
This article was written as a part of the FRO Forecasting project, a partnership between the Federation of American Scientists and Metaculus. This project aims to conduct a pilot study of forecasting as an approach for assessing the scientific and societal value of proposals for Focused Research Organizations. To learn more about the project, see the press release here. To participate in the pilot, you can access the public forecasting tournament here.
The United States federal government is the single largest funder of scientific research in the world. Thus, the way that science agencies like the National Science Foundation and the National Institutes of Health distribute research funding has a significant impact on the trajectory of science as a whole. Peer review is considered the gold standard for evaluating the merit of scientific research proposals, and agencies rely on peer review committees to help determine which proposals to fund. However, peer review has its own challenges. It is a difficult task to balance science agencies’ dual mission of protecting government funding from being spent on overly risky investments while also being ambitious in funding proposals that will push the frontiers of science, and research suggests that peer review may be designed more for the former rather than the latter. We at FAS are exploring innovative approaches to peer review to help tackle this challenge.
Biases in Peer Review
A frequently echoed concern across the scientific and metascientific community is that funding agencies’ current approach to peer review of science proposals tends to be overly risk-averse, leading to bias against proposals that entail high risk or high uncertainty about the outcomes. Reasons for this conservativeness include reviewer preferences for feasibility over potential impact, contagious negativity, and problems with the way that peer review scores are averaged together.
This concern, alongside studies suggesting that scientific progress is slowing down, has led to a renewed effort to experiment with new ways of conducting peer review, such as golden tickets and lottery mechanisms. While golden tickets and lottery mechanisms aim to complement traditional peer review with alternate means of making funding decisions — namely individual discretion and randomness, respectively — they don’t fundamentally change the way that peer review itself is conducted.
Traditional peer review asks reviewers to assess research proposals based on a rubric of several criteria, which typically include potential value, novelty, feasibility, expertise, and resources. These criteria are given a score based on a numerical scale; for example, the National Institutes of Health uses a scale from 1 (best) to 9 (worst). Reviewers then provide an overall score that need not be calculated in any specific way based on the criteria scores. Next, all of the reviewers convene to discuss the proposal and submit their final overall scores, which may be different from what they submitted prior to the discussion. The final overall scores are averaged across all of the reviewers for a specific proposal. Proposals are then ranked based on their average overall score and funding is prioritized for those ranked before a certain cutoff score, though depending on the agency, some discretion by program administrators is permitted.
The way that this process is designed allows for the biases mentioned at the beginning—reviewer preferences for feasibility, contagious negativity, and averaging problems—to influence funding decisions. First, reviewer discretion in deciding overall scores allows them to weigh feasibility more heavily than potential impact and novelty in their final scores. Second, when evaluations are discussed reviewers tend to adjust their scores to better align with their peers. This adjustment tends to be greater when correcting in the negative direction than in the positive direction, resulting in a stronger negative bias. Lastly, since funding tends to be quite limited, cutoff scores tend to be quite close to the best score. This means that even if almost all of the reviewers rate a proposal positively, one very negative review can potentially bring the average below the cutoff.
Designing a New Approach to Peer Review
In 2021, the researchers Chiara Franzoni and Paula Stephan published a working paper arguing that risk in science results from three sources of uncertainty: uncertainty of research outcomes, uncertainty of the probability of success, and uncertainty of the value of the research outcomes. To comprehensively and consistently account for these sources of uncertainty, they proposed a new expected utility approach to peer review evaluations, in which reviewers are asked to
- Identify the primary expected outcome of a research proposal and, optionally, a potential secondary outcome;
- Assess the probability between 0 to 1 of achieving each expected outcome (P(j); and
- Assess the value of achieving each expected outcome (uj) on a numerical scale (e.g., 0 to 100).
From this, the total expected utility can be calculated for each proposal and used to rank them.1 This systematic approach addresses the first bias we discussed by limiting the extent to which reviewers’ preferences for more feasible proposals would impact the final score of each proposal.
We at FAS see a lot of potential in Franzoni and Stephan’s expected value approach to peer review, and it inspired us to design a pilot study using a similar approach that aims to chip away at the other biases in review.
To explore potential solutions for negativity bias, we are taking a cue from forecasting by complementing the peer review process with a resolution and scoring process. This means that at a set time in the future, reviewers’ assessments will be compared to a ground truth based on the actual events that have occurred (i.e., was the outcome actually achieved and, if so, what was its actual impact?). Our theory is that if implemented in peer review, resolution and scoring could incentivize reviewers to make better, more accurate predictions over time and provide empirical estimates of a committee’s tendency to provide overly negative (or positive) assessments, thus potentially countering the effects of contagion during review panels and helping more ambitious proposals secure support.
Additionally, we sought to design a new numerical scale for assessing the value or impact of a research proposal, which we call an impact score. Typically, peer reviewers are free to interpret the numerical scale for each criteria as they wish; Franzoni and Stephan’s design also did not specify how the numerical scale for the value of the research outcome should work. We decided to use a scale ranging from 1 (low) to 10 (high) that was base 2 exponential, meaning that a proposal that receives a score of 5 has double the impact of a proposal that receives a score of 4, and quadruple the impact of a proposal that receives a score of 3.
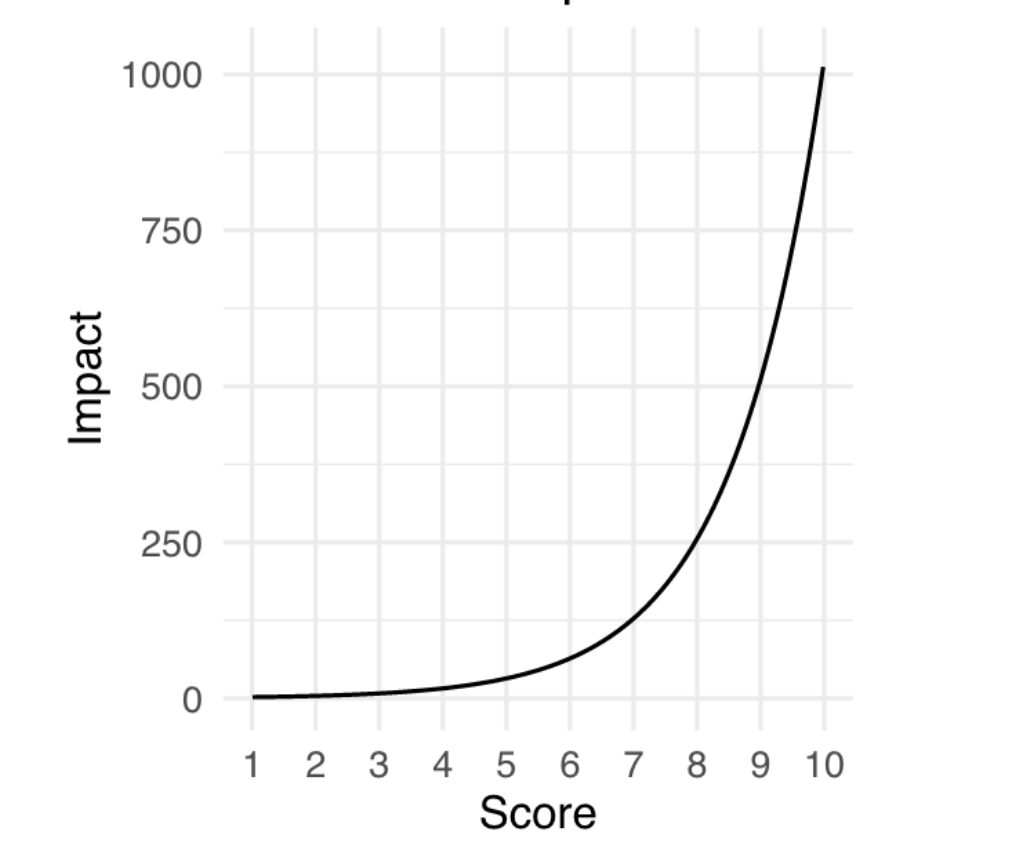
The choice of an exponential scale reflects the tendency in science for a small number of research projects to have an outsized impact (Figure 2), and provides more room at the top end of the scale for reviewers to increase the rating of the proposals that they believe will have an exceptional impact. We believe that this could help address the last bias we discussed, which is that currently, bad scores are more likely to pull a proposal’s average below the cutoff than good scores are likely to pull a proposal’s average above the cutoff.
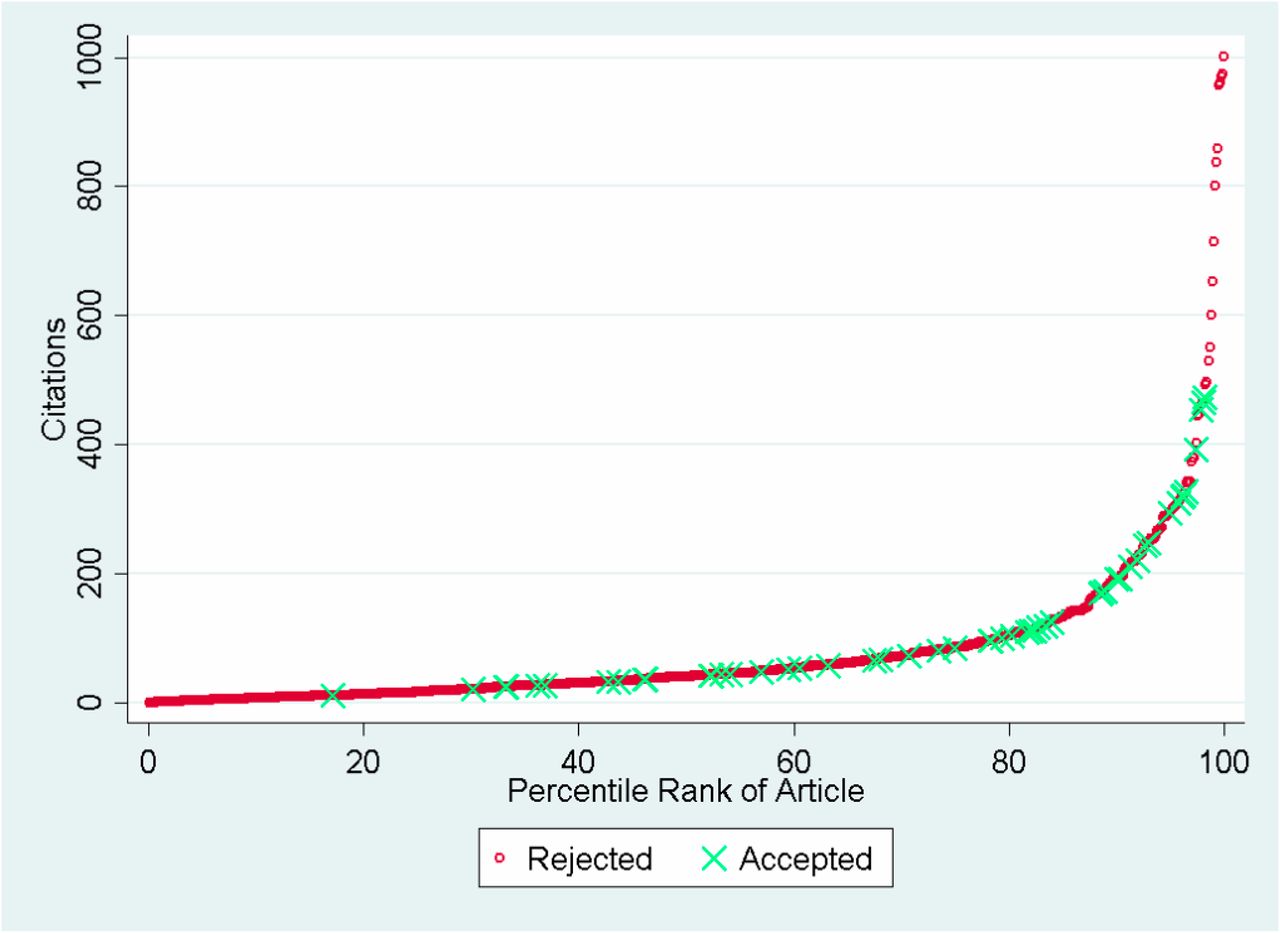
Source: Siler, Lee, and Bero (2014)
We are now piloting this approach on a series of proposals in the life sciences that we have collected for Focused Research Organizations, a new type of non-profit research organization designed to tackle challenges that neither academia or industry is incentivized to work on. The pilot study was developed in collaboration with Metaculus, a forecasting platform and aggregator, and will be hosted on their website. We welcome subject matter experts in the life sciences — or anyone interested! — to participate in making forecasts on these proposals here. Stay tuned for the results of this pilot, which we will publish in a report early next year.
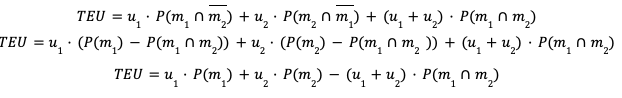
As Congress considers broader packages to advance critical minerals production and supply chain resilience, science diplomacy vehicles must be part of that conversation, not as an afterthought, but as an intentional and foundational pillar of any strategy.
“Structured partnerships with our allies on critical minerals innovation can ensure that the best science and the best talent are working together towards shared security and economic prosperity.”
This is a bipartisan, commonsense measure to reauthorize the Technology Modernization Fund (TMF) before it expires in September 2026.
Many states are introducing AI policies and task forces, but lack the “AI-native” personnel to build and maintain initiatives. To address this in the short term, states should establish AI Resilience Cohorts to embed early-career technologists in key offices to support state AI initiatives. Right now, Virginia and New Jersey have the opportunity to take […]