also pointed out that the bias in the results may have been due to bias in the gallery of images used by the ACLU. If the ACLU compared images to a gallery that disproportionately contained people of color it would be more likely to produce false matches for people of color in congress. The ACLU replied by stressing the dangers of a system that was inaccurate with default thresholds and a lack of guidance for the system’s use.
One lesson from the Amazon Rekognition controversy is that the potential harms of an FRT depend not just on its technical accuracy but also on how users apply these systems. It also provides some indication that Rekognition was more prone to false positive errors when applied to people of color, at least at one significant cutoff threshold.

Figure 4. Three images of a researcher at the National Institute of Standards and Technology. The left image simulates a passport or similar photo, the middle image simulates images that might be taken while going through immigration, the right image simulates an image taken by a kiosk.

Figure 5. Two pairs of images, each pair shows the same person under identical imaging conditions except for a change in lighting (images from the Multi-PIE dataset).
Challenges in Real-World Face Recognition
The most rigorous experiments measuring face recognition accuracy are conducted under tightly controlled conditions. As a result, reported performance often overstates how systems perform in real-world settings, where error rates can be much higher.
The difficulty of face recognition tasks can vary widely. Frequently, identification is performed by performing verification between the probe image and all gallery images. Identification becomes more difficult as the gallery size grows and the number of opportunities for false positive matches increases. The difficulty of face recognition tasks also depends very much on the conditions under which images were taken. For example, in border control, the subject can be required to face the camera with their face fully visible, lighting can be controlled, and camera quality can be ensured.
Figure 4 shows that even images taken at a kiosk can be much harder to match, due, for example, to changes in viewpoint. Figure 5 illustrates the effect that a change of lighting can have on the difficulty of matching faces. As previously shown in Figure 1, when images come from surveillance cameras, the subject may not be facing the camera, they may not be close to the camera, so image resolution can be low, and their hair or hand or another object may obscure part of the face. Identification with poor imaging conditions may have many orders of magnitude more errors than verification under tightly controlled conditions.
By all metrics, there seems to be little doubt that face recognition accuracy has been improving rapidly. The National Institute of Standards and Technology (NIST) Face Recognition Vendor Test (FRVT) evaluations illustrate this increase (most recent results here). NIST evaluates verification performance on two high quality images of frontal facing individuals. From 2020 to 2025 the error rate fell by a factor of three. (They set a threshold for matching to achieve a false positive rate of 0.003%, so about one false identification in 33,000 attempted matches. They then measure the false negative rate, the number of correct matches missed. The best performing system as of January 2025 achieved a false negative rate of 0.13%, a little more than one correct match missed in 800.) Similarly, the error rate on an identification task that matched a mug shot probe image to a large gallery of mugshots fell by a factor of 5 during the same period. (The best performing method, when using a threshold to produce a false positive identification rate of 0.3%, had a false negative error rate of 0.05%. This means that the system would falsely identify a probe image in the gallery (of 1,600,000 mugshots) one time in about 300, while missing a correct match about one time in 2,000.) Some results are shown in Figure 6, as of March 2025. Over a period of decades, NIST has found that errors have generally fallen by about a factor of two every two years. Under controlled conditions, FRT are now much more accurate. For example, on the best performer as of March 30, 2026, when performing verification on two mugshots, using a cutoff set to make a false positive match one time in a million, a false negative failure to find a match will occur one time in 500. This sharp increase in accuracy in a short period has happened alongside widespread adoption in applications like border control or unlocking a phone.
These experiments represent relatively ideal conditions. FRT in the real world may face much higher failure rates. This can occur due to more challenging imaging conditions, such as using a surveillance image as a probe, instead of a mugshot, or other factors such as changes in the subject’s appearance. For example, when the best performing system at mugshot identification is applied in a scenario in which the gallery contains visa images and the probe is taken from a kiosk, the error rate increases by a factor of about 18 with a false negative error about one time in 30 instead of one time in 500. This is a fairly typical increase, and still represents relatively idealized conditions compared to the most challenging ones.
Defining and Measuring Bias in Face Recognition
Face recognition performs with different levels of accuracy on different demographic groups. As face recognition becomes more accurate, this may limit the effects of this disparity in some applications, but it can still be quite significant in high-stakes applications.
Going back more than 30 years, researchers have observed different rates of accuracy in face recognition systems depending on demographic properties of the subject, including race, gender and age. For example, in 2011 a study showed that Western face recognition algorithms performed better on Caucasian faces than East Asian faces, while East Asian face recognition systems performed better on East Asian faces than Caucasian ones. In 2018, the influential Gender Shades paper examined differential performance not in face recognition, but in a related facial analysis problem of determining gender from a face, showing much poorer performance on images of dark skinned females than light skinned males.
Absolute vs. Relative Error
In considering differential performance, it is important to distinguish between absolute and relative differences in performance. We define the absolute difference in two error rates as the difference between the larger and smaller error. For example, if an FRT produces 2% error on male faces and 4% error on female faces, we would say that the absolute difference is 4% – 2% = 2%. We describe the relative error as the ratio between the larger and smaller value, which in this case would be 4%/2% = 2. As overall performance improves, the absolute error tends to decrease, while the relative error rate might or might not decrease. For example, if a new generation of FRT reduces error on male faces to 1% and reduces error on female faces to 2%, absolute error decreases from 2% to 1%, while relative error remains constant.
Whether absolute or relative error is more important depends on the operational considerations and use of the system. When performance is very high, absolute error will tend to shrink. If this translates into operational settings, then relative error may become unimportant. For example, if an FRT makes a mistake once in a billion queries on one population, and twice in a billion on another, errors for either population may be so rare that they are insignificant. In practice, the impact of absolute error also depends on how widely deployed a system is. As systems become more accurate, they may become more widely deployed, which can paradoxically result in more accurate systems producing more errors.
Even though current FRT achieve quite low error rates under ideal conditions, these error rates tend to grow much higher under more challenging conditions, and errors can be quite common. Although it is difficult to study error rates accurately under the most challenging conditions, high relative error under ideal conditions may predict relative error that is just as high or higher under challenging conditions that also have high absolute error. That is, while absolute error in operational contexts is of greatest importance, relative error in highly controlled conditions may predict high absolute error in less controlled conditions. Consequently, it is premature to think that FRT are so accurate that relative error is no longer important. A more nuanced view would hold that continuingly high relative error rates may be less important for some applications, such as unlocking phones, and still be quite important in other applications, such as criminal investigations.
NIST Experiments on Demographic Variation
Since 2019 NIST has performed extensive evaluations of demographic variations in performance on hundreds of face recognition systems. They have access to large collections of non-public images that they use to evaluate FRT submitted by companies. The large size and private nature of the dataset makes it especially unlikely that models are overfit to the data by, for example, selecting parameters that boost their performance on this particular data. NIST computes false negative rates using over a million pairs of images, comparing one high quality image of an individual to a medium quality image of the same person. False positive rates are computed using over a billion pairs of high quality images from different individuals. Image quality reflects applications such as passport checks at airports, but does not include more challenging problems such as police investigations using surveillance footage. All images come with demographic information, including the age, gender and country of origin of the subject. Country of origin is used as a proxy for race, focusing on countries that are less racially diverse, but this is not a perfect proxy.
NIST finds a relatively small demographic variation in false negative rates, in which a correct match is missed, and a much larger variation in false positive rates, in which an incorrect match is accepted. For example, the top performing FRT as of March 2025 produced 358 times as many false positives for West African females over 65 as for Eastern European males aged 35-50, with the false match rate increasing from about one in 15,000 to about one in 50. Among the top ten performing systems, the false positive rate for all West Africans was about 23 times higher, on average, than the rate for Eastern Europeans. The false positive rate for these performers on average is about 4.6 times higher for females than males, and about 2.9 times higher for people over 65 compared to people aged 20-35. The evaluations also show poorer performance on people from South or East Asia, relative to Eastern Europeans. Many additional studies have also found that FRT generally perform better on white people than people from other racial groups, and on males compared to females.
These studies do have important limitations. More narrowly defined groups (e.g. West African women over 65) will have less data, leading to noisy estimates, and when we take the ratio of two noisy estimates we amplify the noise. Also, images taken in different countries may differ in ways beyond the race of the subject, such as in the types of cameras or lighting used. Also, incorrect labels may have a significant effect on accuracy. If a visa photo is associated with the wrong name, this can lead to a false match, and these incorrect labels may be more prevalent in some countries than others. Finally, measures of bias may vary depending on the specific ways in which performance is measured. The chief scientist of a leading face recognition company has stated that in practice they find differential performance between racial groups of a factor of approximately 1.5, rather than the higher numbers found in NIST studies. (Brendan Klare, personal communication.)
Challenges in Measuring Bias in Face Recognition
There is decades of evidence of differential performance of face recognition between demographic groups, particularly affecting non-white people and females. However, these studies generally make use of relatively high quality images, and may not accurately reflect the degree of differential performance in challenging operational cases, such as the use of surveillance footage in criminal investigations or in identifying people on a watch list. This is due to the fact that it is quite difficult to accurately characterize and sample images from challenging environments. And while large scale photo collections with known identities and some demographic information exist, such as passport photos, we do not have large scale collections of photos taken in challenging conditions that have this information. While this problem is elusive, there is some evidence that differential performance increases with the difficulty of the recognition task.
Another limitation occurs because races are not well-defined biological categories but social constructs. It is not clear how to systematically divide a population into different races, especially in the case of multi-racial individuals. This is particularly challenging when images are scraped from the internet, and need to be labeled by race. Some studies have focused on skin darkness rather than race, but this is also difficult to determine accurately from photos due to the effect of unknown lighting conditions on apparent skin color. In spite of these limitations, there is a clear consensus among researchers that differences in FRT performance exist between racial groups.
An important question is how differential performance in face recognition is evolving over time. Is this a problem that was initially ignored, but is now being effectively addressed, or one that is recalcitrant? While there is no question that absolute differences in accuracy are shrinking over time, as FRT become more accurate, the behavior of relative differences is less clear. This is difficult to judge, since new test sets come out frequently, and experimental performance is generally measured over an ever changing landscape of conditions. Perhaps the most stable evaluation framework is NIST’s, which has consistently evaluated new FRT under the same conditions including systems developed from 2018 to 2026. Some of the top performing FRT have evolved, with multiple versions being released over this time period. When we examine these, we see that some have significantly reduced the amount of bias over time, while others have not, and have even seen increased bias. This suggests that it may be possible to reduce systematic bias through model design. More details can be found in the appendix.
Sources of Bias in Face Recognition Systems
Bias in face recognition systems arises from a combination of imbalanced training data, differences in image quality and gallery composition, and other technical and operational factors that are difficult to fully control or eliminate.
False negatives often arise when image quality is poor or facial features are obscured, while false positives are more likely when different individuals appear similar to the system, which can be exacerbated by limitations in training data or representation. For example, if we compare two images of the same person, and one of these images is blurry or has bad lighting or low resolution, the images may appear dissimilar due to these effects. FRT are trained to be somewhat robust to changes in viewing condition, but they are still likely to make errors when these changes are large. On the other hand, if a system is trained using few images of one demographic group, the system may not learn representations that distinguish between a wide range of appearances within that group. For example, if one trained an FRT using images of only one Black person, the system would likely learn to associate dark skin with that individual, and would not learn features that effectively distinguish between different Black people. This is an extreme example, but it is generally found that deep neural networks become more effective as the amount of relevant data increases.
We focus on false positive errors, as these show the greatest differences across demographic groups and are most closely associated with documented harms, such as wrongful arrests. In this section, we will discuss two key points. First, while it may be straightforward to improve demographic balance in datasets, completely eliminating demographic bias is complex and difficult. Second, while demographic bias in the data may be responsible for some bias in false positives, it is not necessarily the only source of these differences. Various research results present conflicting evidence of the importance of dataset bias in practice.
The Contribution of Dataset Bias
Face datasets collected in the last 15-20 years have generally consisted of images scraped from the internet. This enables the creation of large scale datasets that capture a wide range of variations in viewing conditions. These datasets often used well-known people with many online photos, without specific regard to accurately representing the distribution of people of different races or genders in the population as a whole. For example, an early and very influential dataset, Labeled Faces in the Wild (LFW), consisted of 77.5% images of men and 22.5% images of women. LFW was based on people who had appeared in Yahoo! news stories that were identified in captions, making it easier to build a large dataset of known people. However, these people were obviously not representative of the overall population.
Some more recent datasets pay closer attention to capturing the true distribution of people in the world. However, creating unbiased datasets can sometimes be a subtle and difficult problem. For example, the BUPT-Balancedface (BUPT) dataset was constructed to have equal numbers of images of Caucasian, Indian, Asian and African faces. However, subsequent analysis revealed that the Asian and Indian faces consistently appeared as a larger size in the dataset. So although the number of images was balanced, the viewing conditions of the images could still vary significantly. This discrepancy might, for example, lead to biased performance at test time.
The reason for systematic biases in datasets is often not well understood, but it is plausible that when scraping images from the internet, photos from different countries might follow different conventions, use different cameras, or differ in myriad other ways. Therefore, to judge whether a dataset is biased is not as simple as counting the number of images from each population.
A deeper difficulty is even defining what it means to have an unbiased dataset. BUPT represented four demographics equally. But it is unclear what should count as a racial category. For example, should Asian faces be counted as one category? Should Chinese and Japanese people be considered two separate racial categories? What about multiracial individuals? The concept of race is not biological, but a social construct that is not well defined. It is also problematic to correctly label the racial origins of large scale datasets, which may contain images of millions of people. It seems clear that paying attention to demographic diversity will produce less biased datasets than building datasets based on arbitrary selection of celebrities. However, it is also clear that creating completely unbiased datasets is an ill-defined problem. Even with a given definition of “unbiased” it remains very challenging and beyond current technology.
There is certainly strong evidence that dataset bias can produce differential performance, and bias can be reduced through improving the training data balance. It has been found that while Western face recognition algorithms perform better on Caucasian faces than on East Asian faces, algorithms developed in East Asia perform better on East Asian faces, a result that is likely due to dataset bias. After the Gender Shades paper demonstrated that Microsoft’s gender identification algorithm performed much more poorly on Black women than white men, Microsoft quickly improved performance dramatically on Black women by balancing its datasets.
Differential performance can also occur because of biases in the gallery data or probe data. When the gallery is formed from images scraped from the internet, the properties and number of these images may vary drastically from individual to individual, or even from group to group. It has been shown, for example, that if one group is more highly represented in the gallery, this will lead to more false positives among that group because there is greater potential for the gallery to contain faces similar to the probe. As another example, if one group, such as women, frequently have longer hair that covers more of their face in the probe image, this can also lead to higher error rates. Also, if a gallery image is of low quality, not showing a clear image of the face, it may be matched to a similar low quality probe image of a different person. Rite Aid’s use of low-quality images in its gallery is believed to have contributed to the large number of false matches it produced, which in turn led to customers—disproportionately in non-white neighborhoods—being wrongly flagged, confronted, and sometimes expelled from stores. When companies such as Clearview make use of billions of images scraped from the internet it is extremely challenging to balance these datasets or ensure uniformity in their quality.
Assessing dataset bias in commercial systems is complicated further by the fact that companies generally do not make their datasets publicly available or disclose many details about them. Moreover, NIST experiments on dataset bias do not make use of the galleries used by commercial systems. Therefore any bias due to galleries would not be detected.
Sources of Bias Beyond the Data
Other factors besides data may also significantly influence differential performance. Some experiments have shown that even balanced datasets do not produce equal performance on men and women, or between races, and that sometimes more biased datasets produce less biased and better results. Furthermore, demographic groups may have properties that make them easier or harder to recognize. For example, there may be greater variation in hairstyle in one gender than another, and males in different countries may have different trends in facial hair. If someone has an unusual beard, for example, this may make him easier to recognize, or harder to recognize if he shaves his beard. It is difficult to determine the effects on differential performance of social conventions affecting appearance. It has also been noted that darker skin may require different types of lighting to bring out the facial structure. This could result in more recognition errors for people with darker skin when lighting is not controlled.
In summary, it is clear that extreme dataset bias produces biased results. It is quite challenging to produce perfectly unbiased datasets, and less clear to what extent the differential performance observed in modern face recognition systems may be due to dataset bias, especially since these systems are built with proprietary data that is not open to public examination.
Reductions in Bias Over Time
From a policy perspective, perhaps the most important question is whether companies have the ability to produce less biased FRT. To address this question we examined NIST measurements of the performance of models produced by leading companies. NIST has assessed the degree of bias in multiple models produced over time by some companies, allowing us to see how their performance has evolved. Based on NIST reports, we find that some companies have significantly reduced the absolute and relative bias in their systems in two or three years after initial evaluation, while other companies have not reduced relative bias, and in some cases it has increased, even while absolute bias decreases due to improved overall accuracy. Details of this analysis may be found in the appendix.
These results suggest that companies are capable of reducing bias, although this is certainly not definitive. In a conversation with one of the authors, the chief scientist at a leading face recognition company confirmed that NIST evaluations have helped them identify certain variants of differential performance between racial groups, enabling them to take effective steps to proactively identify and reduce bias whenever the company becomes aware of it. (Brendan Klare, personal communication.)
The Human Factor: Face Recognition Systems as part of a Socio-Technical System
Many errors in face recognition are due not just to mistakes by the technology, but to the way in which people make use of it.
The preceding sections focused on the technical properties of face recognition systems. However, these systems do not operate in isolation. They are embedded in what researchers call a sociotechnical system, in which the technology interacts with human judgment and organizational practices. The real-world effects of face recognition therefore depend not only on technical FRT performance, but also on how human users interpret and act on its results. In practice, this interaction can create distinctive failure modes. For example, users may rely too heavily on algorithmic matches without considering other evidence or fail to appreciate how image quality and threshold choices affect reliability.
Limitations of Human Oversight
Some authors argue that these human factors can be structured to correct for technical weaknesses in face recognition systems. One commentator contends that: “it is stunningly easy to build protocols around face recognition that largely wash out the risk of discriminatory impacts…. A simple policy requiring additional confirmation before relying on algorithmic face matches would probably do the trick… one has to wonder why so few researchers who identify bias in artificial intelligence ever go on to ask whether the bias they’ve found could be controlled with such measures.”
However, empirical evidence suggests that this confidence in human oversight may be misplaced. First, FRT tends to make errors on difficult cases, in which humans also make errors. Studies show that humans are unable to identify many of the errors made by automatic systems. Furthermore, human performance on face recognition suffers from similar differential performance as machine learning systems. Dubbed the other-’race’ effect, it has long been known that humans are more accurate in recognizing faces from their own race than from others (it has been posited that this also stems from dataset bias, in that people encounter more individuals of their own race than of others). Some work indicates that current automated systems recognize faces more accurately than the typical person, and that in some cases, combining a less effective human judgement with an automatic system may actually lead to lower accuracy than simply using the results of the automatic system. Human judgements can in some cases be used to improve algorithmic accuracy but it may be difficult to determine when that is the case. In general, we cannot assume that human judgements will be accurate or that human oversight can be counted on to correct errors made by automatic systems.

Figure 7. Christopher Gaitlin, right, was identified using the security photo on the left.
User Errors
Consistent with these findings, many of the known cases of false arrests due to FRT errors involved questionable practices by investigators. Christopher Gatlin was arrested for the brutal assault of a security guard, after an FRT flagged him as a possible suspect, based on a low quality image (Figure 7). Police steered the security guard to identify Gatlin, in what they later admitted was improper behavior.
Robert Williams was arrested for burglary one year after the crime, based on applying FRT to a surveillance video. Lacking witnesses, police showed the surveillance video to an employee of the store’s insurance company, who identified Williams from a photo array, although the video was of poor quality and his face was obscured by a shadow (Figure 1). The police failed to take basic steps such as investigating Williams’ alibi. The police chief at the time, James Craig, said that “this was clearly sloppy, sloppy investigative work.” In other cases, police have shown a single suspect’s photo to a witness, violating best practices by being unduly suggestive. This led to an arrest despite the suspect’s convincing alibi.
In cases where FRT lead to false arrests, it seems that police may in fact give undue weight to the results of FRT, rather than catching their errors, an example of “automation bias”. In another case in which recommended procedures were not followed, police were unable to obtain face recognition results due to the low quality of the surveillance image. A detective felt that the surveillance image resembled the actor Woody Harrelson, and used a picture of him to search for matches, rather than the suspect’s photo.
Failures in the use of FRT occur not only in police investigations. In the Rite Aid case mentioned in the introduction, the FTC’s complaint highlighted not just algorithmic errors but significant governance failures in how the system was operated by store employees. The commission found that Rite Aid did not take reasonable steps to train or oversee store employees who were responsible for acting on match alerts, including failing to teach staff how to interpret alerts or warn them that false positives could occur. The company also failed to test or monitor the technology’s accuracy once deployed, enforce image-quality standards, or implement any procedure for tracking false positive alerts and employee responses. As a result, employees in hundreds of stores routinely followed, confronted, searched, or even called police on customers based solely on system alerts—actions taken without meaningful training on the system’s limitations or appropriate safeguards. These shortcomings in training, oversight, and procedural controls were central to the FTC’s determination that Rite Aid had failed to prevent foreseeable consumer harm from the technology’s use.
In summary, it may be difficult for humans to correct mistakes made by algorithms, and in some cases they may place undue confidence on FRT results that are questionable and based on low quality images. In many applications, such as drug stores that are looking for known shop lifters, the people making use of FRT may not be expert investigators or well trained in the appropriate use of these systems.
Policy Interventions to Address Bias in Face Recognition Systems
Many errors can be addressed by better understanding and regulation of the way in which the technology is used.
A wide variety of policy interventions are available to deal with potential harms caused by bias in FRT. These include research, transparency in documenting bias, voluntary or mandatory guidelines governing the use of face recognition, and outright bans on the use of face recognition in certain contexts. As noted above, FRT make positive contributions in law enforcement and other applications, and these positives must be weighed against potential harms in crafting policy. Numerous institutions have suggested policy changes to address bias in FRT, including a comprehensive set of proposals in a recent report from the National Academies.
Research
Federal agencies already support substantial research on face recognition. NIST conducts ongoing evaluations of performance and demographic disparities, and agencies such as the Office of the Director of National Intelligence (ODNI) and the Intelligence Advanced Research Projects Activity (IARPA) have funded foundational research in face recognition systems. However, important gaps remain, particularly in understanding how these systems perform under operational conditions and how human users interact with their outputs. Additional federal funding could expand independent research in these areas, either by strengthening NIST’s evaluation programs or by supporting academic and nonprofit research focused specifically on bias mitigation and real-world deployment risks.
Two research priorities are especially important. First, evaluation frameworks should better reflect real-world conditions. Current large-scale benchmarks often rely on relatively high-quality images, whereas many high-stakes uses—such as criminal investigations—depend on low-resolution or poorly lit surveillance images. While efforts such as the IARPA Janus Surveillance Video Benchmark (IJB-S) dataset have begun to address this issue, broader and more systematic testing under operational conditions would provide policymakers with a clearer understanding of real-world risk.
Second, research is needed to develop tools that help human operators interpret and appropriately limit their reliance on face recognition results. For example, systems could assess probe image quality, estimate the likelihood that a reliable match can be produced, and warn users when results are unlikely to be dependable. Such tools could reduce the risk that investigators or retail employees draw strong conclusions from low-quality, unreliable inputs.
Measure and Reduce Bias
A better understanding of the bias in FRT can inform the procurement decisions of potential customers and encourage companies to take steps to reduce bias. Transparency in bias can be promoted in a number of ways. NIST is already conducting regular and impactful evaluations of bias in FRT, which can be thought of as an application of the Common Task Method (such evaluations have long been common in the computer vision community). This can be continued and potentially expanded. Regulations or government procurement guidelines can be used to incentivize or require companies to participate in evaluations and make these results public. Since criminal investigations are conducted by the government, procurement guidelines are a strong potential lever in promoting transparency. In addition to transparency in performance, these approaches could also be used to promote transparency in the data used to train FR systems. Making training data public may raise significant privacy concerns, but the government could incentivize the release of information describing the data and the steps taken to enhance the demographic balance of these data sets.
Regulate Sociotechnical use of Face Recognition
If we view FR as part of a sociotechnical system, it makes sense also to govern the way in which face recognition is applied, not just the technical performance of the underlying algorithm. In practice, “responsible use” protocols need to specify who can run searches, what minimum image-quality standards apply, what form results can take, and what documentation and oversight are required. They should also define the permissible purposes for which searches may be conducted, restrict access to trained and certified personnel, require supervisory approval for high-stakes uses, and mandate that face recognition results be treated only as investigative leads rather than as dispositive evidence. Protocols can require minimum similarity thresholds below which no candidate match is returned, prohibit the use of face recognition on images that fall below objective quality metrics, and require contemporaneous documentation explaining why a search was initiated and how results were interpreted.
Additional safeguards could include audit trails of all searches and outcomes, periodic independent audits of performance and demographic disparities, disclosure requirements when face recognition contributed to an arrest or charging decision, and exclusionary consequences if required procedures are not followed. Agencies could also be required to collect and publish aggregate statistics on the number of searches conducted, the rate at which matches lead to arrests, and the frequency of erroneous identifications.
As an example of governance procedures, the FBI has established guidelines on the use of face recognition. These include limiting situations in which it can be used and the type of probe images used. They require that all face queries be evaluated by trained examiners and mandate that face recognition be used for investigative leads that must be corroborated.
As another example, the New York City police department (N.Y.P.D.) has spelled out a detailed protocol for the use of FRT. This requires investigators to submit face images to a special facial identification section of the department (the Real Time Crime Center, Facial Identification Section) that will, for example, ensure that image quality is sufficient and that use of FRT is warranted. The section can reject unsuitable probe images and reviews matches. Critically, a “possible match candidate” is meant to be “treated as an investigative lead only” and does not establish probable cause to make an arrest. The unit also retains records of searches and results. It has been reported that in other localities, investigating officers have accessed FRT directly, without supervision. Specific requirements could be mandated, with legal consequences if they are not followed, such as disallowing evidence produced in subsequent investigation.
However, in spite of N.Y.P.D. guidelines, FRT did lead to the false arrest of Trevis Williams. After FRT identified him as a suspect in a crime, the victim identified him from a photo lineup, although he was eight inches taller and 70 pounds heavier than her initial description of the suspect, in addition to other exculpatory evidence. This illustrates the difficulty of ensuring that guidelines effectively prevent errors and false arrests.
Regulation may be applied not only to government agencies, such as police departments, but also to private companies that are increasingly deploying face recognition systems in commercial settings. RiteAid’s use of face recognition illustrates how governance failures can arise outside of law enforcement. According to the FTC complaint, “Rite Aid failed to consider or address foreseeable harms to consumers flowing from its use of facial recognition technology, failed to test or assess the technology’s accuracy before or after deployment, failed to enforce image quality standards that were necessary for the technology to function accurately, and failed to take reasonable steps to train and oversee the employees charged with operating the technology in Rite Aid stores.” These deficiencies were not primarily algorithmic; they reflected a lack of risk assessment, testing, training, oversight, and ongoing monitoring.
The FTC’s enforcement action demonstrates that existing consumer protection laws can be applied to address some forms of misuse. However, as commercial deployment expands, more explicit regulatory standards may be necessary to prevent similar failures. Such standards could require companies to conduct pre-deployment accuracy and bias testing, implement image-quality controls, establish employee training and supervision protocols, monitor and document false positive rates, and assess foreseeable risks before using face recognition in customer-facing environments. Clear statutory or regulatory requirements would provide ex ante guardrails rather than relying solely on ex post enforcement after harms have occurred. Regulations could also require clear disclosure when face recognition is used—both to affected individuals and in aggregate public reporting—so that its role in decision-making can be scrutinized, evaluated, and corrected where harms emerge.
Policymakers should be willing to ask if using facial recognition is appropriate at all in certain circumstances. In higher-risk contexts, policymakers could impose outrights bans, limit use to specified categories of serious crimes, require a warrant, or mandate corroborating evidence before an individual identified through face recognition is included in a lineup or arrested.
As an example of use restrictions, the state of Maryland has limited the use of automatic face recognition to specific, serious crimes, and requires that defense attorneys be notified when it was used in a case. Montana and Utah require police to obtain warrants in the use of face recognition. In Detroit, police must obtain corroborating evidence before placing a suspect identified through face recognition in a line up. Several cities have banned the police use of face recognition, including San Francisco and Boston, while Portland has banned the use of face recognition by private entities in all public places.
At the federal level, members of Congress have introduced legislation that would impose a nationwide moratorium on government uses of face recognition technology absent explicit congressional authorization. Together, these restrictions illustrate a broader policy approach: limiting deployment in high-risk settings until adequate safeguards, transparency, and accountability mechanisms are in place.
Conclusions
Face recognition systems have improved dramatically in accuracy over the past decade, and in tightly controlled environments they now perform at very high levels. At the same time, substantial differences in performance across demographic groups persist, particularly in the false positive errors most closely associated with wrongful arrests and other harms. As overall error rates decline, these disparities may matter less in low-risk settings, but increasing deployment in high-stakes and uncontrolled contexts may lead to continued harms.
Technical improvements can reduce some sources of bias. Developers can improve dataset balance, adjust thresholds, and refine model design. However, eliminating differential performance entirely is beyond the current state of the art, particularly in operational environments involving low-quality images and large search databases. Policymakers should not assume that continued technical progress alone will resolve these disparities.
Perhaps most importantly, policymakers should view the regulation of face recognition through a sociotechnical lens, considering the interaction between the technical system and the humans who use it.
We cannot wait for perfect sociotechnical systems, but must govern the deployment of imperfect ones. Policymakers must decide where face recognition is not legitimate. If face recognition is used in high-stakes applications, it should be subject to clear limitations, transparency requirements, and enforceable protocols designed to prevent errors from cascading into wrongful arrests or other serious harms.
Appendix: Variations in Bias Over Time
We examined the performance of face recognition systems evaluated by NIST on different demographic groups. All results are based on data on a verification task, updated on March 5, 2025. More recent data on somewhat different tasks shows similar levels of bias. False positive matches are measured when comparing two high quality, visa-like images of two different people of the same sex, age group and region of birth. Demographic disparities are computed by taking the ratio of the false positive rate for two different demographic groups. For example, the ratio of the false positive rate on faces of people born in Western Africa to the false positive rate for people born in Eastern Europe for the highest performing FRT was 17.42, meaning that a false positive match was 17.42 times as likely for someone from Western Africa.
NIST has evaluated differential performance of commercial systems for over five years. Many companies have submitted multiple versions of their FRT over time, as the systems have improved. This allows us to determine how the bias in these systems has changed. We considered the 20 systems with best overall performance, which originated from 12 different companies. Eight of these companies had submitted at least four different versions of their FRT for evaluation, and so we focused on these eight systems.
Figure 8 shows the change in the ratio of differential performance for three pairs of demographic groups. For illustrative purposes, we show results from two different companies. The curves from Sensetime illustrate differential performance that has increased over time, while the curves from Rank One Computing (ROC) show differential performance that has decreased. Solid curves show the ratio of false positives for subjects of West African birth compared to Eastern Europeans. The dashed curves show performance on females compared to males. The dashed-dotted curves show an older age group (65+) compared to a younger cohort (20-35).
Table 1 shows the correlation between the passage of time and the ratio of differential performance for all eight companies. A negative correlation indicates that bias has dropped over time, while a positive correlation shows an overall increase in bias. If the correlation is close to 1 or -1, this means that the change in performance over time is highly consistent, while a correlation close to 0 means that there is no clear trend in the increase or reduction in bias. We can see that Toshiba, Idemia, and ROC have reduced biased performance over all three ratios, while Sensetime has increased bias, with other companies showing mixed performance.
Outcome-Based Contracting Reorients Government IT Acquisition Around Public Value and Mission Results
The effectiveness of federal programs is increasingly determined by the technology that powers them. Yet decades of oversight and research have documented persistent challenges in large-scale IT modernization. The Government Accountability Office has repeatedly designated federal IT management as high risk, citing cost overruns, schedule delays, weak requirements management, and inadequate oversight. Bent Flyvbjerg’s research shows that large public-sector technology and infrastructure programs are especially prone to failure due to scope creep and cumulative risk. The Defense Innovation Board similarly concluded in Software Is Never Done that long development cycles and early requirement lock-in expose missions to unacceptable risk.
Across these analyses, the pattern is consistent: requirements are defined too early and too rigidly; performance is measured too late; incentives reward milestone completion rather than operational outcomes; and risk accumulates until deployment. These failures reflect several structural challenges—fragmented funding, leadership turnover, legacy system complexity, and acquisition models that delay validation and limit adaptation.
Traditional acquisition approaches assume stable requirements and predictable environments. Software-intensive systems do not behave this way. Requirements evolve, dependencies emerge during implementation, and technology ecosystems shift over the life of the contract. In this context, specification-driven models can increase risk by delaying feedback and limiting course correction.
This paper examines Outcome-Based Contracting (OBC) as a model for aligning acquisition with the realities of modern IT delivery. OBC reframes procurement around the staged achievement of measurable mission outcomes rather than the delivery of predefined technical artifacts. OBC ties funding, evaluation, and continuation decisions to mission outcomes and pairs naturally with iterative delivery practices that surface and reduce risk early.
Outcome-Based Contracting
Federal acquisition models have evolved over time in response to changing technologies and risks. Early approaches emphasized detailed specification and cost control, with contracts structured around defined requirements and reimbursement of inputs (e.g., cost-plus and fixed-price models). As systems grew more complex, performance-based contracting emerged to shift focus from activities to measurable outputs and service levels. However, in complex and dynamic environments, even performance-based models often remain tied to predefined deliverables and intermediate metrics, limiting their ability to adapt as conditions, requirements, and understanding evolve over time.
Outcome-based contracting (OBC) represents a further evolution. It structures the government–contractor relationship around shared accountability for mission results rather than delivery of predefined outputs. Its defining feature is not a pricing model, but the alignment of incentives, governance, and performance measurement around measurable mission outcomes.
As Allan Burman notes, building on performance-based contracting, OBC shifts accountability from activities and milestones to mission outcomes. In practice, it establishes a structured process in which government and contractor jointly deliver measurable results, with contracts defining decision rights, evaluation mechanisms, and adaptive processes.
Key features include:
- Shared accountability: success is defined in operational terms, not artifact delivery
- Collaborative outcome definition: the government defines the problem to be solved, contractors propose and refine approaches as evidence emerges
- Adaptive performance management: metrics guide decisions, not just compliance
- Joint problem solving: governance supports rapid adjustment when performance diverges
A useful way to understand outcome-based contracting is as a managed performance relationship rather than a one-time procurement transaction. As research from the IBM Center for The Business of Government emphasizes, effective outcome-based models require clearly defined desired results, measurable indicators of success, and ongoing performance management processes that allow both parties to assess progress and adjust course. This includes establishing baseline performance, continuously monitoring results, and linking financial incentives, contract options, and governance decisions to demonstrated improvement. Critically, these models depend on sustained collaboration and transparency: agencies must be able to interpret performance data and engage in joint problem-solving with vendors, rather than relying solely on compliance reviews. In this sense, OBC is not simply a different way to write requirements—it is a different way to manage delivery, in which measurement, incentives, and decision-making are continuously aligned to achieving mission outcomes.
Applying Outcome-Based Contracting to IT Modernization
Applying OBC to IT modernization requires three shifts: defining measurable outcomes, structuring decision rights, and organizing contracts around incremental delivery.
Defining outcomes
Mission objectives must be translated into measurable operational indicators—such as transaction completion rates, time to resolution, system availability, or error reduction. These indicators must be precise enough for evaluation while reflecting real-world service performance.
Effective models distinguish between:
- Mission-level outcomes (stable): e.g., reducing time to receive benefits
- Implementation metrics (adaptive): e.g., response times or interim system thresholds
For example, a call center contract might set a mission outcome of reducing resolution time by 30 percent, supported by metrics such as speed of answer, first-contact resolution, and callback completion time.
A central design question is how outcomes are embedded in the contract. Outcomes can function as binding accountability anchors, linked to evaluation, incentives, and option decisions, but not as rigid end-states. This approach is only effective when supported by governance structures that allow agencies to interpret performance and adjust delivery.
Critically, outcomes and the underlying problem definition must be treated as testable and subject to refinement. Initial problem framing is often incomplete in complex systems. Contracts and governance models should therefore include regular check-ins, using data, user research, and operational feedback to assess whether the problem is being solved as intended. Where necessary, agencies and vendors must be jointly empowered to restate or refine the problem to ensure continued alignment with mission needs.
Structuring decision rights
OBC requires clear decision making authority over priorities and tradeoffs. In software delivery, this centers on a strong government Product Owner (PO) role. The PO is responsible for backlog prioritization, acceptance criteria, and aligning delivery with mission outcomes. The PO must be empowered to continuously adjust priorities based on user needs and performance data without requiring contract modifications. Contractors are accountable for delivering measurable progress, but do not control mission priorities.
Governance must reflect agency maturity, and also the nature of the initiative. More mature organizations can rely on PO-driven execution and adaptive metrics, using contract outcomes as high-level anchors. Even in less mature agencies, OBC principles can be applied in targeted ways—particularly in user-facing systems or components where outcomes can be clearly measured. In some cases, especially large enterprise system implementations, hybrid approaches may be required. These may combine clearly defined objectives and outcome metrics with more structured implementation phases for core platform rollout. The key is not strict adherence to a single methodology, but aligning decision rights, outcomes, and delivery approach to the realities of the system being implemented.
Structuring incremental delivery
Contracts must support incremental, evidence-based delivery. Large, multi-year programs defer risk discovery until late in the lifecycle. Iterative delivery reduces this risk by shortening feedback loops: capabilities are deployed incrementally, evaluated under real conditions, and adjusted early. Incremental delivery provides disciplined mechanisms for iteratively paying down risk.
OBC complements this model by tying funding and continuation decisions to demonstrated performance. Agile practices surface risk; OBC aligns accountability and resources to its mitigation.
This has direct implications for funding models. Effective OBC implementations require upfront decisions about how much funding is allocated to a product or service, with mechanisms to adjust that funding over time based on performance. Budgeting should support iterative scaling—expanding or contracting investment based on whether outcomes are being achieved. This, in turn, requires financial flexibility, such as capability-based budgeting, and the ability to reallocate funds or leverage working capital-like mechanisms.
In practice, appropriations constraints can limit this flexibility. For example, agencies operating under single-year appropriations may struggle to dynamically adjust funding in response to performance signals. Addressing this requires coordination between acquisition, product, and financial management functions to ensure that funding structures align with the adaptive nature of outcome-based delivery.
Outcome-Based Contracting In Practice
Outcomes-oriented approaches are not new but remain underutilized in IT acquisition. Existing models demonstrate the value of aligning funding to measurable performance.
Within government, the Department of the Navy’s World Class Alignment Metrics (WAM) evaluates IT investments based on outcomes such as resilience, customer satisfaction, and cost per user. Similarly, Department of Defense Performance-Based Logistics ties compensation to readiness outcomes, and NASA’s Commercial Crew program links payments to demonstrated capability.
These examples share a core principle: funding follows validated performance rather than predefined inputs. Applied to IT modernization, this requires pairing mission outcomes with iterative delivery, clear decision rights, and sustained technical engagement. Without these elements, outcomes risk becoming abstract goals rather than operational tools.
Despite its advantages, outcome-based contracting is not the default in federal IT acquisition. In practice, existing incentives continue to favor specification-driven models: funding structures are rigid, oversight emphasizes compliance with predefined requirements, and procurement processes reward detailed up-front definition over adaptive execution. The following case illustrates how these dynamics shape real-world outcomes—and how leadership, governance, and delivery choices ultimately determine whether programs succeed or fail.
Case Study: SSA Call Center Modernization
The Social Security Administration (SSA) operates one of the largest public-facing service platforms in the federal government, serving approximately 70 million Americans through its national 800-number network and field offices, processing high volumes of calls. In 2017, the SSA faced growing problems with its aging, complex telephone infrastructure and rising wait times for the tens of millions of Americans who rely on the agency’s national 800-number for assistance with benefits, Social Security numbers, and other services. To address these issues, SSA launched the Next Generation Telephony Project (NGTP), a large IT modernization effort intended to replace legacy telephone systems and unify call handling across the agency.
NGTP emerged from a traditional acquisition model: a detailed, waterfall-style specification, a large systems-integrator contract, and milestone-based progress tied to predefined technical requirements. In February 2020 SSA awarded an IDIQ contract to Verizon to design, implement, test, transition, operate, and maintain the new telephony platform, including procurement of hardware, software, and services. Implementation faced challenges from the beginning: Verizon’s win was contested, delaying the start of work. SSA’s team didn’t realize the solution Verizon proposed, reinforced by SSA’s own contract requirements, was based on architectural components that were a generation behind leading contact center systems. NGTP’s 10-year planning horizon meant any solution would likely be obsolete before full deployment.
By 2020, with the project still in early development, the COVID-19 pandemic forced SSA call center agents to work remotely — a capability the existing legacy system lacked. Verizon scrambled to assemble a custom stopgap solution, but this was plagued with issues. From May 2021 to December 2022, over 40 service disruptions caused dropped calls, long wait times, and outages. At times, more than half of calls went unanswered as the team capped incoming calls to maintain system stability.
Meanwhile, NGTP suffered further delays and technical hurdles. SSA executives were frustrated but assumed they were contractually stuck. The system finally launched in December 2023 for the 800-number only, delivering just part of the promised functionality. But the system experienced ongoing performance issues, including increased wait times and disconnected or unanswered calls that hindered the agency’s ability to serve the public. On August 22, 2024, after only about 10 months of operation, SSA transitioned the 800-Number Network off the NGTP platform and moved to a different telephony solution. The NGTP project cost SSA over $160 million and was abandoned within a year of deployment, with the agency reverting to an alternative telephony platform.
The failure was not attributable to a single cause. Interviews and oversight findings point instead to a combination of over-specification, missing mission outcomes, weak accountability mechanisms, long planning horizons, and an acquisition structure that made adaptation difficult.
It is also important to recognize the scale and complexity of SSA’s operating environment. The agency’s service delivery depends on hundreds of interdependent systems, many of which encode decades of policy and operational logic. Modernization efforts must contend not only with outdated technology, but with deeply embedded business rules and integration dependencies that are not always fully visible at the outset. These conditions increase the difficulty of both specification and implementation, regardless of acquisition approach.
Specificity Did Not Produce Control
A central lesson of NGTP is that specificity in requirements does not necessarily translate into control over outcomes. The solicitation and technical requirements were extensive and highly prescriptive. They incorporated staff input but lacked sustained user-centered validation and focused heavily on defining technical components rather than the operational outcomes the system was intended to achieve. In several cases, the contract mandated architectural approaches that constrained flexibility and effectively locked the program into solutions already lagging prevailing commercial practice.
The NGTP contract required the development of significant custom telephony capabilities in a market where mature commercial Contact-Center-as-a-Service (CCaaS) platforms already existed. Custom software and hardware development inherently carries greater risk than configuring established commercial platforms: the first buyer bears the cost of defects, scaling problems, and design errors that mature products have already identified and resolved. As a result, the program assumed substantial technical risk without clear evidence that SSA’s mission required a bespoke system.
The decision to pursue a custom telephony architecture also introduced structural technical risks. The system was intended to function as a “single enterprise contact center” capable of routing calls across SSA’s national network. In practice, however, the implemented solution consisted of six separate contact centers operating as independent queues rather than a unified system. According to the SSA Office of Inspector General, this configuration prevented calls from being dynamically rerouted between queues, limited agents to answering calls from a single queue, and could disconnect calls when agents logged out of one queue even if capacity existed elsewhere in the system. These limitations increased wait times and created operational inefficiencies. Efforts to resolve the architectural mismatch led to the development of a custom routing “brain” intended to connect the six queues—effectively reinventing load-balancing technologies that have been widely used and commercially mature for decades. The need to retrofit this architecture required multiple contract modifications and created ongoing operational challenges. As one SSA leader later observed, “Some people on the project might have known that load balancers had been mature for 30 years, but managers weren’t listening to them.”
The contract’s prescriptive structure also undermined the flexibility typically associated with its contract vehicle. Although NGTP was structured as an IDIQ, the narrowly defined solution space meant that many necessary adjustments required formal work orders or contract modifications. In practice, the program combined the administrative rigidity of traditional contracting with the technical risk of custom system development.
The detailed specifications locked the implementation into many types of outdated architectural assumptions. For example, certain components were required to be compatible with an old, yet unspecified, version of Internet Explorer, a browser Microsoft formally retired in 2022 in favor of Microsoft Edge. Rapidly evolving technology environments can render highly specific requirements obsolete before systems are delivered. At the same time, the extensive technical detail did not fully address practical operational considerations, such as ensuring that existing SSA call center staff could easily access and use the system in their day-to-day workflows.
Missing Mission Outcomes
The NGTP case also illustrates the limits of operator-focused metrics. SSA understandably focused on call volume and the ability of the system to handle surges in demand. Previous infrastructure could “top out” during predictable spikes, such as cost-of-living adjustment periods. Capacity therefore became a central concern.
But throughput alone is not the same as service performance. For beneficiaries, the meaningful outcomes include how long it takes to reach a representative, whether the issue is resolved on the first contact, how many interactions are required, and how long it takes to complete a request. Those mission outcomes were not adequately embedded in the contract’s performance framework.
Metrics such as average speed of answer did not fully capture the user experience, particularly when calls were dropped, or handled initially by automated systems, or callbacks were counted in ways that reduced reported wait times without necessarily reducing the time required for beneficiaries to obtain help.
The deeper problem was architectural as well as contractual. SSA’s call center is best understood as a front-end interface to a much larger, deeply complex service delivery system involving eligibility determination, identity verification, claims processing, and payments. Yet the contract largely treated telephony modernization as a standalone technical problem rather than as part of an integrated operating model. This narrow framing also limited foresight into how the capability could evolve over time, adopting future emerging technologies or adding integrations with other agency systems to support an omnichannel service model. Defined primarily within a technical infrastructure context, the effort optimized for telephony components rather than positioning customer service as a strategic, cross-agency capability.
Accountability Was Weak Where It Mattered Most
Federal acquisition frameworks already provide multiple mechanisms for vendor accountability, including service level agreements (SLAs), financial incentives and penalties, option periods tied to demonstrated progress, and formal performance reviews. In the private sector, large IT and service contracts routinely embed such operational standards like uptime guarantees, response-time thresholds, incident-resolution timelines, and financial penalties for failure to meet them to ensure that vendors remain accountable for system performance under real operating conditions. In the NGTP case, however, these mechanisms were not sufficiently embedded in the contract structure or tied to mission outcomes and enforceable operational standards.
The SSA Office of Inspector General found that the NGTP contract lacked sufficient performance-based quality standards and incentives to ensure accountability for resolving system-performance issues. The practical result was limited leverage for the government even when the system failed to meet technical and operational needs.
The most striking example came at termination. When SSA stopped work on the NGTP effort, the agency still paid the vendor the remaining portion of the full $125M contract amount. Whatever the legal and operational considerations behind that decision, the message to the market was problematic: poor performance did not produce a proportionate financial consequence.
SSA’s Course Correction
SSA’s response illustrates an alternative approach. Rather than pursuing another large, fully specified replacement effort, the agency adopted a more incremental approach using cloud-native technology and more flexible contract mechanisms. A proof-of-concept deployment of Amazon Connect at a Pennsylvania call center allowed SSA to test the platform in live operating conditions before scaling further.
This approach introduced several disciplines that had been missing from NGTP. It reduced dependence on bespoke infrastructure, created an opportunity to measure performance under real conditions, and allowed the agency to collect operational evidence before broader rollout. Critically, assumptions were tested incrementally rather than embedded upfront. The agency also adopted Product Operating Model best practices: they stood up a cross-functional product team with a product manager, technical lead, design lead, and an SME lead who was responsible for state specific launches, training, and key metrics.
Early results suggested improvement. SSA’s Office of Inspector General reported that the agency’s telephone service handled substantially more callers in fiscal year 2025 and that reported average speed of answer improved. The subsequent administration leveraged the scalable platform to expand deployment across all field offices. At the same time, oversight and public reporting also highlighted the importance of careful metric design. Some reported gains did not fully reflect the total time beneficiaries waited for callbacks or to resolve their issues. That distinction is key: better performance frameworks depend not simply on more metrics, but on the right metrics.
Lessons for Outcome-Based Acquisition
The SSA case highlights several lessons:
- Complex systems cannot be fully specified in advance. Over-specification increases risk, and can lock programs into the wrong solution.
- Iterative delivery is a risk management tool. It surfaces integration, usability, security, and performance problems early enough to address them.
- Accountability must be tied to mission outcomes. Operational and customer experience results matter more than intermediate artifacts.
Governance matters as much as contract structure. Strong product ownership and leadership are essential. Critical to the successful turnaround was having a cross-functional “product quad” of product management, engineering, design, and domain expertise. In the NGTP case, requirements were largely defined within an infrastructure-oriented telecommunications function, leading to a solution optimized for technical components rather than end-to-end service outcomes. This organizational starting point constrained problem framing and limited the program’s ability to align delivery with user needs and mission performance.
An outcome-based model would have defined mission metrics such as first-contact resolution and total time to complete transactions, incorporated discovery phases, and tied continuation decisions to demonstrated performance. It also would have created a precedent for early adoption of critical monitoring tools used by leaders in the course correction, like integrating real-time customer experience telemetry into daily operations, which enabled continuous monitoring of user outcomes and rapid reprioritization of features to address emerging issues as they occur.
Finally, contract structure alone is not sufficient. Successful implementation depends on sustained leadership, technical judgment, and the institutional willingness to act on evidence. Several interviewees noted that meaningful progress accelerated only after leadership with prior agile and product delivery experience assumed responsibility for the effort. Acquisition structure can enable better outcomes, but it cannot substitute for leadership capable of making informed technical and operational decisions in complex environments.
Conclusion
Large-scale IT modernization is central to federal mission delivery. Traditional acquisition models remain effective in stable, well-defined environments but are poorly matched to software-intensive systems characterized by uncertainty, interdependence, and continuous change.
Outcome-based contracting provides a more effective framework for these conditions. It strengthens accountability by tying funding and continuation decisions to measurable performance, improves risk management through iterative delivery, and reorients acquisition toward public value. Rather than asking whether a contractor delivered what was specified, it asks whether the government achieved the mission results it needed.
Realizing this shift requires more than changes to contract structure. The authorities to pursue outcome-based approaches largely already exist, but incentives, funding constraints, and workforce capabilities continue to reinforce specification-driven models. Appropriations structures limit flexibility, oversight mechanisms emphasize compliance over performance, and many agencies lack the product management and data capabilities needed to define and act on outcome metrics. Addressing these constraints will require coordinated changes across budgeting, oversight, acquisition practice, and workforce development.
In the near term, IT modernization progress should be visible in concrete ways: contracts that tie option decisions and incentives to mission outcomes; programs operating with empowered Product Owners and real-time performance data; and evaluation frameworks that prioritize whether services are improving, not just whether requirements were met. Over time, this would mark a broader shift from managing compliance with plans to managing performance against outcomes.For technology and IT modernization efforts, the success of outcome-based contracting depends on alignment with product operating model practices, technical expertise, and sustained leadership. The central proposition of OBC is not less discipline, but better discipline—organized around measurable outcomes, empirical evidence, and the continuous identification and reduction of technical and operational risk.
Why Credit Access Makes or Breaks Clean Tech Adoption and What Policy Makers Can Do About It
Building Blocks to Make Solutions Stick
For clean energy to reach everyone, government can’t just regulate behavior. It has to actively shape credit markets in partnership with the private sector.
Implications for democratic governance
- Financing programs need governance that is visibly fair, transparent, and accountable to enable trust–without that, low trust drags down their efficacy.
- Build broad constituencies to set and drive the agenda.
- Treat local lenders and communities as active implementers, not passive beneficiaries.
Capacity needs
- Talent, playbooks, and governance structures to run policy-enabled finance (credit, guarantees, revolving funds) with speed and integrity.
- Faster contracting, simpler reporting, and fewer transaction frictions.
- Clear guidance on identifying and resolving tradeoffs, instead of allowing decisions to bog down in case-by-case analysis paralysis.
- Staff who can translate between agencies, investors, and communities.
- Connective tissue to and between states to replicate smart practices and share toolkits for financing mechanisms that move beyond one-time infusions of cash.
- Quasi-public structures that give government agility without sacrificing public interest and accountability.
Access to affordable credit is a necessary condition for an equitable energy transition and an inclusive economy. Markets naturally concentrate capital where risk is low and returns are predictable, leaving low-income communities, rural areas, and smaller projects behind. Well-designed federal policy can change that dynamic by shaping markets—reducing risk, creating incentives, and unlocking private capital so clean technologies reach everyone, everywhere. This paper explores how policy-enabled finance must be part of the toolkit if we are going to drive widespread adoption of clean technologies, and can be summarized as follows:
- Problem: Clean technologies require upfront capital; tax incentives alone are insufficient for small, distributed projects and underresourced borrowers. Without targeted credit solutions, the energy transition will deepen existing economic and environmental inequities.
- Opportunity: Policy‑enabled financial services—direct investments, tax incentives, and loan guarantees—have a proven track record of expanding access to credit and driving inclusive economic growth. The climate policy playbook should be expanded to incorporate lessons from other sectors and programs that have incorporated these interventions.
- Case study: The Greenhouse Gas Reduction Fund (GGRF) was designed to augment grants and tax incentives contained in the Inflation Reduction Act by seeding revolving capital, leveraging national financing hubs, and mobilizing local lenders to scale clean investments. This program was stopped in its tracks early in the Trump administration, but lessons from its design and early implementation should be leveraged by local, state, and future federal programs.
The critical role of policy-enabled finance to drive widespread economic opportunity
Access to affordable credit is not just a financial tool—it is a cornerstone of economic opportunity. It enables families to buy homes, entrepreneurs to launch businesses, and communities to invest in technologies that reduce costs and improve quality of life. Yet, across the United States, access to credit remains deeply uneven. Nearly one in five Americans and entire regions – particularly rural and Tribal communities – are excluded from the financial mainstream, limiting their ability to thrive.
Private-sector financial institutions—banks, private equity firms, and other lenders—are designed to maximize profit. They concentrate on markets where risk is predictable, transaction costs are low, and deals are easy to close. This business model leaves behind borrowers and communities that fall outside these parameters. Without intervention, capital flows toward the familiar and away from the places that need it most.
Public policy can change this dynamic. By creating incentives or mitigating risk, policy can make lending to or investing in underserved markets viable and attractive. These interventions are not distortions — they are strategic investments that unlock economic potential where the market alone cannot, generating economic value and vitality for the direct recipients while yielding positive externalities and public benefit for local communities. And, importantly, these policy interventions act as a critical complement to regulation. Increasing access to credit is often the carrot that can be paired with, or precede, a regulatory stick so that people are not only led to a particular economic intervention, but they are also incentivized and enabled.
For decades, policy-enabled finance has delivered measurable impact through multiple programs and agencies designed to support local financial institutions – regulated and unregulated, depository and non-depository – that are built to drive economic mobility and local growth. These policies and programs have taken multiple forms, but can generally be put in three categories:
- Direct Investments: Programs like the CDFI Fund Financial Assistance awards that provide enterprise grants to Community Development Financial Institutions (CDFIs) to support balance sheet strength and increased lending and the Emergency Capital Investment Program (ECIP) that made equity investments into community development credit unions and banks.
- Tax Credits and Incentives: The Low-Income Housing Tax Credit (LIHTC), New Markets Tax Credit (NMTC), Opportunity Zones, and renewable energy credits like the Investment Tax Credit and Production Tax Credit have spurred billions in private investment for housing, community development, and clean energy.
- Loan Guarantees: Small Business Administration, U.S. Department of Agriculture, and Department of Energy guarantee programs, among others, reduce risk for the lender, enabling small businesses, rural communities, and earlier stage companies to access credit otherwise unavailable at transparent and affordable rates from participating financial institutions.
These tools enjoy broad recognition and bipartisan support because they work. They increase access, availability, and affordability of credit—fueling job creation, housing stability, and economic resilience. Policy-enabled finance is not charity; it is a proven strategy for broad and inclusive economic growth and a key tool for the policy-maker toolkit to support capital investment, project development, and adoption of beneficial technologies in a market-driven context that can increase the effectiveness of a regulatory agenda.
Most importantly, policy-enabled finance has led to major improvements in wealth-building and quality of life for millions of Americans. The 30-year mortgage was created by the Federal Housing Administration in the 1930s as a response to the Great Depression. Before this intervention, only the very wealthy could afford to buy a home given the high downpayment requirements and short-term loans. Since this policy change, thousands of financial institutions have offered long-term mortgages to millions of Americans who have bought homes that provide safety and security for their families, strong communities, and an opportunity to build wealth through appreciating assets. Broad home ownership is a public good, but until the government created the right policy and regulatory framework for the markets, it was out of reach for the majority of Americans.
Similarly, the Small Business Administration’s loan guarantee programs started in the 1950s supported financial institutions, including banks and non-bank lenders, in extending credit to small businesses that would otherwise be difficult to serve with affordable credit. These programs have collectively helped millions of small businesses access the credit they need to grow their businesses, create wealth for themselves and their families, provide critical goods and services in their communities, and create a diverse and vibrant local tax base.
The financial markets, without these types of interventions, are not structured to prioritize access and affordability. Well-designed policy and complementary regulatory interventions have been proven to drive different behaviors in the capital markets that yield real benefits for American families and businesses.
The role of access to credit in driving an equitable energy transition
The public and private sectors have spent decades and billions of dollars investing in the development of clean technologies that reduce greenhouse gas emissions, create economic benefits, and deliver a better customer experience. Now that these technologies exist, the challenge is to deploy them for everyone, everywhere.
The barrier to widespread deployment is that most clean technologies require an upfront investment to yield long-term benefits and savings (i.e., an initial capital expense to reduce ongoing operational expenses) – technologies like solar and battery storage, electric vehicles, electric HVAC and appliances, etc. – which means that people and companies with cash or access to credit are adopting these better technologies while those without access to cash or credit are being left behind. This is yielding an even greater divide – creating economic savings, health benefits, and better technologies for those who can afford them, while leaving dirty, volatile, and increasingly expensive energy sources for the lowest-income communities.
Many of the federal policy interventions to support deployment of these new technologies to date have been through tax credits. These policies have been very popular, but are not often widely adopted, particularly in rural and lower-income communities, because, (a) they are complex, (b) they often require working with individuals or businesses with large tax liabilities, and (c) they typically come with high transaction costs, making smaller, more distributed projects harder to make work. The energy transition is a huge wave of change, but it is made up of many small component parts – individual buildings, machines, vehicles, grids – so if our policies fail to enable small projects to get done, we will fail to transition quickly and equitably.
To deploy everywhere, households and businesses need credit to offset capital expenses. To expand access to credit, we need supportive clean energy policies that work within and alongside local financial services ecosystems – just like we’ve seen with housing and small businesses.
Regulation is insufficient to drive widespread adoption
Pursuing a carbon-free economy is a massive undertaking and, understandably, much of the state and federal government’s toolkit has focused on regulation of people and businesses to drive behavior change – policies like fuel economy standards, pollution restrictions, renewable energy standards, and electrification mandates. This is an important piece of the puzzle – but insufficient to drive broad (and willing) adoption.
Take, for example, the goal of electrifying heavy-duty trucks in and around port communities. States like California have attempted to set a date at which all new trucks on the registry must be zero-emissions vehicles. Predictably, this mandate was met with a lot of pushback from truck drivers, small operators, and industry associations who struggled to see a path to complying with this regulation without a major increase in cost.
It wasn’t until the regulation was paired with direct incentives for truck purchases and an attractive and feasible financing package for vehicle acquisition and charging infrastructure that the industry actors started to come around. This has helped change behavior of both buyers and incumbent sellers in the market.
Policy-enabled finance creates tools – often used in conjunction with other policy mechanisms – that can more effectively meet people where they are with affordable, appropriate, and tailored solutions and can help demonstrate a feasible path to adoption that can help buyers and sellers in these markets adapt accordingly.
The Greenhouse Gas Reduction Fund as an innovative policy-enabled finance program
The Greenhouse Gas Reduction Fund (GGRF) is more than an emissions initiative—it is a strategic investment in economic equity and market innovation that took lessons in program design from many sectors and programs of the past. Designed with three core objectives, the program aims to:
- Reduce greenhouse gas emissions at scale
- Deliver direct benefits to communities, particularly those that have been historically underserved by the financial markets
- Transform financial markets to accelerate clean energy adoption and resilience
GGRF programs, including the National Clean Investment Fund, the Clean Communities Investment Accelerator, and Solar for All, were built to complement other Inflation Reduction Act (IRA) programs by occupying a critical middle ground between grant programs and tax credits. Grant programs provide direct, one-time support for projects and programs that are not financeable (i.e., not generating revenue). Tax credits are put into the market to incentivize private investment for anyone interested in taking advantage but are not typically targeted to any specific project or population.
GGRF bridges these approaches. It channels capital into markets where funding does not naturally flow in the form of loans and investments, ensuring that clean energy and climate solutions reach every community—but does so in a way that often extends the benefits of the tax credits and incentive programs so that they reach a broader set of projects and communities where the incentive is insufficient to drive adoption. GGRF focuses on increasing access to credit and investment in places that traditional finance overlooks by reducing risk and creating scalable financing structures, empowering local lenders, community organizations, and national financing hubs to deploy resources where they are needed most. Also, because the program makes loans and investments, it recycles capital continuously – akin to a revolving loan fund – so that the work filling gaps in market adoption can continue for decades.
GGRF’s design was built on a strong foundation of successful direct investment programs for local lenders, such as CDFI Fund awards and USDA programs. What makes it unique is its scale—tens of billions of dollars—and its centralized approach, leveraging national financing hubs to drive systemic change with and through new and existing local financial capillaries (i.e., credit unions, community banks, green banks, and loan funds). This program was not built to drive incremental progress; it is a market-shaping intervention designed to accelerate the clean energy transition while promoting widespread economic growth.
Unfortunately, the program was stopped in its tracks when the Trump administration illegally froze funds already disbursed to awardees, leading to multiple lawsuits to restore funding. Without this disruption, awardees and their partners across the country would be driving direct economic benefits for families and communities across all 50 states. In the first six months of the program, awardees had pipelines of projects and investments that were projected to create over 49,000 jobs, drive $866 million in local economic benefits, save families and businesses $2.7 billion in energy costs, and leverage nearly $17 billion in private capital. The intention and mechanics of the program were working – and working fast – to deliver direct economic, health and environmental benefits for millions of Americans.
Moving at the speed of trust: Bringing the public and private sectors together for effective implementation
For a program like the Greenhouse Gas Reduction Fund to succeed, both the private and public sectors need clarity, confidence and accountability. But most importantly, they need a baseline of trust between the parties to support ongoing creative problem solving to implement a new, scaled program with exciting promise and a limited blueprint.
For the private sector, certainty is paramount. Investors and lenders (and importantly, their lawyers) require clear definitions, consistent requirements, and transparency about the availability of funds, requirements of use, and the ability to forward commit capital to projects and businesses. They need mechanisms to leverage public dollars with private capital and assurances that counterparties will be shielded from political, compliance, and policy risk. Flexibility is equally critical, allowing actors to adapt to rapid market shifts and technological innovations without being constrained by rigid program structures. Understanding these requirements – and the needs of the financial market actors involved – is outside the comfort zone of most government agencies and employees and requires significant experience and capacity building to strengthen this muscle. Nimble thinking is not often associated with government agencies, but in policy-driven financial services, it is paramount.
At the same time, the public sector has its own requirements which require patience and understanding from the private sector. Policymakers and the EPA, the implementing agency of the GGRF, must ensure that funds are used properly and that Congressional and public oversight is robust. This means designing programs that comply with all laws and regulations while advancing policy priorities. It requires mechanisms for accountability—certifications, reporting, and transparency in how funds flow – along with safeguards against undue influence from purely profit-motivated private actors. Balancing these needs is not optional when managing taxpayer funds; it is the foundation for building trust and ensuring that the program delivers on its promise of reducing emissions, benefiting communities, and transforming markets.
Implementation requires striking the balance between the needs of the private and public actors; this was difficult and time consuming for both the federal employees and for us as private recipients. There was pressure to deploy quickly to demonstrate impact and the value of the program, but it took a long time to get contracts signed and funds in the market because of the many requirements of the public and private parties involved. We speak different languages, are solving for different constraints, and work in drastically different environments – all which led to complexity and delays.
Internal EPA requirements and federal crosscutters (i.e., federal requirements from other related laws that applied to this program) increased time to market and transaction costs. Many of these requirements came with high-level policy objectives without the ability to get to a level of detail required for capital deployment.
For example, two of the major policy crosscutters were the Davis Bacon and Related Acts (DBRA) requirements around labor and workforce, and the Build America Buy America (BABA) requirements for equipment manufacturing and component parts. While the agency and private awardees were aligned at a high level on policy intention – good-paying jobs and domestically-manufactured goods – down streaming these requirements to borrowers and projects required significantly more detail and nuance than was available to the agency, adding weeks and months onto implementation and frustration among private counterparties.
Clear expectations up front on how to manage the trade-offs – policy priorities versus capital deployment – could have helped create a high-level framework for implementation, which was a one-by-one review of use cases to determine feasibility and applicability. This added complexity and friction to the process without driving outsized results.
More requirements and complexity led to slower, more costly deployment, which meant fewer communities would benefit from the program’s goals of cutting emissions, creating jobs, and cutting household and business costs.
Another key feature of the program for the National Clean Investment Fund and Clean Communities Investment Accelerator was the ability for the federal government to leverage a Financial Agent to administer the funds. This arrangement was developed between the EPA and Treasury, leveraging a long-standing practice of the Treasury Department of contracting with external banks to provide financial services that were hard for the government to provide directly. This was particularly important for the National Clean Investment Fund program because the disbursement of funds into awardee accounts enabled the awardees to meet a core statutory requirement to leverage funds with private capital. Without this function, the cash would not be available on the balance sheet of the awardees and would be difficult to leverage with private investment.
Lastly, the reporting requirements for the program were complex, making it hard to provide clarity on what data collection was required for early transactions. Again, both parties recognized the importance of transparent data collection and dissemination but implementing that intent in practice was time consuming. A simple, standardized framework to get started that could evolve over time would have helped reduce uncertainty and supported faster deployment.
Altogether, the cross-sector translation – finding common ground between two disparate worlds – added many months onto the process of getting the program to the market which, in the current political climate, was time not spent doing the important work to educate a broad set of stakeholders on the program’s promise, potential, and purpose. A lot of this complexity could have been reduced by developing a baseline of trust between the parties through the application and award process, complemented by a common goal to improve program implementation over time.
Strange bedfellows create weak alliances
In addition to the programmatic elements of translation, the actors involved in implementing direct investment strategies tend to be unknown entities to government agencies and Congress. Even though many of the implementing organizations – the “awardees” – have been around for decades doing similar work, there were weak ties with Congress, federal agencies, and other related stakeholders. Similarly, there was a lack of understanding of the role that nonprofit and community-based financial organizations play in addressing market gaps. This mutual lack of understanding and engagement leaves room for misunderstanding, distrust or generalizations that can hinder the ability to make collective progress.
Within the agency, this was a new program type for the EPA, so requirements and design process took many months before anything was shared publicly. The Notice of Funding Opportunity was released nearly a year after the legislation was signed.
The unique form and function of the program and limited direct engagement with lawmakers and other stakeholders about the program left a vacuum of information, which led to skepticism and confusion. Because the funds were provided to awardees as grants, many interpreted this as just another grant program – a large federal spending package that would lead to “handouts” – instead of what it was, the federal government seeding a sustainable fund with “equity” that would be lent out, returned, and reinvested in perpetuity. For example, here is the Wall Street Journal editorial page,and later, the EPA press release conflating investments with “handouts”:
“Imagine if Republicans gave the Trump Administration tens of billions of dollars to dole out to right-wing groups to sprinkle around to favored businesses. That’s what Democrats did in the Inflation Reduction Act (IRA). The Trump team’s effort to break up this spending racket has led to a court brawl, which could be educational.”
The fact that this policy structure and the private sector entities charged with implementing it were relative strangers led to confusion and delay during a period that could have been spent on outreach, engagement, and education. Without that broad base of support, the program unnecessarily became a political punching bag.
To mitigate this risk going forward, there needs to be greater investment in relationship building, education, stakeholder engagement and capacity building within and among the implementing partners across all relevant government actors and their private sector counterparts, especially after award selections are made. This connective tissue would go a long way in creating a baseline of common understanding of the policy objectives, program design, and implementation partners involved so all parties are aligned on strategic intent and path forward.
Making policy-enabled finance programs work in the future
If we agree that policy-enabled finance is essential to drive the energy transition and deliver broad benefits, the next step is asking the right questions about how to design these interventions for success, drawing lessons from the GGRF and other related programs.
First, what mechanisms should we use, and what are the trade-offs for each? Federally supported direct investment programs, such as managed funds, can deploy capital quickly and target underserved markets, but they require strong governance, thoughtful program design, and radical transparency, otherwise they are susceptible to the “slush fund” narrative or similar risks (i.e. conflicts of interest and political favors).
Tax credits and incentives have proven effective in attracting private investment, yet they often favor actors with existing tax liability and can leave smaller players behind. Guarantees reduce risk for lenders and unlock private capital, but they demand careful structuring to avoid moral hazard and can struggle to reach communities that are truly under-resourced.
Despite the many pitfalls of direct investment programs, they address a challenge that has plagued many of the more distributed policies: centralization and market making. Often in an attempt to let a thousand flowers bloom, policymakers underestimate the need for centralized or regional infrastructure to help with asset aggregation, data collection, product standardization, and scaled capital access. This yields local infrastructure that is sub-scale, inefficient, and unable to access the capital markets for private leverage – too small to truly shape markets.
While the GGRF’s future is uncertain given pending litigation, its purpose and role as a set of centralized financial institutions within the broader community-based financial ecosystem is critical – and needs to be more broadly understood as policymakers set future priorities.
Second, should government manage funds and programs internally or partner with external experts? Internal management within an agency offers control and accountability but can strain agency capacity and impede the ability to be an active market participant. It is also difficult to attract the right talent within the government’s pay scale, leading to an inability to recruit and high turnover. This model has been attempted through programs like the Department of Energy’s Loan Programs Office (LPO), but even that market-based program has been slower to execute, delaying critical infrastructure and technology investments by months, if not years.
On the other hand, external management brings specialized expertise and market agility, yet it raises questions about oversight and influence. No matter who the private party is, there is skepticism around the use of funds, their personal or professional gain, and their intentions with taxpayer money. In our deeply politicized world, this puts a target on the leaders of these organizations that may limit who is willing to play this role.
Quasi-public Structures
Despite the challenges, on balance it seems that internal agency management or a quasi-public structure is the most feasible path. Internal management pushes the boundaries of public agency function but goes a long way to build trust and accountability. Quasi-public structures seem to be a good compromise when feasible. Other countries have figured out how to manage these programs within a government or quasi-government agency (see the Clean Energy Finance Corporation and Reconstruction Finance Corporation, both in Australia). We can too.
At the federal level, credit programs should be managed by agencies with the skills and capacities to hold an investment function, like the Department of Energy or the Treasury Department, and leverage lessons learned from programs like DOE’s LPO and EPA’s GGRF to structure new entities. Or – like many of the state and local green banks have done – create quasi-public entities that have public sector governance and appropriations but otherwise operate independently as financial institutions with their own balance sheets, bonding authority, and staffing structure.
Lastly, if public-private partnerships are preferred, who should the government work with to implement policies meant to expand access to capital and credit? Nonprofit financial institutions often prioritize mission, community impact and are willing to arrange complex financings that require a higher touch approach but often lack scale and institutional capital access. For-profit firms bring scale and expertise but often find it hard to manage a government program with a mindset or culture that differs from their typical profit-maximization frameworks.
Depository institutions such as banks offer stability and regulatory oversight, whereas non-depositories can innovate more freely to reach the hardest to serve communities. Regulated entities provide robust and trusted infrastructure and controls, but unregulated actors may move faster and can be more creative in supporting traditionally under-resourced opportunities. Specialty firms bring deep sector or asset-class knowledge, while generalists offer broad reach and experience in managing across asset classes.
To identify the optimal path, it is helpful to look to existing programs for lessons. The U.S. Treasury’s Emergency Capital Investment Program (ECIP) demonstrates how direct investment into regulated depository institutions can mobilize significant capital for underserved communities through an existing financial ecosystem. The Loan Programs Office shows what internal management can achieve for large-scale projects. Tax credit programs like the New Markets Tax Credit (NMTC) and Investment Tax Credit (ITC)/Production Tax Credit (PTC) illustrate how incentives can transform markets, while guarantee programs such as the U.S. Department of the Treasury’s Community Development Financial Institutions Fund (CDFI) Fund Bond Guarantee and SBA 7(a) and 504 guarantees highlight the power of risk mitigation in activating and standardizing products to support secondary market access. These precedents offer valuable insights as we design future policies to accelerate a broadly beneficial energy transition.
Educating policymakers to build trust in the community finance ecosystem
Regardless of path forward, one thing remains critical – building better relationships between policymakers and the community finance industry, including community banks, credit unions, loan funds, and green banks. These are the boots-on-the-ground organizations that share a mission with many policymakers to expand economic opportunity and broaden access to capital and credit. And they are often the organizations navigating multiple public products and programs to bring affordable, quality financial services to communities.
The challenge is that most advocacy and educational work for these organizations has been siloed – there are groups representing credit unions big and small, those representing housing lenders, loan funds, green banks, and community banks. The disaggregation of these efforts has diluted the potential for policymakers to look at this ecosystem as a whole to determine how best to leverage it for public good. This is not to say that each of these individual groups does not have a role to play for their members – they all have different needs and requirements and deserve representation. But the broader industry would benefit from collaboration across these organizations to create a mechanism for these institutions to help with outreach, advocacy and education around policy-enabled finance overall. This would bring a strong and powerful group of actors together for a higher collective purpose and, ideally, create a large and diverse constituency with common goals.
State and local governments stepping up
In the near-term, the absence of federal support for clean technology deployment through policy-enabled finance creates an enormous opportunity for state and local governments to step up and push forward. Hundreds of local financial institutions were doing work to prepare for the delivery of GGRF funds to and through local projects and businesses to drive broader adoption of clean technologies. These organizations continue to have the skillsets, capacity, and pipeline to finance these projects – but need access to flexible and affordable capital to do so.
State funding efforts could mirror the program and product design of the GGRF to get deals done locally, working with one or more of the constellation of financial institutions preparing to deploy federal funds. Just because the GGRF’s programs were cut short, it doesn’t mean that the infrastructure and learnings generated should go to waste – if there are public institutions willing to commit capital, there should be many financial institutions across the country ready to put it to good use.
Conclusion
If our shared goal is an equitable, rapid energy transition, policy must do more than regulate — it must enable finance and focus on deployment, or getting great projects done. The Greenhouse Gas Reduction Fund showed both the promise and the pitfalls of large-scale, policy-enabled finance: when designed and governed well, these tools can unlock private capital, deliver measurable local benefits, and sustain long-term market transformation. When implementation gaps and weak relationships persist, even well-intentioned programs become politically vulnerable and ripe for attack. To make these programs successful within our current political context, future efforts should prioritize clear governance, cross-sector capacity, and sustained stakeholder engagement so public dollars can catalyze private investment that reaches every community.
Agenda for an American Renewal
Imperative for a Renewed Economic Paradigm
So far, President Trump’s tariff policies have generated significant turbulence and appear to lack a coherent strategy. His original tariff schedule included punitive tariffs on friends and foes alike on the mistaken basis that trade deficits are necessarily the result of an unhealthy relationship. Although they have been gradually paused or reduced since April 2, the uneven rollout (and subsequent rollback) of tariffs continues to generate tremendous uncertainty for policymakers, consumers, and businesses alike. This process has weakened America’s geopolitical standing by encouraging other countries to seek alternative trade, financial, and defense arrangements.
However, notwithstanding the uncoordinated approach to date, President Trump’s mistaken instinct for protectionism belies an underlying truth: that American manufacturing communities have not fared well in the last 25 years and that China’s dominance in manufacturing poses an ever-growing threat to national security. After China’s admission to the WTO in 2001, its share of global manufacturing grew from less than 10% to over 35% today. At the same time, America’s share of manufacturing shrank from almost 25% to less than 15%, with employment shrinking from more than 17 million at the turn of the century to under 13 million today. These trends also create a deep geopolitical vulnerability for America, as in the event of a conflict with China, we would be severely outmatched in our ability to build critical physical goods: for example, China produces over 80% of the world’s batteries, over 90% of consumer drones, and has a 200:1 shipbuilding capacity advantage over the U.S. While not all manufacturing is geopolitically valuable, the erosion in strategic industries, which went hand-in-hand with the loss of key manufacturing skills in recent decades, poses potential long-term challenges for America.
In addition to its growing manufacturing dominance, China is now competing with America’s preeminence in technology leadership, having leveraged many of the skills gained in science, engineering, and manufacturing for lower-value add industries to compete in higher-end sectors. DeepSeek demonstrated that China can natively generate high-quality artificial intelligence models, an area in which the U.S. took its lead for granted. Meanwhile, BYD rocketed past Tesla in EV sales and accounted for 22% of global sales in 2024 as compared to Tesla’s 10%. China has also been operating an extensive satellite-enabled secure quantum communications channel since 2016, preventing others from eavesdropping.
China’s growing leadership in advanced research may give it a sustained edge beyond its initial gains: according to one recent analysis of frontier research publications across 64 critical technologies, global leadership has shifted dramatically to China, which now leads in 57 research domains. These are not recent developments: they have been part of a series of five year plans, the most well known of which is Made in China 2025, giving China an edge in many critical technologies that will continue to grow if not addressed by an equally determined American response.

An Integrated Innovation, Economic Foreign Policy, and Community Development Approach
Despite China’s growing challenge and recent self-inflicted damage to America’s economic and geopolitical relationships, America still retains many ingrained advantages. The U.S. still has the largest economy, the deepest public and private capital pools for promising companies and technologies, and the world’s leading universities; it has the most advanced military, continues to count most of the world’s other leading armed forces as formal treaty allies, and remains the global reserve currency. Ordinary Americans have benefited greatly from these advantages in the form of access to cutting edge products and cheaper goods that increase their effective purchasing power and quality of life – notwithstanding Secretary Bessent’s statements to the contrary.
The U.S. would be wise to leverage its privileged position in high-end innovation and in global financial markets to build “industries of the future.” However, the next economic and geopolitical paradigm must be genuinely equitable, especially to domestic communities that have been previously neglected or harmed by globalization. For these communities, policies such as the now-defunct Trade Adjustment Assistance program were too slow and too reactive to help workers displaced by the “China Shock,” which is estimated to have caused up to 2.4 million direct and indirect job losses.
Although jobs in trade-affected communities were eventually “replaced,” the jobs that came after were disproportionately lower-earning roles, accrued largely to individuals who had college degrees, and were taken by new labor force entrants rather than providing new opportunities for those who had originally been displaced. Moreover, as a result of ineffective policy responses, this replacement took over a decade and has contributed to heinous effects: look no further than the rate at which “deaths of despair” for white individuals without a college degree skyrocketed after 2000.

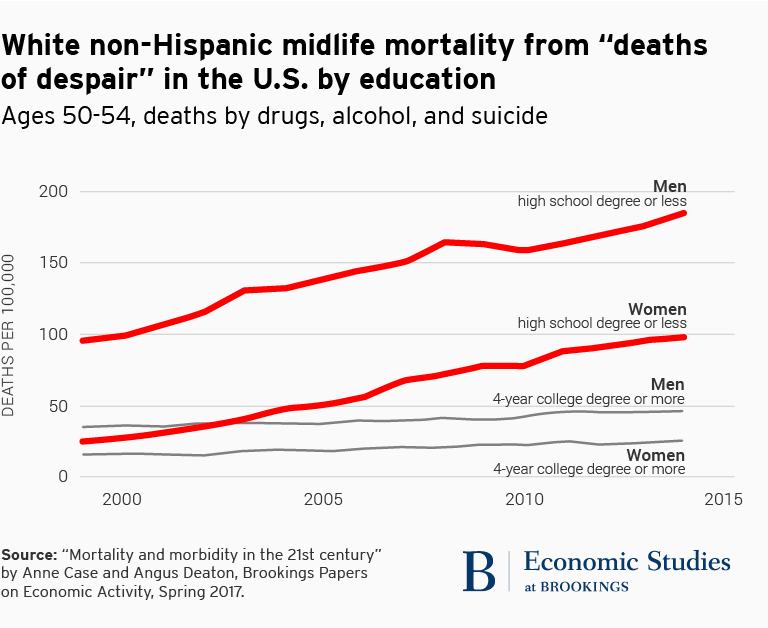
Nonetheless, surrendering America’s hard-won advantages in technology and international commerce, especially in the face of a growing challenge from China, would be an existential error. Rather, our goal is to address the shortcomings of previous policy approaches to the negative externalities caused by globalization. Previous approaches have focused on maximizing growth and redistributing the gains, but in practice, America failed to do either by underinvesting in the foundational policies that enable both. Thus, we are proposing a two-pronged approach that focuses on spurring cutting-edge technologies, growing novel industries, and enhancing production capabilities while investing in communities in a way that provides family-supporting, upwardly mobile jobs as well as critical childcare, education, housing, and healthcare services. By investing in broad-based prosperity and productivity, we can build a more equitable and dynamic economy.
Our agenda is intentionally broad (and correspondingly ambitious) rather than narrow in focus on manufacturing communities, even though current discourse is focused on trade. This is not simply a “political bargain” that provides greater welfare or lip-service concessions to hollowed-out communities in exchange for a return to the prior geoeconomic paradigm. Rather, we genuinely believe that economic dynamism which is led by an empowered middle-class worker, whether they work in manufacturing or in a service industry, is essential to America’s future prosperity and national security – one in which economic outcomes are not determined by parental income and one where black-white disparities are closed in far less than the current pace of 150+ years.

Thus, the ideas and agenda presented here are neither traditionally “liberal” nor “conservative,” “Democrat” nor “Republican.” Instead, we draw upon the intellectual traditions of both segments of the political spectrum. We agree with Ezra Klein’s and Derek Thompson’s vision in Abundance for a technology-enabled future in which America remembers how to build; at the same time, we take seriously Oren Cass’s view in The Once and Future Worker that the dignity of work is paramount and that public policy should empower the middle-class worker. What we offer in the sections below is our vision for a renewed America that crosses traditional policy boundaries to create an economic and political paradigm that works for all.
Policy Recommendations
Investing in American Innovation
Given recent trends, it is clear that there is no better time to re-invigorate America’s innovation edge by investing in R&D to create and capture “industries of the future,” re-shoring capital and expertise, and working closely with allies to expand our capabilities while safeguarding those technologies that are critical to our security. These investments will enable America to grow its economic potential, providing fertile ground for future shared prosperity. We emphasize five key components to renewing America’s technological edge and manufacturing base:
Invest in R&D. Increase federally funded R&D, which has declined from 1.8% of GDP in the 1960s to 0.6% of GDP today. Of the $200 billion federal R&D budget, just $16 billion is allocated to non-healthcare basic science, an area in which the government is better suited to fund than the private sector due to positive spillover effects from public funding. A good start is fully funding the CHIPS and Science Act, which authorized over $200 billion over 10 years for competitiveness-enhancing R&D investments that Congress has yet to appropriate. Funding these efforts will be critical to developing and winning the race for future-defining technologies, such as next-gen battery chemistries, quantum computing, and robotics, among others.
Capability-Building. Develop a coordinated mechanism for supporting translation and early commercialization of cutting-edge technologies. Otherwise, the U.S. will cede scale-up in “industries of the future” to competitors: for example, Exxon developed the lithium-ion battery, but lost commercialization to China due to the erosion of manufacturing skills in America that are belatedly being rebuilt. However, these investments are not intended to be a top-down approach that selects winners and losers: rather, America should set a coordinated list of priorities (leveraging roadmaps such as the DoD’s Critical Technology Areas), foster competition amongst many players, and then provide targeted, lightweight financial support to industry clusters and companies that bubble to the top.
Financial support could take the form of a federally-funded strategic investment fund (SIF) that partners with private sector actors by providing catalytic funding (e.g., first-loss loans). This fund would focus on bridging the financing gap in the “valley of death” as companies transition from prototype to first-of-a-kind / “nth-of-a-kind” commercial product. In contrast to previous attempts at industrial policy, such as the Inflation Reduction Act (IRA) or CHIPS Act, they should have minimal compliance burdens and focus on rapidly deploying capital to communities and organizations that have proven to possess a durable competitive advantage.
Encourage Foreign Direct Investment (FDI). Provide tax incentives and matching funds (potentially from the SIF) for companies who build manufacturing plants in America. This will bring critical expertise that domestic manufacturers can adopt, especially in industries that require deep technical expertise that America would need to redevelop (e.g., shipbuilding). By striking investment deals with foreign partners, America can “learn from the best” and subsequently improve upon them domestically. In some cases, it may be more efficient to “share” production, with certain components being manufactured or assembled abroad, while America ramps up its own capabilities.
For example, in shipbuilding, the U.S. could focus on developing propulsion, sensor, and weapon systems, while allies such as South Korea and Japan, who together build almost as much tonnage as China, convert some shipyards to defense production and send technical experts to accelerate development of American shipyards. In exchange, they would receive select additional access to cutting-edge systems and financially benefit from investing in American shipbuilding facilities and supply chains.
Immigration. America has long been described as a “nation of immigrants.” Their role in innovation is impossible to deny: 46% of companies in the Fortune 500 were founded by immigrants and accounted for 24% of all founders; they are 19% of the overall STEM workforce but account for nearly 60% of doctorates in computer science, mathematics, and engineering. Rather than spurning them, the U.S. should attract more highly educated immigrants by removing barriers to working in STEM roles and offering accelerated paths to citizenship. At the same time, American policymakers should acknowledge the challenges caused by illegal immigration. One such solution is to pass legislation such as the Border Control Act of 2024, which had bipartisan support and increased border security, supplemented by a “points-based” immigration system such as Canada’s which emphasizes educational credentials and in-country work experience.
Create Targeted Fences. Employ tariffs and export controls to defend nascent, strategically important industries such as advanced chips, fusion energy, or quantum communications. However, rather than employing these indiscriminately, tariffs and export controls should be focused on ensuring that only America and its allies have access to cutting-edge technologies that shape the global economic and security landscape. They are not intended to keep foreign competition out wholesale; rather, they should ensure that burgeoning technology developers gain sufficient scale and traction by accelerating through the “learn curve.”
Building Strong Communities
Strong communities are the foundation of a strong workforce, without which new industries will not thrive beyond a small number of established tech hubs. However, strengthening American communities will require the country to address the core needs of a family-sustaining life. Childcare, education, housing, and healthcare are among the largest budget items for families and have been proven time and again to be critical to economic mobility. Nevertheless, they are precisely the areas in which costs have skyrocketed the most, as has been frequently chronicled by the American Enterprise Institute’s “Chart of the Century.” These essential services have been underinvested in for far too long, creating painful shortages for communities that need them most. As such, addressing these issues form the core pillars of our domestic reinvestment plan. Addressing them means grappling with the underlying drivers of their cost and scarcity. These include issues of state capacity, regulatory and licensing barriers, and low productivity growth in service-heavy care sectors. A new policy agenda that addresses the fundamental supply-side issues is needed to reshape the contours of this debate.
Expand Childcare. Inadequate childcare costs the U.S. economy $122 billion in lost wages and productivity as otherwise capable workers, especially women, are forced to reduce hours or leave the labor force. Access is further exacerbated by supply shortages: more than half the population lives in a “childcare desert,” where there are more than three times as many children as licensed slots. Addressing these shortages will alleviate the affordability issue, enabling workers to stay in the workforce and allow families to move up the income ladder.
Fund Early Education. Investments in early childhood education have been demonstrated to generate compelling ROI, with high-quality studies such as the Perry preschool study demonstrating up to $7 – $12 of social return for every $1 invested. While these gains are broadly applicable across the country, they would make an even greater difference in helping to rebuild manufacturing communities by making it easier to grow and sustain families. Given the return on investment and impact on social mobility, American policymakers should consider investing in universal pre-K.
Invest in Workforce Training and Community Colleges. The cost of a four-year college education now exceeds $38K per year, indicating a clear need for cheaper BA degrees but also credible alternatives. At the same time, community colleges can be reimagined and better funded to enable them to focus on high-paying jobs in sectors with critical labor shortages, many of which are in or adjacent to “industries of the future.” Some of these roles, such as IT specialists and skilled tradespeople, are essential to manufacturing. Others, such as nursing and allied healthcare roles, will help build and sustain strong communities.
Build Housing Stock. America has a shortage of 3.2 million homes. Simply put, the country needs to build more houses to address the cost of living and enable Americans to work and raise families. While housing policy is generally decided at lower levels of government, the federal government should provide grants and other incentives to states and municipalities to defray the cost of developing affordable housing; in exchange, state and local jurisdictions should relax zoning regulations to enable more multi-family and high-density single-family housing.
Expand Healthcare Access. American healthcare is plagued with many problems, including uneven access and shortages in primary care. For example, the U.S. has 3.1 primary care physicians (PCPs) per 10,000 people, whereas Germany has 7.1 and France has 9.0. As such, the federal government should focus on expanding the number of healthcare practitioners (especially primary care physicians and nurses), building a physical presence for essential healthcare services in underserved regions, and incentivizing the development of digital care solutions that deliver affordable care.
Allocating Funds to Invest in Tomorrow’s Growth
Investment Requirements
While we view these policies as essential to America’s reinvigoration, they also represent enormous investments that must be paid for at a time when fiscal constraints are likely to tighten. To create a sense of the size of the financial requirements and trade-offs required, we lay out each of the key policy prescriptions above and use bipartisan proposals wherever possible, many of which have been scored by the Congressional Budget Office (CBO) or another reputable institution or agency. Where this is not possible, we created estimates based on key policy goals to be accomplished. Although trade deals and targeted tariffs are likely to have some budget impact, we did not evaluate them given multiple countervailing forces and political uncertainties (e.g., currency impacts).
Potential Pay-Fors
Given the budgetary requirements of these proposals, we looked for opportunities to prune the federal budget. The CBO laid out a set of budgetary options that collectively could save several trillion over the next decade. In laying out the potential pay-fors, we used two approaches that focused on streamlining mandatory spending and optimizing tax revenues in an economically efficient manner. Our first approach is to include budgetary options that eliminate unnecessary spending that are distortionary in nature or are unlikely to have a meaningful direct impact on the population that they are trying to serve (e.g., kickback payments to state health plans). Our second approach is to include budgetary options in which the burden would fall upon higher-earning populations (e.g., raising the cap on payroll and Social Security taxes).
As the table below shows, there is a menu of options available to policymakers that raise funding well in excess of the required investment amounts above, allowing them to pick and choose which are most economically efficient and politically viable. In addition, they can modify many of these options to reduce the size or magnitude of the effect of the policy (e.g., adjust the point at which Social Security benefits for “high earners” is tapered or raise capital gains by 1% instead of 2%). While some of these proposals are potentially controversial, there is a clear and pressing need to reexamine America’s foundational policy assumptions without expanding the deficit, which is already more than 6% of GDP.
Conclusion
America is in need of a new economic paradigm that renews and refreshes rather than dismantles its hard-won geopolitical and technological advantages. Trump’s tariffs, should they be fully enacted, would be a self-defeating act that would damage America’s economy while leaving it more vulnerable, not less, to rivals and adversaries. However, we also recognize that the previous free trade paradigm was not truly equitable and did not do enough to support manufacturing communities and their core strengths. We believe that our two-pronged approach of investing in American innovation alongside our allies along with critical community investments in childcare, higher education, housing, and healthcare bridges the gap and provides a framework for re-orienting the economy towards a more prosperous, fair, and secure future.
Driving Product Model Development with the Technology Modernization Fund
The Technology Modernization Fund (TMF) currently funds multiyear technology projects to help agencies improve their service delivery. However, many agencies abdicate responsibility for project outcomes to vendors, lacking the internal leadership and project development teams necessary to apply a product model approach focused on user needs, starting small, learning what works, and making adjustments as needed.
To promote better outcomes, TMF could make three key changes to help agencies shift from simply purchasing static software to acquiring ongoing capabilities that can meet their long-term mission needs: (1) provide education and training to help agencies adopt the product model; (2) evaluate investments based on their use of effective product management and development practices; and (3) fund the staff necessary to deliver true modernization capacity.
Challenge and Opportunity
Technology modernization is a continual process of addressing unmet needs, not a one-time effort with a defined start and end. Too often, when agencies attempt to modernize, they purchase “static” software, treating it like any other commodity, such as computers or cars. But software is fundamentally different. It must continuously evolve to keep up with changing policies, security demands, and customer needs.
Presently, agencies tend to rely on available procurement, contracting, and project management staff to lead technology projects. However, it is not enough to focus on the art of getting things done (project management); it is also critically important to understand the art of deciding what to do (product management). A product manager is empowered to make real-time decisions on priorities and features, including deciding what not to do, to ensure the final product effectively meets user needs. Without this role, development teams typically march through a vast, undifferentiated, unprioritized list of requirements, which is how information technology (IT) projects result in unwieldy failures.
By contrast, the product model fosters a continuous cycle of improvement, essential for effective technology modernization. It empowers a small initial team with the right skills to conduct discovery sprints, engage users from the outset and throughout the process, and continuously develop, improve, and deliver value. This approach is ultimately more cost effective, results in continuously updated and effective software, and better meets user needs.
However, transitioning to the product model is challenging. Agencies need more than just infrastructure and tools to support seamless deployment and continuous software updates – they also need the right people and training. A lean team of product managers, user researchers, and service designers who will shape the effort from the outset can have an enormous impact on reducing costs and improving the effectiveness of eventual vendor contracts. Program and agency leaders, who truly understand the policy and operational context, may also require training to serve effectively as “product owners.” In this role, they work closely with experienced product managers to craft and bring to life a compelling product vision.
These internal capacity investments are not expensive relative to the cost of traditional IT projects in government, but they are currently hard to make. Placing greater emphasis on building internal product management capacity will enable the government to more effectively tackle the root causes that lead to legacy systems becoming problematic in the first place. By developing this capacity, agencies can avoid future costly and ineffective “modernization” efforts.
Plan of Action
The General Services Administration’s Technology Modernization Fund plays a crucial role in helping government agencies transition from outdated legacy systems to modern, secure, and efficient technologies, strengthening the government’s ability to serve the public. However, changes to TMF’s strategy, policy, and practice could incentivize the broader adoption of product model approaches and make its investments more impactful.
The TMF should shift from investments in high-cost, static technologies that will not evolve to meet future needs towards supporting the development of product model capabilities within agencies. This requires a combination of skilled personnel, technology, and user-centered approaches. Success should be measured not just by direct savings in technology but by broader efficiencies, such as improvements in operational effectiveness, reductions in administrative burdens, and enhanced service delivery to users.
While successful investments may result in lower costs, the primary goal should be to deliver greater value by helping agencies better fulfill their missions. Ultimately, these changes will strengthen agency resilience, enabling them to adapt, scale, and respond more effectively to new challenges and conditions.
Recommendation 1. The Technology Modernization Board, responsible for evaluating proposals, should:
- Assess future investments based on the applicant’s demonstrated competencies and capacities in product ownership and management, as well as their commitment to developing these capabilities. This includes assessing proposed staffing models to ensure the right teams are in place.
- Expand assessment criteria for active and completed projects beyond cost savings, to include measurements of improved mission delivery, operational efficiencies, resilience, and adaptability.
Recommendation 2. The TMF Program Management Office, responsible for stewarding investments from start to finish, should:
- Educate and train agencies applying for funds on how to adopt and sustain the product model.
- Work with the General Services Administration’s 18F to incorporate TMF project successes and lessons learned into a continuously updated product model playbook for government agencies that includes guidance on the key roles and responsibilities needed to successfully own and manage products in government.
- Collaborate with the Office of Personnel Management (OPM) to ensure that agencies have efficient and expedited pathways for acquiring the necessary talent, utilizing appropriate assessments to identify and onboard skilled individuals.
Recommendation 3. Congress should:
- Encourage agencies to set up their own working capital funds under the authorities outlined in the TMF legislation.
- Explore the barriers to product model funding in the current budgeting and appropriations processes for the federal government as a whole and develop proposals for fitting them to purpose.
- Direct OPM to reduce procedural barriers that hinder swift and effective hiring.
Conclusion
The TMF should leverage its mandate to shift agencies towards a capabilities-first mindset. Changing how the program educates, funds, and assesses agencies will build internal capacity and deliver continuous improvement. This approach will lead to better outcomes, both in the near and long terms, by empowering agencies to adapt and evolve their capabilities to meet future challenges effectively.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
Congress established TMF in 2018 “to improve information technology, and to enhance cybersecurity across the federal government” through multiyear technology projects. Since then, more than $1 billion has been invested through the fund across dozens of federal agencies in four priority areas.
White House Issues a “National” Science & Tech Agenda
A new White House budget memo presents science and technology as a distinctly American-led enterprise in which U.S. dominance is to be maintained and reinforced. The document is silent on the possibility or the necessity of international scientific cooperation.
“The five R&D budgetary priorities in this memorandum ensure that America remains at the forefront of scientific progress, national and economic security, and personal wellbeing, while continuing to serve as the standard-bearer for today’s emerging technologies and Industries of the Future,” wrote Acting OMB Director Russell T. Vought and White House science advisor Dr. Kelvin K. Droegemeier in the August 30 memo.
The document, which is intended to inform executive branch budget planning for fiscal year 2021, contains no acknowledgment that many scientific challenges are global in scope, that foreign countries lead the U.S. in some areas of science and technology, or that the U.S. could actually benefit from international collaboration.
* * *
The White House memo begins by designating the entire post-World War II period until now as America’s “First Bold Era in S&T [Science & Technology].” It goes on to proclaim that the “Second Bold Era in S&T” has now begun under President Trump.
“The Trump Administration continues to prioritize the technologies that power Industries of the Future (IotF),” the memo declares.
Many of the proposed technology priorities are already in progress — including artificial intelligence, robotics, and gene therapy. Some are controversial or disputed — such as the purported need to invest in protection against electromagnetic pulse attacks.
Meanwhile, the memo takes pains to avoid even mentioning the term “climate change,” which is disfavored by this White House. Instead, it speaks of “Earth system predictability” and “knowing the extent to which components of the Earth system are practically predictable.”
Today’s Second Bold Era is “characterized by unprecedented knowledge, access to data and computing resources, ubiquitous and instant communication,” and so on. “Unfortunately, this Second Bold Era also features new and extraordinary threats which must be confronted thoughtfully and effectively.”
The White House guidance suggests vaguely that the Second Bold Era could require a recalibration of secrecy policy in science and technology. “[Success] will depend upon striking a balance between the openness of our research ecosystem and the protection of our ideas and research outcomes.”
This may or may not augur a change in the longstanding policy of openness in basic research that was formally adopted in President Reagan’s 1985 National Security Decision Directive 189. That directive stated that “It is the policy of this Administration that, to the maximum extent possible, the products of fundamental research remain unrestricted.”
* * *
The context for the concern about protecting U.S. ideas and research outcomes is an assessment that U.S. intellectual property is being aggressively targeted and illicitly acquired by China, among other countries.
“China has expansive efforts in place to acquire U.S. technology to include sensitive trade secrets and proprietary information,” according to a 2018 report from the National Counterintelligence and Security Center. “Chinese companies and individuals often acquire U.S. technology for commercial and scientific purposes.”
Perceived Chinese theft of U.S. intellectual property is one of the factors that led to imposition of U.S. tariffs on Chinese imports. See U.S.-China Relations, Congressional Research Service, August 29, 2019.
* * *
At an August 30 briefing on artificial intelligence in the Department of Defense, Air Force Lt. General Jack Shanahan discussed the need to protect military data in the context of AI.
But unlike the new White House memo, Gen. Shanahan recognized the need for international cooperation even (or especially) in national security matters:
“We’re very interested in actively engaging a number of international partners,” he said, “because if you envision a future of which the United States is employing A.I. in its military capabilities and other nations are not, what does that future look like? Does the commander trust one and not the other?”
By analogy, however, the same need for international collaboration arises in many other areas of science and technology which cannot be effectively addressed solely on a national basis, from mitigating climate change to combating disease. In such cases, everyone needs to be “at the forefront” together.
* * *
One way to bolster U.S. scientific and intellectual leadership that the White House memo does not contemplate is to encourage foreign students at American universities to remain in this country. Too often, they are discouraged from doing so, wrote Columbia University Lee C. Bollinger in the Washington Post.
“Many of these international scholars, especially in the fields of science, technology, engineering and mathematics, would, if permitted, prefer to remain in the United States and work for U.S.-based companies after graduation, where they could also contribute to the United States’ economic growth and prosperity. But under the present rules, when their academic studies are completed, we make it difficult for them to stay. They return to their countries with the extraordinary knowledge they acquired here, which can inform future commercial strategies deployed against U.S. competitors,” Bollinger wrote on August 30.
* * *
As for the Trump Administration’s pending FY2020 budget request for research and development, it does not convey much in the way of boldness (or Boldness).
“Under the President’s FY2020 budget request, most federal agencies would see their R&D funding decline. The primary exception is the Department of Defense,” according to the Congressional Research Service.
“The President’s FY2020 budget request would reduce funding for basic research by $1.5 billion (4.0%), applied research by $4.3 billion (10.5%), and facilities and equipment by $0.5 billion (12.8%), while increasing funding for development by $4.5 billion (8.3%).” See Federal Research and Development (R&D) Funding: FY2020, updated August 13, 2019.
Navy Torpedoes Scientific Advisory Group
This week the U.S. Navy abruptly terminated its own scientific advisory group, depriving the service of a source of internal critique and evaluation.
The Naval Research Advisory Committee (NRAC) was established by legislation in 1946 and provided science and technology advice to the Navy for the past 73 years. Now it’s gone.
The decision to disestablish the Committee was announced in a March 29 Federal Register notice, which did not provide any justification for eliminating it. Phone and email messages to the office of the Secretary of the Navy seeking more information were not returned.
“I think it’s a shortsighted move,” said one Navy official, who was not part of the decisionmaking process.
This official said that the Committee had been made vulnerable by an earlier effort to reduce the number of Navy advisory committees. Instead of remaining an independent entity, the NRAC was redesignated as a sub-committee of the Secretary of the Navy Advisory Panel, which provides policy advice to the Secretary. It was a poor fit for the NRAC technologists, the official said, since they don’t do policy and were thus “misaligned.” When the Secretary decided to eliminate the Panel, the NRAC was swept away with it.
Did the NRAC do or say something in particular to trigger the Navy’s wrath? If so, it’s unclear what that might have been. “This is the most highly professional crew I’ve seen,” the Navy official said. “They stay between the lines.”
The NRAC was the Navy counterpart to the Army Science Board and the Air Force Scientific Advisory Board. It has no obvious replacement.
“This will leave the Navy without an independent and objective technical advisory body, which is not in the best interests of the Navy or the nation,” said a Navy scientist.
According to the NRAC website (which is still online for now), “The Naval Research Advisory Committee (NRAC) is an independent civilian scientific advisory group dedicated to providing objective analyses in the areas of science, research and development. By its recommendations, the NRAC calls attention to important issues and presents Navy management with alternative courses of action.”
Its mission was “To know the problems of the Navy and Marine Corps, keep abreast of the current research and development programs, and provide an independent, objective assessment capability through investigative studies.”
A 2017 report on Autonomous and Unmanned Systems in the Department of the Navy appears to be the NRAC’s most recent unclassified published report.
Under Secretary of the Navy Thomas B. Modly ordered disestablishment of the NRAC in a 21 February 2019 memo.
“This was a sudden and unexpected move according to people I know,” said the Navy scientist. “I have not yet seen an explanation for its termination.”
A Profile of Defense Science & Tech Spending
Annual spending on defense science and technology has “grown substantially” over the past four decades from $2.3 billion in FY1978 to $13.4 billion in FY2018 or by nearly 90% in constant dollars, according to a new report from the Congressional Research Service.
Defense science and technology refers to the early stages of military research and development, including basic research (known by its budget code 6.1), applied research (6.2) and advanced technology development (6.3).
“While there is little direct opposition to Defense S&T spending in its own right,” the CRS report says, “there is intense competition for available dollars in the appropriations process,” such that sustained R&D spending is never guaranteed.
Still, “some have questioned the effectiveness of defense investments in R&D.”
CRS takes note of a 2012 article published by the Center for American Progress which argued that military spending was an inefficient way to spur innovation and that the growing sophistication of military technology was poorly suited to meet some low-tech threats such as improvised explosive devices (IEDs) in Iraq and Afghanistan (as discussed in an earlier article in the Bulletin of the Atomic Scientists).
The new CRS report presents an overview of the defense science and tech budget, its role in national defense, and questions about its proper size and proportion. See Defense Science and Technology Funding, February 21, 2018,
Other new and updated reports from the Congressional Research Service include the following.
Armed Conflict in Syria: Overview and U.S. Response, updated February 16, 2018
Jordan: Background and U.S. Relations, updated February 16, 2018
Bahrain: Reform, Security, and U.S. Policy, updated February 15, 2018
Potential Options for Electric Power Resiliency in the U.S. Virgin Islands, February 14, 2018
U.S. Manufacturing in International Perspective, updated February 21, 2018
Methane and Other Air Pollution Issues in Natural Gas Systems, updated February 15, 2018
Where Can Corporations Be Sued for Patent Infringement? Part I, CRS Legal Sidebar, February 20, 2018
How Broad A Shield? A Brief Overview of Section 230 of the Communications Decency Act, CRS Legal Sidebar, February 21, 2018
Russians Indicted for Online Election Trolling, CRS Legal Sidebar, February 21, 2018
Hunting and Fishing on Federal Lands and Waters: Overview and Issues for Congress, February 14, 2018
US-China Scientific Cooperation “Mutually Beneficial”
The US and China have successfully carried out a wide range of cooperative science and technology projects in recent years, the State Department told Congress last year in a newly released report.
Joint programs between government agencies on topics ranging from pest control to elephant conservation to clean energy evidently worked to the benefit of both countries.
“Science and technology engagement with the United States continues to be highly valued by the Chinese government,” the report said.
At the same time, “Cooperative activities also accelerated scientific progress in the United States and provided significant direct benefit to a range of U.S. technical agencies.”
The 2016 biennial report to Congress, released last week under the Freedom of Information Act, describes programs that were ongoing in 2014-2015.
See Implementation of Agreement between the United States and China on Science and Technology, report to Congress, US Department of State, April 2016.
Science & Technology Issues Facing Congress, & More from CRS
Science and technology policy issues that may soon come before Congress were surveyed in a new report from the Congressional Research Service.
Overarching issues include the impact of recent reductions in federal spending for research and development.
“Concerns about reductions in federal R&D funding have been exacerbated by increases in the R&D investments of other nations (China, in particular); globalization of R&D and manufacturing activities; and trade deficits in advanced technology products, an area in which the United States previously ran trade surpluses. At the same time, some Members of Congress have expressed concerns about the level of federal funding in light of the current federal fiscal condition. In addition, R&D funding decisions may be affected by differing perspectives on the appropriate role of the federal government in advancing science and technology.”
See Science and Technology Issues in the 115th Congress, March 14, 2017.
Other new and updated reports from the Congressional Research Service include the following.
The American Health Care Act, March 14, 2017
Previewing a 2018 Farm Bill, March 15, 2017
EPA Policies Concerning Integrated Planning and Affordability of Water Infrastructure, updated March 14, 2017
National Park Service: FY2017 Appropriations and Ten-Year Trends, updated March 14, 2017
Qatar: Governance, Security, and U.S. Policy, updated March 15, 2017
Northern Ireland: Current Issues and Ongoing Challenges in the Peace Process, updated March 14, 2017
Navy LX(R) Amphibious Ship Program: Background and Issues for Congress, updated March 14, 2017
Under Pressure: Long Duration Undersea Research
“The Office of Naval Research is conducting groundbreaking research into the dangers of working for prolonged periods of time in extreme high and low pressure environments.”
Why? In part, it reflects “the increased operational focus being placed on undersea clandestine operations,” said Rear Adm. Mathias W. Winter in newly published answers to questions for the record from a February 2016 hearing.
“The missions include deep dives to work on the ocean floor, clandestine transits in cold, dark waters, and long durations in the confines of the submarine. The Undersea Medicine Program comprises the science and technology efforts to overcome human shortfalls in operating in this extreme environment,” he told the House Armed Services Committee.
See DoD FY2017 Science and Technology Programs: Defense Innovation to Create the Future Military Force, House Armed Services Committee hearing, February 24, 2016.
Patents Granted to Two Formerly Secret Inventions
Two patent applications that had been subject to “secrecy orders” under the Invention Secrecy Act for years or decades were finally granted patents and publicly disclosed in 2016.
“Only two patents have been granted so far on cases in which the secrecy order was rescinded in FY16,” the US Patent and Trademark Office said this week in response to a Freedom of Information Act request. They were among the 20 inventions whose secrecy orders were rescinded over the past year.
One of the patents concerns “a controllable barrier layer against electromagnetic radiation, to be used, inter alia, as a radome for a radar antenna for instance.” The inventor, Anders Grop of Sweden, filed the patent application in 2007 and it was granted on April 5, 2016 (patent number 9,306,290).
The other formerly secret invention that finally received a patent this year described “multi-charge munitions, incorporating hole-boring charge assemblies.” Detonation of the munitions is “suitable for defeating a concrete target.” That invention was originally filed in 1990 by Kevin Mark Powell and Edward Evans of the United Kingdom and was granted on October 25, 2016 (patent number 9,476,682).
The inventors could not immediately be contacted for comment. But judging from appearances, the decision to control the disclosure of these two inventions for a period of time and then to grant them a patent was consistent with the terms of the Invention Secrecy Act, and it had no obvious adverse impacts.