Science & Technology Funding Uncertainty Impacts Regular People, Too
The Federation of American Scientists urges the U.S. government to release holds on Congressionally-appropriated funding for scientific research, education, and critical activities at the earliest possible time. This includes removing new or additional administrative processes that create additional layers of review and approval for federal funding opportunities, consistent with the Administration’s stated commitment to reduce administrative overhead in science and technology.
Funding disruptions and delays can create additional uncertainty for scientific programs, forcing individuals to change plans, cancel work, or seek other opportunities. According to a recent survey published by STAT:
- 23% of laboratories funded by NIH have laid off staff and rescinded offers made to graduate students as a result of funding changes, threatening the viability of the country’s talent pipeline (especially impacting women scientists and scientists from marginalized communities, and early career researchers);
- 68% reported their institutions increased administrative processes for spending and hiring as a result of federal policy changes, despite the government’s commitment to relieve administrative burden;
- 43% of researchers canceled planned research;
- 54% of researchers reduced the scope of their research, diminishing the impact and efficiency of their work;
- 56% redirected funding from other projects; and
- 53% of researchers advised their students to consider opportunities outside the United States.
When the economic dynamics of any industry change, those with the talent and ability to change direction are often the first to do so. We are already seeing increasing competition for international funding opportunities from American scientists. The prestigious European Research Council, whose grants are awarded if researchers agree to establish their team in Europe, has seen a fourfold increase in applications from Americans for the program’s Advanced Grants. Last year, a survey by Nature suggested that 75% of American researchers were considering moving overseas.
Changes in the viability of proposals as a result of funding delays and lengthy approval processes also wastes the government’s time and money, forcing program officers to reevaluate proposals, often under new direction, when projects being considered for funding are no longer considered viable.
What seem like esoteric considerations that impact only a small fraction of the population is, in fact, a much larger concern: historically, funding for science and technology has significant ripple effects that boost the American economy and offer real solutions that improve people’s daily lives. If the National Institutes of Health expenditure is limited to that provided in the Fiscal Year 2026 President’s Budget Request, the projected economic impact would cost the U.S. economy approximately 46 billion dollars and over 200,000 jobs (not including NIH jobs already terminated). Cuts to research-performing agencies can lead to losses of capacity, reduced ability to develop and deploy critical and emerging technologies, and diminished capability to maintain datasets that are essential for the functioning of the American economy, as noted in FAS’s ongoing “Dearly Departed Datasets” project.
“Recapturing the urgency that propelled us so far in the last century”, as the President’s letter to OSTP Director Michael Kratsios directs, requires approaching our changing competitive landscape, including federal support for science and technology, with the same level of urgency.
At FAS, we believe that collaboration produces the strongest policy solutions in pursuit of a government that delivers real results for the American people. This includes engaging directly with key stakeholders across the S&T ecosystem who are deeply connected to, impacted by or implicated in federal policymaking decisions around S&T funding and infrastructure. We also engage directly with members of the public who may have ideas or input about the impact of changes to the structure and level of the federal S&T ecosystem, but may not be in a position to directly impact it.
If you are interested in this topic, want to offer your perspective, or have ideas for policy solutions to this challenge, we invite you to connect with our team by responding to our open call.
Bringing Transparency to Federal R&D Infrastructure Costs
There is an urgent need to manage the escalating costs of federal R&D infrastructure and the increasing risk that failing facilities pose to the scientific missions of the federal research enterprise. Many of the laboratories and research support facilities operating under the federal research umbrella are near or beyond their life expectancy, creating significant safety hazards for federal workers and local communities. Unfortunately, the nature of the federal budget process forces agencies into a position where the actual cost of operations are not transparent in agency budget requests to OMB before becoming further obscured to appropriators, leading to potential appropriations disasters (including an approximately 60% cut to National Institute of Standards and Technology (NIST) facilities in 2024 after the agency’s challenges became newsworthy). Providing both Congress and OMB with a complete accounting of the actual costs of agency facilities may break the gamification of budget requests and help the government prioritize infrastructure investments.
Challenge and Opportunity
Recent reports by the National Research Council and the National Science and Technology Council, including the congressionally-mandated Quadrennial Science and Technology Review have highlighted the dire state of federal facilities. Maintenance backlogs have ballooned in recent years, forcing some agencies to shut down research activities in strategic R&D domains including Antarctic research and standards development. At NIST, facilities outages due to failing steam pipes, electricity, and black mold have led to outages reducing research productivity from 10-40 percent. NASA and NIST have both reported their maintenance backlogs have increased to exceed 3 billion dollars. The Department of Defense forecasts that bringing their buildings up to modern standards would cost approximately 7 billion “putting the military at risk of losing its technological superiority.” The shutdown of many Antarctic science operations and collapse of the Arecibo Observatory have been placed in stark contrast with the People’s Republic of China opening rival and more capable facilities in both research domains. In the late 2010s, Senate staffers were often forced to call national laboratories, directly, to ask them what it would actually cost for the country to fully fund a particular large science activity.
This memo does not suggest that the government should continue to fund old or outdated facilities; merely that there is a significant opportunity for appropriators to understand the actual cost of our legacy research and development ecosystem, initially ramped up during the Cold War. Agencies should be able to provide a straight answer to Congress about what it would cost to operate their inventory of facilities. Likewise, Congress should be able to decide which facilities should be kept open, where placing a facility on life support is acceptable, and which facilities should be shut down. The cost of maintaining facilities should also be transparent to the Office of Management and Budget so examiners can help the President make prudent decisions about the direction of the federal budget.
The National Science and Technology Council’s mandated research and development infrastructure report to Congress is a poor delivery vehicle. As coauthors of the 2024 research infrastructure report, we can attest to the pressure that exists within the White House to provide a positive narrative about the current state of play as well as OMB’s reluctance to suggest additional funding is needed to maintain our inventory of facilities outside the budget process. It would be much easier for agencies who already have a sense of what it costs to maintain their operations to provide that information directly to appropriators (as opposed to a sanitized White House report to an authorizing committee that may or may not have jurisdiction over all the agencies covered in the report)–assuming that there is even an Assistant Director for Research Infrastructure serving in OSTP to complete the America COMPETES mandate. Current government employees suggest that the Trump Administration intends to discontinue the Research and Development Infrastructure Subcommittee.
Agencies may be concerned that providing such cost transparency to Congress could result in greater micromanagement over which facilities receive which investments. Given the relevance of these facilities to their localities (including both economic benefits and environmental and safety concerns) and the role that legacy facilities can play in training new generations of scientists, this is a matter that deserves public debate. In our experience, the wider range of factors considered by appropriation staff are relevant to investment decisions. Further, accountability for macro-level budget decisions should ultimately fall on decisionmakers who choose whether or not to prioritize investments in both our scientific leadership and the health and safety of the federal workforce and nearby communities. Facilities managers who are forced to make agonizing choices in extremely resource-constrained environments currently bear most of that burden.
Plan of Action
Recommendation 1: Appropriations committees should require from agencies annual reports on the actual cost of completed facilities modernization, operations, and maintenance, including utility distribution systems.
Transparency is the only way that Congress and OMB can get a grip on the actual cost of running our legacy research infrastructure. This should be done by annual reporting to the relevant appropriators the actual cost of facilities operations and maintenance. Other costs that should be accounted for include obligations to international facilities (such as ITER) and facilities and collections that are paid for by grants (such as scientific collections which support the bioeconomy). Transparent accounting of facilities costs against what an administration chooses to prioritize in the annual President’s Budget Request may help foster meaningful dialogue between agencies, examiners, and appropriations staff.
The reports from agencies should describe the work done in each building and impact of disruption. Using the NIST as an example, the Radiation Physics Building (still without the funding to complete its renovation) is crucial to national security and the medical community. If it were to go down (or away), every medical device in the United States that uses radiation would be decertified within 6 months, creating a significant single point of failure that cannot be quickly mitigated. The identification of such functions may also enable identification of duplicate efforts across agencies.
The costs of utility systems should be included because of the broad impacts that supporting infrastructure failures can have on facility operations. At NIST’s headquarters campus in Maryland, the entire underground utility distribution system is beyond its designed lifespan and suffering nonstop issues. The Central Utility Plant (CUP), which creates steam and chilled water for the campus, is in a similar state. The CUP’s steam distribution system will be at the complete end of life (per forensic testing of failed pipes and components) in less than a decade and potentially as soon as 2030. If work doesn’t start within the next year (by early 2026), it is likely the system could go down. This would result in a complete loss of heat and temperature control on the campus; particularly concerning given the sensitivity of modern experiments and calibrations to changes in heat and humidity. Less than a decade ago, NASA was forced to delay the launch of a satellite after NIST’s steam system was down for a few weeks and calibrations required for the satellite couldn’t be completed.
Given the varying business models for infrastructure around the Federal government, standardization of accounting and costs may be too great a lift–particularly for agencies that own and operate their own facilities (government owned, government operated, or GOGOs) compared with federally funded research and development centers (FFRDCs) operated by companies and universities (government owned, contractor operated, or GOCOs).
These reports should privilege modernization efforts, which according to former federal facilities managers should help account for 80-90 percent of facility revitalization, while also delivering new capabilities that help our national labs maintain (and often re-establish) their world-leading status. It would also serve as a potential facilities inventory, allowing appropriators the ability to de-conflict investments as necessary.
It would be far easier for agencies to simply provide an itemized list of each of their facilities, current maintenance backlog, and projected costs for the next fiscal year to both Congress and OMB at the time of annual budget submission to OMB. This should include the total cost of operating facilities, projected maintenance costs, any costs needed to bring a federal facility up to relevant safety and environmental codes (many are not). In order to foster public trust, these reports should include an assessment of systems that are particularly at risk of failure, the risk to the agency’s operations, and their impact on surrounding communities, federal workers, and organizations that use those laboratories. Fatalities and incidents that affect local communities, particularly in laboratories intended to improve public safety, are not an acceptable cost of doing business. These reports should be made public (except for those details necessary to preserve classified activities).
Recommendation 2: Congress should revisit the idea of a special building fund from the General Services Administration (GSA) from which agencies can draw loans for revitalization.
During the first Trump Administration, Congress considered the establishment of a special building fund from the GSA from which agencies could draw loans at very low interest (covering the staff time of GSA officials managing the program). This could allow agencies the ability to address urgent or emergency needs that happen out of the regular appropriations cycle. This approach has already been validated by the Government Accountability Office for certain facilities, who found that “Access to full, upfront funding for large federal capital projects—whether acquisition, construction, or renovation—could save time and money.” Major international scientific organizations that operate large facilities, including CERN (the European Organization for Nuclear Research), have similar ability to take loans to pay for repairs, maintenance, or budget shortfalls that helps them maintain financial stability and reduce the risk of escalating costs as a result of deferred maintenance.
Up-front funding for major projects enabled by access to GSA loans can also reduce expenditures in the long run. In the current budget environment, it is not uncommon for the cost of major investments to double due to inflation and doing the projects piecemeal. In 2010, NIST proposed a renovation of its facilities in Boulder with an expected cost of $76 million. The project, which is still not completed today, is now estimated to cost more than $450 million due to a phased approach unsupported by appropriations. Productivity losses as a result of delayed construction (or a need to wait for appropriations) may have compounding effects on industry that may depend on access to certain capabilities and harm American competitiveness, as described in the previous recommendation.
Conclusion
As the 2024 RDI Report points out “Being a science superpower carries the burden of supporting and maintaining the advanced underlying infrastructure that supports the research and development enterprise.” Without a transparent accounting of costs it is impossible for Congress to make prudent decisions about the future of that enterprise. Requiring agencies to provide complete information to both Congress and OMB at the beginning of each year’s budget process likely provides the best chance of allowing us to address this challenge.
A National Institute for High-Reward Research
The policy discourse about high-risk, high-reward research has been too narrow. When that term is used, people are usually talking about DARPA-style moonshot initiatives with extremely ambitious goals. Given the overly conservative nature of most scientific funding, there’s a fair appetite (and deservedly so) for creating new agencies like ARPA-H, and other governmental and private analogues.
The “moonshot” definition, however, omits other types of high-risk, high-reward research that are just as important for the government to fund—perhaps even more so, because they are harder for anyone else to support or even to recognize in the first place.
Far too many scientific breakthroughs and even Nobel-winning discoveries had trouble getting funded at the outset. The main reason at the time was that the researcher’s idea seemed irrelevant or fanciful. For example, CRISPR was originally thought to be nothing more than a curiosity about bacterial defense mechanisms.
Perhaps ironically, the highest rewards in science often come from the unlikeliest places. Some of our “high reward” funding should therefore be focused on projects, fields, ideas, theories, etc. that are thought to be irrelevant, including ideas that have gotten turned down elsewhere because they are unlikely to “work.” The “risk” here isn’t necessarily technical risk, but the risk of being ignored.
Traditional funders are unlikely to create funding lines specifically for research that they themselves thought was irrelevant. Thus, we need a new agency that specializes in uncovering funding opportunities that were overlooked elsewhere. Judging from the history of scientific breakthroughs, the benefits could be quite substantial.
Challenge and Opportunity
There are far too many cases where brilliant scientists had trouble getting their ideas funded or even faced significant opposition at the time. For just a few examples (there are many others):
- The team that discovered how to manufacture human insulin applied for an NIH grant for an early stage of their work. The rejection notice said that the project looked “extremely complex and time-consuming,” and “appears as an academic exercise.”
- Katalin Karikó’s early work on mRNA was a key contributor to multiple Covid vaccines, and ultimately won the Nobel Prize. But she repeatedly got demoted at the University of Pennsylvania because she couldn’t get NIH funding.
- Carol Grieder’s work on telomerase was rejected by an NIH panel on literally the same day that she won the Nobel Prize, on the grounds that she didn’t have enough preliminary data about telomerase.
- Francisco Mojica (who identified CRISPR while studying archaebacteria in the 1990s) has said, “When we didn’t have any idea about the role these systems played, we applied for financial support from the Spanish government for our research. The government received complaints about the application and, subsequently, I was unable to get any financial support for many years.”
- Peyton Rous’s early 20th century studies on transplanting tumors between purebred chickens was ridiculed at the time, but his work won the Nobel Prize over 50 years later, and provided the basis for other breakthroughs involving reverse transcription, retroviruses, oncogenes, and more.
One could fill an entire book with nothing but these kinds of stories.
Why do so many brilliant scientists struggle to get funding and support for their groundbreaking ideas? In many cases, it’s not because of any reason that a typical “high risk, high reward” research program would address. Instead, it’s because their research can be seen as irrelevant, too far removed from any practical application, or too contrary to whatever is currently trendy.
To make matters worse, the temptation for government funders is to opt for large-scale initiatives with a lofty goal like “curing cancer” or some goal that is equally ambitious but also equally unlikely to be accomplished by a top-down mandate. For example, the U.S. government announced a National Plan to Address Alzheimer’s Disease in 2012, and the original webpage promised to “prevent and effectively treat Alzheimer’s by 2025.” Billions have been spent over the past decade on this objective, but U.S. scientists are nowhere near preventing or treating Alzheimer’s yet. (Around October 2024, the webpage was updated and now aims to “address Alzheimer’s and related dementias through 2035.”)
The challenge is whether quirky, creative, seemingly irrelevant, contrarian science—which is where some of the most significant scientific breakthroughs originated—can survive in a world that is increasingly managed by large bureaucracies whose procedures don’t really have a place for that type of science, and by politicians eager to proclaim that they have launched an ambitious goal-driven initiative.
The answer that I propose: Create an agency whose sole raison d’etre is to fund scientific research that other agencies won’t fund—not for reasons of basic competence, of course, but because the research wasn’t fashionable or relevant.
The benefits of such an approach wouldn’t be seen immediately. The whole point is to allocate money to a broad portfolio of scientific projects, some of which would fail miserably but some of which would have the potential to create the kind of breakthroughs that, by definition, are unpredictable in advance. This plan would therefore require a modicum of patience on the part of policymakers. But over the longer term, it would likely lead to a number of unforeseeable breakthroughs that would make the rest of the program worth it.
Plan of Action
The federal government needs to establish a new National Institute for High-Reward Research (NIHRR) as a stand-alone agency, not tied to the National Institutes of Health or the National Science Foundation. The NIHRR would be empowered to fund the potentially high-reward research that goes overlooked elsewhere. More specifically, the aim would be to cast a wide net for:
- Researchers (akin to Katalin Karikó or Francisco Mojica) who are perfectly well-qualified but have trouble getting funding elsewhere;
- Research projects or larger initiatives that are seen as contrary to whatever is trendy in a given field;
- Research projects or larger initiatives that are seen as irrelevant (e.g., bacterial or animal research that is seen as unrelated to human health).
NIHRR should be funded at, say, $100m per year as a starting point ($1 billion would be better). This is an admittedly ambitious proposal. It would mean increasing the scientific and R&D expenditure by that amount, or else reassigning existing funding (which would be politically unpopular). But it is a worthy objective, and indeed, should be seen as a starting point.
Significant stakeholders with an interest in a new NIHRR would obviously include universities and scholars who currently struggle for scientific funding. In a way, that stacks the deck against the idea, because the most politically powerful institutions and individuals might oppose anything that tampers with the status quo of how research funding is allocated. Nonetheless, there may be a number of high-status individuals (e.g., current Nobel winners) who would be willing to support this idea as something that would have aided their earlier work.
A new fund like this would also provide fertile ground for metascience experiments and other types of studies. Consider the striking fact that as yet, there is virtually no rigorous empirical evidence as to the relative strengths and weaknesses of top-down, strategically-driven scientific funding versus funding that is more open to seemingly irrelevant, curiosity-driven research. With a new program for the latter, we could start to derive comparisons between the results of that funding as compared to equally situated researchers funded through the regular pathways.
Moreover, a common metascience proposal in recent years is to use a limited lottery to distribute funding, on the grounds that some funding is fairly random anyway and we might as well make it official. One possibility would be for part of the new program to be disbursed by lottery amongst researchers who met a minimum bar of quality and respectability, and who had got a high enough score on “scientific novelty.” One could imagine developing an algorithm to make an initial assessment as well. Then we could compare the results of lottery-based funding versus decisions made by program officers versus algorithmic recommendations.
Conclusion
A new line of funding like the National Institute for High-Reward Research (NIHRR) could drive innovation and exploration by funding the potentially high-reward research that goes overlooked elsewhere. This would elevate worthy projects with unknown outcomes so that unfashionable or unpopular ideas can be explored. Funding these projects would have the added benefit of offering many opportunities to build in metascience studies from the outset, which is easier than retrofitting projects later.
This memo produced as part of the Federation of American Scientists and Good Science Project sprint. Find more ideas at Good Science Project x FAS
Absolutely, but that is also true for the current top-down approach of announcing lofty initiatives to “cure Alzheimer’s” and the like. Beyond that, the whole point of a true “high-risk, high-reward” research program should be to fund a large number of ideas that don’t pan out. If most research projects succeed, then it wasn’t a “high-risk” program after all.
Again, that would be a sign of potential success. Many of history’s greatest breakthroughs were mocked for those exact reasons at the time. And yes, some of the research will indeed be irrelevant or silly. That’s part of the bargain here. You can’t optimize both Type I and Type II errors at the same time (that is, false positives and false negatives). If we want to open the door to more research that would have been previously rejected on overly stringent grounds, then we also open the door to research that would have been correctly rejected on those grounds. That’s the price of being open to unpredictable breakthroughs.
How to evaluate success is a sticking point here, as it is for most of science. The traditional metrics (citations, patents, etc.) would likely be misleading, at least in the short-term. Indeed, as discussed above, there are cases where enormous breakthroughs took a few decades to be fully appreciated.
One simple metric in the shorter term would be something like this: “How often do researchers send in progress reports saying that they have been tackling a difficult question, and that they haven’t yet found the answer?” Instead of constantly promising and delivering success (which is often achieved by studying marginal questions and/or exaggerating results), scientists should be incentivized to honestly report on their failures and struggles.
Predicting Progress: A Pilot of Expected Utility Forecasting in Science Funding
Read more about expected utility forecasting and science funding innovation here.
The current process that federal science agencies use for reviewing grant proposals is known to be biased against riskier proposals. As such, the metascience community has proposed many alternate approaches to evaluating grant proposals that could improve science funding outcomes. One such approach was proposed by Chiara Franzoni and Paula Stephan in a paper on how expected utility — a formal quantitative measure of predicted success and impact — could be a better metric for assessing the risk and reward profile of science proposals. Inspired by their paper, the Federation of American Scientists (FAS) collaborated with Metaculus to run a pilot study of this approach. In this working paper, we share the results of that pilot and its implications for future implementation of expected utility forecasting in science funding review.
Brief Description of the Study
In fall 2023, we recruited a small cohort of subject matter experts to review five life science proposals by forecasting their expected utility. For each proposal, this consisted of defining two research milestones in consultation with the project leads and asking reviewers to make three forecasts for each milestone:
- the probability of success;
- The scientific impact of the milestone, if it were reached; and
- The social impact of the milestone, if it were reached.
These predictions can then be used to calculate the expected utility, or likely impact, of a proposal and design and compare potential portfolios.
Key Takeaways for Grantmakers and Policymakers
The three main strengths of using expected utility forecasting to conduct peer review are
- For reviewers, it’s a relatively light-touch approach that encourages rigor and reduces anti-risk bias in scientific funding.
- The review criteria allow program managers to better understand the risk-reward profile of their grant portfolios and more intentionally shape them according to programmatic goals.
- Quantitative forecasts are resolvable, meaning that program officers can compare the actual outcomes of funded proposals with reviewers’ predictions. This generates a feedback/learning loop within the peer review process that incentivizes reviewers to improve the accuracy of their assessments over time.
Despite the apparent complexity of this process, we found that first-time users were able to successfully complete their review according to the guidelines without any additional support. Most of the complexity occurs behind-the-scenes, and either aligns with the responsibilities of the program manager (e.g., defining milestones and their dependencies) or can be automated (e.g., calculating the total expected utility). Thus, grantmakers and policymakers can have confidence in the user friendliness of expected utility forecasting.
How Can NSF or NIH Run an Experiment on Expected Utility Forecasting?
An initial pilot study could be conducted by NSF or NIH by adding a short, non-binding expected utility forecasting component to a selection of review panels. In addition to the evaluation of traditional criteria, reviewers would be asked to predict the success and impact of select milestones for the proposals assigned to them. The rest of the review process and the final funding decisions would be made using the traditional criteria.
Afterwards, study facilitators could take the expected utility forecasting results and construct an alternate portfolio of proposals that would have been funded if that approach was used, and compare the two portfolios. Such a comparison would yield valuable insights into whether—and how—the types of proposals selected by each approach differ, and whether their use leads to different considerations arising during review. Additionally, a pilot assessment of reviewers’ prediction accuracy could be conducted by asking program officers to assess milestone achievement and study impact upon completion of funded projects.
Findings and Recommendations
Reviewers in our study were new to the expected utility forecasting process and gave generally positive reactions. In their feedback, reviewers said that they appreciated how the framing of the questions prompted them to think about the proposals in a different way and pushed them to ground their assessments with quantitative forecasts. The focus on just three review criteria–probability of success, scientific impact, and social impact–was seen as a strength because it simplified the process, disentangled feasibility from impact, and eliminated biased metrics. Overall, reviewers found this new approach interesting and worth investigating further.
In designing this pilot and analyzing the results, we identified several important considerations for planning such a review process. While complex, engaging with these considerations tended to provide value by making implicit project details explicit and encouraging clear definition and communication of evaluation criteria to reviewers. Two key examples are defining the proposal milestones and creating impact scoring systems. In both cases, reducing ambiguities in terms of the goals that are to be achieved, developing an understanding of how outcomes depend on one another, and creating interpretable and resolvable criteria for assessment will help ensure that the desired information is solicited from reviewers.
Questions for Further Study
Our pilot only simulated the individual review phase of grant proposals and did not simulate a full review committee. The typical review process at a funding agency consists of first, individual evaluations by assigned reviewers, then discussion of those evaluations by the whole review committee, and finally, the submission of final scores from all members of the committee. This is similar to the Delphi method, a structured process for eliciting forecasts from a panel of experts, so we believe that it would work well with expected utility forecasting. The primary change would therefore be in the definition and approach for eliciting criterion scores, rather than the structure of the review process. Nevertheless, future implementations may uncover additional considerations that need to be addressed or better ways to incorporate forecasting into a panel environment.
Further investigation into how best to define proposal milestones is also needed. This includes questions such as, who should be responsible for determining the milestones? If reviewers are involved, at what part(s) of the review process should this occur? What is the right balance between precision and flexibility of milestone definitions, such that the best outcomes are achieved? How much flexibility should there be in the number of milestones per proposal?
Lastly, more thought should be given to how to define social impact and how to calibrate reviewers’ interpretation of the impact score scale. In our report, we propose a couple of different options for calibrating impact, in addition to describing the one we took in our pilot.
Interested grantmakers, both public and private, and policymakers are welcome to reach out to our team if interested in learning more or receiving assistance in implementing this approach.
Introduction
The fundamental concern of grantmakers, whether governmental or philanthropic, is how to make the best funding decisions. All funding decisions come with inherent uncertainties that may pose risks to the investment. Thus, a certain level of risk-aversion is natural and even desirable in grantmaking institutions, especially federal science agencies which are responsible for managing taxpayer dollars. However, without risk, there is no reward, so the trade-off must be balanced. In mathematics and economics, expected utility is the common metric assumed to underlie all rational decision making. Expected utility has two components: the probability of an outcome occurring if an action is taken and the value of that outcome, which roughly corresponds with risk and reward. Thus, expected utility would seem to be a logical choice for evaluating science funding proposals.
In the debates around funding innovation though, expected utility has largely flown under the radar compared to other ideas. Nevertheless, Chiara Franzoni and Paula Stephan have proposed using expected utility in peer review. Building off of their paper, the Federation of American Scientists (FAS) developed a detailed framework for how to implement expected utility into a peer review process. We chose to frame the review criteria as forecasting questions, since determining the expected utility of a proposal inherently requires making some predictions about the future. Forecasting questions also have the added benefit of being resolvable–i.e., the true outcome can be determined after the fact and compared to the prediction–which provides a learning opportunity for reviewers to improve their abilities and identify biases. In addition to forecasting, we incorporated other unique features, like an exponential scale for scoring impact, that we believe help reduce biases against risky proposals.
With the theory laid out, we conducted a small pilot in fall of 2023. The pilot was run in collaboration with Metaculus, a crowd forecasting platform and aggregator, to leverage their expertise in designing resolvable forecasting questions and to use their platform to collect forecasts from reviewers. The purpose of the pilot was to test the mechanics of this approach in practice, see if there are any additional considerations that need to be thought through, and surface potential issues that need to be solved for. We were also curious if there would be any interesting or unexpected results that arise based on how we chose to calculate impact and total expected utility. It is important to note that this pilot was not an experiment, so we did not have a control group to compare the results of the review with.
Since FAS is not a grantmaking institution, we did not have a ready supply of traditional grant proposals to use. Instead, we used a set of two-page research proposals for Focused Research Organizations (FROs) that we had sourced through separate advocacy work in that area.1 With the proposal authors’ permission, we recruited a cohort of twenty subject matter experts to each review one of five proposals. For each proposal, we defined two research milestones in consultation with the proposal authors. Reviewers were asked to make three forecasts for each milestone:
- The probability of success;
- The scientific impact, conditional on success; and
- The social impact, conditional on success.
Reviewers submitted their forecasts on Metaculus’ platform; in a separate form they provided explanations for their forecasts and responded to questions about their experience and impression of this new approach to proposal evaluation. (See Appendix A for details on the pilot study design.)
Insights from Reviewer Feedback
Overall, reviewers liked the framing and criteria provided by the expected utility approach, while their main critique was of the structure of the research proposals. Excluding critiques of the research proposal structure, which are unlikely to apply to an actual grant program, two thirds of the reviewers expressed positive opinions of the review process and/or thought it was worth pursuing further given drawbacks with existing review processes. Below, we delve into the details of the feedback we received from reviewers and their implications for future implementation.
Feedback on Review Criteria
Disentangling Impact from Feasibility
Many of the reviewers said that this model prompted them to think differently about how they assess the proposals and that they liked the new questions. Reviewers appreciated that the questions focused their attention on what they think funding agencies really want to know and nothing more: “can it occur?” and “will it matter?” This approach explicitly disentangles impact from feasibility: “Often, these two are taken together, and if one doesn’t think it is likely to succeed, the impact is also seen as lower.” Additionally, the emphasis on big picture scientific and social impact “is often missing in the typical review process.” Reviewers also liked that this approach eliminates what they consider biased metrics, such as the principal investigator’s reputation, track record, and “excellence.”
Reducing Administrative Burden
The small set of questions was seen as more efficient and less burdensome on reviewers. One reviewer said, “I liked this approach to scoring a proposal. It reduces the effort to thinking about perceived impact and feasibility.” Another reviewer said, “On the whole it seems a worthwhile exercise as the current review processes for proposals are onerous.”
Quantitative Forecasting
Reviewers saw benefits to being asked to quantify their assessments, but also found it challenging at times. A number of reviewers enjoyed taking a quantitative approach and thought that it helped them be more grounded and explicit in their evaluations of the proposals. However, some reviewers were concerned that it felt like guesswork and expressed low confidence in their quantitative assessments, primarily due to proposals lacking details on their planned research methods, which is an issue discussed in the section “Feedback on Proposals.” Nevertheless, some of these reviewers still saw benefits to taking a quantitative approach: “It is interesting to try to estimate probabilities, rather than making flat statements, but I don’t think I guess very well. It is better than simply classically reviewing the proposal [though].” Since not all academics have experience making quantitative predictions, we expect that there will be a learning curve for those new to the practice. Forecasting is a skill that can be learned though, and we think that with training and feedback, reviewers can become better, more confident forecasters.
Defining Social Impact
Of the three types of questions that reviewers were asked to answer, the question about social impact seemed the harder one for reviewers to interpret. Reviewers noted that they would have liked more guidance on what was meant by social impact and whether that included indirect impacts. Since questions like these are ultimately subjective, the “right” definition of social impact and what types of outcomes are considered most valuable will depend on the grantmaking institution, their domain area, and their theory of change, so we leave this open to future implementers to clarify in their instructions.
Calibrating Impact
While the impact score scale (see Appendix A) defines the relative difference in impact between scores, it does not define the absolute impact conveyed by a score. For this reason, a calibration mechanism is necessary to provide reviewers with a shared understanding of the use and interpretation of the scoring system. Note that this is a challenge that rubric-based peer review criteria used by science agencies also face. Discussion and aggregation of scores across a review committee helps align reviewers and average out some of this natural variation.2
To address this, we surveyed a small, separate set of academics in the life sciences about how they would score the social and scientific impact of the average NIH R01 grant, which many life science researchers apply to and review proposals for. We then provided the average scores from this survey to reviewers to orient them to the new scale and help them calibrate their scores.
One reviewer suggested an alternative approach: “The other thing I might change is having a test/baseline question for every reviewer to respond to, so you can get a feel for how we skew in terms of assessing impact on both scientific and social aspects.” One option would be to ask reviewers to score the social and scientific impact of the average grant proposal for a grant program that all reviewers would be familiar with; another would be to ask reviewers to score the impact of the average funded grant for a specific grant program, which could be more accessible for new reviewers who have not previously reviewed grant proposals. A third option would be to provide all reviewers on a committee with one or more sample proposals to score and discuss, in a relevant and shared domain area.
When deciding on an approach for calibration, a key consideration is the specific resolution criteria that are being used — i.e., the downstream measures of impact that reviewers are being asked to predict. One option, which was used in our pilot, is to predict the scores that a comparable, but independent, panel of reviewers would give the project some number of years following its successful completion. For a resolution criterion like this one, collecting and sharing calibration scores can help reviewers get a sense for not just their own approach to scoring, but also those of their peers.
Making Funding Decisions
In scoring the social and scientific impact of each proposal, reviewers were asked to assess the value of the proposal to society or to the scientific field. That alone would be insufficient to determine whether a proposal should be funded though, since it would need to be compared with other proposals in conjunction with its feasibility. To do so, we calculated the total expected utility of each proposal (see Appendix C). In a real funding scenario, this final metric could then be used to compare proposals and determine which ones get funded. Additionally, unlike a traditional scoring system, the expected utility approach allows for the detailed comparison of portfolios — including considerations like the expected proportion of milestones reached and the range of likely impacts.
In our pilot, reviewers were not informed that we would be doing this additional calculation based on their submissions. As a result, one reviewer thought that the questions they were asked failed to include other important questions, like “should it occur?” and “is it worth the opportunity cost?” Though these questions were not asked of reviewers explicitly, we believe that they would be answered once the expected utility of all proposals is calculated and considered, since the opportunity cost of one proposal would be the expected utility of the other proposals. Since each reviewer only provided input on one proposal, they may have felt like the scores they gave would be used to make a binary yes/no decision on whether to fund that one proposal, rather than being considered as a part of a larger pool of proposals, as it would be in a real review process.
Feedback on Proposals
Missing Information Impedes Forecasting
The primary critique that reviewers expressed was that the research proposals lacked details about their research plans, what methods and experimental protocols would be used, and what preliminary research the author(s) had done so far. This hindered their ability to properly assess the technical feasibility of the proposals and their probability of success. A few reviewers expressed that they also would have liked to have had a better sense of who would be conducting the research and each team member’s responsibilities. These issues arose because the FRO proposals used in our pilot had not originally been submitted for funding purposes, and thus lacked the requirements of traditional grant proposals, as we noted above. We assume this would not be an issue with proposals submitted to actual grantmakers.3
Improving Milestone Design
A few reviewers pointed out that some of the proposal milestones were too ambiguous or were not worded specifically enough, such that there were ways that researchers could technically say that they had achieved the milestone without accomplishing the spirit of its intent. This made it more challenging for reviewers to assess milestones, since they weren’t sure whether to focus on the ideal (i.e., more impactful) interpretation of the milestone or to account for these “loopholes.” Moreover, loopholes skew the forecasts, since they increase the probability of achieving a milestone, while lowering the impact of doing so if it is achieved through a loophole.
One reviewer suggested, “I feel like the design of milestones should be far more carefully worded – or broken up into sub-sentences/sub-aims, to evaluate the feasibility of each. As the questions are currently broken down, I feel they create a perverse incentive to create a vaguer milestone, or one that can be more easily considered ‘achieved’ for some ‘good enough’ value of achieved.” For example, they proposed that one of the proposal milestones, “screen a library of tens of thousands of phage genes for enterobacteria for interactions and publish promising new interactions for the field to study,” could be expanded to
- “Generate a library of tens of thousands of genes from enterobacteria, expressed in E. coli
- “Validate their expression under screenable conditions
- “Screen the library for their ability to impede phage infection with a panel of 20 type phages
- “Publish …
- “Store and distribute the library, making it as accessible to the broader community”
We agree with the need for careful consideration and design of milestones, given that “loopholes” in milestones can detract from their intended impact and make it harder for reviewers to accurately assess their likelihood. In our theoretical framework for this approach, we identified three potential parties that could be responsible for defining milestones: (1) the proposal author(s), (2) the program manager, with or without input from proposal authors, or (3) the reviewers, with or without input from proposal authors. This critique suggests that the first approach of allowing proposal authors to be the sole party responsible for defining proposal milestones is vulnerable to being gamed, and the second or third approach would be preferable. Program managers who take on the task of defining milestones should have enough expertise to think through the different potential ways of fulfilling a milestone and make sure that they are sufficiently precise for reviewers to assess.
Benefits of Flexibility in Milestones
Some flexibility in milestones may still be desirable, especially with respect to the actual methodology, since experimentation may be necessary to determine the best technique to use. For example, speaking about the feasibility of a different proposal milestone – “demonstrate that Pro-AG technology can be adapted to a single pathogenic bacterial strain in a 300 gallon aquarium of fish and successfully reduce antibiotic resistance by 90%” – a reviewer noted that
“The main complexity and uncertainty around successful completion of this milestone arises from the native fish microbiome and whether a CRISPR delivery tool can reach the target strain in question. Due to the framing of this milestone, should a single strain be very difficult to reach, the authors could simply switch to a different target strain if necessary. Additionally, the mode of CRISPR delivery is not prescribed in reaching this milestone, so the authors have a host of different techniques open to them, including conjugative delivery by a probiotic donor or delivery by engineered bacteriophage.”
Peer Review Results
Sequential Milestones vs. Independent Outcomes
In our expected utility forecasting framework, we defined two different ways that a proposal could structure its outcomes: as sequential milestones where each additional milestone builds off of the success of the previous one, or as independent outcomes where the success of one is not dependent on the success of the other(s). For proposals with sequential milestones in our pilot, we would expect the probability of success of milestone 2 to be less than the probability of success of milestone 1 and for the opposite to be true of their impact scores. For proposals with independent outcomes, we do not expect there to be a relationship between the probability of success and the impact scores of milestones 1 and 2. There are different equations for calculating the total expected utility, depending on the relationship between outcomes (see Appendix C).
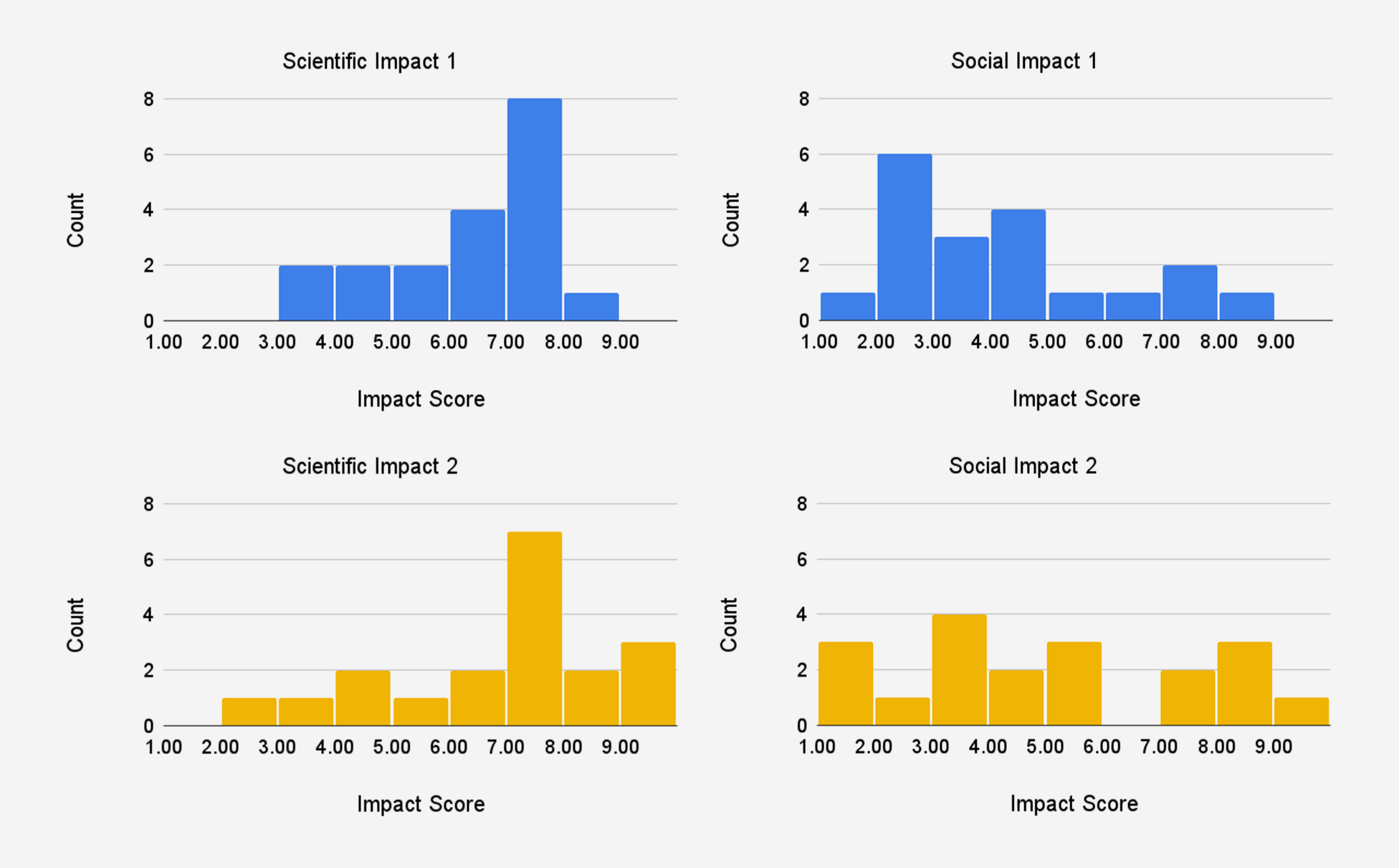
For each of the proposals in our study, we categorized them based on whether they had sequential milestones or independent outcomes. This information was not shared with reviewers. Table 1 presents the average reviewer forecasts for each proposal. In general, milestones received higher scientific impact scores than social impact scores, which makes sense given the primarily academic focus of research proposals. For proposals 1 to 3, the probability of success of milestone 2 was roughly half of the probability of success of milestone 1; reviewers also gave milestone 2 higher scientific and social impact scores than milestone 1. This is consistent with our categorization of proposals 1 to 3 as sequential milestones.
Further Discussion on Designing and Categorizing Milestones
We originally categorized proposal 4’s milestones as sequential, but one reviewer gave milestone 2 a lower scientific impact score than milestone 1 and two reviewers gave it a lower social impact score. One reviewer also gave milestone 2 roughly the same probability of success as milestone 1. This suggests that proposal 4’s milestones can’t be considered strictly sequential.
The two milestones for proposal 4 were
- Milestone 1: Develop a tool that is able to perturb neurons in C. elegans and record from all neurons simultaneously, automated w/ microfluidics, and
- Milestone 2: Develop a model of the C. elegans nervous system that can predict what every neuron will do when stimulating one neuron with R2 > 0.8
The reviewer who gave milestone 2 a lower scientific impact score explained: “Given the wording of the milestone, I do not believe that if the scientific milestone was achieved, it would greatly improve our understanding of the brain.” Unlike proposals 1-3, in which milestone 2 was a scaled-up or improved-upon version of milestone 1, these milestones represent fundamentally different categories of output (general-purpose tool vs specific model). Thus, despite the necessity of milestone 1’s tool for achieving milestone 2, the reviewer’s response suggests that the impact of milestone 2 was being considered separately rather than cumulatively.
To properly address this case of sequential milestones with different types of outputs, we recommend that for all sequential milestones, latter milestones should be explicitly defined as inclusive of prior milestones. In the above example, this would imply redefining milestone 2 as “Complete milestone 1 and develop a model of the C. elegans nervous system…” This way, reviewers know to include the impact of milestone 1 in their assessment of the impact of milestone 2.
To help ensure that reviewers are aligned with program managers in how they interpret the proposal milestones (if they aren’t directly involved in defining milestones), we suggest that either reviewers be informed of how program managers are categorizing the proposal outputs so they can conduct their review accordingly or allow reviewers to decide the category (and thus how the total expected utility is calculated), whether individually or collectively or both.
We chose to use only two of the goals that proposal authors provided because we wanted to standardize the number of milestones across proposals. However, this may have provided an incomplete picture of the proposals’ goals, and thus an incomplete assessment of the proposals. We recommend that future implementations be flexible and allow the number of milestones to be determined based on each proposal’s needs. This would also help accommodate one of the reviewers’ suggestion that some milestones should be broken down into intermediary steps.
Importance of Reviewer Explanations
As one can tell from the above discussion, reviewers’ explanation of their forecasts were crucial to understanding how they interpreted the milestones. Reviewers’ explanations varied in length and detail, but the most insightful responses broke down their reasoning into detailed steps and addressed (1) ambiguities in the milestone and how they chose to interpret ambiguities if they existed, (2) the state of the scientific field and the maturity of different techniques that the authors propose to use, and (3) factors that improve the likelihood of success versus potential barriers or challenges that would need to be overcome.
Exponential Impact Scales Better Reflect the Real Distribution of Impact
The distribution of NIH and NSF proposal peer review scores tends to be skewed such that most proposals are rated above the center of the scale and there are few proposals rated poorly. However, other markers of scientific impact, such as citations (even with all of its imperfections), tend to suggest a long tail of studies with high impact. This discrepancy suggests that traditional peer review scoring systems are not well-structured to capture the nonlinearity of scientific impact, resulting in score inflation. The aggregation of scores at the top end of the scale also means that very negative scores have a greater impact than very positive scores when averaged together, since there’s more room between the average score and the bottom end of the scale. This can generate systemic bias against more controversial or risky proposals.
In our pilot, we chose to use an exponential scale with a base of 2 for impact to better reflect the real distribution of scientific impact. Using this exponential impact scale, we conducted a survey of a small pool of academics in the life sciences about how they would rate the impact of the average funded NIH R01 grant. They responded with an average scientific impact score 5 and an average social impact score of 3, which are much lower on our scale compared to traditional peer review scores4, suggesting that the exponential scale may be beneficial for avoiding score inflation and bunching at the top. In our pilot, the distribution of scientific impact scores was centered higher than 5, but still less skewed than NIH peer review scores for significance and innovation typically are. This partially reflects the fact that proposals were expected to be funded at one to two orders of magnitude more than NIH R01 proposals are, so impact should also be greater. The distribution of social impact scores exhibits a much wider spread and lower center.
Conclusion
In summary, expected utility forecasting presents a promising approach to improving the rigor of peer review and quantitatively defining the risk-reward profile of science proposals. Our pilot study suggests that this approach can be quite user-friendly for reviewers, despite its apparent complexity. Further study into how best to integrate forecasting into panel environments, define proposal milestones, and calibrate impact scales will help refine future implementations of this approach.
More broadly, we hope that this pilot will encourage more grantmaking institutions to experiment with innovative funding mechanisms. Reviewers in our pilot were more open-minded and quick-to-learn than one might expect and saw significant value in this unconventional approach. Perhaps this should not be so much of a surprise given that experimentation is at the heart of scientific research.
Interested grantmakers, both public and private, and policymakers are welcome to reach out to our team if interested in learning more or receiving assistance in implementing this approach.
Acknowledgements
Many thanks to Jordan Dworkin for being an incredible thought partner in designing the pilot and providing meticulous feedback on this report. Your efforts made this project possible!
Appendix A: Pilot Study Design
Our pilot study consisted of five proposals for life science-related Focused Research Organizations (FROs). These proposals were solicited from academic researchers by FAS as part of our advocacy for the concept of FROs. As such, these proposals were not originally intended as proposals for direct funding, and did not have as strict content requirements as traditional grant proposals typically do. Researchers were asked to submit one to two page proposals discussing (1) their research concept, (2) the motivation and its expected social and scientific impact, and (3) the rationale for why this research can not be accomplished through traditional funding channels and thus requires a FRO to be funded.
Permission was obtained from proposal authors to use their proposals in this study. We worked with proposal authors to define two milestones for each proposal that reviewers would assess: one that they felt confident that they could achieve and one that was more ambitious but that they still thought was feasible. In addition, due to the brevity of the proposals, we included an additional 1-2 pages of supplementary information and scientific context. Final drafts of the milestones and supplementary information were provided to authors to edit and approve. Because this pilot study could not provide any actual funding to proposal authors, it was not possible to solicit full length research proposals from proposal authors.
We recruited four to six reviewers for each proposal based on their subject matter expertise. Potential participants were recruited over email with a request to help review a FRO proposal related to their area of research. They were informed that the review process would be unconventional but were not informed of the study’s purpose. Participants were offered a small monetary compensation for their time.
Confirmed participants were sent instructions and materials for the review process on the same day and were asked to complete their review by the same deadline a month and a half later. Reviewers were told to assume that, if funded, each proposal would receive $50 million in funding over five years to conduct the research, consistent with the proposed model for FROs. Each proposal had two technical milestones, and reviewers were asked to answer the following questions for each milestone:
- Assuming that the proposal is funded by 2025, will the milestone be achieved before 2031?
- What will be the average scientific impact score, as judged in 2032, of accomplishing the milestone?
- What will be the average social impact score, as judged in 2032, of accomplishing the milestone?
The impact scoring system was explained to reviewers as follows:
Please consider the following in determining the impact score: the current and expected long-term social or scientific impact of a funded FRO’s outputs if a funded FRO accomplishes this milestone before 2030.
The impact score we are using ranges from 1 (low) to 10 (high). It is base 2 exponential, meaning that a proposal that receives a score of 5 has double the impact of a proposal that receives a score of 4, and quadruple the impact of a proposal that receives a score of 3. In a small survey we conducted of SMEs in the life sciences, they rated the scientific and social impact of the average NIH R01 grant — a federally funded research grant that provides $1-2 million for a 3-5 year endeavor — on this scale to be 5.2 ± 1.5 and 3.1 ± 1.3, respectively. The median scores were 4.75 and 3.00, respectively.
Below is an example of how a predicted impact score distribution (left) would translate into an actual impact distribution (right). You can try it out yourself with this interactive version (in the menu bar, click Runtime > Run all) to get some further intuition on how the impact score works. Please note that this is meant solely for instructive purposes, and the interface is not designed to match Metaculus’ interface.
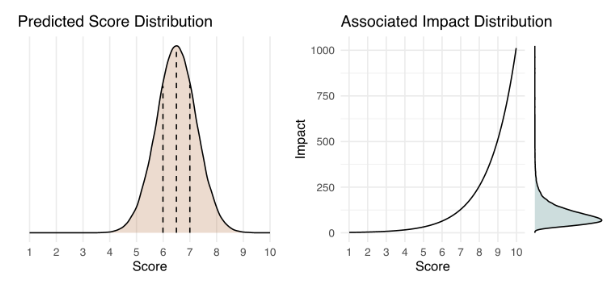
The choice of an exponential impact scale reflects the tendency in science for a small number of research projects to have an outsized impact. For example, studies have shown that the relationship between the number of citations for a journal article and its percentile rank scales exponentially.
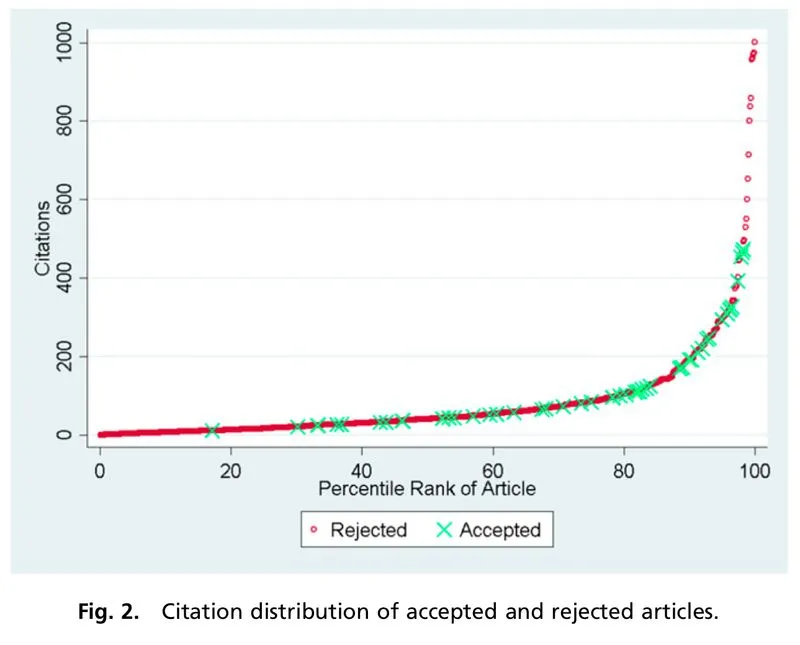
{kind=link}
Scientific impact aims to capture the extent to which a project advances the frontiers of knowledge, enables new discoveries or innovations, or enhances scientific capabilities or methods. Though each is imperfect, one could consider citations of papers, patents on tools or methods, or users of software or datasets as proxies of scientific impact.
Social impact aims to capture the extent to which a project contributes to solving important societal problems, improving well-being, or advancing social goals. Some proxy metrics that one might use to assess a project’s social impact are the value of lives saved, the cost of illness prevented, the number of job-years of employment generated, economic output in terms of GDP, or the social return on investment.
You may consider any or none of these proxy metrics as a part of your assessment of the impact of a FRO accomplishing this milestone.
Reviewers were asked to submit their forecasts on Metaculus’ website and to provide their reasoning in a separate Google form. For question 1, reviewers were asked to respond with a single probability. For questions 2 and 3, reviewers were asked to provide their median, 25th percentile, and 75th percentile predictions, in order to generate a probability distribution. Metaculus’ website also included information on the resolution criteria of each question, which provided guidance to reviewers on how to answer the question. Individual reviewers were blind to other reviewers’ responses until after the submission deadline, at which point the aggregated results of all of the responses were made public on Metaculus’ website.
Additionally, in the Google form, reviewers were asked to answer a survey question about their experience: “What did you think about this review process? Did it prompt you to think about the proposal in a different way than when you normally review proposals? If so, how? What did you like about it? What did you not like? What would you change about it if you could?”
Some participants did not complete their review. We received 19 complete reviews in the end, with each proposal receiving three to six reviews.
Study Limitations
Our pilot study had certain limitations that should be noted. Since FAS is not a grantmaking institution, we could not completely reproduce the same types of research proposals that a grantmaking institution would receive nor the entire review process. We will highlight these differences in comparison to federal science agencies, which are our primary focus.
- Review Process: There are typically two phases to peer review at NIH and NSF. First, at least three individual reviewers with relevant subject matter expertise are assigned to read and evaluate a proposal independently. Then, a larger committee of experts is convened. There, the assigned reviewers present the proposal and their evaluation, and then the committee discusses and determines the final score for the proposal. Our pilot study only attempted to replicate the first phase of individual review.
- Sample Size: In our pilot, the sample size was quite small, since only five proposals were reviewed, and they were all in different subfields, so different reviewers were assigned to each proposal. NIH and NSF peer review committees typically focus on one subfield and review on the order of twenty or so proposals. The number of reviewers per proposal–three to six–in our pilot was consistent with the number of reviewers typically assigned to a proposal by NIH and NSF. Peer review committees are typically larger, ranging from six to twenty people, depending on the agency and the field.
- Proposals: The FRO proposals plus supplementary information were only two to four pages long, which is significantly shorter than the 12 to 15 page proposals that researchers submit for NIH and NSF grants. Proposal authors were asked to generally describe their research concept, but were not explicitly required to describe the details of the research methodology they would use or any preliminary research. Some proposal authors volunteered more information on this for the supplementary information, but not all authors did.
- Grant Size: For the FRO proposals, reviewers were asked to assume that funded proposals would receive $50 million over five years, which is one to two orders of magnitude more funding than typical NIH and NSF proposals.
Appendix B: Feedback on Study-Specific Implementation
In addition to feedback about the review framework, we received feedback on how we implemented our pilot study, specifically the instructions and materials for the review process and the submission platforms. This feedback isn’t central to this paper’s investigation of expected value forecasting, but we wanted to include it in the appendix for transparency.
Reviewers were sent instructions over email that outlined the review process and linked to Metaculus’ webpage for this pilot. On Metaculus’ website, reviewers could find links to the proposals on FAS’ website and the supplementary information in Google docs. Reviewers were expected to read those first and then read through the resolution criteria for each forecasting question before submitting their answers on Metaculus’ platform. Reviewers were asked to submit the explanations behind their forecasts in a separate Google form.
Some reviewers had no problem navigating the review process and found Metaculus’ website easy to use. However, feedback from other reviewers suggested that the different components necessary for the review were spread out over too many different websites, making it difficult for reviewers to keep track of where to find everything they needed.
Some had trouble locating the different materials and pieces of information needed to conduct the review on Metaculus’ website. Others found it confusing to have to submit their forecasts and explanations in two separate places. One reviewer suggested that the explanation of the impact scoring system should have been included within the instructions sent over email rather than in the resolution criteria on Metaculus’ website so that they could have read it before reading the proposal. Another reviewer suggested that it would have been simpler to submit their forecasts through the same Google form that they used to submit their explanations rather than through Metaculus’ website.
Based on this feedback, we would recommend that future implementations streamline their submission process to a single platform and provide a more extensive set of instructions rather than seeding information across different steps of the review process. Training sessions, which science funding agencies typically conduct, would be a good supplement to written instructions.
Appendix C: Total Expected Utility Calculations
To calculate the total expected utility, we first converted all of the impact scores into utility by taking two to the exponential of the impact score, since the impact scoring system is base 2 exponential:
Utility=2Impact Score.
We then were able to average the utilities for each milestone and conduct additional calculations.
To calculate the total utility of each milestone, ui, we averaged the social utility and the scientific utility of the milestone:
ui = (Social Utility + Scientific Utility)/2.
The total expected utility (TEU) of a proposal with two milestones can be calculated according to the general equation:
TEU = u1P(m1 ∩ not m2) + u2P(m2 ∩ not m1) + (u1+u2)P(m1m2),
where P(mi) represents the probability of success of milestone i and
P(m1 ∩ not m2) = P(m1) – P(m1 ∩ m2)
P(m2 ∩ not m1) = P(m2) – P(m1 ∩ m2).
For sequential milestones, milestone 2 is defined as inclusive of milestone 1 and wholly dependent on the success of milestone 1, so this means that
u2, seq = u1+u2
P(m2) = Pseq(m1 ∩ m2)
P(m2 ∩ not m1) = 0.
Thus, the total expected utility of sequential milestones can be simplified as
TEU = u1P(m1)-u1P(m2) + (u2, seq)P(m2)
TEU = u1P(m1) + (u2, seq-u1)P(m2)
This can be generalized to
TEUseq = Σi(ui, seq-ui-1, seq)P(mi).
Otherwise, the total expected utility can be simplified to
TEU = u1P(m1) + u2P(m2) – (u1+u2)P(m1 ∩ m2).
For independent outcomes, we assume
Pind(m1 ∩ m2) = P(m1)P(m2),
so
TEUind = u1P(m1) + u2P(m2) – (u1+u2)P(m1)P(m2).
To present the results in Tables 1 and 2, we converted all of the utility values back into the impact score scale by taking the log base 2 of the results.
Expected Utility Forecasting for Science Funding
The typical science grantmaker seeks to maximize their (positive) impact with a limited amount of money. The decision-making process for how to allocate that funding requires them to consider the different dimensions of risk and uncertainty involved in science proposals, as described in foundational work by economists Chiara Franzoni and Paula Stephan. The Von Neumann-Morgenstern utility theorem implies that there exists for the grantmaker — or the peer reviewer(s) assessing proposals on their behalf — a utility function whose expected value they will seek to maximize.
Common frameworks for evaluating proposals leave this utility function implicit, often evaluating aspects of risk, uncertainty, and potential value independently and qualitatively. Empirical work has suggested that such an approach may lead to biases, resulting in funding decisions that deviate from grantmakers’ ultimate goals. An expected utility approach to reviewing science proposals aims to make that implicit decision-making process explicit, and thus reduce biases, by asking reviewers to directly predict the probability and value of different potential outcomes occurring. Implementing this approach through forecasting brings the added benefits of providing (1) a resolution and scoring process that could help incentivize reviewers to make better, more accurate predictions over time and (2) empirical estimates of reviewers’ accuracy and tendency to over or underestimate the value and probability of success of proposals.
At the Federation of American Scientists, we are currently piloting this approach on a series of proposals in the life sciences that we have collected for Focused Research Organizations (FROs), a new type of non-profit research organization designed to tackle challenges that neither academia or industry is incentivized to work on. The pilot study was developed in collaboration with Metaculus, a forecasting platform and aggregator, and is hosted on their website. In this paper, we provide the detailed methodology for the approach that we have developed, which builds upon Franzoni and Stephan’s work, so that interested grantmakers may adapt it for their own purposes. The motivation for developing this approach and how we believe it may help address biases against risk in traditional peer review processes is discussed in our article “Risk and Reward in Peer Review”.
Defining Outcomes
To illustrate how an expected utility forecasting approach could be applied to scientific proposal evaluation, let us first imagine a research project consisting of multiple possible outcomes or milestones. In the most straightforward case, the outcomes that could arise are mutually exclusive (i.e., only a single one will be observed). Indexing each outcome with the letter 𝑖, we can define the expected value of each as the product of its value (or utility; 𝓊𝑖) and the probability of it occurring, 𝑃(𝑚𝑖). Because the outcomes in this example are mutually exclusive, the total expected utility (TEU) of the proposed project is the sum of the expected value of each outcome1:
𝑇𝐸𝑈 = 𝛴𝑖𝓊𝑖𝑃(𝑚𝑖).
However, in most cases, it is easier and more accurate to define the range of outcomes of a research project as a set of primary and secondary outcomes or research milestones that are not mutually exclusive, and can instead occur in various combinations.
For instance, science proposals usually highlight the primary outcome(s) that they aim to achieve, but may also involve important secondary outcome(s) that can be achieved in addition to or instead of the primary goals. Secondary outcomes can be a research method, tool, or dataset produced for the purpose of achieving the primary outcome; a discovery made in the process of pursuing the primary outcome; or an outcome that researchers pivot to pursuing as they obtain new information from the research process. As such, primary and secondary outcomes are not necessarily mutually exclusive. In the simplest scenario with just two outcomes (either two primary or one primary and one secondary), the total expected utility becomes
𝑇𝐸𝑈 = 𝓊1𝑃(𝑚1⋂ not 𝑚2) + 𝓊2𝑃(𝑚2⋂ not 𝑚1) + (𝓊1 + 𝓊2)𝑃(𝑚1⋂𝑚2),
𝑇𝐸𝑈 = 𝓊1𝑃(𝑚1) – (𝑚1⋂ 𝑚2)) + 𝓊2𝑃(𝑚2) – 𝑃(𝑚1⋂ 𝑚2)) + (𝓊1 + 𝓊2)𝑃(𝑚1⋂𝑚2)
𝑇𝐸𝑈 = 𝓊1𝑃(𝑚1) + 𝓊2𝑃(𝑚2) – (𝓊1 + 𝓊2)𝑃(𝑚1⋂𝑚2).
As the number of outcomes increases, the number of joint probability terms increases as well. Assuming the outcomes are independent though, they can be reduced to the product of the probabilities of individual outcomes. For example,
𝑃(𝑚1⋂𝑚2) = 𝑃(𝑚1) * 𝑃(𝑚2)
On the other hand, milestones are typically designed to build upon one another, such that achieving later milestones necessitates the achievement of prior milestones. In these cases, the value of later milestones typically includes the value of prior milestones: for example, the value of demonstrating a complete pilot of a technology is inclusive of the value of demonstrating individual components of that technology. The total expected utility can thus be defined as the sum of the product of the marginal utility of each additional milestone and its probability of success:
𝑇𝐸𝑈 = 𝛴𝑖(𝓊𝑖 + 𝓊𝑖-1)𝑃(𝑚𝑖),
where 𝓊0 = 0.
Depending on the science proposal, either of these approaches — or a combination — may make the most sense for determining the set of outcomes to evaluate.
In our FRO Forecasting pilot, we worked with proposal authors to define two outcomes for each of their proposals. Depending on what made the most sense for each proposal, the two outcomes reflected either relatively independent primary and secondary goals, or sequential milestone outcomes that directly built upon one another (though for simplicity, we called all of the outcomes milestones).
Defining Probability of Success
Once the set of potential outcomes have been defined, the next step is to determine the probability of success between 0% and 100% for each outcome if the proposal is funded. A prediction of 50% would indicate the highest level of uncertainty about the outcome, whereas the closer the predicted probability of success is to 0% or 100%, the more certainty there is that the outcome will be one over the other.
Furthermore, Franzoni and Stephan decompose probability of success into two components: the probability that the outcome can actually occur in nature or reality and the probability that the proposed methodology will succeed in obtaining the outcome (conditional on it being possible in nature). The total probability is then the product of these two components:
𝑃(𝑚𝑖) = 𝑃nature(𝑚𝑖) * 𝑃proposal(𝑚𝑖)
Depending on the nature of the proposal (e.g., more technology-driven, or more theoretical/discovery driven), each component may be more or less relevant. For example, our forecasting pilot includes a proposal to perform knockout validation of renewable antibodies for 10,000 to 15,000 human proteins; for this project, 𝑃nature(𝑚𝑖) approaches 1 and 𝑃proposal(𝑚𝑖) drives the overall probability of success.
Defining Utility
Similarly, the value of an outcome can be separated into its impact on the scientific field and its impact on society at large. Scientific impact aims to capture the extent to which a project advances the frontiers of knowledge, enables new discoveries or innovations, or enhances scientific capabilities or methods. Social impact aims to capture the extent to which a project contributes to solving important societal problems, improving well-being, or advancing social goals.
In both of these cases, determining the value of an outcome entails some subjective preferences, so there is no “correct” choice, at least mathematically speaking. However, proxy metrics may be helpful in considering impact. Though each is imperfect, one could consider citations of papers, patents on tools or methods, or users of method, tools, and datasets as proxies of scientific impact. For social impact, some proxy metrics that one might consider are the value of lives saved, the cost of illness prevented, the number of job-years of employment generated, economic output in terms of GDP, or the social return on investment.
The approach outlined by Franzoni and Stephan asks reviewers to assess scientific and social impact on a linear scale (0-100), after which the values can be averaged to determine the overall impact of an outcome. However, we believe that an exponential scale better captures the tendency in science for a small number of research projects to have an outsized impact and provides more room at the top end of the scale for reviewers to increase the rating of the proposals that they believe will have an exceptional impact.
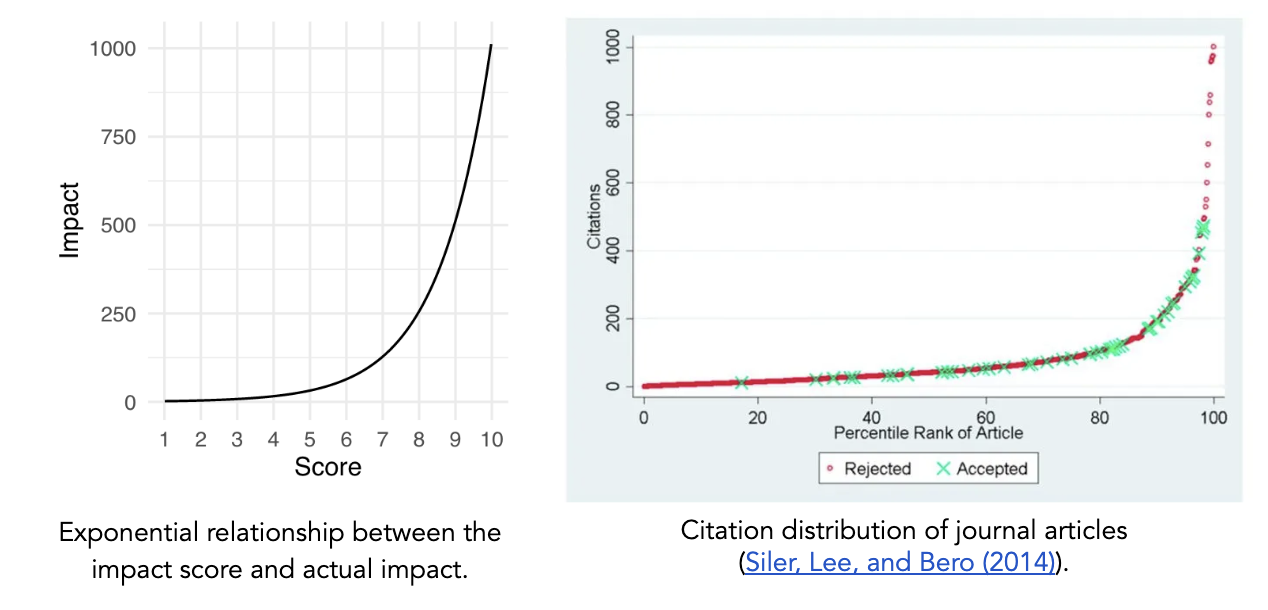
As such, for our FRO Forecasting pilot, we chose to use a framework in which a simple 1–10 score corresponds to real-world impact via a base 2 exponential scale. In this case, the overall impact score of an outcome can be calculated according to
𝓊𝑖 = log[2science impact of 𝑖 + 2social impact of 𝑖] – 1.
For an exponential scale with a different base, one would substitute that base for two in the above equation. Depending on each funder’s specific understanding of impact and the type(s) of proposals they are evaluating, different relationships between scores and utility could be more appropriate.
In order to capture reviewers’ assessment of uncertainty in their evaluations, we asked them to provide median, 25th, and 75th percentile predictions for impact instead of a single prediction. High uncertainty would be indicated by a narrow confidence interval, while low uncertainty would be indicated by a wide confidence interval.
Determining the “But For” Effect of Funding
The above approach aims to identify the highest impact proposals. However, a grantmaker may not want to simply fund the highest impact proposals; rather, they may be most interested in understanding where their funding would make the highest impact — i.e., their “but for” effect. In this case, the grantmaker would want to fund proposals with the maximum difference between the total expected utility of the research proposal if they chose to funded it versus if they chose not to:
“But For” Impact = 𝑇𝐸𝑈(funding) – 𝑇𝐸𝑈(no funding).
For TEU(funding), the probability of the outcome occurring with this specific grantmaker’s funding using the proposed approach would still be defined as above
𝑃(𝑚𝑖 | funding) = 𝑃nature(𝑚𝑖) * 𝑃proposal(𝑚𝑖),
but for 𝑇𝐸𝑈(no funding), reviewers would need to consider the likelihood of the outcome being achieved through other means. This could involve the outcome being realized by other sources of funding, other researchers, other approaches, etc. Here, the probability of success without this specific grantmaker’s funding could be described as
𝑃(𝑚𝑖 | no funding) = 𝑃nature(𝑚𝑖) * 𝑃other mechanism(𝑚𝑖).
In our FRO Forecasting pilot, we assumed that 𝑃other mechanism(𝑚𝑖) ≈ 0. The theory of change for FROs is that there exists a set of research problems at the boundary of scientific research and engineering that are not adequately supported by traditional research and development models and are unlikely to be pursued by academia or industry. Thus, in these cases it is plausible to assume that,
𝑃(𝑚𝑖 | no funding) ≈ 0
𝑇𝐸𝑈(no funding) ≈ 0
“But For” Impact ≈ 𝑇𝐸𝑈(funding).
This assumption, while not generalizable to all contexts, can help reduce the number of questions that reviewers have to consider — a dynamic which we explore further in the next section.
Designing Forecasting Questions
Once one has determined the total expected utility equation(s) relevant for the proposal(s) that they are trying to evaluate, the parameters of the equation(s) must be translated into forecasting questions for reviewers to respond to. In general, for each outcome, reviewers will need to answer the following four questions:
- If this proposal is funded, what is the probability that this outcome will occur?
- If this proposal is not funded, what is the probability that this outcome will still occur?
- What will be the scientific impact of this outcome occurring?
- What will be the social impact of this outcome occurring?
For the probability questions, one could alternatively ask reviewers about the different probability components (𝑃nature(𝑚𝑖), 𝑃proposal(𝑚𝑖), 𝑃other mechanism(𝑚𝑖), etc.), but in most cases it will be sufficient — and simpler for the reviewer — to focus on the top-level probabilities that feed into the TEU calculation.
In order for the above questions to tap into the benefits of the forecasting framework, they must be resolvable. Resolving the forecasting questions means that at a set time in the future, reviewers’ predictions will be compared to a ground truth based on the actual events that have occurred (i.e., was the outcome actually achieved and, if so, what was its actual impact?). Consequently, reviewers will need to be provided with the resolution date and the resolution criteria for their forecasts.
Resolution of the probability-based questions hinges mostly on a careful and objective definition of the potential outcomes, and is otherwise straightforward — though note that only one of the probability questions will be resolved, since they are mutually exclusive. The optimal resolution of the scientific and social impact questions may depend on the context of the project and the chosen approach to defining utility. A widely applicable approach is to resolve the utility forecasts by having either program managers or subject matter experts evaluate the results of the completed project and score its impact at the resolution date.
For our pilot, we asked forecasting questions only about the probability of success given funding (question 1 above) and the scientific and social impact of each outcome (questions 3 and 4); since we assumed that the probability of success without funding was zero, we did not ask question 2. Because outcomes for the FRO proposals were designed to be either independent or sequential, we did not have to ask additional questions on the joint probability of multiple outcomes being achieved. We chose to resolve our impact questions with a post-project panel of subject matter experts.
Additional Considerations
In general, there is a tradeoff in implementing this approach between simplicity and thoroughness, efficiency and accuracy. Here are some additional considerations on that tradeoff for those looking to use this approach:
- The responsibility of determining the range of potential outcomes for a proposal could be assigned to three different parties: the proposal author, the proposal reviewers, or the program manager. First, grantmakers could ask proposal authors to comprehensively define within their proposal the potential primary and secondary outcomes and/or project milestones. Alternatively, reviewers could be allowed to individually — or collectively — determine what they see as the full range of potential outcomes. The third option would be for program managers to define the potential outcomes based on each proposal, with or without input from proposal authors. In our pilot, we chose to use the third approach with input from proposal authors, since it simplified the process for reviewers and allowed us to limit the number of outcomes under consideration to a manageable amount.
- In many cases, a “failed” or null outcome may still provide meaningful value by informing other scientists that the research method doesn’t work or that the hypothesis is unlikely to be true. Considering the replication crises in multiple fields, this could be an important and unaddressed aspect of peer review. Grantmakers could choose to ask reviewers to consider the value of these null outcomes alongside other outcomes to obtain a more complete picture of the project’s utility. We chose not to address this consideration in our pilot for the sake of limiting the evaluation burden on reviewers.
- If grant recipients’ are permitted greater flexibility in their research agendas, this expected value approach could become more difficult to implement, since reviewers would have to consider a wider and more uncertain range of potential outcomes. This was not the case for our FRO Forecasting pilot, since FROs are designed to have specific and well-defined research goals.
Other Similar Efforts
Currently, forecasting is an approach rarely used in grantmaking. Open Philanthropy is the only grantmaking organization we know of that has publicized their use of internal forecasts about grant-related outcomes, though their forecasts do not directly influence funding decisions and are not specifically of expected value. Franzoni and Stephan are also currently piloting their Subjective Expected Utility approach with Novo Nordisk.
Conclusion
Our goal in publishing this methodology is for interested grantmakers to freely adapt it to their own needs and iterate upon our approach. We hope that this paper will help start a conversation in the science research and funding communities that leads to further experimentation. A follow up report will be published at the end of the FRO Forecasting pilot sharing the results and learnings from the project.
Acknowledgements
We’d like to thank Peter Mühlbacher, former research scientist at Metaculus, for his meticulous feedback as we developed this approach and for his guidance in designing resolvable forecasting questions. We’d also like to thank the rest of the Metaculus team for being open to our ideas and working with us on piloting this approach, the process of which has helped refine our ideas to their current state. Any mistakes here are of course our own.