Fighting Fakes and Liars’ Dividends: We Need To Build a National Digital Content Authentication Technologies Research Ecosystem
The U.S. faces mounting challenges posed by increasingly sophisticated synthetic content. Also known as digital media ( images, audio, video, and text), increasingly, these are produced or manipulated by generative artificial intelligence (AI). Already, there has been a proliferation in the abuse of generative AI technology to weaponize synthetic content for harmful purposes, such as financial fraud, political deepfakes, and the non-consensual creation of intimate materials featuring adults or children. As people become less able to distinguish between what is real and what is fake, it has become easier than ever to be misled by synthetic content, whether by accident or with malicious intent. This makes advancing alternative countermeasures, such as technical solutions, more vital than ever before. To address the growing risks arising from synthetic content misuse, the National Institute of Standards and Technology (NIST) should take the following steps to create and cultivate a robust digital content authentication technologies research ecosystem: 1) establish dedicated university-led national research centers, 2) develop a national synthetic content database, and 3) run and coordinate prize competitions to strengthen technical countermeasures. In turn, these initiatives will require 4) dedicated and sustained Congressional funding of these initiatives. This will enable technical countermeasures to be able to keep closer pace with the rapidly evolving synthetic content threat landscape, maintaining the U.S.’s role as a global leader in responsible, safe, and secure AI.
Challenge and Opportunity
While it is clear that generative AI offers tremendous benefits, such as for scientific research, healthcare, and economic innovation, the technology also poses an accelerating threat to U.S. national interests. Generative AI’s ability to produce highly realistic synthetic content has increasingly enabled its harmful abuse and undermined public trust in digital information. Threat actors have already begun to weaponize synthetic content across a widening scope of damaging activities to growing effect. Project losses from AI-enabled fraud are anticipated to reach up to $40 billion by 2027, while experts estimate that millions of adults and children have already fallen victim to being targets of AI-generated or manipulated nonconsensual intimate media or child sexual abuse materials – a figure that is anticipated to grow rapidly in the future. While the widely feared concern of manipulative synthetic content compromising the integrity of the 2024 U.S. election did not ultimately materialize, malicious AI-generated content was nonetheless found to have shaped election discourse and bolstered damaging narratives. Equally as concerning is the accumulative effect this increasingly widespread abuse is having on the broader erosion of public trust in the authenticity of all digital information. This degradation of trust has not only led to an alarming trend of authentic content being increasingly dismissed as ‘AI-generated’, but has also empowered those seeking to discredit the truth, or what is known as the “liar’s dividend”.
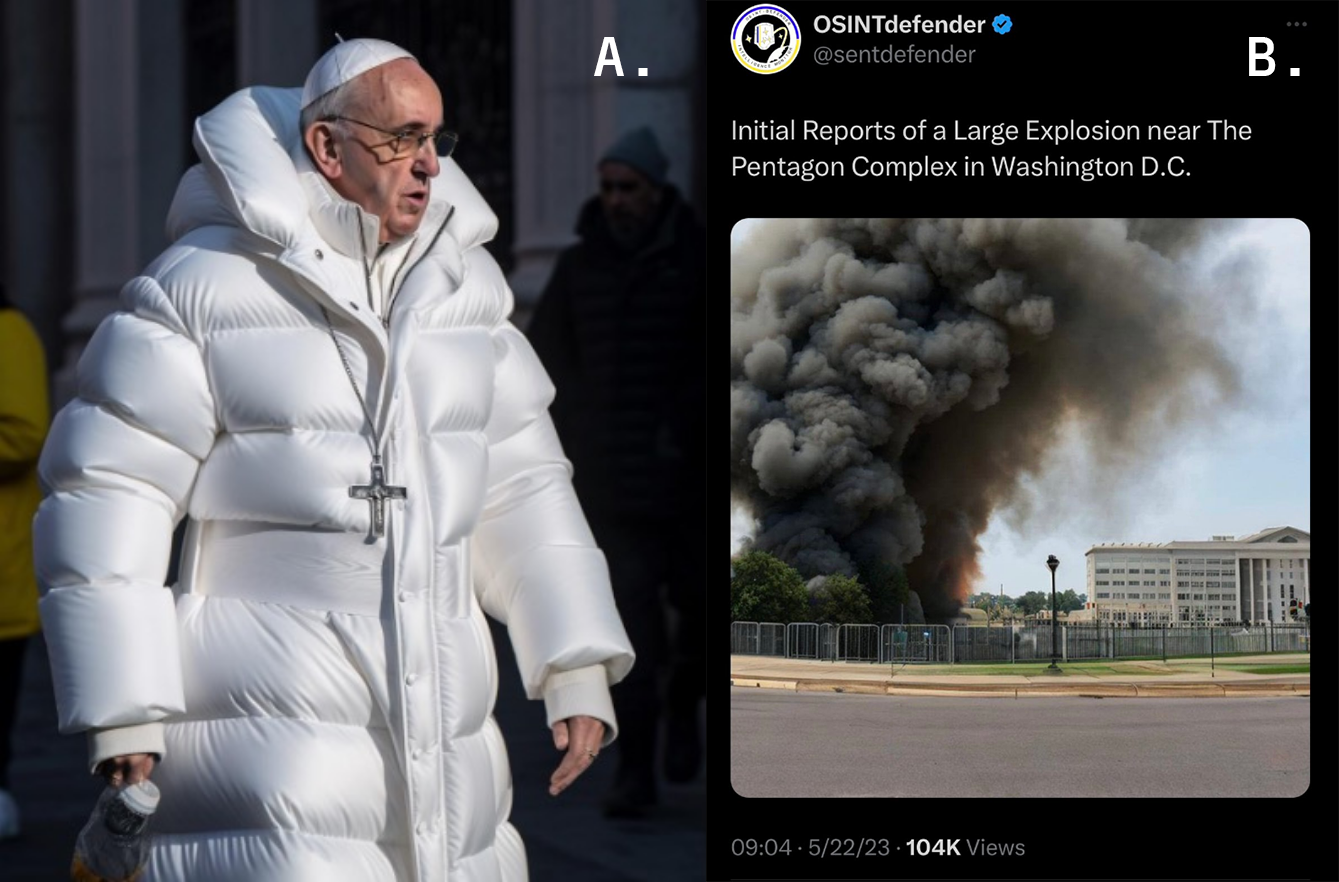
A. In March 2023, a humorous synthetic image of Pope Francis, first posted on Reddit by creator Pablo Xavier, wearing a Balenciaga coat quickly went viral across social media.
B. In May 2023, this synthetic image was duplicitously published on X as an authentic photograph of an explosion near the Pentagon. Before being debunked by authorities, the image’s widespread circulation online caused significant confusion and even led to a temporary dip in the U.S. stock market.
Research has demonstrated that current generative AI technology is able to produce synthetic content sufficiently realistic enough that people are now unable to reliably distinguish between AI-generated and authentic media. It is no longer feasible to continue, as we currently do, to rely predominantly on human perception capabilities to protect against the threat arising from increasingly widespread synthetic content misuse. This new reality only increases the urgency of deploying robust alternative countermeasures to protect the integrity of the information ecosystem. The suite of digital content authentication technologies (DCAT), or techniques, tools, and methods that seek to make the legitimacy of digital media transparent to the observer, offers a promising avenue for addressing this challenge. These technologies encompass a range of solutions, from identification techniques such as machine detection and digital forensics to classification and labeling methods like watermarking or cryptographic signatures. DCAT also encompasses technical approaches that aim to record and preserve the origin of digital media, including content provenance, blockchain, and hashing.
Evolution of Synthetic Media

Published in 2018, this now infamous PSA sought to illustrate the dangers of synthetic content. It shows an AI-manipulated video of President Obama, using narration from a comedy sketch by comedian Jordan Peele.

In 2020, a hobbyist creator employed an open-source generative AI model to ‘enhance’ the Hollywood CGI version of Princess Leia in the film Rouge One.

The hugely popular Tiktok account @deeptomcruise posts parody videos featuring a Tom Cruise imitator face-swapped with the real Tom Cruise’s real face, including this 2022 video, racking up millions of views.

The 2024 film Here relied extensively on generative AI technology to de-age and face-swap actors in real-time as they were being filmed.
Robust DCAT capabilities will be indispensable for defending against the harms posed by synthetic content misuse, as well as bolstering public trust in both information systems and AI development. These technical countermeasures will be critical for alleviating the growing burden on citizens, online platforms, and law enforcement to manually authenticate digital content. Moreover, DCAT will be vital for enforcing emerging legislation, including AI labeling requirements and prohibitions on illegal synthetic content. The importance of developing these capabilities is underscored by the ten bills (see Fig 1) currently under Congressional consideration that, if passed, would require the employment of DCAT-relevant tools, techniques, and methods.
However, significant challenges remain. DCAT capabilities need to be improved, with many currently possessing weaknesses or limitations such brittleness or security gaps. Moreover, implementing these countermeasures must be carefully managed to avoid unintended consequences in the information ecosystem, like deploying confusing or ineffective labeling to denote the presence of real or fake digital media. As a result, substantial investment is needed in DCAT R&D to develop these technical countermeasures into an effective and reliable defense against synthetic content threats.
The U.S. government has demonstrated its commitment to advancing DCAT to reduce synthetic content risks through recent executive actions and agency initiatives. The 2023 Executive Order on AI (EO 14110) mandated the development of content authentication and tracking tools. Charged by the EO 14110 to address these challenges, NIST has taken several steps towards advancing DCAT capabilities. For example, NIST’s recently established AI Safety Institute (AISI) takes the lead in championing this work in partnership with NIST’s AI Innovation Lab (NAIIL). Key developments include: the dedication of one of the U.S. Artificial Intelligence Safety Institute Consortium’s (AISIC) working groups to identifying and advancing DCAT R&D; the publication of NIST AI 100-4, which “examines the existing standards, tools, methods, and practices, as well as the potential development of further science-backed standards and techniques” regarding current and prospective DCAT capabilities; and the $11 million dedicated to international research on addressing dangers arising from synthetic content announced at the first convening of the International Network of AI Safety Institutes. Additionally, NIST’s Information Technology Laboratory (ITL) has launched the GenAI Challenge Program to evaluate and advance DCAT capabilities. Meanwhile, two pending bills in Congress, the Artificial Intelligence Research, Innovation, and Accountability Act (S. 3312) and the Future of Artificial Intelligence Innovation Act (S. 4178), include provisions for DCAT R&D.
Although these critical first steps have been taken, an ambitious and sustained federal effort is necessary to facilitate the advancement of technical countermeasures such as DCAT. This is necessary to more successfully combat the risks posed by synthetic content—both in the immediate and long-term future. To gain and maintain a competitive edge in the ongoing race between deception and detection, it is vital to establish a robust national research ecosystem that fosters agile, comprehensive, and sustained DCAT R&D.
Plan of Action
NIST should engage in three initiatives: 1) establishing dedicated university-based DCAT research centers, 2) curating and maintaining a shared national database of synthetic content for training and evaluation, as well as 3) running and overseeing regular federal prize competitions to drive innovation in critical DCAT challenges. The programs, which should be spearheaded by AISI and NAIIL, are critical for enabling the creation of a robust and resilient U.S. DCAT research ecosystem. In addition, the 118th Congress should 4) allocate dedicated funding to supporting these enterprises.
These recommendations are not only designed to accelerate DCAT capabilities in the immediate future, but also to build a strong foundation for long-term DCAT R&D efforts. As generative AI capabilities expand, authentication technologies must too keep pace, meaning that developing and deploying effective technical countermeasures will require ongoing, iterative work. Success demands extensive collaboration across technology and research sectors to expand problem coverage, maximize resources, avoid duplication, and accelerate the development of effective solutions. This coordinated approach is essential given the diverse range of technologies and methodologies that must be considered when addressing synthetic content risks.
Recommendation 1. Establish DCAT Research Institutes
NIST should establish a network of dedicated university-based research to scale up and foster long-term, fundamental R&D on DCAT. While headquartered at leading universities, these centers would collaborate with academic, civil society, industry, and government partners, serving as nationwide focal points for DCAT research and bringing together a network of cross-sector expertise. Complementing NIST’s existing initiatives like the GenAI Challenge, the centers’ research priorities would be guided by AISI and NAIIL, with expert input from the AISIC, the International Network of AISI, and other key stakeholders.
A distributed research network offers several strategic advantages. It leverages elite expertise from industry and academia, and having permanent institutions dedicated to DCAT R&D enables the sustained, iterative development of authentication technologies to better keep pace with advancing generative AI capabilities. Meanwhile, central coordination by AISI and NAIIL would also ensure comprehensive coverage of research priorities while minimizing redundant efforts. Such a structure provides the foundation for a robust, long-term research ecosystem essential for developing effective countermeasures against synthetic content threats.
There are multiple pathways via which dedicated DCAT research centers could be stood up. One approach is direct NIST funding and oversight, following the model of Carnegie Mellon University’s AI Cooperative Research Center. Alternatively, centers could be established through the National AI Research Institutes Program, similar to the University of Maryland’s Institute for Trustworthy AI in Law & Society, leveraging NSF’s existing partnership with NIST.
The DCAT research agenda could be structured in two ways. Informed by NIST’s report NIST AI 100-4, a vertical approach could be taken to centers’ research agendas, assigning specific technologies to each center (e.g. digital watermarking, metadata recording, provenance data tracking, or synthetic content detection). Centers would focus on all aspects of a specific technical capability, including: improving the robustness and security of existing countermeasures; developing new techniques to address current limitations; conducting real-world testing and evaluation, especially in a cross-platform environment; and studying interactions with other technical safeguards and non-technical countermeasures like regulations or educational initiatives. Conversely, a horizontal approach might seek to divide research agendas across areas such as: the advancement of multiple established DACT techniques, tools, and methods; innovation of novel techniques, tools, and methods; testing and evaluation of combined technical approaches in real-world settings; examining the interaction of multiple technical countermeasures with human factors such as label perception and non-technical countermeasures. While either framework provides a strong foundation for advancing DCAT capabilities, given institutional expertise and practical considerations, a hybrid model combining both approaches is likely the most feasible option.
Recommendation 2. Build and Maintain a National Synthetic Content Database
NIST should also build and maintain a national database of synthetic content database to advance and accelerate DCAT R&D, similar to existing federal initiatives such as NIST’s National Software Reference Library and NSF’s AI Research Resource pilot. Current DCAT R&D is severely constrained by limited access to diverse, verified, and up-to-date training and testing data. Many researchers, especially in academia, where a significant portion of DCAT research takes place, lack the resources to build and maintain their own datasets. This results in less accurate and more narrowly applicable authentication tools that struggle to keep pace with rapidly advancing AI capabilities.
A centralized database of synthetic and authentic content would accelerate DCAT R&D in several critical ways. First, it would significantly alleviate the effort on research teams to generate or collect synthetic data for training and evaluation, encouraging less well-resourced groups to conduct research as well as allowing researchers to focus more on other aspects of R&D. This includes providing much-needed resources for the NIST-facilitated university-based research centers and prize competitions proposed here. Moreover, a shared database would be able to provide more comprehensive coverage of the increasingly varied synthetic content being created today, permitting the development of more effective and robust authentication capabilities. The database would be useful for establishing standardized evaluation metrics for DCAT capabilities – one of NIST’s critical aims for addressing the risks posed by AI technology.
A national database would need to be comprehensive, encompassing samples of both early and state-of-the-art synthetic content. It should have controlled laboratory-generated along with verified “in the wild” or real world synthetic content datasets, including both benign and potentially harmful examples. Further critical to the database’s utility is its diversity, ensuring synthetic content spans multiple individual and combined modalities (text, image, audio, video) and features varied human populations as well as a variety of non-human subject matter. To maintain the database’s relevance as generative AI capabilities continue to evolve, routinely incorporating novel synthetic content that accurately reflects synthetic content improvements will also be required.
Initially, the database could be built on NIST’s GenAI Challenge project work, which includes “evolving benchmark dataset creation”, but as it scales up, it should operate as a standalone program with dedicated resources. The database could be grown and maintained through dataset contributions by AISIC members, industry partners, and academic institutions who have either generated synthetic content datasets themselves or, as generative AI technology providers, with the ability to create the large-scale and diverse datasets required. NIST would also direct targeted dataset acquisition to address specific gaps and evaluation needs.
Recommendation 3. Run Public Prize Competitions on DCAT Challenges
Third, NIST should set up and run a coordinated prize competition program, while also serving as federal oversight leads for prize competitions run by other agencies. Building on existing models such as the DARPA SemaFor’s AI FORCE and the FTC’s Voice Cloning challenge, the competitions would address expert-identified priorities as informed by the AISIC, International Network of AISI, and proposed DCAT national research centers. Competitions represent a proven approach to spurring innovation for complex technical challenges, enabling the rapid identification of solutions through diverse engagement. In particular, monetary prize competitions are especially successful at ensuring engagement. For example, the 2019 Kaggle Deepfake Detection competition, which had a prize of $1 million, fielded twice as many participants as the 2024 competition, which gave no cash prize.
By providing structured challenges and meaningful incentives, public competitions can accelerate the development of critical DCAT capabilities while building a more robust and diverse research community. Such competitions encourage novel technical approaches, rapid testing of new methods, facilitate the inclusion of new or non-traditional participants, and foster collaborations. The more rapid-cycle and narrow scope of the competitions would also complement the longer-term and broader research being conducted by the national DCAT research centers. Centralized federal oversight would also prevent the implementation gaps which have occurred in past approved federal prize competitions. For instance, the 2020 National Defense Authorization Act (NDAA) authorized a $5 million machine detection/deepfakes prize competition (Sec. 5724), and the 2024 NDAA authorized a ”Generative AI Detection and Watermark Competition” (Sec. 1543). However, neither prize competition has been carried out, and Watermark Competition has now been delayed to 2025. Centralized oversight would also ensure that prize competitions are run consistently to address specific technical challenges raised by expert stakeholders, encouraging more rapid development of relevant technical countermeasures.
Some examples of possible prize competitions might include: machine detection and digital forensic methods to detect partial or fully AI-generated content across single or multimodal content; assessing the robustness, interoperability, and security of watermarking and other labeling methods across modalities; testing innovations in tamper-evident or -proofing content provenance tools and other data origin techniques. Regular assessment and refinement of competition categories will ensure continued relevance as synthetic content capabilities evolve.
Recommendation 4. Congressional Funding of DCAT Research and Activities
Finally, the 118th Congress should allocate funding for these three NIST initiatives in order to more effectively establish the foundations of a strong DCAT national research infrastructure. Despite widespread acknowledgement of the vital role of technical countermeasures in addressing synthetic content risks, the DCAT research field remains severely underfunded. Although recent initiatives, such as the $11 million allocated to the International Network of AI Safety Institutes, are a welcome step in the right direction, substantially more investment is needed. Thus far, the overall financing of DCAT R&D has been only a drop in the bucket when compared to the many billions of dollars being dedicated by industry alone to improve generative AI technology.
This stark disparity between investment in generative AI versus DCAT capabilities presents an immediate opportunity for Congressional action. To address the widening capability gap, and to support pending legislation which will be reliant on technical countermeasures such as DCAT, the 118th Congress should establish multi-year appropriations with matching fund requirements. This will encourage private sector investment and permit flexible funding mechanisms to address emerging challenges. This funding should be accompanied by regular reporting requirements to track progress and impact.
One specific action that Congress could take to jumpstart DCAT R&D investment would be to reauthorize and appropriate the budget that was earmarked for the unexecuted machine detection competition it approved in 2020. Despite the 2020 NDAA authorizing $5 million for it, no SAC-D funding was allocated, and the competition never took place. Another action would be for Congress to explicitly allocate prize money for the watermarking competition authorized by the 2024 NDAA, which currently does not have any monetary prize attached to it, to encourage higher levels of participation in the competition when it takes place this year.
Conclusion
The risks posed by synthetic content present an undeniable danger to U.S. national interests and security. Advancing DCAT capabilities is vital for protecting U.S. citizens against both the direct and more diffuse harms resulting from the proliferating misuse of synthetic content. A robust national DCAT research ecosystem is required to accomplish this. Critically, this is not a challenge that can be addressed through one-time solutions or limited investment—it will require continuous work and dedicated resources to ensure technical countermeasures keep pace alongside increasingly sophisticated synthetic content threats. By implementing these recommendations with sustained federal support and investment, the U.S. will be able to more successfully address current and anticipated synthetic content risks, further reinforcing its role as a global leader in responsible AI use.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
It is in the interests of the United States to appropriately protect information that needs to be protected while maintaining our participation in new discoveries to maintain our competitive advantage.
Our analysis of federal AI governance across administrations shows that divergent compliance procedures and uneven institutional capacity challenge the government’s ability to deploy AI in ways that uphold public trust.
To secure the U.S. bio-infrastructure, maintain global leadership in biotechnology, and safeguard American citizens from emerging threats to their privacy, the federal government must modernize its approach to human genetic and biological data.
From use to testing to deployment, the scaffolding for responsible integration of AI into high-risk use cases is just not there.