An open letter to the new NYC PIT Crew
When government works well, people barely notice; it’s just easy. This is what New Yorkers deserve—a responsive government is not only about good policy; it’s about the ability to deliver public services that are accessible, simple to navigate, and meets their needs. We are practitioners who have built, led, and supported successful digital service initiatives around the country, including leading IRS’ Direct File—which is why we are so encouraged by the launch of the NYC Public Interest Technology (PIT) Crew.
This initiative can improve services for millions. We are excited to see this investment in:
- People-centered delivery. The fastest way to build trust is to make government easier to navigate—trust is built or broken at the counter, on the phone, in the app that either works or doesn’t. Treating service delivery as a priority and putting people’s needs at the center will help the PIT Crew deliver for New Yorkers.
- Building lasting government capacity. The most responsive governments invest in their own people. Building in-house expertise in product management, engineering, design, and data creates the internal capacity to improve services, adapt to change, and reduce costly outside vendors—building public services that are by and for New Yorkers.
- New ways of working. The best digital service teams don’t just build better technology, they rethink how government works by organizing around the needs of people rather than the boundaries of bureaucracy. This is a new model for government—and what’s being built in New York can help cities around the U.S. learn how to deliver better services.
Recently, the Federation of American Scientists and the Beeck Center for Social Impact + Innovation at Georgetown University talked to more than 100 government leaders who built and led digital service initiatives across local, state, and federal government. Their experiences revealed important information about the conditions that allow public interest tech projects like this to create lasting impact.
The announcement reflects many of those lessons already. We hope you’ll consider several principles that are essential to radically redefining the relationship between people and their government:
- Set a standard that changes expectations of government. Take a page from the work of Direct File, which increased trust in the IRS by 86%—don’t just build services that are better than before, build services that are so intuitive, accessible, and reliable that New Yorkers expect every interaction with government to meet the same standard.
- Move beyond agency siloes. Organize around services, not agencies. People come to government at different moments in their lives: a new baby, a lost job, a business they’re trying to start. The most effective digital service teams organize their work, including funding, staffing, and operations, around the outcomes that public services are trying to achieve.
- Empower and hold accountable service leaders. The only way to scale your impact is to empower teams and hold them transparently accountable. The highest performing organizations succeed because a single team is empowered to own a service end-to-end and answers for its success. Giving teams clear responsibility for outcomes—paired with the authority to actually make changes and tough choices—creates the conditions for faster, better, and more durable results.
- Live or die by good gov-ops. Move to outcomes-based everything—from hiring, to procurement, to budgeting and, of course, product launches, taking an agile, outcomes and deadline-driven approach will ensure delivery happens on time. We are encouraged by the COGE and believe a similar, challenging approach to all types of policies and processes should be taken.
- Go big or go home. Be bold enough to become the model. You have the opportunity to not just improve New Yorker City’s services, but to create open, reusable approaches—from open source public options to services with 100% uptake—that raise the standard for governments anywhere.
This is a tremendous opportunity to redefine what people expect from government, and in doing so, inspire cities across the country to raise their own ambitions. We are excited to see this initiative lead the way and look forward to cheering your success.
The Federation of American Scientists (FAS) is a nonpartisan science and technology policy organization dedicated to bringing evidence-based expertise into government to help solve the country’s biggest challenges.
The Beeck Center for Social Impact + Innovation at Georgetown University is dedicated to improving how people experience government by strengthening the design and delivery of public services.
Research Agenda: Estimating the U.S. Government’s Return-on-Investment on Scientific Research & Development
The United States federal government invests nearly $150 billion annually in research and development. Four times ($937 billion in 2023, as estimated by NSF) this amount flows from state governments, private foundations, and corporate R&D budgets. These investments are made on the premise that they generate scientific, economic, and social returns. That premise is widely held. However, the supporting evidence generates wildly different estimates depending on the methods and available data.
That evidentiary weakness has always been a limitation. It is now, increasingly, a liability. Federal R&D budgets are subject to scrutiny of an intensity not seen in decades. Longstanding assumptions about the appropriate scale and direction of public investment in science are being actively contested across branches of government. In that environment, the inability to answer basic questions about what research investment produces – for whom, on what timeline, and compared to what alternative – leaves the field without the tools it needs to make its case. This agenda is designed, in part, to begin building those tools.
The literature on the returns to R&D investment has grown substantially over the past three decades. The work began in the 1950s with papers published by Zvi Griliches estimating the social rate of return to research activity. Economists have since estimated rates of return to federally funded basic research. Health economists have traced the pathway from NIH appropriations to pharmaceutical innovation to reductions in mortality. Innovation scholars have documented knowledge spillovers across firms, sectors, and national borders. This body of work has been useful, and has provided important empirical grounding for sustained public investment in science. But it has also left critical questions underexplored, and has not kept pace with the demands that policymakers, funders, and program administrators now place on evidence and evaluation.
Three gaps are especially consequential. First, the existing literature is concentrated on a narrow band of measurable outcomes – financial returns, patent counts, publication rates, and selected health outcomes – while the full range of value that R&D investment generates remains largely unmeasured. Social benefits, distributional effects, environmental outcomes, and the intrinsic value of scientific knowledge itself are acknowledged in principle but rarely captured in practice. The result is an evaluation vocabulary that systematically understates what investing in public research produces, and that is poorly suited to the constituencies who most need to understand it. Further, the paucity of data on the returns on investment in research makes it difficult to make informed decisions on future funding levels and allocations.
Second, the existing literature has made limited progress on the foundational problem of causal attribution. Demonstrating that an investment generated value is not the same as demonstrating that it generated value that would not otherwise have existed. The counterfactual question – what would have happened in the absence of a given funding decision – is rarely, if ever, answered with the rigor that credible evaluation requires. Where causal methods have been applied, they have typically addressed narrow, well-defined questions; broader claims about program or agency-level returns rest on methodological assumptions that are often implicit and rarely interrogated.
Third, the producers and consumers of evidence on the ROI of R&D are poorly connected. Federal agency program officers, congressional appropriators, budget examiners, state science advisors, philanthropic funders, and university research administrators all face versions of the same underlying questions – about returns, timescales, counterfactuals, spillovers, and accountability – but they ask those questions in different registers, with different data needs, on different timelines, and with different tolerances for methodological uncertainty. Research that is designed without these customers in mind and engaged in the process tends to reach only the audiences already most predisposed to engage with it. This means that key decision-makers are often making hard choices with little-to-no high-quality evidence on hand to support their thinking.
This research agenda is a response to those gaps. It was developed through a structured process of stakeholder engagement that surfaced both the range of outcomes that R&D investment is understood to produce and the specific informational needs of the actors responsible for making, evaluating, and defending funding decisions across the public, private, and philanthropic sectors. The result is a set of eleven research questions, organized from foundational to applied, that together constitute a program of inquiry capable of substantially advancing the field’s ability to measure, attribute, and communicate the returns to R&D investment.
The agenda does not promise that all of these questions can be fully answered. Several of the most important ones – including the construction of credible counterfactuals and the valuation of non-pecuniary returns – pose methodological challenges that current tools can address only partially. A transparent research agenda must acknowledge those limits clearly, both to set appropriate expectations and to direct methodological innovation toward the places where it is most needed. What the agenda does promise is that serious, well-designed inquiry into each of these questions would produce findings that are useful – to researchers, to practitioners, and to the policymakers who ultimately determine the scale and direction of public investment in science.
Methods
The primary vehicle for developing this set of research questions was a one-day workshop hosted in February 2026. The workshop convened academics, policymakers, and policy experts to discuss where the literature stands today and where it should head in the future. It was also intended to help launch a new initiative: the Pop-Up Journal. This initiative, whose first iteration will focus on the ROI of R&D (sometimes called the Griliches Question), will aim to answer many of the questions posed by participants and in this research agenda.
During the workshop, participants engaged in a series of exercises designed to elicit answers to two key questions:
- When we consider return-on-investment from R&D, what are the outcomes we should be measuring?
- What are the research questions that, if answered, are most likely to inform the decision-making of key stakeholders?
To answer the first question, we asked participants to identify a range of possible outcomes that might be important to someone trying to understand the return of their R&D investments.
To answer the second question, we assigned small groups different “personas” to consider – ranging from Congressional staff to federal agency leaders to universities and the private sector. They grappled with not just the types of research questions that are most novel, but the ones that were most likely to be useful to decision and policy makers.
To supplement the workshop, we also conducted a series of informal one-on-one interviews with experts – researchers who might one day seek to answer questions posed in this agenda, and policymakers who might use the evidence generated.
What We Recommend for Building Better Digital Service Teams, Initiatives, and Results
There is No Unifying Theory of Change
The book Good Strategy/Bad Strategy by Richard P. Rumelt states “Good strategy works by focusing energy and resources on one, or a very few, pivotal objectives whose accomplishment will lead to a cascade of favorable outcomes.”
In every retrospective we hosted, participants bemoaned the lack of a strategy and a longer-term theory of change in their work, or “how”, tied to outcomes. No shared strategy of work and functional purpose across the federal teams – USDS, 18F/TTS, OFCIO, and beyond – led to confusion, competition for limited resources, and a focus on individual team or organizational goals rather than shared agency- or government-wide outcomes. No shared strategy for mission outcomes at the government-wide or agency level meant we heard time and time again during the retros that teams at all levels of government felt like they were missing a chance at making an even greater, deeper impact. In the absence of such shared mission outcomes, digital service teams felt like their participation was the metric for success and their activity was a substitute for long-term progress. This is emblematic of a systemic problem – digital service initiatives operate within silos, compete for limited resources and talent, and often operate at agencies that lack a clear sense of how digital service initiatives contribute to their goals, ultimately diminishing the impact.
The lack of strategy impacted not just the teammates trying to do the work, it also impacted the agencies and stakeholders digital service teams interact with. A strategy defines a set of priorities that is repeatable and accountable, making it easier to partner, delegate, and work fast; it also communicates what you don’t want to work on, transparently outlining priorities. For digital service teams, strategy was absent but should exist at multiple levels. At the highest level, it articulates the theory for how digital services contribute to societal outcomes – how digital and service design improves public health through better access to benefits such as SNAP, or simplified access to healthcare. Strategy also exists at the government-wide level, defining priorities and processes for achieving those outcomes. And at the organizational and functional level, strategy defines the logic model for how diverse teams – including crisis response, modernization, implementation, product building, and operations and maintenance – work together across government.
And now, at a moment of significant technological change and demands on government, the stakes of having no strategy at each of these levels are higher than ever. Without a clear position on AI, government won’t even get their tactics right — they’ll spend all their time debating tools instead of outcomes. A strategy doesn’t require consensus. It is a signal of what you value, and provides the concrete steps to get what you’re trying to achieve, and why — so that people can ignore it, engage with it, challenge it, or build on it.
Moving forward, the digital service community should be a part of articulating an ambitious, outcomes based strategy at each level for what we want to achieve across the country in the next 5-10-20 years; and to look at defining foundational elements that make a strategy effective: building user-centered government and how to reform our institutions to become modern, responsive organizations.
User-centered government. Digital service practitioners have spent a decade hearing firsthand what people actually want and need from government. That knowledge shouldn’t stop at delivery- it should drive the strategy. Digital service teams are uniquely positioned to define those outcomes in concrete, user-centered terms and to hold the strategy accountable to them. No strategy should be set without that perspective at the table.
Institutional (re)design. For a decade, the civic tech community launched good services inside of – and sometimes in spite of – broken institutions. Direct File worked – and yet it didn’t change the IRS. That gap between modern ways of working and working across the organization to support radical change is the opportunity to update and upgrade our government. Digital leaders have the knowledge to go further: to define what a modern agency actually looks like, how it makes decisions, how it procures, how it hires.
Defining an ambitious strategy is an urgent first step: effective strategy is built on clear, user-centered outcomes and institutions that are structured to achieve them. Placing delivery technologists at the top of our organizations to shape both service delivery and how the institutions themselves run is one of the most critical things a political leader must do. The field is navigating AI adoption, budget austerity without a framework for prioritization, and planning for the future with a radically different federal landscape. An ambitious response to this moment is worth examining on its own and we look forward to contributing and seeing what our peers discover.
As is, the Digital Government Field Cannot Scale
Over the course of engaging 100+ individuals through the Digital Services Retros project, one theme that emerged was a shared concern that the individual contributions of any one team, no matter how talented, could not scale to influence how digital services were delivered throughout the rest of an agency. While teams of talented, experienced technical professionals could turn around quality products and evangelize a few allies to their style of working, ultimately teams struggled to turn their hard-won bright spots into scalable models of working across federal agencies.
The government digital services field’s current M.O. is to rely on a relatively small and scrappy pipeline of talent who attempt to sustain their work through oral histories and few resources or tools for which they’ve managed to win temporary exceptions. Scaling quality product development and service delivery across government demands a more mature approach, replacing unpredictable patterns of work with more cohesive processes, a shared vision of quality and strong resources that support the field of civic technology professionals.
Make it as easy to hire technologists as it is to hire lawyers
Current legislation and federal civil service code stops digital service teams from being able to hire the talent they want, build or buy the tools they need, and engage with users in the manner they need to. For this reason, the civic technology field has come to rely on a series of flexibilities and exceptions in lieu of real, streamlined repeatable career pathways.
Reliance on exceptional methods (e.g., term-based hiring, ad hoc programs that get designated salary exceptions) without reforming the system to enable a streamlined and quality process for hiring is an expedient approach, but not a sustainable or scalable one.
Policy leaders, including Congress, need to stop encouraging bandaids: digital service teams were never meant to be their perpetual excuse to avoid reform. Each needs to take concerted action to align the mechanics of the executive branch with modern hiring, workflows, and procurement that force every team to reinvent the wheel.
Make it someone’s job to scale change
Everything – from hiring, to ATO (authorization to operate) processes, to onboarding and everything in between – is a one-off, making lasting change within and across agencies near impossible. Moving forward, agencies and teams need to spend a percentage of time rewiring the agency as the work happens. Service delivery is a great opportunity to model new behaviors, work in an outcomes based manner, and use momentum to make change – this should become the norm and agencies should codify these upgrades alongside delivery work. The best way should be the default way, not the workaround. One strategy to target this need is to create a scale team – a team that shares best practice and is empowered, authorized, and expected to make sure the best ways become the default way. Institutions need to learn to expect change and implement better.
Additionally, there’s no shared definition of what good looks like in government digital delivery, which means digital teams in government are effectively grading their own homework. In contrast, within the private sector, there are industry standards for service-level agreements and user experience. These aren’t necessarily uniform across every enterprise or product, however there is broad alignment of what quality delivery reflects.
Government digital teams need to define their own “industry standards” for service levels and delivery. These definitions should not pigeonhole teams into rigid processes or unnecessary metrics, but rather provide a flexible benchmark that equips teams and leaders to gauge how successful their efforts are and how they compare across government and over time. In concrete terms, this could look like expectations for down time, user satisfaction indicators, and increased uptake of services among eligible populations. These also give agency leaders a way to set expectations and give users a basis for demanding better.
Expand field resources
Even as the field grows, there is still significant work to be done to develop its size and quality through shared vocabulary, resources, training, and methodologies. Organizations like Technologists for Public Good and events like the Code for America conference are promising valuable bright spots, but the potential for building a robust, well-connected field is far from saturated.
Establishing common training and methodologies would not only make the work itself more efficient, but would also create greater worker mobility across organizations. When practitioners share a common foundation, they become more interchangeable in the best sense; technologists are able to move between roles and institutions, which in turn drives more competitive opportunities and raises the quality of the field as a whole.
We Built Digital Teams, Not Services
“Build a digital service team” they said. And they did, oftentimes with great results, change, and service delivery. Over the last 10+ years, digital service teams have added capacity to struggling agencies across the country in order to deliver critical services that may otherwise not reach their intended user. This is a worthy goal. But what was the measurement of success? Was building the team the outcome?
During the Digital Services Retros project a pattern – across all levels of government (federal, state, local) – seemed to emerge: digital service teams were set up to add needed capacity to any number of solutions or as an outcome itself. The early strategy was – land the team, expand to solve new problems.
Somewhere along the way, the digital government field lost sight of what we were solving for. The unit of success was a digital service team; the thinking was that this team of talented individuals could be put against any set of problems or outcomes. And implicitly there was a correlation between the team being the intended outcome – an agency was deemed more “mature” or complete if it housed this team. To a certain degree this worked, and this worked well.
Today, most digital service teams have a similar set of attributes:
- A digital service is typically located centrally, either reporting into the principal or CIO/CTO or COO
- Power and authorities vary greatly; generally power is derived from political capital or occasional legislation that establishes it; they rarely have authorities to hire, fire, or hold teams accountable to outcomes
- The same set of skills were hired, regardless of the intended problem at hand, or outcome
It is assumed that digital services were somewhat plug and play – your handy government Swiss Army knife. Yet, the work itself varies greatly due to the priorities of leadership, the work it is empowered to do, and the depth at which it is allowed to operate. These teams have had great impact – and also, it is time to examine other models, units, and ways of working that can complement the standard digital service team.
The needs are so disparate and each context they work in so unique, we need a wider set of models from which to draw upon on purpose, not happenstance. Agencies and leaders at all levels need to have the right model that fits their constituents’ or agency’s or legislative need, as well as their agency’s maturity.
In its current evolutionary phase, most digital service teams are stand-alone teams assigned to deliver a specific task, often embedded in the CIO or agency head’s office. It is true that top cover and leadership capital is critical for success; however, we would like to challenge this new model in an attempt to create more enduring, transformative change for end users and for agencies.
The key ingredient: organizing the work around the shared outcome of a service, rather than a functional or organizational boundary. This orientation focuses the team on the outcome and be held accountable to its delivery. Such teams are more likely to be enduring, as the services that they deliver are either embedded in statute or have a permanency. Furthermore, the funding is allocated to outcomes that are aligned to the strategic goals (and budget) of the organization, leading to more enduring change.
The Service Team
The target state: a service. Established by the UK’s Government Digital Service and developed further by practitioners like Kate Tarling, a service team is organized around a service as experienced by an external user, i.e. “file my taxes,” “apply for college financial aid,” “enroll in benefits.” It’s not a project, nor an app, nor a vendor run system – a service is a thing a person needs to do.
A service, as Tarling defines it is described from the user’s point of view; encompasses every step between the user and the outcome; crosses organizational silos; and ties directly to the institution’s goals. This is similar to the “product operating model” seen in the private sector.
Where government services depart from a typical product team are the unique constraints faced by the public sector. A private sector product team is usually a mix of engineers, designers, and a product manager sitting in a product silo. A government service team needs that, plus program and policy staff, and often lawyers who have to navigate the policy requirements alongside the technical ones. Crucially, the user of government services also usually can’t “opt out” for a competitor product; if a benefits application breaks, the user has no other option.
These differences in the staffing and user experience are significant, however the underlying logic of a persistent, empowered ownership team remains the same. The product operating model gives government the operating mechanics: how a team should be funded, staffed, and run day to day. The service model outlines the unit that the team should be organized around: the user’s full journey, rather than an IT system, or office, or budget line. Government needs both the discipline of the product operating model, applied to the full weight of what an end-to-end government service actually requires.
A few items stand out here. First, a service is an end-to-end journey. In most agencies a service team by this definition would span across multiple teams and silos in an organization. A service also completes the user’s task (and it does so confidently, securely, and accurately). And a service team crosses organizational boundaries and is fully empowered to deliver this complete, end-to-end task. Restructuring delivery around an end-to-end service, either collapsing or working across silos, allows digital to truly shape the work that matters most to users.
That last part is what makes this model sticky. A service team organized around “Renew My Passport” is less likely to be disbanded when leadership turns over, because the service doesn’t go away. Funding is allocated to an outcome, year after year. The work survives because it’s embedded in something tangible.
We don’t have to look to the UK for proof of concept. An independent assessment of the IRS conducted in 2024 described Direct File as already ‘functionally operating as an isolated service-oriented organization.’ The model worked well and was proving itself across the organization for two prominent reasons. First, the most important decision the Direct File team made was to appoint a single accountable owner empowered to make day-to-day decisions. This leadership and governance model allowed the team to work in an empowered manner, at pace. Second, the service team joined up customer support and product teams.
What we heard in the retros was the flip side of that: projects that stalled because of indecision, too many stakeholders, being dropped into ambiguous situations without clear ownership, among other reasons. Building end-to-end service teams is not for the faint of heart – achieving this model of embedded technical and program teams, working collaboratively on an end-to-end journey, fully empowered to update processes and ways of working as they go is the mature end of the digital government spectrum. But it is included here as it not only achieves better results for the end user, it also helps the agency and staff transform as they work in a new, fully digital, collaborative manner.
Different Models for Different Problems
Not every new challenge in government requires the same organizational response. During our retros, participants bemoaned how USDS and 18F didn’t often build the right team for the problem they were trying to solve. This was often due to multiple reasons, top among them scarcity of talent. Below are models and purposes that emerged from our retros, each with distinct purposes, skill requirements, and conditions for success. These aren’t mutually exclusive; a mature digital organization will likely need more than one at once. The service team is the north star, the most mature model. The others are legitimate and necessary, but they should be chosen deliberately and not defaulted into.
Additional models for teams that could be applied to different problems, include:
A Forward Looking Agenda for Digital Service Delivery
This is the moment for ambitious change. The digital government field has an opportunity to build a more responsive and resilient government by pushing into expanded frontiers, with new tools, approaches, and even organizations that don’t exist yet. While the pace of change can be overwhelming, there is something clarifying about a moment when people are questioning the value of institutions themselves. This is the time for radical experimentation, delivery, and exploration.
So what’s next? The recommendations we’ve laid out – building a coherent strategy, matching the right team for the right problem, and scaling what works to stabilize and reposition the field can be read through multiple future-looking lenses. First institutional: what does building ambitious and capable government institutions look like, and how do you build it? Another is contextual:, trends like artificial intelligence and austerity are both going to reshape what’s possible and not in directions we can easily predict.
The following options and ideas exist on a spectrum, and are part of a suite of reform ideas that can help build government with the ambition and capacity to deliver. We welcome challenge, debate, and more ideas to this dialogue – love or hate it? Great! Tell us! Like an idea? Great! Steal it and go deeper!
Federal Digital Service Delivery
Building ambitious and capable government institutions – Federal edition
Federal capacity, or “The Department of Digital”
Federal digital and delivery capacity will continue to be a necessary piece of a strong, delivery oriented government. The question is – now that the US Digital Service has become DOGE and 18F is dismantled, what should the future model be?
The federal government needs a strong, centralized digital capacity responsible for three distinct purposes: capacity to deliver on presidential priorities, setting standards for better delivery, and building and managing shared platforms that can be used across government to save both government and external users time and money. For inspiration on what this centralized structure could be in a federal system, we look to Germany and the UK.
Germany’s recently established Ministry for Digital Transformation and Government Modernisation is delivering a portfolio of services, holding agencies across the government accountable for excellent, modern services, and ensuring that all software that is developed is interoperable across agencies and to devolved jurisdictions. It is a priority of the German government to build software that can be reused not just across the central government, but to states as well. Embedded in the ministry is a 250+ strong digital service team, responsible for excellent user experiences and digitizing the key interactions with government.
Germany is also taking the software it uses seriously and, in an effort to ensure national sovereignty over their own technology, is setting out to build their own full stack office software, across document management, presentations, collaboration suites, and other essential office software for use by civil servants across the country. It has become a national priority to not get locked into any single vendor or be reliant on any single country to provide software or cloud services; building resiliency across the tech stack is a strategic national necessity, not an afterthought.
The UK’s Government Digital Service (GDS) established a central team that builds platforms that can be used across government and sets standards that all new services must meet before they launch. These standards ensure consistent design and interaction patterns, end-to-end transaction completion, and more. The central team also builds shared platforms – GOV.UK Login, Pay, Notify, NDX Cloud, and Design System. More recently, they began developing shared open source frameworks to support local governments across the country. These platforms have become an essential foundational layer for the modernization of the UK’s government; the central team has many tools and templates that are easy to use, replicate, and apply to launching new services.
In the U.S., a central digital department could truly hold agencies accountable and help drive the momentum for change across the federal government, as well as support, build, and launch critical government platforms. Additionally, identifying and setting shared standards that not only establish a baseline for experiences, but also come with muscular authorities to enforce and hold teams accountable to those standards. What does accountability look like in practice? Agencies having their services assessed and getting approval before launching a new service experience, as the UK does now.
Recommended additions to the U.S. toolkit
Example standards. Standards that define what good looks like and come with the authority to enforce it could include:
- AI in practice – guidance for application and usage
- Service standards – design, interaction, call center, and service completion standards
- Budget controls – oversight over digital and tech procurements
- Service performance standards – transparency into service performance across government
Example platforms. Platforms any agency or jurisdiction can plug into, rather than procuring their own version from scratch. These could include:
- Login.gov
- A payment platform
- Income verification platform
- AI LLMs for civil servants that are compliant with federal and state laws (for example, Berlin’s BarGPT for Berlin city government employees and is GDPR compliant)
- Open Source office software (for example, France’s Lasuite) and code (for example, U.S. Web Design System (USWDS))
- Identifying projects similar in nature and scope to Ukraine’s Diia
Federal agencies – models for services and more
At the agency level, there are multiple models to support service delivery and leaders should support the model that meets their needs. However, almost universally we recommend that agencies should explore the service model for their key services. This model organizes teams and the work around the shared outcome of a service, rather than a functional or organizational boundary. Working across silos, in multidisciplinary teams leads to better outcomes for users and helps transform the organization into a more modern, responsive one along the way.
State and Local Digital Service Delivery
Building ambitious and capable government institutions: Working across federal and state/local
Federalism, what is it good for?
Federalism is great for ensuring power doesn’t get too centralized when managing a huge and hugely diverse country. However, federalism is rarely good for the end-user experience or for delivery efficiency. A review found that federal legislation meant to quickly build infrastructure, support cities and states during COVID, and pave a path towards a greener country was slow to get out the door and make tangible. The matrixed delivery of federal -> state -> city/local doesn’t always support efficient implementation, and it also doesn’t have to be this complicated.
An ambitious federal digital strategy should include consideration of the complete delivery cycle – inclusive of legislation, the disbursement of funds, tracking all the way down to the front line and ultimately the intended end users. There are two potential areas to explore for better outcomes – a ‘middle layer’ of shared open, public infrastructure that helps budget-strapped state/local governments deliver on key services and the inclusion of state/local digital capacity to support implementation of any legislation that requires a user experience.
A menu of tools: open source platforms, shared infrastructure, and public options
There are countless examples of large IT vendors building the same product, poorly, for 50 states. This model can and should be reimagined – moving towards a vision where governments can opt-in to a shared public infrastructure. It is time to look at options that tie federal outcomes to delivery intent: We need shared public infrastructure around key legislation and universal platforms. These could support both internal government efficiency and end-user experience.
Shared open source platforms and digital infrastructure can provide government teams across the country with additional options for delivery at a national scale. This ‘middle layer’ would look at services that are required in multiple jurisdictions or infrastructure necessary to implement new legislation. Such platforms could exist as a public option – government-provided services that coexist with one or more private options.
Governments shouldn’t have to build from scratch: Modern income verification infrastructure really only needs to be built once and made available to jurisdictions that opt-in and could be used in a countless number of ways, from federal scholarship applications to SNAP. Governments at all levels lose money to payment processing fees. A public option payment platform would cut costs and add a new competitor to the market, saving taxpayers money. Universal moments, such as birth and death registry, could be built centrally and deployed locally. Even when state and local governments build their own services, government registries and digital services could be built using a government-managed open-source low-code platform, like is being done in Ukraine with Diia.Engine.
To date, these delivery challenges have been too onerous to tackle. States are often reluctant to share data and platforms. Some jurisdictions have begun planning shared procurement strategies, but radically different, outcomes-based delivery will take reimagined governance and significant political will.
State and Local delivery capacity
State and city governments are the source of many peoples’ daily experiences with public services and infrastructure. Yet most lack the resources and capacity needed to deliver the efficient, seamless, and intuitive digital experience that the public has come to expect in the private sector. This gap is not a reflection of ambition or effort at the state level, but the result of long-standing structural constraints on funding, talent, and technical support.
Existing federal funding mechanisms and technical assistance programs are insufficient to close this gap. While federal dollars often support state IT projects, they rarely come with embedded technical capacity, hands-on delivery support, or durable mechanisms for knowledge transfer. Today, states face persistent challenges recruiting and retaining digital talent due to rigid hiring systems, compensation constraints, and limited professional development pathways.
From this, we propose a couple of options to close the capacity experience gap between the end user and state and local institutions.
- Include implementation or service teams as part of legislation to ensure that delivery intent is actually possible and is critical to the success of any legislation. Building that capacity in-house, in the institution that is responsible for the end-user interaction, is a critical step towards a successful implementation.
- Centrally funded technical assistance – in this model, a dedicated central office in the federal government – should be established to provide consultative and technical assistance to state governments at scale. This office would form interdisciplinary teams that consist of state government employees and technologists who work on high impact issues of service delivery, ranging from social safety net access, to environmental permitting, to shared digital infrastructure modernization.
Artificial Intelligence Risks and Rewards in Digital Service Delivery
AI was not a major topic during the retros, largely because many practitioners view AI as one of many commercially available technologies that can be deployed to solve problems. However, interest in AI is growing as governments increasingly experiment with and deploy AI in their operations and service delivery.
AI, when deployed responsibly and with a clear purpose in mind, has the potential to assist in streamlining benefits, reaching citizens with timely information, and automating certain tasks. However, AI does not exist in a social, economic, or political vacuum and carries significant risk to governments and the general public through cybersecurity vulnerabilities, data privacy risks, entrenched bias, intellectual property infringement, and more. These risks highlight the need for a well informed government workforce, and additional in-house technical experts within government to support users and make decisions that advance progress with a robust understanding of the implications.
Artificial Intelligence in the age of austerity
During periods of financial uncertainty or recessions it can be challenging to make the case for AI adoption when it weighs against more urgent needs. Additionally, nationwide, states, counties, and cities are facing tighter budgets due to existing deficits and a change in federal funding. Resource- and capacity-constrained institutions are turning to AI to help fill that gap and deliver for their constituents. But to ensure that AI adoption is fair and transparent, governments need AI strategies and strong, technical talent embedded to deliver on this new technology.
This moment demands confronting a reality that is complex, rapidly evolving, and where just about every decision will have a profound impact on the lives of those the government is meant to serve and the institutions themselves. If the government and the civic tech community are not intentional about how we design, procure, use, and govern this new technology, it has the risk of making capacity issues worse and undermining trust in institutions that are already fragile.
Artificial Intelligence, practically
In this moment, our recommendations – have a strategy tied to outcomes, build embedded multidisciplinary teams, make it easy to build and sustain this capacity – are more important than ever, as AI becomes a critical tool that governments across the country are rapidly adopting. AI can help improve service delivery when applied to specific problem-driven use cases and deployed in ways that promote fair, user-centric, and transparent application.
Where we would deploy AI towards service delivery:
- Embedding in the practices of front line employees, to understand where processes can be automated, notes transcribed, and the right approach to using LLMs that allow employees to save time on notes, searching and applying different policies, etc, ultimately allowing them to spend more time with clients.
- Prototyping new experiences, forms, and interactions – normally these are interactions that require lengthy procurement processes, now governments have the opportunity to use new AI tools to perform exploratory work.
- Other problem-driven uses that focus on solving specific challenges rather than adopting technology for its own sake.
- With content support across translation, transcription, simplification.
Principles:
- Build with, not for – build systems that complement the lived experience of the government employee and meaningfully include end-users in the design and testing of AI platforms.
- Be transparent around how and when AI is used, especially in decisionmaking processes or in the provision of benefits.
- Best practices include: public use-case inventories, and consumer notification/disclosure of AI use (and where)
- De-bias, wherever possible – Understand how LLMs have certain biases and how, as government employees, there are frameworks around those biases to mitigate potential risk or harm.
- Being aware of existing applicable laws, and of increased compliance risk with AI tools that have limited interpretability or control over data inputs (such as adverse action notices that are required under FCRA/ECOA)
- Pre-deployment planning: Before you deploy, understanding how it is best used, and situations in which in can actually make things work less well (i.e., when you need factual information)
- Preventing buyers remorse: Clear procurement guardrails that include sunset provisions, and auditability/interpretability (to prevent accidental bias).
- California is a great example. The state piloted multiple programs to improve service delivery and killed the ones that didn’t work or were too costly.
- Preventing buyers remorse: Clear procurement guardrails that include sunset provisions, and auditability/interpretability (to prevent accidental bias).
- Consistent quality control: As agencies independently acquire a growing number of services, maintaining consistent quality control and oversight becomes increasingly difficult. A centralized review and governance function should evaluate and monitor the tools and services being adopted across agencies. (i.e., a FEDRAMP process for AI)
- Centralized vetting of AI models and products ensures consistent standards and is more effective than fragmented (and often more expensive) agency-level procurement.
The platforms and models that we choose matter. Again, there is inspiration to be found abroad. The Swiss Euria GPT is fully powered by renewable energy, and all heat produced by the platform’s data centers is fed back into Geneva’s heating network; furthermore, it does not collect or train its models from any user data and is fully compliant with Swiss data and privacy laws.
While the future holds seemingly unlimited uncertainty, there is a lot of opportunity to learn from what’s come before and to radically redesign the future of digital government.
This Proposed Rule Could Change American Science Forever. We Read It So You Don’t Have To.
On May 29, the Office of Management and Budget (OMB) dropped a 108 page (single-spaced) proposed rule to “revise the Guidance for Federal Financial Assistance to improve government-wide policies and requirements related to the management of grants, cooperative agreements, and other forms of assistance.” If you are not a dyed-in-the-wool wonk, here’s a translation: this proposed rule would change the way the federal government funds scientific research. And state energy programs. And community health grants. And the local governments trying to modernize how they deliver services. Like a lot.
Aside: there is something wrong with the way we fund science in this country — the list of flaws is long and we have to own them. We also have to build something durable, not treat our principles like a suicide pact.
Rule changes like this thrive in tall weeds: the language is arcane, esoteric even, meant to be understood by lawyers and policy experts. Here’s what’s actually in them.
How we got here
There is a crisis of trust in science. Trust in science is still lower than before the COVID-19 pandemic reshaped our reality, with trust in federal science lower still. This trust is also partisan: Democrats are more likely to have confidence in scientists than Republicans are. Many people struggle to trust scientific processes and activities, to have faith in government as an interpreter of scientific findings, to feel public science priorities represent their needs. The federal research funding apparatus feels distant from most people’s lives, and the connection between public investment and public benefit isn’t easily traceable by the people whose taxes make it happen.
The federal execution of science has real problems too. Administrative burden, convoluted workflows, a funding system that concentrates awards among the already-large and already-connected, a merit review process that has calcified in ways that make it slow and risk-averse. As a community we have to own that. The fish psilocybin study wasn’t taxpayer-funded, but some real head-scratchers were (for the record: some of them were worth it).
Backstopping all of this is a weakening of Congress’s role in R&D. While there is bipartisan support for research in Congress (like the many Democratic and Republican lawmakers who have championed investment across AI regulation, wildland fire, and on emerging technologies like biotech and quantum computing), Congress has been relegated to a rump when it comes to their fiduciary duty to scientific research. Money expressly authorized and appropriated by the people’s house is being held up, research agencies are being starved of their necessary funds, and there is hardly anyone left to do the work.
In that context, the Trump administration has been establishing a policy lineage for major change in how the federal government invests in many areas, including R&D. The 2025 Restoring Gold Standard Science executive order directed political appointees to oversee agency scientific decisions and resolve GSS “violations,” inserting politics into processes where existing scientific integrity policies had specifically been designed to keep it out. Agency implementation plans followed across multiple science agencies. This proposed rule is the next step.
Back to these rules
How much have you heard the phrase “gold standard science” in the last year? As a concept, it was reaching for something important: accountability in how research dollars get spent, scrutiny of whether peer review had become a closed loop, a question about whether federally funded science was delivering for the public that funds it. What it became in practice is something different.
Is it, for example, the systemic weakening of career staff at science agencies to replace their blood-sweat-and-tears expertise with political appointees? Is it firing the National Science Board en masse over email on a weekend? Is it gagging the NSF watchdog meant to uncover research misconduct and fraud? This doesn’t begin to cover the politicking that has diminished our national public health apparatus, or the bed bugs in the Animal and Plant Inspection Service building.
What gold standard science became in practice is a mechanism for political appointees to override scientific judgment and frame ideological interference as methodological rigor. This proposed rule puts that mechanism into binding regulation, government-wide: mandatory political review of every discretionary grant before it’s awarded, expanded authority to terminate awards mid-stream, new restrictions on what funded researchers can publish, say, or collaborate on internationally.
Science is not the only thing at stake. The federal grants system funds an enormous range of what government actually does: states building out energy infrastructure, local health departments running maternal care programs, nonprofits delivering workforce services, cities trying to modernize how they serve residents. OMB’s proposed rule governs all of it: billions in federal grants, every dollar now subject to the same appointee review and presidential priority test. A political appointee gets to decide, mid-stream, that the work no longer matters. That’s not a grants system anyone can build anything ambitious in.
Replacing expert peer review with political appointees doesn’t make federal financial assistance of any kind more accountable to the public, it makes it accountable to whichever political team won the last election and their appointees’ desire to micromanage. Every grantee in America is now operating on that assumption.
The proposed change to §200.205 would formalize prior guidance for senior appointees – not career scientists, not program officers, not people who know how to do this thing – to review every discretionary grant before it’s awarded (science and beyond).
For science specifically, it goes further: appointees expressly prohibited from deferring to peer review [read: experts] on the matter. Since WWII nearly every science agency has emphasized independent expert peer review as THE measure of scientific merit. Even your 8th grade science teacher emphasized this. Under the change to §200.205(d), a political appointee can override the scientific community’s judgment just because. Discretionary awards must also “advance the President’s policy priorities” – not national security, or public health, nor foundational science priorities. Presidential ones.
Under current rules, terminating a grant requires a finding of noncompliance or fraud, which is a high bar because multi-year awards require multi-year commitments. You can’t build a cutting edge research program or radically transform a grid on a one-year horizon. The proposed change to §200.340(a)(2) drops that bar entirely. No finding required; termination is available whenever an award no longer aligns with agency priorities or the national interest. Yes that could mean almost anything. There are currently 150,000 active multi-year awards operating under the assumption that finishing what they started is possible. The chilling effect on applications may be as significant as the terminations themselves: why spend months on a competitive grant application, or structure your organization around a multi-year award, if the whole thing can evaporate at will?
Then there’s the elimination of fixed-amount awards. Smaller organizations, the ones without teams of grants managers and compliance lawyers, depend on fixed-amount awards because they’re manageable. Kill them and you’ve told a significant chunk of the grants ecosystem that they’re no longer in the running.
Proposed changes to §200.421, §200.432, and §200.461 restrict the use of federal funds for publications, press communications, and conference attendance. For researchers, this directly conflicts with a longstanding OSTP mandate requiring federally funded research to be published open-access. You can’t comply with one federal requirement without violating another. But the restrictions aren’t limited to science: any federally funded practitioner sharing findings, any state agency presenting at a national conference, any nonprofit documenting what their grant actually accomplished runs into the same wall. In other words: you can’t do public work that the public can see and learn about.
The proposed changes to §200.220 and§200.202(e) would require case-by-case approval for international research collaborations — a domestic-first framework that treats standard scientific practice as a special exception. (We did just bring a Canadian to the moon with us, for the record.) International cooperation is standard practice across many scientific disciplines; fruitful, peaceful scientific collaboration has been the norm with any number of countries (that we are already engaged in multilateral collaboration with)? A domestic-first framework that requires case-by-case approval would be detrimental to international public health efforts, where foreign scientists are leading research into treatments and containment.
Changes to §200.206 look a lot like a loyalty test and not just for science. Any organization applying for a federal grant would be subject to eligibility review based on its affiliations, activities, and perceived alignment with administration priorities. Congress tried this one in 1949 when they tried to sneak in a loyalty test affidavit into the National Science Foundation Bill. We said it in 1949 and we’ll say it again: “Its sole justification for inclusion is concession to current fears and hysteria. Totally ineffective in detecting actual enemies of the U.S., it is significant only in its indication of the state of mind of the country – one of unreasoning insecurity and fear. To fail to oppose the provision is to accept this state of mind and permit it to go on to even more dangerous manifestations.”
The provision that should worry everyone is in §200.202(a)(iii): a requirement that federal programs “align with administration policies and priorities.” Science funding has always been political and anyone telling you otherwise is selling something. Democratic legitimacy matters for public investment, and the federal government should be accountable to the people whose taxes fund it. But there’s a meaningful difference between federal priorities and administration priorities that this rule deliberately erases. The federal government is a massive institution with a general mandate to serve the public across generations. An administration comes and goes every four to eight years, with narrower ideological agendas and a much shorter time horizon. Requiring every grant dollar to align with the current administration’s priorities isn’t accountability, it’s a different thing entirely.
Two things can be true
To be fair, a few things in this rule are worth having. NOFO streamlining and encouragement of multi-year awards are real improvements to a pre-award process that has frustrated applicants for years. The rule also comes down hard on merit review as a source of stagnation, and to an extent that’s not wrong. We’ll take those. (Further FAS insights into merit review are forthcoming, but traditionalists be forewarned: we make a many-pronged call for reform.) As a scientific community we have to own the current flaws. We also have to build something durable, not treat them like a suicide pact.
Step back from the individual provisions and the systemic problem becomes clear: this rule is a demand signal and institutions will respond to it rationally. Universities, nonprofits, state agencies, and local governments will look at these conditions — arbitrary termination authority, political pre-clearance, loyalty reviews — and make reasonable decisions about what’s worth pursuing. You cannot have loyalty tests and a scientific effort the size of the Manhattan Project or in new areas of discovery where the trajectory is unknown. Smaller institutions without the legal and administrative capacity to manage the new compliance burden will exit the market; larger ones will self-censor. The portfolio of federally funded work will get narrower because the risk calculus changed.
There’s an irony here for anyone who believes in competent government: a system that can override expert judgment at will has less use for experts. That’s a demand signal too. There is a world beyond merit review emerging, like the NSF X-Labs initiative, team science models, Tech Labs built on baked-in independence. Exciting constructions, none of them ready for prime time. We can’t throw the baby out with the bathwater. Better results from federal grants are a legitimate goal, and the path there isn’t complicated to describe: grants systems that actually reflect the communities and problems they’re meant to serve, and that are designed to learn from what happens after the money goes out the door. We don’t have that now and this proposed rule doesn’t get there either.
So what’s next
Many of our peers are outraged. AAAS CEO Sudip Parikh calls these proposed changes “a brazen power grab,” while Irene Ngun, Assistant Director of Policy and Advocacy at Stand Up For Science, plainly calls it a “weaponization.” Across the science and technology policy community, there is a feeling that this represents the final bell toll of an apocalyptic-level event for American science. Whether or not that is your read on the situation, this is as significant as a change as can be. Independence is the source of scientific integrity. (And those outside of this community should care too: OMB’s proposal would govern billions in federal grants. Every dollar everywhere will be subject to the same appointee review and need to meet presidential priorities.)
There is no question this is a Big Deal. If you are a university or research lab, or aspire to work in one, or are simply an enthusiast of federally-funded research (the kind that gave us the internet!), what’s next will matter. It is likely these changes will lead to litigation. When that time comes, we will offer dispassionate analysis, giving primacy to facts and figures. But before that, we are exploring every avenue available to us to revert this threat.
- We’re in constant contact with science advocacy groups, industry, scientists and innovators, and policymakers to stay on top of the latest dynamics and opportunities for action.
- We’re reaching out to congress and the executive branch with substantive oversight priorities. We need members from both sides of the aisle to act on these. Raise your hand if this is you. Some of these include:
- Conflicting mandates between this rule and other rules throughout government (like the Office of Science and Technology Policy’s open access publishing guidance),
- Clarification about how this rule affects existing and multi-year awards, and
- A Government Accountability Office study request.
- We’re preparing a public comment and encourage you and your institution to do the same.
What the Metascience Community Should Learn From the Federal Evidence Movement Before Making Our Mistakes
There is a growing community of people inside and around the federal government who believe we should apply the scientific method to science itself: how grants are awarded, how peer review works, how labs are organized, how R&D portfolios are built. In some circles this is called metascience, others it goes by science of science, or research on research. The label matters less than the conviction that how we fund and structure science isn’t fixed and that we could be doing it a lot better.
The political moment may be unusually open to acting on this conviction, as R&D institutions face pressures and disruptions not seen since the post-World War II era.
A quick orientation on where things stand: most metascience activity today is external researchers studying government R&D programs from the outside, and that community is growing. Inside the government, interest is picking up: a handful of agencies are starting to think seriously about what internal capacity might look like, with NSF’s proposed metascience unit in the FY2027 budget request as the most visible signal so far. Whether that momentum builds into something more structured, or stays scattered or administration-dependent, remains to be seen.
There’s no Evidence Act equivalent being seriously discussed, but it’s a great moment for laying the ingredients for what comes next. This piece is aimed at both audiences: researchers trying to make their work matter inside agencies, and the agency leaders and staff thinking about standing something up.
I want to be a serious champion for building this capacity inside the government. But I also want to make sure we don’t sleepwalk into a set of traps that I watched swallow another reform movement — one I was part of! — over the last decade. The federal evidence community, which grew dramatically following the Foundations for Evidence-Based Policymaking Act of 2018, had serious ambitions and major accomplishments. It also made structural mistakes that a metascience community could easily repeat. Here’s my take on how we can learn from each other (and what you should steal).
Design around decisions people need (or want) to make, not just questions the research community finds interesting, and be useful early.
Know the decision calendar; a finding that arrives late doesn’t exist.
Co-design with program officers; make their success your success.
Existence of evidence doesn’t equal use; figure out what motivates the people who need to act.
Government needs in-house flexibility to do the work.
Decide whether this is a destination or a waystation and build accordingly.
Solve the structural problems first.
External accountability, cross-agency champions, and Congressional relationships are survival infrastructure.
Episodic engagement is a design failure.
What the evidence community got right (somewhat-evidence-based answer: quite a bit!)
The Evidence Act was a major achievement both as legislation and systems change that continues to make stronger policy possible. It normalized the idea that the government can admit knowledge gaps and curiosity. That agencies should be asking hard questions about whether their programs work, and that building the infrastructure to answer them is important (to me, this is a fundamental of democratic governance, something we owe the American people to maintain legitimacy). Asking “does this program actually do what we think it does?” could read as hostile or politically threatening. The Evidence Act made it standard management practice and that cultural shift, however incomplete, was not nothing!
The infrastructure that followed (Learning Agendas, Evaluation Officers, CDO Councils, OMB evaluation guidance) created shared vocabulary and accountability that hadn’t existed before. In the agencies where it took hold, it opened space for questions, roles, partnerships, and curiosity that previously had no institutional home. Giving someone a title that made clear their role was to facilitate knowledge generation and translation in a bureaucracy that knows how to build on structural opportunity is a big step. Setting a standard process to collect questions needed for effective governance is huge, culturally and administratively.
External accountability mattered too. OMB guidance, GAO oversight, and congressional interest created pressure that internal motivation alone couldn’t sustain. Compliance requirements work when someone is going to ask about them and care about the response (spoiler: I had to do this a lot, and occasionally explain the difference between, say, audits and evaluations). Where the evidence work shaped decisions, it was usually because someone with budget authority and leadership access wanted it. And because a community of practice built enough shared norms to carry the work across agencies and administrations.
What went wrong (or not as well as it should have) and why metascience can learn from our experiments
Insert here tremendous respect and awe for the evaluation officers and their colleagues who fought the hard fight without the support they should have had.
We built supply without equal attention to demand. Evaluation planning and learning agendas were sometimes produced because Congress and OMB required them, not just because program offices were always asking for answers. Carol Weiss has called this the “two communities” problem for ages: researchers and policymakers operating in parallel universes with different timelines, incentives, and languages. And while the community has iterated in that moniker and concept for a long time, we’ve never quite solved it. Too often the results landed in reports nobody read (if they were published at all!), or in inboxes where they became someone else’s problem, or on a timeline that didn’t match decisionmaking. The basic customer question — who needs this, and when, and in what form — wasn’t asked enough, and when it was, we didn’t have great leverage to change.
We got divorced from the workflow. Evaluations routinely finished after the budget cycles and policy windows they were meant to inform. The evidence community struggled to map its work to actual decision points: appropriations timelines, leadership transitions, program reauthorizations. While the evidence community would be well served by considering a range of flexible and timely evidence models, gold-standard evidence methods like Randomized Controlled Trials of major programs can and do take time (certainly more time than a single fiscal year). Unsurprisingly, format mattered too: the people who needed to act, needed a two-pager, or, better, a conversation; more than a technical report delivered six months after the window had closed.
We (cringe) made ourselves hard to work with. The evidence community was often expert-centric rather than partner-centric, more focused on what constituted the highest quality legitimate evidence than on what would be useful, approachable, or on what timeline (see Jen Pahlka’s thinking on “stop energy” vs. “go energy”). The vocabulary was sometimes alienating and methodological gatekeeping was a real downer. More structurally, evaluation offices were sometimes poorly located organizationally, sitting outside program design and budget processes where leverage lived, and relationships upstream or downstream didn’t always come naturally.
We had a LOT of questions but buried them where no one could find them. On the other side of the equation, we too often made a reasonably good effort at compiling our research and evaluation questions in Learning Agendas and did the government equivalent of post and pray, launching a PDF deep on a federal website without requisite effort to connect it it to researchers who would’ve loved to follow up. There were great exceptions: outside the government, I participated in a “matchmaking” session on the President’s Management Agenda Learning agenda, connecting federal leaders with research teams excited to engage on their challenges. The OMB evidence lead I was privileged to work with created a Learning Agenda Questions Dashboard (on evaluation.gov, RIP), and the “evidence project portal” to consolidate opportunities for outside researchers.
We lost the hiring, funding, and buying battles. The Evidence Act directed OPM to develop a hiring classification to support building out the evaluation community. As the person at OMB responsible for pushing that effort (years after the deadline), I watched OPM’s underresourced and sometimes calcified approach to classification make this so challenging that colleagues described it as the worst professional experience of their careers. As an ongoing consequence, agencies defaulted to using generic job series for evidence functions that couldn’t elevate qualified people. Evaluation officers are frequently double and triple-hatted as performance managers, data scientists, and learning officers, often with no dedicated staff, no protected budget, and no solid career path. Likewise, the paths to funding research were highly varied and full of dragons. I could not in good faith consistently tell an agency “here’s how to get your high priority research funded” because it was so variable across agencies. Likewise, unwieldy procurement vehicles added unnecessary burden to a process that already struggled to get RFPs out the door.
We struggled with the theory of adoption. The simplistic foundational assumption was: create the requirement, do the study, policymakers use it; policymakers create a program, evidence is generated, change is made. It SOUNDS right but in practice so much was wrong in that chain because it didn’t consider incentives and timelines. Who needs this finding the most, and when? What would motivate them to change their behavior? What’s standing in their way? Am I asking a question they can act on? Even when the evidence was good, the pathway from finding to decision was assumed rather than designed.
We kept building administrative burden while assuming people wanted it. Learning Agendas and Annual Evaluation Plans and Policies are great concepts and valuable ways to bring learning and policy communities together. But even in the best of worlds these were still compliance requirements layered on top of staff who were already stretched, and in the worst, when done badly, they overcomplicated what should have been a culture changing moment. A metascience function that responds to that history by adding more reporting requirements would be its own kind of failure. The goal should be fewer dragons and headaches on on the path from question to useful answer.
And we struggled with politics. The truth is that many policy leaders don’t want to know if their idea won’t work or didn’t work. Publishing work that shows waste to taxpayers is politically costly, and that problem doesn’t disappear because a law requires evaluation plans. Likewise, sometimes programs do work well and the evidence shows it brilliantly, but politics means that success is less desirable to advertise.
But failures weren’t all inside the government. The academic communities best positioned to do rigorous, policy-relevant evaluation work faced their own incentive problems. Publishing in top journals rewards novelty, methodological elegance, and positive findings (even if you have to p-hack your way there); relevance to a policymaker’s actual questions is less important. The researcher who produces a technically brilliant study and never engages with the agency whose program they studied is likely more fully rewarded by their institution than those supporting policy design. Fortunately, there are researchers across disciplines who care about public impact, and there are organizations like the Evidence-to-Impact Collaborative at Penn State doing serious work to build the infrastructure that makes researcher-policymaker relationships function. But consistently orienting the research community toward the questions that matter inside agencies is a question metascience will inherit too.
Hark! There is a Fork in the Road!
The emerging federal metascience community is asking fascinating questions that are equally vital for democratic legitimacy: beyond “did this program work” to “how does the federal R&D enterprise itself work, and how could it work better?”
But it faces the same fork in the road and even more disruptive moment. The metascience community is also trying to do this work in a volatile moment, where the institutions being studied are changing fast, and where interest in metascience inside the government is emerging alongside real disruption to the research enterprise. That combination is an argument for urgency: the window to shape how internal metascience capacity gets built may be shorter than anyone expected. A unit stood up quickly, without a protected budget or independent authority, narrowly focused on politically convenient questions, and with no plan for continuity — that’s a real risk. The design choices that prevent it aren’t complicated, but they have to happen early.
A metascience function that produces insights about peer review and grant mechanisms without building serious demand from program officers is the evidence community’s supply problem in a new form. A “Metascience Officer” role with no potential for career path or growth, no protected budget, no customer or audience, and competing responsibilities is the Evaluation Officer problem with a different name. Learning agenda questions about R&D mechanisms that nobody follows up on become checkboxes. Evidence that never reaches the room where program design decisions happen, regardless of its quality, has no impact.
Part of what makes institutional design so hard is that the distance between “we produced amazing insights” and “that knowledge changed anything” can be enormous. Experts at the Institutional Architecture Lab have a great framework here. They distinguish between institutions that produce knowledge (authoritative but loosely coupled to action), institutions that have knowledge formally embedded in decision processes (where findings must be engaged), and institutions where specific evidence thresholds trigger changes in practice. The Evidence Act was designed for the middle category and often ended up in the first.
Before we tell you where to go next, a note that applies to both communities: the questions metascience is asking aren’t exactly new inside agencies. Learning Agendas have been wrestling with peer review design, funding mechanisms, and portfolio effectiveness for years: imperfectly, under-resourced, but with real interest and curiosity. Arriving like you’re the first person to notice the building is on fire is a real pattern in the good governance world, and it’s one the evidence community sometimes got too good at before metascience got here. Ask what’s already been tried before you propose what’s next. It’s faster and it might save you from reinventing something that already didn’t work.
What to do instead: a checklist we wish we’d had
- Start with demand AND supply. Map the actual decisions agency leadership faces, like peer review redesigns, new funding mechanisms, portfolio rebalancing, and build the research agenda around those decisions instead of around what the metascience community finds most interesting. Before you build anything, build relationships with the people who will act on what you find. Understand what questions keep them up at night.
- Master the workflow problem. Know the decision calendar and what inputs people will actually read, in what format, and when. A finding that arrives after the window has closed doesn’t exist for practical purposes.
- Embed partnership in the working model. Co-design questions with program officers and make their success your success. Whether metascience becomes a resource people seek out or an office people avoid is something you can shape now.
- Take incentives seriously. Just because a metascience function exists doesn’t mean program officers will care, or that agency leaders will act on what it produces, or Congress will be curious. What are program officers actually rewarded for? What are agency leaders trying to protect? What would make peer reviewers engage differently with evidence about their own processes?
- Develop in-house capacity in addition to solid relationships with the outside. While it’s vital to find consistent and reliable communication paths between government and external research institutions, the government also needs some internal capacity to help be more responsive, flexible, and secure on time sensitive and issue sensitive questions.
- Design the talent model with purpose instead of happenstance. Is this a destination or a waystation? A fixed-term appointment that makes people more attractive when they leave, building an alumni network that carries the practice forward? Or a permanent career function that builds institutional memory? Both have a role: pure rotation and you lose institutional memory; pure permanence and you lose touch with the field.Think about where people come from, where they go, and what signal the function sends about whether this is meaningful work or a backwater.
- Build for durability. External accountability, cross-agency benchmarking, champions in OMB and Congress are what keeps a function alive across administrations. Build them early, when you have momentum and goodwill (by the way, though evidence work is still doing democracy good across government, the Evidence Team I led at OMB doesn’t exist anymore).
- Invest in relationships before you need them. One of the deepest structural failures in the evidence community was treating researcher-policymaker relationships as something that happened naturally, or that individual researchers could maintain on their own. Individual researchers can’t track decision-makers across election cycles, persist through staff turnover, or stay useful for years before they need anything back. And FAS research on local governments shows that policymakers often struggle to find the “front door” into research partnerships, even when they do want to build those relationships. The result is that academic engagement with policy tends to be episodic: it activates when someone needs something, fades when the grant or policy window ends, and depends entirely on who happens to know whom (there’s also interesting research by Max Crowley and colleagues that suggest all these ties are better built early in careers and levels of influence, on all sides). A well-designed metascience function has the ability to solve that “front door” problem – but should treat relationship-building as a core function, rather than assuming it will happen automatically, and invest in presence before anyone needs help.
The steps taken over the last several years to build federal evaluation capacity were good ones. The people who did that work were serious, and they built something real under difficult conditions. We hope this piece lands as what it’s meant to be: a love letter to that work, and a friendly peer review of the structural choices that will determine whether metascience does better
Successful Pooled Hiring Starts With Diving the Deep End
The Office of Personnel Management has been busily reversing course on federal workforce reductions with some splashy hiring announcements. In December, it launched Tech Force, a pooled recruitment effort targeting 1,000 early-career technologists to be placed across agencies for two-year stints. In March, it stood up across-government shared certificate for project managers. It launched an Early Career Talent Network spanning five job categories. Two weeks ago, it expanded Tech Force into cybersecurity. OPM Director Scott Kupor has been explicit about his ambition: this is a “model for more centralized, efficient hiring across government.”
I’ll bite: yes, there’s a lot of promise in that! The instinct behind all of these actions builds on years of initiatives meant to create efficiencies out of the hundreds of thousands of hires made federally each here. Pooled hiring, which should include one well-designed announcement, one shared assessment, and many agencies drawing from the same pool of qualified candidates, is exactly the kind of tool the federal government should be using. I saw this up close when I was at OMB and I fully drank this Kool-Aid. The logic is compelling: (typically) the federal government processes over 22 million applications and hires over 350,000 people into public service every year. No private employer operates anywhere near that scale, which I still believe can be an asset, and pooled hiring creates the entry point to get there.
But pooled hiring has a track record (going back several administrations), and it’s uneven. Most recently, the Biden administration championed it most ambitiously during the infrastructure surge, where OPM partnered with seven agencies and hired roughly 5,000 employees, doing things like USDA hiring 39 HR specialists off a single certificate (if this sounds underwhelming to you, trust me when I say it’s mindblowing to your average hiring manager; more explained shortly). But the same period produced plenty of pooled actions that generated duplicative work, agency foot-dragging, and candidates who aged off certificates before anyone made them an offer. FAS and others have been studying these challenges in the context of the permitting workforce surge, and the problems are structural, predictable, and repeating. Also? Solvable.
The concept has promise but implementation has kept breaking in the same places. This piece is about why and about how to get it right, now, while there’s political will and active momentum to use it.
The Design Error at the Center of Everything
First, a quick explainer on how this actually works — because “pooled hiring” gets used loosely and the mechanics matter. A pooled hiring action is a competitive job announcement run either by OPM centrally or by a lead agency on behalf of multiple agencies and intended to fill multiple open positions in multiple agencies. Instead of each agency posting its own announcement, recruiting its own applicants, and running its own assessment, one announcement goes out, one applicant pool forms, and one assessment process screens candidates into a shared certificate of eligibles (government-speak for a ranked list of candidates that agencies can choose from). Agencies that have signed on to participate can then make selections from that certificate without having to run their own action from scratch. OPM-run actions (like the current Tech Force or the project manager cert) work the same way, just with OPM as the lead rather than a single agency. Either way, the cert is the output: a ranked list of candidates who have been assessed as qualified, available to any participating agency to hire from without having to solicit new resumes, review their qualifications, administer assessments, or other tedious parts of the hiring process.
That’s the theory.
The shared certificate is where most implementations stop. Agencies get a screened list and then do their own thing — their own interviews, on their own timelines, with their own offer processes. Or maybe they don’t, even when they said they would! The coordination ends at the cert. Everything downstream remains fully siloed at each agency.
This is far from the ideal that most policymakers have in mind and what many private employers do. A genuine pooled hiring action pools the whole pipeline. Recruitment, assessment, interviewing, and offers — all coordinated, all running in parallel across participating agencies. That doesn’t work for every role, but in surge situations, or for roles where agencies make dozens of hires of the same roles every year, it’s great. Agencies don’t just agree to draw from the same pool. They show up on the same interviewing days. They make offers on the same compressed timeline. Candidates who applied once get considered by many agencies simultaneously with each running its own slow-motion version of the process.
Almost nothing the federal government currently calls “pooled hiring” actually does this. The new OPM actions are no exception. Tech Force is better marketed than previous efforts, and the private-sector partnerships are genuinely new. But the selection and offer stages remain siloed at each agency and I’ll be very curious if they make selections. That’s the design flaw everything else flows from.
What Breaks When You Don’t Fix the Design
When I was at OMB, we saw these failure modes up close, in what were probably deeply frustrating meetings with the valiant program team as we learned where the seams were. Some things we saw:
Pooled hiring worked when it was a clear administration priority and had OPM and OMB supplementation. Early indicators suggest that Tech Force has success because it’s clear that the administration, the OPM director, and OPM staff are both giving it attention and smoothing implementation behind the scenes. That’s good for proof of concept, but it doesn’t show the weaknesses that can emerge when administration accountability doesn’t hold agencies to delivery on innovation hiring methods.
Agencies didn’t trust screening they didn’t run. OPM’s own guidance requires agencies making selections from another agency’s certificate to verify that the original qualification and assessment criteria are appropriate for their position. That verification step becomes a second screening — which defeats the efficiency rationale entirely. Agencies that double and triple-screened candidates created more work than if each had run its own action from scratch. The fix isn’t better guidance, it’s building trust into the design upfront, by ensuring the people trusted with the most relevant subject-matter expertise help design the assessment in the first place.
Demand didn’t stay put. Agencies raised their hands, agencies or OPM ran a resource-intensive recruitment action, and then agencies were slow to hire — or circumstances changed before they did. The August 2024 OMB/OPM hiring memo specifically directed agencies to review available shared certificates before launching new hiring actions — a discipline that, if actually followed, would force better demand alignment upfront. It mostly didn’t happen and, absent the sort of prompting we talk about later, is hard to enforce. Partly this is a culture problem, but it’s also a structural one: agencies that don’t plan for talent surges find that new hiring needs don’t align with their existing workforce plans or their capacity to recruit, assess, and onboard. You can’t opt into a pooled action and then be surprised when the pool fills.
We struggled to tell the right people, and the system didn’t either. There’s a more fundamental problem sitting underneath the demand-alignment failure: hiring managers and HR specialists often don’t hear about pooled hiring announcements at all, and when they do, it’s generally not with enough lead time to actually prepare. Pooled actions get announced through OPM memos and Chief Human Capital Officers (CHCO) Council communications that circulate at the leadership level (and boy howdy did we circulate!), but that information doesn’t reliably travel to the hiring manager who is already three weeks into drafting a job announcement for the exact role sitting in a shared cert. And when it does arrive, it arrives as information: there’s no deadline attached, no checklist triggered, no reason to stop what they’re already doing. As it stands, among the 200K+ hiring managers, most made very few hires a year or in their overall career, so learning a process with barriers to entry was challenging.
Nothing interrupts the default action.The deeper problem is that nothing in the hiring workflow itself cues anyone to look. When a hiring manager initiates a new action in the hiring system, they’re not pushed or incentivized in any systematic way to check for an existing cert. When an HR specialist begins drafting a job announcement, no flag surfaces to say: a shared certificate for this position series already exists, do you want to use it? The system simply lets them proceed. This means that even when an agency or OPM has done the work of running a pooled action and producing a cert, agencies duplicate that effort anyway; less due to indifference, but because the path of least resistance is to do what they’ve always done, and nothing in the process interrupts that default.
The fix here is partly cultural but a lot technical. The Agency Talent Portal and USA Staffing need to surface available shared certificates at the moment a hiring manager or HR specialist initiates a new action for a covered position: as a required check embedded in the workflow itself. If you’re about to post a GS-12 data scientist announcement and there’s an active governmentwide cert for that exact series and grade, the system should tell you, right then, before you proceed. Opt-out, not opt-in. The current design assumes awareness that doesn’t exist and motivation that isn’t reliable.
Pooled actions were expensive for the “owner” and the experts: While cost-saving overall, running pooled actions could be resource and time consuming for the “owner,” and particularly the subject matter experts brought in for assessment, particularly when hires were not ultimately made.
The position description bottleneck. Pooled hiring inherits whatever good and bad planning exists in agencies’ position description (PD) libraries. Even for commonly-hired roles, position descriptions are not always readily accessible and, likewise, standard assessments often don’t exist at every grade level. But it’s a bigger challenge than that: the whole GS system presumes (competencies, job task analyses, and more) that every job is highly specialized, not generalizable for cross-agencies pools. FAS documented this directly: OPM and the Permitting Council collaborated to create a pooled, cross-government announcement for Environmental Protection Specialists — one job announcement producing a candidate list many agencies could use. But the assessment became a bottleneck because standard assessments didn’t exist for each grade level in the announcement, requiring significant additional development time. This isn’t an edge case, it’s a Tuesday. Breaking! OPM Director Kupor just announced a new AI tool to generate PDs! We’ll follow with interest.
Hiring managers couldn’t get access without a permission chain. For a new hiring innovation to be adopted, you’d think that all the barriers, incentives, and opt-in/out dynamics would be aligned. You’d be wrong. Pooled hiring at a “mother may I” architecture: system passwords and access, coordinators, gating processes, intermediaries between hiring managers and shared certificates. It’s a design flaw dressed up as compliance. The same 2024 memo had to explicitly direct agencies to update hiring manager permissions in the Agency Talent Portal. That it needed to be said tells you everything about how poorly the access question had been handled. As FAS and the Niskanen Center jointly documented in their analysis of the current OPM hiring memos, the toughest tasks are also the most crucial: changing the culture around hiring to empower managers, and actually letting line managers be managers.
Talent teams could be a good idea that keeps getting launched without the authority or resources to actually work. Every administration for the past decade has called for empowered agency talent teams — small, specialized units charged with driving hiring innovation, adopting new tools like SME-QA, and coordinating participation in pooled actions. M-24-16 explicitly called for agencies to create and sustain these teams, and the current OPM Merit Hiring Plan has stood one up at the central level as well. The concept has potential but execution has been consistently undercut by the same failure mode: no committed resources, no authority to intervene, no access, and no product mindset. In understaffed agency HR offices that were not empowered to “get to yes”, the function hasn’t meshed well, and moreover, it’s arrived in a system that already lacks strong strategic workforce planning, a key enabler of its potential success.
As FAS and the Niskanen Center documented agency talent teams, OPM communications and education support, and the necessary systems changes all require people, money, and IT investment that hasn’t materialized. Announcing a mandate is not the same as funding its execution.
But underfunding isn’t the only problem. Even well-resourced talent teams have struggled when they lacked the institutional standing to actually change agency behavior. The core failure mode is assuming that having good people in the building is enough — that talent solves problems on its own, without a clear theory of change about authority, access, and how decisions get made. An agency talent team that is advisory in nature, without a direct line to hiring managers and HR decision-makers, without leadership backing when they push back against entrenched process habits, and without metrics that create accountability for adoption, is not going to move the needle on pooled hiring participation. It’s going to produce reports and hold workshops and then watch agencies do what they were already going to do.
Veterans preference created confusion that nobody addressed proactively. Preference applies differently in delegated examining versus merit promotion contexts. When agencies share certificates across those lanes, legal ambiguity creates real hesitation. This is genuinely solvable — but only if OPM issues targeted guidance with each pooled action as a standard part of the launch package. Stepping back, it’s necessary to state that any type of absolute preference is going to make pooled hiring challenging. Clarifying guidance is a Band-Aid.
Small technical barriers compound the problem. One underreported friction point: shared certificate policies can constrain agencies from sharing certs across different geographic locations designated in the original announcement, or across different hire types — temporary versus permanent. An agency running a pooled action for DC-based positions can’t easily extend that cert to field office hires. A cert issued for permanent positions doesn’t smoothly cover term appointments. These are solvable technical problems that OPM and OMB could fix through policy revision but they require someone to actually map the barriers before designing the action.
And when agencies go it alone anyway, the burden multiplies for everyone. This is the part that gets lost in discussions that treat siloed hiring as merely inefficient rather than actively harmful. When agencies that are already understaffed — particularly permitting and HR teams — don’t leverage opportunities to work together, bottlenecks compound. Pooled hiring isn’t just a convenience for well-resourced agencies. For teams that are already stretched, it’s the difference between a manageable workload and an impossible one.
Agency HR leads without the skills or network to work across agencies. Like so much else, pooled hiring depends on relationships. OPM and agencies have not carefully selected the HR managers who not only understand the potential policy barriers to working across agencies but the collaboration skills and networks to solve problems quickly.
The Assessment Question: Use the Right Tool Not the Easy One
If you’ve read this far, you’ve probably heard of things like SME-QA, the greatest acronym in the hiring world. Let’s talk assessments.
The default federal hiring assessment — the self-assessment questionnaire — is effectively worthless for identifying technical talent. As Jennifer Pahlka has put it, the system has been built so that the most important knowledge is how the hiring process works instead of the knowledge needed to do the job. A nationally recognized programmer once applied to the Department of Defense and was initially rejected because their resume described real expertise in language that didn’t match OPM’s classification keywords. Meanwhile, someone who understood the system could mark themselves “expert” across every self-assessment category with no verification at all.
The Subject Matter Expert Qualification Assessment, or SME-QA, was one of the skills based hiring toolkits developed to fix this: real experts screen for real skills, with HR ensuring merit principles hold. SMEs independently review every resume. Candidates who clear the initial bar then go through further steps like structured interviews, coding exercises, or written assessments — administered by other practitioners in the field, not generalist HR staff. For technical roles going into a pooled action — data scientists, cybersecurity professionals, engineers — SME-QA paired with a shared certificate is close to the ideal design. Build the assessment once with governmentwide SME input, share the cert, and every agency draws from a pool that was actually screened by people who know the field.
But any skills based hire practice has a scaling problem that’s been documented since the first USDS pilots. The work is resource intensive for federal agencies not used to dedicating so much SME time to a hiring process. As Niskanen’s recent analysis of the Chance to Compete Act makes clear, new written assessments developed by industrial-organizational psychologists are extremely resource-intensive to produce — likely prohibitively expensive at the scale needed to cover broad swaths of the federal workforce. But there are roles and moments where such dedicated investment makes sense.
The design principle that should govern this: pooled hiring should be an opportunity to concentrate assessment burden at the enterprise level, not multiply it at the agency level. Build the assessment once, or maximize use of SME-QA time, governmentwide, for roles where it genuinely matters. Actually use them consistently rather than rebuilding from scratch at each agency. And as Niskanen argues, transform OPM’s role from compliance monitor to assessment engine: a marketplace of vetted, shared tools agencies can pull from rather than commission independently.
There’s a trust dividend here too. Agencies that contribute subject-matter experts to the assessment design have far more reason to trust the resulting certificate. Skin in the game at the assessment stage translates directly to confidence at the hiring stage.
A Note On Listening
Many successful pooled actions worked because OMB and OPM (or other senior White House offices) gave attention, capacity, authority and accountability to the process, bolstering agencies who were being asked to execute hiring with unusual flexibility and competence.
Overall, however, when agencies told OPM and OMB that pooled hiring was hard for them to execute alone, the response from the center was too often some version of: the guidance is out there, the instructions are online, that’s how the process works. Agencies described a cascade of rigidities that made implementation genuinely difficult, and we weren’t always responsive. We treated compliance problems as communication problems. If agencies weren’t doing it right, they must not have understood it correctly, so the answer was more guidance, clearer FAQs, better webinars.
That’s the wrong diagnosis. What they were telling us was that the process didn’t fit their reality and that the gap between what the policy assumed and what their operations actually looked like was wide enough that no amount of additional instruction was going to close it. When the people responsible for carrying out a policy are consistently telling you it’s hard in specific, consistent ways, the right response is to ask what’s broken in the desig.. The people designing these systems need to hear that feedback as signal instead of as resistance to be overcome.
This is the reason why the recommendations in this piece are about structural changes to how pooled hiring is designed, not about better outreach or clearer communications. Agencies don’t need another memo explaining how shared certificates work. They need a system that works in the conditions they’re actually operating in.
How to Actually Do This Right
The current OPM actions are a real opportunity. Here’s what would make them work, stated as plainly as possible.
Lock in real demand before you launch. Not expressions of interest: actual hiring commitments with funded billets and named positions. The failure mode is OPM building a pool that agencies shop from slowly or not at all. Require agencies to submit hiring forecasts before they’re included in a pooled action, and hold them to those forecasts with visible accountability.
Build assessment infrastructure before the announcement goes up. Standardized PDs, validated assessments, and clear SME selection criteria that agencies trust need to exist before the action launches. Thecentralized position description library called for in M-24-16 is the right vehicle. Critically, assessments need to exist at every grade level included in the announcement.
Build the awareness and the system prompt together. Upgrade communication on pooled hiring announcements directly to hiring managers and HR specialists. But communication alone won’t fix this. The Agency Talent Portal and USA Staffing need to surface available shared certificates at the moment a hiring manager or HR specialist initiates a new action for a covered position series and grade. This should be a required check embedded in the workflow itself — before they proceed with drafting a new announcement. If you’re about to post a GS-12 data scientist announcement and an active government-wide cert exists for that series and grade, the system should tell you right then. The current design assumes awareness that doesn’t exist and motivation that isn’t reliable.
Pool the interviewing, not just the screening. Coordinated interviewing days. Same-day or 48-hour offer authority for hiring managers. Agencies competing for the same candidates simultaneously, not sequentially. Cross-agency onboarding cohorts that start together and build peer networks from day one. This is what actually compresses time-to-hire.
Fund and empower talent teams as implementation infrastructure. Every idea in this piece requires someone inside each major agency whose job it is to make that happen. That’s what a talent team is for. But talent teams need three things that they rarely get: a dedicated budget line, direct access to the hiring managers and HR leadership they’re supposed to influence, and metrics that hold them accountable for adoption rates and actual hiring outcomes rather than process activity. A talent team of one person with a shared budget and no senior sponsor is not an implementation strategy.
Give hiring managers direct access. Update the Agency Talent Portal permissions. Eliminate the intermediary layers between a hiring manager and a cert they’re authorized to use. Hold managers accountable for whether they hire. Culture change here is real but it follows structural change: when managers have direct access and clear authority, behavior shifts.
Make follow-through a metric with teeth. Agencies that opt in and don’t hire should have to explain why, publicly, to the President’s Management Council.The voluntary participation problem doesn’t get solved with please-and-thank-you memos.
Run continuous pooled actions for common roles. HR specialists, contracting officers, environmental specialists, IT managers — these aren’t surge needs, they’re permanent ones. A cert that’s always open, with agencies drawing from it as needs emerge, is far more useful than a prestige program that runs once a year and then goes quiet.
The Bigger Lens
(with thanks to Gabe Menchaca and Peter Bonner for making the stronger argument)
Pooled hiring is a microcosm of a question the federal government seesaws on constantly: what does it mean to govern as an enterprise rather than as several hundred agencies that happen to share a payroll source?
This requires admitting something those of us who have worked in the center don’t always say plainly: agencies and their leaders are protecting their turf for understandable reasons. They are accountable for their missions, their budgets, and their outcomes. When a pooled hiring action asks them to trust a cert they didn’t design, coordinate interviews around a shared calendar, and accept that they won’t get every single thing they want, and that’s a big ask! The trade may be worth making, but it doesn’t happen automatically, and the center has not historically done a good job making the case for why, or building the conditions under which agencies can actually say yes.
That’s a collective action problem, and it’s harder than it looks. It requires genuine leadership alignment across all the agencies involved, and a center that has made the benefit of cooperation concrete and visible rather than just asserting it in guidance. Too often the response to non-participation has been more documentation rather than an honest look at what the actual barrier was. That’s compounded by a structural problem worth naming: agencies are accountable for their HR outcomes but OPM holds much of the compliance authority over how hiring gets done. Accountability without authority produces exactly the behavior you’d expect.
The federal government has demonstrated it can operate differently. The BIL surge, the data scientist certs, USDA’s HR specialists (and maybe Tech Force) worked because the conditions were right: shared design, locked-in demand, leadership alignment, enough urgency to overcome the default toward agency autonomy. The question is whether we can build those conditions deliberately rather than stumbling into them during a crisis. That requires a solid theory of change about how cross-agency infrastructure actually gets adopted: one that takes agency self-interest seriously as a design constraint rather than an obstacle to be overcome by memo. Get that right, and pooled hiring becomes a model for how the federal government decides what to do together and what to do apart. That’s a bigger prize than faster hiring. It’s a more functional government.
Strengthening the Federal Cycle of Learning and Adaptation by Closing the Loops
The federal government has a feedback-loop problem.
Regularly generated information, including evidence, performance information, and qualitative insights from implementation, too often fails to shape decisions. Evidence may be reviewed without changing priorities; performance data may be tracked without clarifying what it informs, and implementation feedback may reach leadership without surfacing what works for whom and why, or suggesting next steps. The components of a cyclical learning system linking priorities, questions, evidence, decisions, and implementation information exist in theory and on paper, but the connective tissue that turns all of these components into a functioning cycle of learning and adjustment is lacking. Information and artifacts alone don’t necessarily facilitate learning and adaptation; strengthening federal feedback loops requires embedding translation and use into decision-making from the start.
This memo is not a case for new infrastructure. The Evidence Act, learning agendas, evaluation plans, performance frameworks, and customer experience authorities already exist; what they do not yet add up to is a learning system. The translation this memo proposes is turning the infrastructure we have into the learning system we need, and it’s addressed to federal program leaders, policy officials, evaluation and evidence staff, performance officers, and strategic planning teams who already sit inside it and are best positioned to make it function as intended.
Challenge and Opportunity
The federal government already operates within a broad cycle of goal-setting, evidence generation, performance review, implementation, and reporting. On paper and in principle, this cycle should allow for learning, adjustment, and improvement to federal programs over time. In practice, however, agencies vary in how consistently they translate such information into planning, decision-making, or course-correction. Federal agencies have made progress in building and using evidence, but translating that information into timely operational or policy revisions remains uneven.
The core problem isn’t production; it’s translation, and the translation failure shows up as “so what” gaps on both sides of the information pipeline. On the input side, receivers of information are often left asking what they’re supposed to do, and on the output side, a second question appears – “is it my job to act on this, and if so, how?”. Research findings are often too slow, too caveated, or too disconnected from immediate policy and management questions. Performance data may show quantitative changes in outputs, costs, or enrollment without revealing the mechanisms behind them or the practical implications for implementation, or cueing the design apparatus that could apply these insights. Feedback from frontline service providers and affected users might reach leadership mainly through quantitative indicators, dashboards, or status updates, which don’t always capture lived experience, causal explanation, or informed suggestions for course correction. Without named owners and defined next steps, even the most actionable information tends to circulate rather than convert.
Three gaps sit behind this pattern. First; a context gap – decision-makers often lack the full picture, because qualitative indicators and customer experience research arrive separately, or later than quantitative evidence, leaving them with only a partial view of what’s working well or driving implementation problems. Second, an action gap; even with a complete view of the picture, it’s not always obvious which lever applies, on what timeline, or with what tradeoff. Third, an ownership gap; it’s often unclear who is responsible for translating any given signal into a decision, and this ambiguity means that insights can be observed without being acted on. Together, these three gaps leave evidence and feedback insufficiently integrated into decision-making routines.
The problem is also structural; decision-makers face turnover, competing priorities, time limits, and management pressures, and thus, evidence needs a more robust pathway. Devoid of clear translation, trusted messengers, and defined or mandated use points, even the most relevant information can be too late, too ill-timed, or too jargon-heavy to influence decisions, resulting in missed adaptation opportunities.
The federal government doesn’t need an entirely new learning architecture. It needs to make the one it already has more usable. Agencies can do this in a few ways. First, by building stronger translation functions by creating space for “knowledge brokers” (people or teams whose core function is to translate evidence into decision-relevant language and maintain the required relationships that make the translation trusted). Second, by incorporating the use of evidence, performance, and implementation feedback into policy and program work from the start. Third, by creating better pathways for implementation and lived-experience feedback to reach leadership in ways that resonate with them and support action.
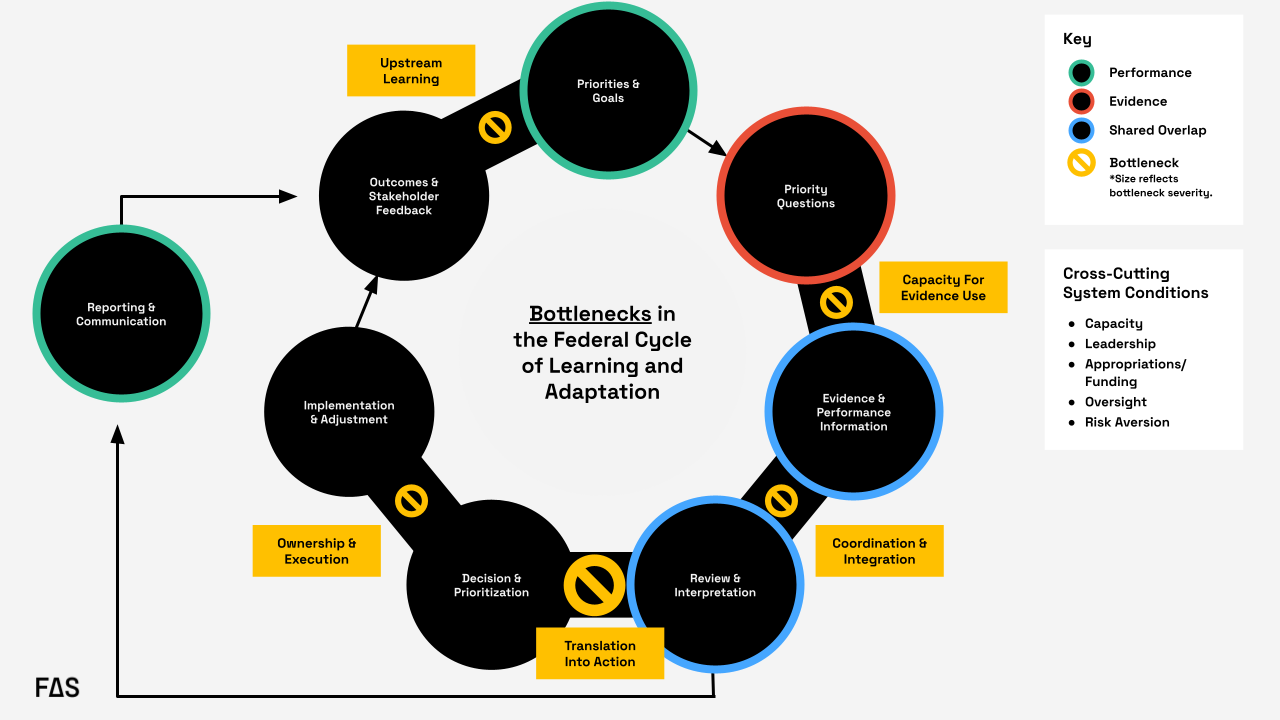
Formal federal guidance envisions a closed “loop” linking goals, priority questions, evidence, and performance information, along with review, decision-making, implementation, reporting, and feedback. In practice, the loop often degrades at key handoffs: evidence-use capacity, coordination and integration, translation into action, ownership and execution, and upstream learning from outcomes. The most significant recurring bottleneck occurs during the transition from review and interpretation to decision and prioritization, where information is generated and reviewed but does not reliably translate into action.
Plan of Action
We need to shift from a system that collects information to a system that uses it.
Agencies should create or strengthen embedded translation functions that connect evidence, performance information, implementation experience, and policy levers at the moment decisions are being made. The key is to move from a dissemination model to a utilization model. Instead of “produce, disseminate, and hope for uptake”, agencies should do the following:
Recommendation 1. Designate a knowledge broker to facilitate regular decision briefs…
or routines that create structured opportunities to clarify what’s known, what’s uncertain, and what actions are available – beginning with a defined set of high priority issues rather than every single decision the agency needs to make.
This recommendation targets the translation into action bottleneck in Figure 1; the handoff from review and interpretation to decision and prioritization, which can be considered the most significant recurring point of failure in the federal cycle of learning and adaptation. In practice, this means assigning this function to a role or small team housed in an existing performance, evaluation, strategy, or program office and requiring that group to support recurring decision points with short decision briefs. Those briefs should identify the decision, synthesize relevant evidence, performance trends, and implementation feedback, and specify available actions, tradeoffs, and owners.
For example, in the rollout of the FAFSA Simplification Act, a knowledge broker tied specifically to this initiative could have translated readiness indicators, beneficiary feedback, and information from financial aid administrators into decision-ready synthesis for the officials with decision authority who were attempting to course correct in real time. Instead, significant delays turned the rollout into a high-profile implementation issue.
Crucially, this function should start narrow. Rather than positioning a knowledge broker as an all-purpose translator for an agency’s full decision load, the initial portfolio could be scoped to a small set of priority issues. Starting narrow lets the broker establish credibility and relationships that make translation trusted and refine what the routine and explicit outputs are before it scales – the portfolio can scale later. This gives agencies a defined mechanism for turning reviewed information into decisions rather than leaving that handoff informal. Within the federal government, the Office of Evaluation Sciences has modeled how an embedded team of evidence translators can work alongside program offices rather than from a silo.
Recommendation 2. Start policy initiatives and evaluation planning with a real question…
or decision, identify the user, specify the lever, and clarify – in advance – what different findings would imply. Incorporating this thinking upstream changes the role of evidence from a retrospective input to an operational tool.
This recommendation mainly addresses the translation into action bottleneck, and secondarily, the evidence-use capacity bottleneck. Agencies can operationalize this by building decision framing into existing learning agenda and evaluation planning processes, both of which are already required under the Evidence Act. Before an evidence product is commissioned or a performance indicator is selected, program offices can be required to answer four questions on the record: What decision is this for? Who will use it? What lever would change as a result? What finding would lead to what action?
In a hypothetical example, say that USDA’s Food and Nutrition Service (FNS) wants to commission a new evaluation or analysis regarding SNAP redetermination churn (the pattern of households losing SNAP benefits at recertification and then re-enrolling, often for procedural reasons rather than eligibility). The four questions noted above can be answered on the record before the work begins. The decision is whether to issue new guidance to state agencies on recertification practices and what that guidance should encourage. The user is the FNS administrator and the relevant policy office, with state level SNAP directors as the implementing audience. The lever is subregulatory guidance. The early thinking regarding mapping findings to actions would specify, in advance, which patterns or insights would trigger which associated response. This way, when the findings arrive, USDA wouldn’t be starting from scratch with the “what do we do with this” question; the decision architecture would already be in place.
Pre-specifying these conditions in a short decision-framing memo that travels with the work turns evidence from a retrospective deliverable into a tool scoped to a specific decision or policy window. The same logic extends to decision memo templates themselves, which can include standing prompts such as “what evidence informed this decision?” and “how will we learn about this in real time?”, so that utilization is built in.
Recommendation 3. Create pathways for easier access to mixed methods evidence and insights from lived experience.
Recommendation 3 targets the coordination and integration, and upstream learning bottlenecks; the gap where evaluation, performance, administrative, qualitative, and customer experience data move at different speeds, live in different places, and reach decision-makers as parallel streams. Insights from lived experience – what programs actually look and feel like to the people using them – are particularly likely to be separated from information that reaches leadership, arriving as anecdotes, if they arrive at all. Because these problems are distinct; the recommendations can be broken down and addressed at the agency level.
Recommendation 4. Standardize decision-ready formats that consolidate quantitative and qualitative evidence.
Agencies should build standardized decision templates and briefs that present quantitative indicator-level data alongside narrative summaries of lived experience and implementation conditions, so decision-makers aren’t expected to synthesize across disparate sources on their own timelines. The resulting artifacts should be tied to recurring decision moments (budgeting, guidance revisions, program reauthorization) so that they can be used in real time.
In the FAFSA Simplification Act rollout, the Department of Education leadership faced this problem: application data, technical readiness indicators, information from financial aid administrators, and user feedback existed separately, and moved at different speeds. A standardized decision-ready format could have pulled those streams together; pairing completion trend data with brief narratives or exemplary quotes regarding what applicants and financial aid offices were actually encountering, rather than leaving leaders alone to assemble the picture in real time
Recommendation 5. Actively use existing general clearance mechanisms for rapid qualitative and user experience research.
Agencies should make use of standing generic clearance mechanisms that allow them to fast-track small qualitative and user experience studies (for example, up to 100 respondents, completed within a fixed time window) when unexpected findings need rapid explanation. This would allow for the ability to run a tightly scoped evaluation in weeks rather than months, which is the operational timescale at which decisions frequently move. Without it, the qualitative evidence needed to explain any type of performance anomaly often arrives after the decision or policy window has closed.
For SNAP redetermination churn, this would let FNS turn around a short, scoped evaluation of why participants are dropping off at a specific step in the recertification cycle in weeks rather than months. The insights could then inform the next round of guidance rather than coming in after the fact.
Recommendation 6. Build customer-first indicators built into existing federal reporting requirements.
Beneficiary and frontline experience should become part of the evidence base by default rather than by exception. Most federal programs already have reporting infrastructure, and layering in a modest set of customer-first indicators that use the existing infrastructure rather than building new information collection requirements ensures that user perspectives are consistently available as routine inputs.
Within the federal government, the customer experience and life experience work coordinated through OMB and performance.gov has demonstrated that lived experience can be collected and used at scale within existing authorities, which can be considered a foundation to build from rather than reinvent. At the state level,Minnesota’s Story Collective, housed within Minnesota Management and Budget (MN MMB), pairs administrative and performance data with qualitative, lived-experience narratives to give decision-makers a richer view of what their programs are actually producing.
These recommendations also address a common weakness in the federal system: evidence and performance information sit within the same broad ecosystem but move at different speeds, use different tools, and often reach different audiences. This is all the more reason to create a translation layer that can synthesize across them. Agencies need staff and routines that can connect evaluation, administrative data, performance indicators, qualitative input, and implementation realities into decision-relevant guidance. Without that connective tissue, agencies are left with parallel streams of information that don’t consistently converge at the point where action occurs.
Conclusion
The federal government already generates a great deal of information about what it’s doing and how it’s performing, but information isn’t the same as learning, and learning isn’t the same as adaptation. The gap between them is where the “so what” goes unanswered, and where the federal feedback loop breaks down.
Closing these loops doesn’t require new infrastructure or authority. It requires three shifts in how the existing system is used: designating knowledge brokers to carry translation across the handoff from review to decision-making, building decision framing into policy and evaluation work from the start so that evidence is scoped to the decisions it’s meant to inform, and creating pathways that move mixed-methods and lived experience into decision-makers’ hands in formats and timeframes that match how decisions actually happen in the federal environment. Whether the question is about USDA responding to SNAP redetermination churn or the Department of Education learning from an application rollout in real time, the underlying pattern is the same: the signals exist, but the translation that turns signals into actionable insights doesn’t reliably happen.
If the government wants a system of learning and adaptation that improves results in real time, it has to treat translation, utilization, and adaptation as core functions of governance rather than as afterthoughts.
Outcome-Based Contracting Reorients Government IT Acquisition Around Public Value and Mission Results
The effectiveness of federal programs is increasingly determined by the technology that powers them. Yet decades of oversight and research have documented persistent challenges in large-scale IT modernization. The Government Accountability Office has repeatedly designated federal IT management as high risk, citing cost overruns, schedule delays, weak requirements management, and inadequate oversight. Bent Flyvbjerg’s research shows that large public-sector technology and infrastructure programs are especially prone to failure due to scope creep and cumulative risk. The Defense Innovation Board similarly concluded in Software Is Never Done that long development cycles and early requirement lock-in expose missions to unacceptable risk.
Across these analyses, the pattern is consistent: requirements are defined too early and too rigidly; performance is measured too late; incentives reward milestone completion rather than operational outcomes; and risk accumulates until deployment. These failures reflect several structural challenges—fragmented funding, leadership turnover, legacy system complexity, and acquisition models that delay validation and limit adaptation.
Traditional acquisition approaches assume stable requirements and predictable environments. Software-intensive systems do not behave this way. Requirements evolve, dependencies emerge during implementation, and technology ecosystems shift over the life of the contract. In this context, specification-driven models can increase risk by delaying feedback and limiting course correction.
This paper examines Outcome-Based Contracting (OBC) as a model for aligning acquisition with the realities of modern IT delivery. OBC reframes procurement around the staged achievement of measurable mission outcomes rather than the delivery of predefined technical artifacts. OBC ties funding, evaluation, and continuation decisions to mission outcomes and pairs naturally with iterative delivery practices that surface and reduce risk early.
Outcome-Based Contracting
Federal acquisition models have evolved over time in response to changing technologies and risks. Early approaches emphasized detailed specification and cost control, with contracts structured around defined requirements and reimbursement of inputs (e.g., cost-plus and fixed-price models). As systems grew more complex, performance-based contracting emerged to shift focus from activities to measurable outputs and service levels. However, in complex and dynamic environments, even performance-based models often remain tied to predefined deliverables and intermediate metrics, limiting their ability to adapt as conditions, requirements, and understanding evolve over time.
Outcome-based contracting (OBC) represents a further evolution. It structures the government–contractor relationship around shared accountability for mission results rather than delivery of predefined outputs. Its defining feature is not a pricing model, but the alignment of incentives, governance, and performance measurement around measurable mission outcomes.
As Allan Burman notes, building on performance-based contracting, OBC shifts accountability from activities and milestones to mission outcomes. In practice, it establishes a structured process in which government and contractor jointly deliver measurable results, with contracts defining decision rights, evaluation mechanisms, and adaptive processes.
Key features include:
- Shared accountability: success is defined in operational terms, not artifact delivery
- Collaborative outcome definition: the government defines the problem to be solved, contractors propose and refine approaches as evidence emerges
- Adaptive performance management: metrics guide decisions, not just compliance
- Joint problem solving: governance supports rapid adjustment when performance diverges
A useful way to understand outcome-based contracting is as a managed performance relationship rather than a one-time procurement transaction. As research from the IBM Center for The Business of Government emphasizes, effective outcome-based models require clearly defined desired results, measurable indicators of success, and ongoing performance management processes that allow both parties to assess progress and adjust course. This includes establishing baseline performance, continuously monitoring results, and linking financial incentives, contract options, and governance decisions to demonstrated improvement. Critically, these models depend on sustained collaboration and transparency: agencies must be able to interpret performance data and engage in joint problem-solving with vendors, rather than relying solely on compliance reviews. In this sense, OBC is not simply a different way to write requirements—it is a different way to manage delivery, in which measurement, incentives, and decision-making are continuously aligned to achieving mission outcomes.
Applying Outcome-Based Contracting to IT Modernization
Applying OBC to IT modernization requires three shifts: defining measurable outcomes, structuring decision rights, and organizing contracts around incremental delivery.
Defining outcomes
Mission objectives must be translated into measurable operational indicators—such as transaction completion rates, time to resolution, system availability, or error reduction. These indicators must be precise enough for evaluation while reflecting real-world service performance.
Effective models distinguish between:
- Mission-level outcomes (stable): e.g., reducing time to receive benefits
- Implementation metrics (adaptive): e.g., response times or interim system thresholds
For example, a call center contract might set a mission outcome of reducing resolution time by 30 percent, supported by metrics such as speed of answer, first-contact resolution, and callback completion time.
A central design question is how outcomes are embedded in the contract. Outcomes can function as binding accountability anchors, linked to evaluation, incentives, and option decisions, but not as rigid end-states. This approach is only effective when supported by governance structures that allow agencies to interpret performance and adjust delivery.
Critically, outcomes and the underlying problem definition must be treated as testable and subject to refinement. Initial problem framing is often incomplete in complex systems. Contracts and governance models should therefore include regular check-ins, using data, user research, and operational feedback to assess whether the problem is being solved as intended. Where necessary, agencies and vendors must be jointly empowered to restate or refine the problem to ensure continued alignment with mission needs.
Structuring decision rights
OBC requires clear decision making authority over priorities and tradeoffs. In software delivery, this centers on a strong government Product Owner (PO) role. The PO is responsible for backlog prioritization, acceptance criteria, and aligning delivery with mission outcomes. The PO must be empowered to continuously adjust priorities based on user needs and performance data without requiring contract modifications. Contractors are accountable for delivering measurable progress, but do not control mission priorities.
Governance must reflect agency maturity, and also the nature of the initiative. More mature organizations can rely on PO-driven execution and adaptive metrics, using contract outcomes as high-level anchors. Even in less mature agencies, OBC principles can be applied in targeted ways—particularly in user-facing systems or components where outcomes can be clearly measured. In some cases, especially large enterprise system implementations, hybrid approaches may be required. These may combine clearly defined objectives and outcome metrics with more structured implementation phases for core platform rollout. The key is not strict adherence to a single methodology, but aligning decision rights, outcomes, and delivery approach to the realities of the system being implemented.
Structuring incremental delivery
Contracts must support incremental, evidence-based delivery. Large, multi-year programs defer risk discovery until late in the lifecycle. Iterative delivery reduces this risk by shortening feedback loops: capabilities are deployed incrementally, evaluated under real conditions, and adjusted early. Incremental delivery provides disciplined mechanisms for iteratively paying down risk.
OBC complements this model by tying funding and continuation decisions to demonstrated performance. Agile practices surface risk; OBC aligns accountability and resources to its mitigation.
This has direct implications for funding models. Effective OBC implementations require upfront decisions about how much funding is allocated to a product or service, with mechanisms to adjust that funding over time based on performance. Budgeting should support iterative scaling—expanding or contracting investment based on whether outcomes are being achieved. This, in turn, requires financial flexibility, such as capability-based budgeting, and the ability to reallocate funds or leverage working capital-like mechanisms.
In practice, appropriations constraints can limit this flexibility. For example, agencies operating under single-year appropriations may struggle to dynamically adjust funding in response to performance signals. Addressing this requires coordination between acquisition, product, and financial management functions to ensure that funding structures align with the adaptive nature of outcome-based delivery.
Outcome-Based Contracting In Practice
Outcomes-oriented approaches are not new but remain underutilized in IT acquisition. Existing models demonstrate the value of aligning funding to measurable performance.
Within government, the Department of the Navy’s World Class Alignment Metrics (WAM) evaluates IT investments based on outcomes such as resilience, customer satisfaction, and cost per user. Similarly, Department of Defense Performance-Based Logistics ties compensation to readiness outcomes, and NASA’s Commercial Crew program links payments to demonstrated capability.
These examples share a core principle: funding follows validated performance rather than predefined inputs. Applied to IT modernization, this requires pairing mission outcomes with iterative delivery, clear decision rights, and sustained technical engagement. Without these elements, outcomes risk becoming abstract goals rather than operational tools.
Despite its advantages, outcome-based contracting is not the default in federal IT acquisition. In practice, existing incentives continue to favor specification-driven models: funding structures are rigid, oversight emphasizes compliance with predefined requirements, and procurement processes reward detailed up-front definition over adaptive execution. The following case illustrates how these dynamics shape real-world outcomes—and how leadership, governance, and delivery choices ultimately determine whether programs succeed or fail.
Case Study: SSA Call Center Modernization
The Social Security Administration (SSA) operates one of the largest public-facing service platforms in the federal government, serving approximately 70 million Americans through its national 800-number network and field offices, processing high volumes of calls. In 2017, the SSA faced growing problems with its aging, complex telephone infrastructure and rising wait times for the tens of millions of Americans who rely on the agency’s national 800-number for assistance with benefits, Social Security numbers, and other services. To address these issues, SSA launched the Next Generation Telephony Project (NGTP), a large IT modernization effort intended to replace legacy telephone systems and unify call handling across the agency.
NGTP emerged from a traditional acquisition model: a detailed, waterfall-style specification, a large systems-integrator contract, and milestone-based progress tied to predefined technical requirements. In February 2020 SSA awarded an IDIQ contract to Verizon to design, implement, test, transition, operate, and maintain the new telephony platform, including procurement of hardware, software, and services. Implementation faced challenges from the beginning: Verizon’s win was contested, delaying the start of work. SSA’s team didn’t realize the solution Verizon proposed, reinforced by SSA’s own contract requirements, was based on architectural components that were a generation behind leading contact center systems. NGTP’s 10-year planning horizon meant any solution would likely be obsolete before full deployment.
By 2020, with the project still in early development, the COVID-19 pandemic forced SSA call center agents to work remotely — a capability the existing legacy system lacked. Verizon scrambled to assemble a custom stopgap solution, but this was plagued with issues. From May 2021 to December 2022, over 40 service disruptions caused dropped calls, long wait times, and outages. At times, more than half of calls went unanswered as the team capped incoming calls to maintain system stability.
Meanwhile, NGTP suffered further delays and technical hurdles. SSA executives were frustrated but assumed they were contractually stuck. The system finally launched in December 2023 for the 800-number only, delivering just part of the promised functionality. But the system experienced ongoing performance issues, including increased wait times and disconnected or unanswered calls that hindered the agency’s ability to serve the public. On August 22, 2024, after only about 10 months of operation, SSA transitioned the 800-Number Network off the NGTP platform and moved to a different telephony solution. The NGTP project cost SSA over $160 million and was abandoned within a year of deployment, with the agency reverting to an alternative telephony platform.
The failure was not attributable to a single cause. Interviews and oversight findings point instead to a combination of over-specification, missing mission outcomes, weak accountability mechanisms, long planning horizons, and an acquisition structure that made adaptation difficult.
It is also important to recognize the scale and complexity of SSA’s operating environment. The agency’s service delivery depends on hundreds of interdependent systems, many of which encode decades of policy and operational logic. Modernization efforts must contend not only with outdated technology, but with deeply embedded business rules and integration dependencies that are not always fully visible at the outset. These conditions increase the difficulty of both specification and implementation, regardless of acquisition approach.
Specificity Did Not Produce Control
A central lesson of NGTP is that specificity in requirements does not necessarily translate into control over outcomes. The solicitation and technical requirements were extensive and highly prescriptive. They incorporated staff input but lacked sustained user-centered validation and focused heavily on defining technical components rather than the operational outcomes the system was intended to achieve. In several cases, the contract mandated architectural approaches that constrained flexibility and effectively locked the program into solutions already lagging prevailing commercial practice.
The NGTP contract required the development of significant custom telephony capabilities in a market where mature commercial Contact-Center-as-a-Service (CCaaS) platforms already existed. Custom software and hardware development inherently carries greater risk than configuring established commercial platforms: the first buyer bears the cost of defects, scaling problems, and design errors that mature products have already identified and resolved. As a result, the program assumed substantial technical risk without clear evidence that SSA’s mission required a bespoke system.
The decision to pursue a custom telephony architecture also introduced structural technical risks. The system was intended to function as a “single enterprise contact center” capable of routing calls across SSA’s national network. In practice, however, the implemented solution consisted of six separate contact centers operating as independent queues rather than a unified system. According to the SSA Office of Inspector General, this configuration prevented calls from being dynamically rerouted between queues, limited agents to answering calls from a single queue, and could disconnect calls when agents logged out of one queue even if capacity existed elsewhere in the system. These limitations increased wait times and created operational inefficiencies. Efforts to resolve the architectural mismatch led to the development of a custom routing “brain” intended to connect the six queues—effectively reinventing load-balancing technologies that have been widely used and commercially mature for decades. The need to retrofit this architecture required multiple contract modifications and created ongoing operational challenges. As one SSA leader later observed, “Some people on the project might have known that load balancers had been mature for 30 years, but managers weren’t listening to them.”
The contract’s prescriptive structure also undermined the flexibility typically associated with its contract vehicle. Although NGTP was structured as an IDIQ, the narrowly defined solution space meant that many necessary adjustments required formal work orders or contract modifications. In practice, the program combined the administrative rigidity of traditional contracting with the technical risk of custom system development.
The detailed specifications locked the implementation into many types of outdated architectural assumptions. For example, certain components were required to be compatible with an old, yet unspecified, version of Internet Explorer, a browser Microsoft formally retired in 2022 in favor of Microsoft Edge. Rapidly evolving technology environments can render highly specific requirements obsolete before systems are delivered. At the same time, the extensive technical detail did not fully address practical operational considerations, such as ensuring that existing SSA call center staff could easily access and use the system in their day-to-day workflows.
Missing Mission Outcomes
The NGTP case also illustrates the limits of operator-focused metrics. SSA understandably focused on call volume and the ability of the system to handle surges in demand. Previous infrastructure could “top out” during predictable spikes, such as cost-of-living adjustment periods. Capacity therefore became a central concern.
But throughput alone is not the same as service performance. For beneficiaries, the meaningful outcomes include how long it takes to reach a representative, whether the issue is resolved on the first contact, how many interactions are required, and how long it takes to complete a request. Those mission outcomes were not adequately embedded in the contract’s performance framework.
Metrics such as average speed of answer did not fully capture the user experience, particularly when calls were dropped, or handled initially by automated systems, or callbacks were counted in ways that reduced reported wait times without necessarily reducing the time required for beneficiaries to obtain help.
The deeper problem was architectural as well as contractual. SSA’s call center is best understood as a front-end interface to a much larger, deeply complex service delivery system involving eligibility determination, identity verification, claims processing, and payments. Yet the contract largely treated telephony modernization as a standalone technical problem rather than as part of an integrated operating model. This narrow framing also limited foresight into how the capability could evolve over time, adopting future emerging technologies or adding integrations with other agency systems to support an omnichannel service model. Defined primarily within a technical infrastructure context, the effort optimized for telephony components rather than positioning customer service as a strategic, cross-agency capability.
Accountability Was Weak Where It Mattered Most
Federal acquisition frameworks already provide multiple mechanisms for vendor accountability, including service level agreements (SLAs), financial incentives and penalties, option periods tied to demonstrated progress, and formal performance reviews. In the private sector, large IT and service contracts routinely embed such operational standards like uptime guarantees, response-time thresholds, incident-resolution timelines, and financial penalties for failure to meet them to ensure that vendors remain accountable for system performance under real operating conditions. In the NGTP case, however, these mechanisms were not sufficiently embedded in the contract structure or tied to mission outcomes and enforceable operational standards.
The SSA Office of Inspector General found that the NGTP contract lacked sufficient performance-based quality standards and incentives to ensure accountability for resolving system-performance issues. The practical result was limited leverage for the government even when the system failed to meet technical and operational needs.
The most striking example came at termination. When SSA stopped work on the NGTP effort, the agency still paid the vendor the remaining portion of the full $125M contract amount. Whatever the legal and operational considerations behind that decision, the message to the market was problematic: poor performance did not produce a proportionate financial consequence.
SSA’s Course Correction
SSA’s response illustrates an alternative approach. Rather than pursuing another large, fully specified replacement effort, the agency adopted a more incremental approach using cloud-native technology and more flexible contract mechanisms. A proof-of-concept deployment of Amazon Connect at a Pennsylvania call center allowed SSA to test the platform in live operating conditions before scaling further.
This approach introduced several disciplines that had been missing from NGTP. It reduced dependence on bespoke infrastructure, created an opportunity to measure performance under real conditions, and allowed the agency to collect operational evidence before broader rollout. Critically, assumptions were tested incrementally rather than embedded upfront. The agency also adopted Product Operating Model best practices: they stood up a cross-functional product team with a product manager, technical lead, design lead, and an SME lead who was responsible for state specific launches, training, and key metrics.
Early results suggested improvement. SSA’s Office of Inspector General reported that the agency’s telephone service handled substantially more callers in fiscal year 2025 and that reported average speed of answer improved. The subsequent administration leveraged the scalable platform to expand deployment across all field offices. At the same time, oversight and public reporting also highlighted the importance of careful metric design. Some reported gains did not fully reflect the total time beneficiaries waited for callbacks or to resolve their issues. That distinction is key: better performance frameworks depend not simply on more metrics, but on the right metrics.
Lessons for Outcome-Based Acquisition
The SSA case highlights several lessons:
- Complex systems cannot be fully specified in advance. Over-specification increases risk, and can lock programs into the wrong solution.
- Iterative delivery is a risk management tool. It surfaces integration, usability, security, and performance problems early enough to address them.
- Accountability must be tied to mission outcomes. Operational and customer experience results matter more than intermediate artifacts.
Governance matters as much as contract structure. Strong product ownership and leadership are essential. Critical to the successful turnaround was having a cross-functional “product quad” of product management, engineering, design, and domain expertise. In the NGTP case, requirements were largely defined within an infrastructure-oriented telecommunications function, leading to a solution optimized for technical components rather than end-to-end service outcomes. This organizational starting point constrained problem framing and limited the program’s ability to align delivery with user needs and mission performance.
An outcome-based model would have defined mission metrics such as first-contact resolution and total time to complete transactions, incorporated discovery phases, and tied continuation decisions to demonstrated performance. It also would have created a precedent for early adoption of critical monitoring tools used by leaders in the course correction, like integrating real-time customer experience telemetry into daily operations, which enabled continuous monitoring of user outcomes and rapid reprioritization of features to address emerging issues as they occur.
Finally, contract structure alone is not sufficient. Successful implementation depends on sustained leadership, technical judgment, and the institutional willingness to act on evidence. Several interviewees noted that meaningful progress accelerated only after leadership with prior agile and product delivery experience assumed responsibility for the effort. Acquisition structure can enable better outcomes, but it cannot substitute for leadership capable of making informed technical and operational decisions in complex environments.
Conclusion
Large-scale IT modernization is central to federal mission delivery. Traditional acquisition models remain effective in stable, well-defined environments but are poorly matched to software-intensive systems characterized by uncertainty, interdependence, and continuous change.
Outcome-based contracting provides a more effective framework for these conditions. It strengthens accountability by tying funding and continuation decisions to measurable performance, improves risk management through iterative delivery, and reorients acquisition toward public value. Rather than asking whether a contractor delivered what was specified, it asks whether the government achieved the mission results it needed.
Realizing this shift requires more than changes to contract structure. The authorities to pursue outcome-based approaches largely already exist, but incentives, funding constraints, and workforce capabilities continue to reinforce specification-driven models. Appropriations structures limit flexibility, oversight mechanisms emphasize compliance over performance, and many agencies lack the product management and data capabilities needed to define and act on outcome metrics. Addressing these constraints will require coordinated changes across budgeting, oversight, acquisition practice, and workforce development.
In the near term, IT modernization progress should be visible in concrete ways: contracts that tie option decisions and incentives to mission outcomes; programs operating with empowered Product Owners and real-time performance data; and evaluation frameworks that prioritize whether services are improving, not just whether requirements were met. Over time, this would mark a broader shift from managing compliance with plans to managing performance against outcomes.For technology and IT modernization efforts, the success of outcome-based contracting depends on alignment with product operating model practices, technical expertise, and sustained leadership. The central proposition of OBC is not less discipline, but better discipline—organized around measurable outcomes, empirical evidence, and the continuous identification and reduction of technical and operational risk.
Who Governs Government AI? The Challenge of Federal Implementation
Public Trust and the Stakes of Federal AI Regulation
Americans are skeptical that their government can regulate artificial intelligence. A Pew Research Center study from October 2025 found that while large majorities in countries like India (89%), Indonesia (74%), and Israel (72%) trust their governments to regulate AI effectively, only 44% of Americans say the same, and a greater number, 47%, express distrust. Globally, more people trust the European Union (53%) to regulate AI than the United States (37%). Americans will only realize the benefits of AI if they have confidence that these systems are used safely, fairly, and in ways that improve their lives.
Trust is not a soft concern: it is the foundation for the adoption, legitimacy, and long-term success of any technology. When people doubt that AI systems are governed responsibly, they are less likely to accept their use in sensitive domains like healthcare, education, public benefits, or national security. Public skepticism can slow innovation, undermine compliance, and deepen polarization around emerging technologies. Encouragingly, this is not a partisan issue. Republicans and Democrats alike have emphasized that trustworthy AI use is a prerequisite for public adoption and lasting legitimacy. If the U.S. is going all-in on AI, then building and maintaining that trust is therefore not simply a communications challenge; it is a governance imperative.
The federal government plays a starring role in meeting that imperative—not only as a regulator, but also as a model user of AI. It deploys some of the most consequential and high-risk AI systems, including those that shape access to benefits, guide law enforcement priorities, manage immigration processes, and support national security decisions. The federal approach to deploying these systems does more than affect service delivery or cost savings; it sets expectations for industry standards, academic research, and public perception of the technology. In effect, the federal government serves as a societal-level proving ground for AI governance. Because it uses AI in high-risk contexts, it must demonstrate that these systems can be governed effectively through transparency, oversight, accountability, and meaningful safeguards. Failure to do so would not only diminish confidence in AI as an economic and societal asset, but weaken the already tenuous trust the public has in government as a manager of risk and opportunity
Two use cases illustrate this point. One existing high-potential but high-risk application is the Veteran’s Administration’s (VA) REACH VET program, which uses predictive models to identify veterans at elevated suicide risk so clinicians can proactively reach out. Because it draws on health records and includes explicit race coding, one would be concerned about opaque modeling choices and the possibility of inequitable or incorrect flags. The stakes are high. If veterans feel that an algorithm is driving interventions without clear transparency, clinical guardrails, and accountability or if it misses potential intervention needs, trust can erode, not only in REACH VET but in the VA’s broader use of AI, and its mental health screening and treatment programs.
Planned uses of AI in the current administration are also concerning. CMS’s planned Medicare WISeR Model would test whether “enhanced technologies,” including AI, can “expedite the prior authorization processes for select items and services that have been identified as particularly vulnerable to fraud, waste, and abuse, or inappropriate use.” In practice, this could result in automated systems delaying or denying coverage for medically necessary prescriptions or treatments if a model incorrectly flags them as suspicious. The trust risk is immediate: prior authorization already feels like a barrier to care, and adding AI without appropriate guardrails or adjudication can make delays or denials seem more automated, less explainable, and more complicated to challenge, especially for older or medically complex beneficiaries. If people perceive AI as prioritizing cost control over care, it will quickly undermine confidence in Medicare and in government AI more broadly.
These two use cases show how setting parameters around federal AI governance is not an abstract compliance exercise; it directly shapes whether people experience AI as a helpful tool or as an unaccountable gatekeeper in some of the most sensitive and consequential interactions they have with the government. Federal guidance on incorporating elements like risk assessments, inventory documentation, and recourse processes into agency deployment play an outsized role in fomenting trust in government use of AI.
Attempting to meet this challenge, both the Biden and Trump administrations have issued major federal guidance on how agencies should govern their use of AI. In 2024, the Biden administration’s Office of Management and Budget released OMB Memorandum M-24-10: Advancing Governance, Innovation, and Risk Management for Agency Use of Artificial Intelligence as part of their role in establishing how federal agencies operate and implement government-wide regulations. This memorandum set forth a government-wide framework for the responsible use of AI, including requirements for risk assessments, transparency, safeguards for high-impact systems, and clear waiver processes. However, we previously found that the growing body of AI-specific guidance, layered on top of existing procurement rules such as the Federal Acquisition Regulation (FAR), can be difficult for agencies and vendors to navigate, particularly when determining at what stage in the acquisition process risk and impact assessments should occur.
Last year, the Trump Administration’s OMB superseded OMB M-24-10 with new guidance: M-25-21: Accelerating Federal Use of AI through Innovation, Governance, and Public Trust. This memo includes elements similar to the Biden administration guidance but, because of its more flexible, agency-driven model, also makes consistent implementation more challenging. The shift toward greater agency discretion could be explained by the Administration’s emphasis on accelerating AI adoption and reducing centralized compliance requirements that could slow experimentation or deployment. Agencies now shoulder greater responsibility for building their own governance and compliance structures, a task that depends heavily on available resources and technical capacity. Well-funded agencies may be positioned to meet these expectations, while smaller or resource-constrained agencies, including those whose tools have the greatest impact on low-income or marginalized communities, may struggle to develop and implement the same safeguards. The result is a growing risk of fragmented governance across the federal landscape, with uneven protections for the people most affected by AI systems.
With this context in mind, it’s worth examining how each administration has approached the challenge of governing high-risk AI, and what these differences mean for agency accountability and public trust.
From “Rights- and Safety-Impacting” to “High-Impact”: A Change in Orientation
AI Risk Thresholds
OMB Guidance M-24-10, issued under the Biden administration, established a government-wide framework for identifying and managing artificial intelligence systems that pose elevated risks to rights or safety. The memo introduced two formal designations: “rights-impacting AI” and “safety-impacting AI.” Rights-impacting systems are those whose outputs serve as a principal basis for decisions or actions with legally significant effects on individuals’ civil rights, liberties, privacy, or equitable access to services such as housing, education, credit, or employment. Safety-impacting systems are those whose decisions or actions have the potential to significantly affect human life or well-being, the environment, critical infrastructure, or national and strategic assets.
Under the Trump administration, OMB M-25-21 replaced the dual “rights-impacting” and “safety-impacting” categories with a single unified definition of “high-impact AI.” This term covers any AI system whose “output serves as a principal basis for a decision or action that has legal, material, binding, or similarly significant effects on individuals or entities.” Examples still include systems affecting civil rights, access to government programs or resources, health and safety, critical infrastructure, or other vital assets. While the framework remains centered on AI systems that serve as a principal basis for consequential decisions, the new memo consolidates the prior rights- and safety-based categories into a single, more generalized standard.
This shift is not merely semantic. The way OMB defines high-risk or high-impact AI determines which federal agencies must apply heightened safeguards, conduct impact assessments, and implement specific oversight and accountability measures. It also signals to contractors, state and local governments, and private-sector partners the types of AI use that warrant the most stringent governance practices. As discussed below, consolidating the categories may affect the scope, clarity, and structure of minimum risk-mitigation requirements across agencies.
Minimum Risk Management Practices
Reaching a designated risk threshold, whether categorized as “rights- or safety-impacting” under the Biden administration or “high-impact” under the Trump Administration, does not bar an AI system from being used in government. Instead, both administrations require agencies to meet a set of minimum risk management practices before deploying such systems. These requirements, summarized in the table below, establish the baseline safeguards for high-risk AI use.
While there are consistent practices among both guidance documents, including AI impact assessments, ongoing monitoring and evaluation, and workforce training, there are a few elements noticeably absent from the Trump administration’s M-25-21. For example, the new guidance does not have opt-out considerations, has a looser procedure for remedies of high impact systems, and does not go into as much detail on what ongoing risk monitoring should look like. Independent review in the Biden administration formalized the inclusion of the Chief AI Officer (CAIO) or another agency advisory board, while the Trump administration has more flexibility in who can review high-impact use cases.
The Trump administration also differs in including a new element: pilot projects. These pilot AI programs are exempt from full risk-management requirements if they are limited in scale and duration, approved and centrally tracked by the agency’s Chief AI Officer, allow participants to opt in or out with proper notice when possible, and still apply risk-management practices wherever practicable.
Waivers
If, for whatever reason, agencies decide to not undergo the aforementioned minimum practices, both guidance documents offer waivers that give the agency’s CAIO authority to supersede a minimum risk practice. These waivers are centrally tracked and reported to OMB.
Whereas the Biden administration portrayed this as a procedural element, M-25-21 shifts the tone and purpose of these waivers. Under this system, an agency’s CAIO, in coordination with relevant officials, can grant a waiver from one or more of the minimum practices whenever strict compliance would impede mission-critical operations or increase overall risk. The memo explicitly allows waivers when compliance might “create an unacceptable impediment” to agency objectives, a broader, more permissive standard than under Biden.
By introducing a flexible pilot program model and more permissive and vague language risk management practices, the framework places substantial discretion in the hands of agencies and their CAIOs. In practice, agencies will exercise this discretion unevenly because they vary widely in governance maturity, technical capacity, and oversight infrastructure, an issue discussed in more detail below. These disparities are compounded by differences in how CAIO roles are structured across agencies: some CAIOs are career officials with dedicated staff and technical expertise, while others serve in an acting or dual-hatted capacity, combining AI oversight with unrelated portfolios and limited institutional support. The absence of uniform qualification requirements or minimum resource standards further increases the likelihood that implementation will diverge significantly across agencies.
Agency Snapshots: A Disjointed Compliance Landscape
Federal AI governance operates at two distinct levels: (1) centralized policy direction issued by OMB, and (2) agency-level compliance processes that operationalizes those policies. While policy sets uniform expectations, compliance is implemented through agency-specific procedures shaped by capacity, mission, and internal governance maturity. The interaction between these layers determines whether federal AI governance appears coherent or fragmented.
Under Trump’s OMB Memorandum M-25-21, every federal agency is required to publish both an AI Strategy and an AI Compliance Plan outlining how it will govern its high-impact AI systems and manage its waiver processes. The majority of these plans were published in September and October 2025. The following agencies provide a useful snapshot of how different parts of the government are approaching compliance with this guidance.
It is appropriate for agencies to develop risk evaluation approaches that reflect their distinct missions and deployment contexts. Sector-specific risks vary enormously: the harms posed by clinical decision-support tools differ from those associated with benefits administration, law enforcement, or worker-protection considerations. Agencies need the flexibility to evaluate risks within their own operational contexts.
However, differences in the content of sectoral risks and differences in the processes agencies use to manage those risks are not the same thing. Allowing agencies wide latitude in interpreting minimum risk management practices and in designing their waiver procedures creates the possibility of procedural divergence, not just divergence in substantive sector-specific requirements.This is where inconsistency becomes a governance problem, not just a technical one.
Agencies have long struggled to apply their own policies consistently across programs and time. A 2023 study of Biden-era AI governance practices found that fewer than 40 percent of mandated actions under key federal AI authorities were verifiably implemented, and that nearly half of federal agencies failed to publish required AI use-case inventories despite demonstrable use of machine-learning systems. Although the Trump administration may grant more discretion in agency AI governance, we see that the ability to consistently apply guidance is a structural issue that spans administrations. Without a baseline of procedural consistency, OMB may struggle in its mission to oversee these compliance plans.
The Importance of State Capacity
When each agency is left to design its own compliance architecture, implementation will also inevitably diverge according to capacity rather than mission need. This will produce a fragmented governance landscape that closely resembles the “patchwork” often cited as a concern in broader AI regulatory debates. Some agencies have already demonstrated the ability to produce relatively robust internal guidance because they possess deeper technical benches, established governance bodies, and more mature risk assessment processes. As shown in Table 2, for example, DHS has established centralized AI governance structures, published detailed AI inventories and use-case documentation, and built out internal review mechanisms to assess high-risk systems. Similarly, the DoL has developed agency-wide AI plans and formal oversight processes that integrate risk assessment, transparency, and workforce training components. But smaller, under-resourced agencies, such as the Court Services and Offender Supervision Agency (CSOSA) references in Table 1, may struggle even to stand up the foundational processes needed to comply with M-25-21.
At the core of this capacity gap is a workforce challenge. Effective AI governance depends not only on the right guidance but also on sufficient and well-deployed talent. This includes AI talent – staff with expertise in machine learning, data science, and model evaluation, and AI-enabling talent, which includes product managers, procurement specialists, privacy and civil liberties experts, domain specialists, and program managers who can integrate understanding of technical systems into real-world decisions and operations. AI governance bodies, risk assessment frameworks, and waiver adjudication processes cannot function without personnel who understand the technology and the agency’s mission context, and who can manage and adapt agency learning and implementation systems over time. A single brilliant CAIO is a smart first step, but long term effectiveness relies on the agency’s ability to enable a “flywheel” of adaptation, growing AI and AI enabling capacity over time.
The Biden administration had an AI Talent Surge with the explicit focus on bringing in AI and AI-enabling talent into the federal government, and was able to bring at least 200 experts into public service while advising agencies on structure and capacity-building. While M-25-21 prompts agencies to develop and retain AI and AI-enabling talent, it’s unclear how that matches up with the fact that 317,000 federal workers have left the government in 2025. Because many of the Biden-era AI hires were still within their probationary period, therefore vulnerable to layoffs, and because some entire digital teams, such as GSA’s 18F and the DHS’ own AI Corps, were slashed, it is now difficult to determine where federal AI talent resides or how much of that capacity remains in government.
Recent Trump administration moves have recognized some of this gap, but the emphasis on early-career vs. institutional adaptation is limiting. Late last year, the Office of Personnel Management issued a “Building the AI Workforce of the Future” guidance document, with emphasis on the launched TechForce (hiring early-career technologists for limited terms of two years), Project Management and Data Science Fellows programs, and other early-career oriented programs.
Conclusion
The divergence between M-24-10 and M-25-21, coupled with the uneven compliance plans that have followed, reveal a federal AI governance landscape marked by structural fragmentation, one that carries real implications for public trust. Agencies with robust technical resources are positioned to comply with these requirements if they choose to, while others will struggle to keep pace. Compounding this disparity, the dissolution of digital teams and loss of probationary AI hires have obscured the government’s understanding of its AI workforce, weakening its capacity to implement trusted and transparent governance.
Ultimately, M-25-21’s compliance plans will not fulfill their intended purpose unless agencies receive the funding, staffing, and political support required to carry them out. A compliance plan is only as strong as the people and resources behind it. Robust, transparent governance is impossible without investments in the civil service capacity needed to implement it, and without such trust-building capacity, agencies risk forgoing the responsible adoption of AI systems that could improve public services and operational effectiveness.
A pre-mortem on OPM’s HR 2.0 initiative: Imagining failure in order to support success
[Editor’s note: full examination here (pdf)]
Large-scale IT modernization projects fail with remarkable regularity. They fail in private companies with strong profit incentives and unified leadership. They fail in state and local governments with narrower missions and simpler constraints. And they fail — often spectacularly — in the federal government. Entire multibillion‑dollar industries exist precisely because implementing large, complex software, including Enterprise Resource Planning (ERP) systems, is hard: technically complex, organizationally disruptive, politically fraught, and culturally destabilizing.
OPM’s new HR 2.0 initiative is therefore entering hostile terrain by default. The initiative aspires to rationalize, consolidate, and modernize a sprawling thicket of federal human resources systems that has grown organically over half a century. It seeks to replace dozens of agency‑specific solutions, hundreds of interfaces, and innumerable manual workarounds with a standardized, interoperable, enterprise‑wide platform capable of supporting modern workforce management.
Those of us who have followed federal HR modernization for years desperately want this effort to succeed. The current HR IT landscape is costly, brittle, opaque, insecure, and increasingly misaligned with how the federal government needs to recruit, manage, pay, and deploy its workforce. As OPM has documented and independent research shows, the federal government likely wastes billions of dollars maintaining hundreds of systems that slow agencies down, force them to duplicate effort, and obfuscate rather than clarify the data required to make business and workforce decisions. Some of these systems are decades old and have been assessed as a high risk to government operations if they should fail. Modernization is no longer optional. It is a prerequisite for addressing mission delivery, workforce planning, and public trust.
But optimism is not a plan, and aspiration is not execution. In our experience, the greatest danger to large federal IT programs is not a lack of good intentions, but rather a failure to fully internalize how hard it is to succeed and avoid the missteps of the past. In that spirit, this paper adopts an intentionally uncomfortable posture: It is a pre‑mortem. Rather than waiting until a future GAO report, Inspector General audit, or congressional hearing explains why this effort underperformed, we imagine that possible failure mode now.
We assume — purely for analytical purposes — that OPM’s HR 2.0 initiative did not achieve its intended outcomes. From that hypothetical vantage, we ask:
- What were the most likely failure modes that doomed the effort?
- What could OPM, OMB, Congress, and agencies have done earlier to materially reduce those risks?
- What questions should OMB and OPM leadership be asking today to avoid that outcome?
OPM, agencies, and OMB have already invested substantial time and energy in planning this effort. This paper is intended to complement — not undermine — that work by surfacing structural vulnerabilities early, when they can still be addressed. This, in turn, can help guide implementation teams’ focus today under the presumption that success, with care and forethought, is possible despite all the barriers.
HR 2.0 is a good idea, but it has risks
At its core, OPM’s initiative is a good one and addresses an often-neglected part of the federal business enterprise that has long needed attention from senior leadership. It is also perhaps the most ambitious attempt ever made to solve this problem once and for all. In fact, OPM has made a series of choices related to how it has structured the program — decisions that demonstrate the administration’s seriousness and commitment, and we mostly agree with the impulse and meaning behind each of them:
- Single award – Currently, several different vendors service the federal government, including Oracle, SAP, and Workday. This creates interoperability and data standards challenges, as upgrades need to be made in each proprietary code-base when policies or directions change. OPM’s approach in HR 2.0 solves this by mandating a move to one, single software company, which can tightly integrate the entire federal enterprise into a standard solution that is easier and cheaper to maintain.
- Direct contracting with software OEM – Historically, when agencies moved to new systems, they contracted with a large system integrator (SI) that served as something of a middleman between the agency and the company that actually built the software. These SIs served as translators between the two groups: business requirements from agency to vendor, technical specifications from vendor to agency. However, this creates additional cost and management complexity as the agency relies on a third party to act in its interests. OPM’s approach in HR 2.0 solves this by establishing a direct contracting relationship between OPM and the eventual software vendor so that OPM can control vendor behavior and changes to the underlying single code-base.
- Recoup costs from agencies – There are a variety of models for funding mandatory government-wide services, including both specific appropriations and also pooling funds from agencies to a central account. For HR 2.0, OPM appears to be electing the latter, which gives agencies “skin in the game” and ownership of the resulting solution: They’re paying for it, so they are true customers rather than simply takers of OPM’s direction.
- Explicit direction to agencies – There are various ways to drive adoption of single solutions. OPM and OMB have elected to pursue a top-down, mandatory, whole-of-government approach that establishes a schedule and mandates adoption. This solves many common collective-action problems across government: No agency wants to go first and everyone would prefer to push the timeline out as far as possible.
However, we also know how hard this is going to be, both because of our own experience working on this topic inside the federal government ,and because the government has failed at this exact exercise before. In fact, it has already failed at this project this decade.
Learning from DoD’s failure
In March of 2025, Secretary of Defense Pete Hegseth released a memo and then a video highlighting an effort to cut wasteful spending and putting several programs on hold. The first program on his list was the Defense Civilian Human Resources Management System, or DCHRMS (pronounced dee-charms in classic defense bureaucracy style).
The program had been “intended to streamline a significant portion of the Department’s legacy Human Resources (HR) information technology stack – an important mission we still need to achieve – but further investment in the DCHRMS project would be throwing more good taxpayer money after bad.” In his telling, the program was “780 percent over budget. We’re not doing that anymore.” It was over — the DoD had tried and spectacularly failed to move to a single HR system for just its own department. This high-profile bust is exactly what we mean when we say this type of HR IT modernization is hard and fails all the time.
The project originally started in 2018 as a $36 million, one-year proof of concept and then morphed into a years-long effort to consolidate at least six separate DoD systems based on Oracle’s E-Business Suite software onto a single, DoD-wide Oracle Cloud HCM platform. The project moved from proof of concept into full execution without a formal acquisition or rigorous planning, leaving the systems integrator that managed the legacy systems also in charge of implementing the new system. The department tried mightily to standardize business processes across DoD services. But people familiar with the project say that middle managers and subject-matter experts across the department added requirements that led to scope creep as the project wore on. As the project timeline began slipping, Oracle introduced new technologies and features that led to further slippage to incorporate them into the program baseline. By the time the program was cancelled, it was not clear what DoD’s measures of success were. That the integrator responsible for deploying the new system was simultaneously profiting from operating the legacy systems also presented an obvious conflict of interest.
The DCHRMS saga maps several pitfalls associated with large-scale enterprise IT modernization programs. The failure to maintain a rigorous convergence baseline and guard against scope creep is one. That seems to have been compounded by a business model and accountability structure that were not well thought through or did not adhere to best practices. And ultimately, by the time it became clear that the program was unable to deliver concrete, measurable outcomes in a reasonable and well-defined timeframe, the state of technology had evolved, rendering the program’s initial targets irrelevant and forcing the program to rebaseline.
These reasons for failure are not unique to DCHRMS, nor are they unforeseeable. In fact, they are some of the most common failure modes that doom complicated, multi\stakeholder technology implementations in complex organizations. Not even the DoD’s generally deferential-to-leadership and can-do culture could overcome them.
Predicting failure modes and mitigating the risks
For OMB and OPM to avoid this fate for HR 2.0, they need to consider the possibility of failure and take the risks of their approach head on. DCHRMS was a good idea, too, but good ideas only get you out of the gate and not over the finish line.
Based on our experience, we’ve imagine what the failure modes might be; suggest mitigations; and, crucially, articulate the questions leaders should be asking today to try to avoid failure in the future.
Failure mode 1: The single-award strategy backfires, or Industry doth protest too much
Scenario: In early 2026, GSA awarded the government-wide contract to implement HR 2.0 to a single vendor after a competitive evaluation,but the project quickly went the way of JEDI. Within weeks, two unsuccessful offerors — gigantic tech companies with deep pockets and nothing to lose — filed protests with GAO, arguing that the evaluation criteria unfairly favored the awardee’s architecture and that OPM had failed to adequately consider total cost of ownership. GAO sustained one protest on narrow technical grounds, requiring a reevaluation. That process took months, during which a third vendor protested, alleging the revised criteria were designed to reverse-engineer the original outcome. By the time the litigation resolved in late 2027, OPM had lost its original program leadership, the vendor’s proposed technical team had largely dispersed to other projects, and three agencies that had been preparing for early implementation had redirected their modernization budgets elsewhere.
The single-award approach isn’t inherently flawed, but it demands unusual discipline in execution and presents significant risks. OPM and GSA must assume protests are coming and prepare accordingly, both legally and programmatically. Their goal should be twofold: make protests less likely to succeed on their merits, and structure the program so that even a sustained protest doesn’t collapse momentum entirely. Here’s how:
- Build legitimacy through transparency. Proactively explain the award decision to appropriators, GAO, industry associations, and agency stakeholders. When policymakers and others understand and accept the rationale, vendors have less political cover for delay tactics. This will set the stage for effective vendor debriefs as well.
- Build innovation incentives directly into task orders. Normally, the federal government drives innovation in its vendor base through competition: Companies compete to offer the mix of capabilities relative to price and are incentivized to lower their work margins. In a single-award model, OPM loses some of this competitive pressure to innovate. As a result, rather than assuming innovation will emerge organically as a result of market forces, OPM should explicitly reward it. This could include incentive fees tied to measurable improvements in usability, automation, or data quality, as well as structured mechanisms for piloting and scaling new capabilities.
- Protect exit options. Require data portability in nonproprietary formats and government ownership of custom code. Real exit options, even if unlikely to be exercised, weaken the “lock-in/lock-out” narrative that makes protests attractive.
- Maintain the ecosystem. A curated marketplace for ancillary solutions (i.e., microsolutions outside the scope of the current contract) keeps competitive pressure alive and gives losing vendors a reason to stay engaged with the federal government rather than litigate over the loss of their entire market share.
Key questions for OPM and OMB leadership to ask: What is our realistic timeline and budget for protest and litigation? And have we structured the program so that a significant delay won’t collapse momentum entirely?
Failure mode 2: An OPM-led, OPM-managed effort becomes a bottleneck or Herding Cats Is too Hard
Scenario: By mid-2027, the program had a governance problem that no one wanted to name. OPM had established an impressive array of boards, councils, and working groups, but decisions that should have taken days were taking months. Agency requests for configuration changes sat in queues. Escalation paths were unclear. When disputes reached senior leadership, they often got sent back for “more analysis.” Agencies, meanwhile, learned that the fastest path to resolution was to route around OPM entirely: calling OMB, complaining to appropriators, or simply delaying participation until someone else went first.
Centralizing authority at OPM makes sense in theory: It’s the government’s HR agency, and fragmented leadership doomed earlier efforts. But centralization only works if OPM has the capacity to actually lead, and if governance structures enable decisions rather than defer them when agencies push back — and they will push back. This requires deliberate investment in both institutional capability and stakeholder engagement:
- Build capacity before you need it. OPM will need staff profiles it hasn’t historically employed at scale: senior IT program executives, enterprise architects, contracting specialists, and financial managers. Borrowing talent through detailees can help initially, but durable capability requires permanent investment and new types of positions.
- Design governance for speed. Establish clear decision rights, escalation paths, and timelines at every tier. Linked governance bodies must cover the full range of strategy, policy, contracting, operations, stakeholder engagement, and performance. They should have authority to resolve issues, not just discuss them. When decisions are kicked up the ladder, there should be a deadline for resolution.
- Develop model interagency agreements (IAAs). Standardized IAAs with explicit service levels, cost allocation, and dispute resolution will reduce the transaction costs that otherwise consume leadership attention.
- Make agencies partners, not passengers. Leverage the Chief Human Capital Officers (CHCO) Council not only as a communication channel, but also as a genuine forum for surfacing concerns and shaping implementation. Agencies need to see that their expertise matters, even when their preferred approaches don’t prevail.
- Treat HR 2.0 as a product, not as a project. HR 2.0’s success relies not simply on the implementation of a new IT system, but on the ongoing evolution of the features and functionalities that will enable the system to respond to and meet the needs of agency users. The private sector, and increasingly parts of the government, have adopted a “product operation model” to manage around these constraints. OPM should leverage the considerable experience its HR Solutions organization has with this model and mindset to adopt many of these management principles for HR 2.0.
Key questions for OPM and OMB leadership to ask: Does OPM have — or can it rapidly build — the programmatic capacity to manage a government-wide implementation? Or will it need to partner more deeply with other organizations to fill critical gaps?
Failure mode 3: Contracting directly with OEMs goes awry, or Integrators were integral after all
Scenario: The idea was novel: contract directly with the software company, make it accountable for delivery, and relegate the big integrators to supporting roles. However, what no one fully appreciated was that the OEM had never run a federal program at this scale. Its government practice was built around licensing, not implementation. When agencies reached out to them directly, staff struggled to handle their dual role as client navigator and enforcer of standards. Meanwhile, the integrator subcontractors had little incentive to go beyond its narrowly defined task orders; It had learned from experience that exceeding scope meant absorbing risk. By 2028, the program had developed a peculiar dysfunction: The OEM nominally owned delivery but lacked the expertise to drive it, while the integrators who had the expertise lacked the authority or incentive to deploy it. Problems that should have been resolved at the working level instead became triangular disputes among OPM, the OEM, and whichever integrator happened to be nearby when something broke.
Contracting directly with the OEM aligns authority with product knowledge, a real advantage when implementation challenges stem from product limitations. But OEMs are product companies, not delivery organizations. Making this model work requires treating the OEM relationship as a partnership to be developed, not a vendor to be managed, and designing governance structures that compensate for predictable gaps. Here’s how:
- Conduct rigorous OEM due diligence. Go beyond product maturity to assess delivery capacity, federal acquisition experience, subcontractor management capability, and organizational culture. How does the OEM handle failure? How does it resolve disputes? What’s its approach to managing agency customers?
- Design governance as a “team of teams.” The OEM should orchestrate, not micromanage. Agencies and their integrator partners need clear roles and enough autonomy to solve problems without constant escalation. Decision rights should be explicit and documented.
- Stress-test capacity assumptions. OEMs may underestimate what federal implementation requires: cleared staff, program management depth, constant stakeholder engagement. Validate their staffing plans and scaling assumptions before award, during early execution, and down the stretch to avoid foreseeable issues.
- Anticipate finger-pointing and design around it. Establish clear responsibility matrices distinguishing product issues from configuration or data issues. Create joint risk registers and escalation paths that prioritize resolution over blame.
- Maintain a curated marketplace for extensions. Even the best core system won’t cover everything. OPM and the OEM should jointly certify integrator-built solutions to ensure they align with enterprise standards without stifling innovation.
Key Questions for OPM and OMB leadership to ask: Has the OEM ever successfully delivered a program of comparable scale and complexity? And if not, what governance structures will compensate for that inexperience?
Failure Mode 4: Configuration management becomes unmanageable, or The Christmas tree collapses under its own weight”
Scenario: No one could point to the moment the baseline stopped being a baseline. It happened gradually, one exception at a time. An agency with a unique pay authority needed a configuration variant; that was legitimate. Another agency’s union agreement required a different leave-tracking workflow; that was unavoidable. A third agency wanted to preserve a legacy-report format that its budget office depended on; that was easier to accommodate than to fight. By 2028, the “standard” system had 17 major configuration branches, 42 approved extensions, and an uncounted number of agency-specific workflows that had been implemented as “temporary” accommodations. The vendor’s upgrade cycle, originally planned for quarterly releases, slipped to annual. Even then, each upgrade required months of regression testing across configuration variants to ensure that push of new commercial code didn’t break these customizations. The government had succeeded in replacing dozens of legacy systems with a single modern platform. Unfortunately, it also had recreated the fragmentation that modernization was supposed to eliminate.
Configuration pressure is inevitable. Federal HR is governed by multiple statutory regimes, and agencies will always have legitimate reasons for divergence. Some amount of tailoring is inevitable, but the major goal OPM should consider is how it might govern the solution so that exceptions remain exceptions rather than becoming the new normal. This requires treating configuration management as a strategic discipline, not an administrative afterthought. Here’s how:
- Define the baseline clearly and defend it. Establish explicit standard processes and hold agencies to them unless divergence is legally required. “We’ve always done it this way” is not a sufficient justification.
- Create a hierarchy of tailoring options. Not all customization is equal. Advanced configuration within the product is preferable to extensions; extensions are preferable to bolt-on integrations; core product modifications should be rare and require executive approval.
- Sequence for simplicity. Start implementation with smaller, less complex agencies to establish guardrails before tackling organizations with intricate labor agreements and statutory exceptions.
- Use funding as a governance lever. Agencies should pay for tailoring beyond the baseline but only after accepting and implementing the standard. This creates natural friction against unnecessary divergence.
- Make configuration decisions transparent. Publish what’s been approved, what’s been denied, and why. Transparency counters the belief, widespread in government, that “everything we do is special.”
- Align with civil service reform. Configuration complexity is downstream of policy complexity. OPM and OMB should work with Congress to explain how statutory exceptions drive cost and discourage future proliferation.
Key Questions for OPM and OMB leadership to ask: Who has the authority to say “no” to an agency’s configuration request> And will those with that authority get backup when politically powerful agencies push back?
Failure mode 5: Funding is insufficient, unreliable, or unsustainable, or The passed hat drops
Scenario: The funding model mapped to a usual format for government: Agencies would pay for their participation, OPM would recover costs through its revolving fund, and the program would be self-sustaining once it reached scale. What the model hadn’t accounted for was the messy reality of federal budgeting. Three agencies requested implementation funding in their FY 2027 submissions; two were denied by their appropriations subcommittees, who saw HR modernization as discretionary against more pressing mission needs. A fourth agency had funds but couldn’t obligate them in time because its IAA with OPM was still being negotiated. By 2028, the program’s wave schedule had been revised four times, each revision eroding vendor confidence that the government was serious. The OEM, facing uncertain volume, quietly raised its per-agency pricing to hedge against lower-than-expected adoption. Agencies that had been on the fence used the chaos as justification to wait. OPM found itself in the worst of all positions: accountable for a government-wide program but dependent on agencies it couldn’t compel and appropriators it couldn’t control.
In the federal government, budgets are political documents as much as they are management ones. The way money flows determines who has authority, who bears risk, and who ultimately decides what gets built. A distributed funding model may be administratively orthodox, but it diffuses accountability in ways that are toxic to enterprise modernization. OPM and OMB should treat the funding architecture as a strategic design decision, not an inherited constraint. Here’s how:
- Seek direct appropriations for implementation. Congress should appropriate funds to OPM specifically for the implementation phase, with a defined transition to a revolving fund model for operations and maintenance. This gives OPM real authority to enforce configuration discipline and control sequencing without having to beg, borrow and steal from across government.
- Partner early with OMB and appropriators. Don’t wait for the budget cycle to explain why traditional funding models are ill-suited to enterprise transformation. Build the case now for why centralized implementation funding produces better outcomes at lower long-term cost, and take advantage of the opportunity to explain how viewing this initiative through a product management lens implies the need for a different funding strategy.
- Impose transparency on revolving fund operations. If agencies will eventually pay through the revolving fund, they need clear visibility into what they’re paying for. Publish cost drivers, configuration decisions, and tradeoff rationales.
- Plan for multi-year commitment. Seek multi-year appropriations where feasible. They reduce annual renegotiation risk and signal to vendors, agencies, and oversight bodies that the government is serious.
- Use funding to enforce sequencing. Agencies that want to delay should understand that funding availability may not wait for them. Early participation should carry advantages; late entry should carry costs.
Key Questions for OPM and OMB leadership to ask: Can this program realistically achieve its objectives through distributed agency funding? Or does success require a level of centralized financial authority that OPM does not currently have, at least at the implementation phase?
Failure Mode 6: Agencies are not ready when their turn comes, or Agencies miss their marks
Scenario: OPM and the OEM did their parts. The contract was awarded, governance was established, and the wave schedule was published 18 months in advance. What no one had fully reckoned with was the state of agency readiness. The first wave included 4agencies, chosen for their manageable size and expressed enthusiasm. Two were genuinely prepared: Their data was clean, processes were documented, and change management was underway. The other two had overestimated their readiness. One discovered during configuration that its position data existed in three different systems that had never been reconciled; cleaning it would take nine months. The other had documented its “as-is” processes, but those documents described how the agency thought things worked rather than how they actually worked, a gap that surfaced only when end users began testing. OPM faced an uncomfortable choice: delay the wave, which would ripple across the entire schedule; lower quality standards, which would embed problems into the baseline; or push forward and absorb the pain.
Agency readiness isn’t just an agency problem, it is also a program problem. OPM can execute flawlessly on procurement, governance, and vendor management and still fail if agencies aren’t prepared when their turn comes. That means readiness requirements need to be specific, measurable, and consequential. Agencies have incentives to obfuscate their readiness until it’s too late if they don’t think you’re serious or don’t understand what you’re asking them to do. OPM needs a clear escalation path if agencies miss their marks. Here’s how:
- Define clear readiness thresholds. Agencies need specific targets—data quality metrics, process documentation standards, and change management milestones—not general encouragement to “prepare.” These thresholds should be published early and tied explicitly to wave eligibility.
- Assess readiness independently. Self-reported readiness is unreliable. OPM should establish assessment mechanisms—whether internal or third-party—to validate agency preparation before committing to implementation dates.
- Make sequencing flexible. Wave schedules should be benchmarked against readiness, with the explicit expectation that agencies can be swapped based on objective criteria. Agencies that are ready should move forward; agencies that aren’t should wait.
- Provide resources for preparation. Readiness work requires investment—staff time, contractor support, leadership attention. OPM should issue detailed preparation guidance immediately upon award and establish contract vehicles for data cleanup, process reengineering, and change management.
- Incentivize early engagement. Agencies with complex needs should be encouraged to participate in early planning, even if they won’t implement in early waves. Early involvement confers influence and builds the expertise that makes later implementation smoother.
Key questions for leadership: How will OPM distinguish among agencies that are genuinely ready and those that merely believe they are? And what happens when an agency in the latter category is scheduled for an early wave?
Failure mode 7: Executive sponsorship wanes over time, or Government takes its eye off the ball
Scenario: For the first two years of the term, the program had everything it needed: White House attention, OMB backing, an OPM Director with the right skills who made modernization a personal priority, and agency heads who understood they were expected to participate. Then, as happens in nearly every term, political appointees began to turn over. New appointees came in after the midterms with different priorities. The career staff who understood the program’s history remained, but their authority to make decisions — and their air cover when those decisions were contested — evaporated. Agency executives who had reluctantly committed to early waves found that their objections now received a more sympathetic hearing. By 2028, the program still existed: contracts were in place, some agencies had implemented, governance bodies still met. But the urgency was gone. Wave schedules slipped. The program had become one of many initiatives rather than the initiative. It would eventually deliver something — but not the enterprise transformation that had been promised.
Executive attention is a wasting asset. It cannot be sustained indefinitely through personal commitment alone: Eventually, leaders move on, priorities shift, and attention migrates to newer challenges. The only way to protect a multi-year, multiadministration program is to convert early momentum into durable structures that don’t depend on any single leader’s continued engagement, and embed support for this program in the career staff who will need to sustain it across agencies far into the future.
- Codify governance beyond individuals. Decision rights, escalation paths, and performance standards should be documented and institutionalized, not dependent on personal relationships or informal understandings.
- Build a permanent career backbone. Political leadership is transient; career leadership is not. Invest in a cadre of SES leaders at OPM and participating agencies who understand the program’s full arc and are empowered to sustain it across transitions.
- Secure bipartisan congressional support. Frame the initiative as state-capacity investment, not an administration priority. Active engagement with authorizers and appropriators across parties is essential; without it, the program becomes vulnerable to being labeled discretionary or ideological.
- Lock in early wins. Move quickly to establish durable artifacts — contracts, standards, migrated agencies — that create facts on the ground. Reversal becomes harder when real implementation has occurred.
- Practice radical transparency. Publish progress, setbacks, costs, and tradeoffs. Transparency builds the credibility that sustains support across leadership transitions and reduces the risk that future leaders view the program as a black box inherited from predecessors.
Key question for OPM and OMB leadership to ask: What specific structures, commitments, and artifacts can be put in place in the next 18 months that would make it difficult for a future administration to abandon or significantly scale back this initiative?
OPM needs to manage the risk without paralyzing the program
All of these failure modes are, in our view, plausible but they are not inevitable. The fact that they’re extremely foreseeable makes them easier to plan around.
The good news is that the risks facing this initiative are not primarily technical. Whomever OPM selects as the vendor will likely be able to deliver some kind of working product. Rather, the risks are mostly governance risks, capacity risks, and incentive-alignment risks. The bad news is that these risks are harder to mitigate, and addressing them requires more than better requirements or more detailed project plans. It requires a conscious effort to design institutions, funding flows, and oversight mechanisms that help the program succeed rather than simply document its shortcomings.
With this in mind, there are some things that OPM and OMB can do to get a better hold on them. In particular, there are programmatic opportunities to rethink the use of independent verification and validation (IV&V) and the role of other actors in the federal ecosystem, such as Congress, GAO, and OMB, who often play their roles as overseers, authorizers, and advisers in the process of transformation. There are also obvious lessons from private sector product management experience that can help reduce the risk of a catastrophic meltdown posed by large-scale waterfall implementations.
Traditional IV&V models often emphasize exhaustive risk identification, which may be appropriate for discrete, bounded systems. However, for a multi-year, enterprise-scale transformation operating in a high-risk environment, a more useful IV&V strategy would be selective, staged, and decision oriented. Rather than attempting to monitor everything at once, IV&V should focus on a small number of high-leverage risk domains aligned with the failure modes identified in this paper, such as configuration governance and convergence discipline, funding adequacy and sustainability, agency readiness and sequencing decisions, and executive sponsorship and institutionalization. Within these domains, IV&V should aim not merely to assess compliance, but to inform real decisions: whether to pause, resequence, simplify, or escalate. Stage gating the implementation based on these factors (rather than just cost, schedule, and performance) can help OPM and OMB course correct when they need to rather than barrel ahead until it is too late.
In conjunction with this, OPM should lean into its relationship with stakeholders such as Congress and GAO. Agencies and program managers often avoid interacting with these officers because such interactions seem to invite scrutiny and criticism. But this program, with its size and ambition, will not avoid scrutiny along the way. And engaging these powerful actors earnestly up front offers OPM the best chance it will have to enlist them as allies and secure longer-term sponsorship for this important effort.
Finally, OPM should consider adopting a product operating model for HR 2.0 rather than managing it as a traditional, time-boxed “waterfall” IT project. As our colleagues have previously argued, the product operating model directly counteracts several of the failure modes identified in this paper. Replacing rigid milestone-based delivery with iterative development cycles reduces the risk of configuration complexity spiraling out of control, because problems surface early and can be corrected before they calcify into permanent accommodations. Embedding dedicated technical product managers within the program and empowering them to resolve ambiguity, manage scope, and make tradeoff decisions addresses the governance bottleneck risk by ensuring that day-to-day decisions don’t require constant escalation to senior leadership. Continuous, outcome-based funding aligned to a product model mitigates the funding fragility by shifting the budgetary conversation from one-time project appropriations to sustained investment in a living service. And because the product model emphasizes organizational alignment with outcomes rather than obstacles, it helps insulate the program against the loss of executive sponsorship: durable team structures, institutionalized feedback loops, and transparent progress metrics create continuity that persists even as political leadership turns over.
In short, the product operating model is an institutional design that would reduce the probability of several of the most dangerous failure scenarios HR 2.0 faces, and in doing so, increase the probability of historic success.
A Final Observation
Federal HR IT modernization is ambitious because it must be. The federal government is one of the largest single employers in the world and it runs on badly outdated and outclassed HR software. The status quo is unsustainable. Fragmentation, duplication, and opacity carry their own costs and risks. The choice, then, is not between risk and safety. It is between managed risk and unmanaged risk. The failure modes outlined in this paper are not predictions — they don’t have to come true — but they are warnings. Each represents a point at which deliberate choices can either compound fragility or build resilience.
The success of this initiative will depend less on technical execution than on leaders willing to confront these choices honestly, early, and repeatedly. That, more than any single procurement or platform decision, will determine whether HR 2.0 becomes a foundation for reform — or another cautionary tale about a federal IT meltdown…
For a more detailed examination of these ideas, please download the full report (pdf) here.
Appendix: A brief history of HR IT modernization and consolidation in the federal government
Early agency‑built HR systems
Federal agencies, like their private sector counterparts, began building enterprise HR and payroll systems in the 1970s. These systems were typically bespoke, homegrown solutions designed to meet the specific needs of individual agencies. They were written in what was then state-of-the-art programming languages such as COBOL and Natural, languages that are now considered archaic, despite the fact that they continue to underpin mission‑critical systems in the banking industry and across government.
At the time, this approach made sense. Commercial HR software barely existed, and the federal government was already one of the largest employers in the world. Computing helped agencies manage complex, routine tasks like payroll and therefore were highly customized. There was little expectation that systems would interoperate across agencies, as the internet did not yet exist in its modern form. Each organization optimized for its own statutory authorities, workforce composition, and operational needs.
Over time, however, these systems accreted complexity. New laws, pay plans, labor agreements, and reporting requirements were layered on top of old code. Documentation decayed. Original developers retired and left little in the way of documentation about what they did. Institutional knowledge became increasingly fragile. What remained were systems that worked — until they didn’t — and that were extraordinarily difficult to modify, integrate, or retire.
The commercial ERP wave
In the 1990s, commercial ERP systems, led by vendors such as SAP and PeopleSoft, rose to prominence in the private sector. Initially focused on manufacturing and finance, these platforms gradually expanded to include HR, payroll, and talent management functionality for almost all large enterprises.
By the late 1990s, federal agencies began adopting commercial HR systems, overwhelmingly selecting PeopleSoft. These implementations promised modernization, vendor support, and alignment with private‑sector best practices. In practice, agencies often customized these systems extensively to replicate legacy processes and accommodate federal‑ and agency-specific requirements inherent in the custom solutions they replaced. While modernization occurred, standardization largely did not.
Payroll consolidation: A rare success
By the early 2000s, the federal government operated more than 20 mostly bespoke payroll systems, each of which did the same basic thing: calculate payroll and send instructions to the Department of the Treasury to process. This level of duplication was expensive and untenable, leading the Bush administration to adopt payroll consolidation as a pillar of its newly minted “e‑Government” agenda and the newly established HR Line of Business.
This effort is notable for both its sponsorship and its execution. The initiative was driven directly by OMB Director Mitch Daniels, with strong leadership from OPM Director Kay Coles James. OPM conducted a formal internal competition among federal payroll providers, resulting in the designation of four agencies — the General Services Administration, the Defense Finance and Acquisition Service (DFAS), the Department of Agriculture’s National Finance Center, and the Department of the Interior’s National (now Interior) Business Center — as payroll shared service providers, responsible for processing not only their own agency’s payroll but also that of several customer agencies. The Department of Agriculture, for example, processes payroll for the Departments of Homeland Security and Justice, while DFAS processes payroll for the Veterans Administration and the Department of Energy, among other arrangements.
Despite early skepticism and schedule slippage, payroll consolidation succeeded for the most part. By 2006–2007, most civilian agencies had migrated payroll operations to one of these providers. OPM later estimated that the effort produced roughly $1 billion in savings and cost avoidance, with continued benefits accruing over time, including better standardization and control over the data supply chain from agency systems to OPM.
Crucially, this payroll consolidation was not explicitly authorized by statute or executive order. It succeeded because senior leaders treated it as a management imperative, and they enforced compliance and sustained attention long enough to overcome institutional resistance.
The long plateau: 2007–2024
After payroll consolidation, OMB sought to extend the shared services model to broader HR functionality. Beginning in 2007, OMB issued a series of memoranda requiring agencies to migrate to approved HR shared service centers when modernizing. This policy trajectory culminated in OMB Memorandum M‑19‑16, which established Quality Service Management Offices for HR, financial management, grants management, and cybersecurity.
Despite these directives, progress was uneven. Some agencies modernized successfully; many did not. Fragmentation persisted. A defining feature of this period was the absence of sustained, senior‑level executive sponsorship comparable to that seen during payroll consolidation. HR IT modernization became a perennial priority — but rarely the top priority.
Everything You Need to Know (and Ask!) About OPM’s New Schedule Policy/Career Role: Oversight Resource for OPM’s Schedule Policy/Career Rule
In February 2026, the Office of Personnel Management finalized a rule creating Schedule Policy/Career, a new category for certain career federal positions they deem as “policy-influencing.”
When the rule was initially proposed, FAS raised concerns that removing civil servant employment protections could place unnecessary and undesirable political pressure on highly specialized scientific and technical career professionals serving in government. While we appreciate the Administration’s revisions (such as those that clarify competitive service status), important questions remain about how the rule will be implemented in practice, and how it may affect agency operations, workforce motivation, and mission delivery. This is a complex change to a long-standing system, with significant implications for thousands of current and future public servants – with great potential for unintended consequences. Congress has both a responsibility and opportunity to understand the rule’s intent, implementation, and impacts as it works constructively to shape a better federal workforce system that meets the needs of the country.
This resource is designed to help Congressional members and staff (and other oversight bodies) with cross-cutting and agency oversight roles understand what implementation could look like, where discretion lives in implementation, what changes or risks may emerge over time, and what questions may be most useful to ask in oversight activities such as hearings, briefings, letters, commissioned reports, and GAO audits. Potential areas to watch and requests are aimed at specific implementation periods, as part ongoing engagement with individual agencies, or as part of more holistic review, with the goal of supporting practical, evidence-based oversight as agencies put the rule into effect.
Background
Under the rule, Schedule P/C positions remain career, merit-based roles, but employees in Schedule P/C roles:
- Move from the competitive service to the excepted service, with no appeal for such transfers
- Lose Chapter 43 (performance) and Chapter 75 (adverse action) due process protections under Title 5
- No longer have MSPB appeal rights
- Become effectively at-will for purposes of removal
- Retain protections from prohibited personnel practices (PPP) enforced internally instead of the U.S. Office of Special Counsel (OSC)
Importantly, career staff who had competitive status can transfer to a non-Schedule P/C role and regain competitive service protections. Staff who are hired into Schedule P/C roles under the merit system can likewise gain competitive status after 2 years and acquire competitive service protections if they move out of Schedule P/C.
This rule gives agencies significantly more authority over certain career policy roles. Whether that authority improves accountability or creates new risks depends almost entirely on how agencies interrupt and apply it.
If you’re interested in….
What the rule actually changes (and what it doesn’t)
Understand
- Schedule P/C are not political appointees. Under the new regulation, schedule P/C roles are policy influencing roles hired through merit processes and who retain their roles across administrations, vs. political appointments, which are selected through the White House and whose tenure ends when a president leaves office.
- The rule primarily changes protections and removal authority for staff moved to Schedule P/C, not hiring – though overseers should stay aware of hiring practices for these roles.
- Schedule P/C roles remain career, merit-filled positions and P/C employees have or can attain competitive service status (but this is worth continued engagement on)
- However, while in P/C roles, employees lose Ch. 43/75 process due process protections and MSPB appeal rights.
Ask agencies (now)
- How are you explaining this change to managers and staff?
- By what criteria will you decide what agency positions are determined to be “policy influencing” for approval by OPM?
- What written guidance have supervisors received?
Watch
- Confusion in agencies about what this is
- Implementers with different interpretations on breadth of the definitions
- Differential discussion of or treatment of Schedule P/C roles beyond this rulemaking
Why it matters: Early confusion or inconsistency may lead to uneven or overbroad designation of roles, uneven treatment across agencies, or morale challenges due to confusion about goals.
What is policy influencing (and what isn’t)
Understand: Agencies are supposed to identify roles based on whether the duties of the position meet the statutory test for being policy influencing – the role, not the person. Agencies are told to consider: roles that:
- Shape, write, or interpret regulations or policy
- Advise senior leaders on policy choices
- Translate presidential or agency priorities into action
- Direct the work of people doing the above
- Sit in policy offices, regulatory offices, or leadership advisory roles
- Have authority to influence how laws and directives are carried out
Agencies should not be considering:
- Performance
- Seniority
- Political beliefs
- Individual behavior
Ask (after agencies have made determinations):
- What criteria did you use to determine a role was policy-influencing?
- Did you conduct a role-by-role analysis? Are there instances where you designated whole offices?
- Which occupational series and functions were included? Were scientists, attorneys, grants officials, or program managers included?
- How did you treat supervisory roles?
- What written justification exists for each position?
Watch:
- Expansion or changing of definitions over time beyond the initial intent
- Use of office-wide or team-wide designations rather than position-specific analysis
- Application of the definition to roles that are primarily technical, scientific, legal, or delivery-oriented rather than policy-shaping
- Variation in interpretation across components or agencies
Why it matters: Good oversight here is about definitions and consistency.
How positions get put on the schedule
Understand: Agencies identify the roles, OPM vets the justification, and the President makes the final decision to place the positions into Schedule Policy/Career.
Ask (after agencies have made designations)
- What process did agencies use to identify positions? Are all such positions designated Schedule P/C?
- Who approved each designation at agencies?
- What documentation supports each decision at agencies?
- How are employees and job applicants notified about placement into Schedule P/C?
- How is OPM ensuring consistency between agencies?
- Given the volume of positions reviewed, what process exists to revisit or correct designations if needed?
Ask (on a rolling basis, or in a GAO review 1 year after implementation)
- How many positions were added after the initial designation?
- What justifications were used later, and did they change in scope?
- Whether the definition of “policy-influencing” is changing?
Watch
- Whether processes remain consistent and well-documented over time
- Patterns of employee questions or concerns about how decisions were made
Why it matters: Much of the practical discretion in this rule rests in how agencies conduct and document this step. Understanding this process is key to meaningful oversight.
What the loss of Chapter 43 & 75 protections really means
Understand: This removes performance improvement periods (PIPs), MSPB appeal rights, and statutory due process (notice and response) removal processes.
Ask
- How will agencies set standards for managers to meet before removing someone on Schedule P/C?
- What internal review happens before a removal decision is finalized?
Watch
- How frequently this authority is used across agencies
- Whether managers express uncertainty about when or how to use this authority
- Differences in how agencies apply this authority
- Situations where employees raise concerns related to PPP protections
Why it matters: The health of the civil service depends on disciplined, fair, and consistent implementation of workforce policies.
What replaces MSPB and OSC review and whistleblower safeguards
Understand: Schedule P/C employees cannot appeal placement or removal through MSPB or file complaints with the OSC. Instead, the rule requires agencies to create and enforce internal protections against Prohibited Personnel Practices (PPPs), including whistleblower reprisal.
Ask (when agencies have made designations)
- What PPP/whistleblower safeguards have you established for Schedule P/C?
- Who reviews allegations of misuse?
- Are these procedures public to employees?
- If an employee is separated, will they have access to these procedures?
- Will job applicants have access to these procedures?
- How are complaints tracked and reported?
- Will the confidentiality of whistleblowers be protected?
- What training have managers received on PPP risks when using Schedule P/C authority?
- What role do IG and OSC play?
- Are Schedule P/C related PPP complaints being flagged as a category?
Watch
- Whether employees understand where and how to raise concerns
- Whether safeguards are formalized in written procedures
- Whether managers demonstrate understanding of PPP responsibilities
- Patterns in complaint data that may indicate either effective safeguards or lack of awareness
- How seriously agencies operationalize these safeguards in practice
Why it matters: Under the traditional civil service system, MSPB provided an independent judge, formal record, public decisions, visible check on agency action. OSC safeguarded the merit system by protecting federal employees and applicants from prohibited personnel practices and provided a secure channel for federal employees to blow the whistle by disclosing wrongdoing. Under Schedule P/C, legitimacy depends on whether agencies build credible, transparent, and trusted internal safeguards. Visible safeguards are essential for preventing misuse of at-will authority; protecting whistleblowers and dissenters acting in good faith; maintaining workforce trust in policy offices; ensuring accountability does not become perceived politicization. Agencies need to have strong systems before problems arise.
Hiring and merit rules
Understand: Hiring for Schedule P/C roles must still follow merit procedures. New hires in Schedule P/C can gain competitive status in 2 years.
Ask (on a rolling basis)
- Are there any differences between traditional merit hiring and Schedule P/C hiring practices?
- As the rule is implemented, how many new hires have been made into these roles?
- Have any individuals previously serving in political roles been hired into Schedule P/C roles?
Watch
- Whether employees and managers clearly understand how competitive status is gained
- Public hiring announcements and transparency around these roles
Why it matters: Perceptions of politicization may arise here.
Workforce and mission impacts
Understand: These roles will sit in a wide range of functions across agencies. Early concerns about Schedule P/C highlighted risks to sensitive, scientific, technical, or high-demand roles where continuity and ability to “speak truth to power” are valued.
Ask (on a rolling basis)
- Have you seen retention or recruitment impacts in Schedule P/C roles?
- Have employees moved to Schedule P/C declined roles or departed Federal service?
- What Schedule P/C roles are in the national security, scientific, or health fields, or fields engaged in long-term risk work?
- How are agencies addressing concerns that Schedule P/C would stifle dissent or evidence-based policymaking?
- How many employees in Schedule PC roles have transferred or competed for non-Schedule PC roles? How many have sought to?
Watch
- Hollowing out of key policy offices
- Reluctance of experienced staff to serve
Why it matters: Accountability gains should not come at the expense of mission capacity.
Does this address the performance problem it’s meant to solve?
Understand: OPM justifies the rule using MSPB and FEVS data showing managers struggle to remove poor performers; however, the rule does not introduce a more mature performance management standard.
Ask (on a rolling basis, or through GAO review)
- What evidence do you have that those in “policy influencing” roles have performance issues, or that the impact of such performance issues is greater?
- Have you used this authority to remove employees for performance issues? Why could they not be addressed under prior mechanisms?
- Are managers finding it easier to address poor performance? What about to incent strong performance?
- What indicators are you watching for improved overall performance?
- What standards are being applied for performance? Are they consistent within or across agencies?
Watch
- Rule exists on paper but behavior doesn’t change
- Different definitions for poor performance arise from adverse action, conduct and performance as defined in Chapters 43 and 75
- Performance problems persist for other reasons
Why it matters: Congress should know if the remedy matches the diagnosis.
Data Congress should request via GAO for ongoing tracking and comparison
Request from agencies:
- List of all positions designated
- Written justifications
- Counts by grade, office, and occupational series
- Number of removals using this authority
- Number of PPP/whistleblower complaints related to it
- Number of hires into Schedule P/C roles
Why it matters: Early transparency prevents speculation and enables evidence-based oversight.
Costs Come First in a Reset Climate Agenda
Building Blocks to Make Solutions Stick
Durable and legitimate climate action requires a government capable of clearly weighting, explaining, and managing cost tradeoffs to the widest away of audiences, which in turn requires strong technocratic competency.
Democratic governance needs
- Clear articulation of tradeoffs in policy design, including who pays, who benefits (and when), and why.
- Think bigger and wider in building durable coalitions for climate action, mobilizing dispersed beneficiaries and taking advantage of policy Overton windows that cut across partisan lines.
State Capacity needs
- Intergovernmental delivery muscle and partnering capacity to enable state and local actors.
- Invest in technocratic state capacity where the big wins live, like permitting and siting, interconnection and transmission, or power-market governance, and implementation capacity to limit bottleneck-driven policy failures.
- Institutionalize rigorous ex ante and regular cost benefit analysis to guide design and mid-course corrections.
Key Takeaways
- The costs of climate policy influence whether reforms benefit society, as well as their likelihood of passage and durability. Four ways to categorize climate policy costs are: negative-cost policies (pro-growth policies with climate co-benefits); low-cost policies (costs below domestic climate benefits); medium-cost policies (costs below global climate benefits); and high-cost policies (costs above global climate benefits). Cross-partisan alignment is most evident among pro-abundance progressives and pro-market conservatives.
- Negative- and low-cost policies align with domestic self-interest and comprise a growing share of the abatement curve. For example, market liberalization in permitting, siting, electricity regulation, and certain transportation applications lower energy costs and have profound emissions benefits. A prominent low-cost policy is emissions transparency. Negative- and low-cost policies hold the most potential for durable reforms and are often technocratic in nature.
- Chronic underconsideration of costs has induced an overselection of high-cost policies and underpursuit of low- and negative-cost policies. Legislative policies, such as subsidies and fuel mandates or bans, often receive no ex ante cost-benefit analysis before adoption. Interventions receiving cost-benefit analysis, especially regulation, tend to underestimate costs.
- Innovation policy – namely public support for research, development, and early-stage deployment – can align with domestic self-interest and address legitimate market deficiencies. By contrast, industrial policy for mature technology carries high costs, often erodes social welfare, and is not politically durable. Notably, public support for mature technologies in the Inflation Reduction Act was not durable, but support remained for nascent industry.
- We recommend that a reset climate agenda focus on abatement results over symbolic outcomes, prioritize state capacity for technocratic institutions, and emphasize cost considerations in policy formulation and maintenance. Negative cost policies warrant prioritization, with an emphasis on mobilizing beneficiaries like consumer, non-incumbent supplier, and taxpayer groups to overcome the lobbying clout of entrenched interests. Robust benefit-cost analysis should precede any cost-additive policies and be periodically reconducted to guide adjustments.
Introduction
Public policy involves tradeoffs. The primary tradeoff for climate change mitigation is economic cost. Secondary tradeoffs include commercial freedom, consumer choice, and the quality or reliability of goods and services. Political movements seeking to address a collective action problem, such as climate change, are prone to overlook the consequences of tradeoffs on other parties, like consumers and taxpayers. This paper posits that the cost tradeoffs of climate change mitigation have been underappreciated in the formation of public policy. This has resulted in an overselection of high cost policies that are not politically durable and may erode social welfare. It also results in overlooking low or negative-cost policies that are durable and hold deep abatement potential. These policies can have broad political appeal because they align with the self-interest of the United States, however they typically require dispersed beneficiaries to overcome the concentrated lobby of entrenched interests.
A core, normative objective of public policy is to improve social welfare, which “encourages broadminded attentiveness to all positive and negative effects of policy choices”. Environmental economics determines the welfare effects of climate change mitigation policy by the net of its abatement benefits less the costs. The conventional technique to determine abatement benefits is the social cost of carbon (SCC). The barometer for whether climate policy benefits society is to determine whether abatement benefits exceed costs. Accounting for full social welfare effects requires consideration of co-benefits as well, granted these tend to be conventional air emissions with existing mitigation mechanisms covered under the Clean Air Act. Nevertheless, accounting for costs is essential to ensure climate policy benefits society.
Abatement costs also have a discernable bearing on the likelihood and durability of policy reforms. Climate policies exhibit patterns of passage, mid-course adjustments, and political resilience across election cycles based on the constituency support levels linked to benefit-allocation and cost imposition. This paper develops four policy classifications as a function of their abatement benefit-cost profile, and uses this framework to examine the political economy, abatement effectiveness, and economic performance of select past and potential policy instruments.
Political Economy and Policy Taxonomy
The translation of climate policy concepts into legitimate policy options in the eyes of policymakers can be viewed through the Overton Window. That is, politicians tend to support policies when they do not unduly risk their electoral support. The Overton Window for climate policy is constantly shifting within and across political movements with the foremost factor being cost.
In a 2024 survey of voters, the most valued characteristics of energy consumption were 37% for energy cost, 36% for power availability, 19% for climate effect, 6% for U.S. energy security effect, and 1% for something else. Democrats slightly valued energy cost and power availability more than climate effects. Independents and Republicans heavily valued energy cost and power availability more than climate effect.
Progressives have long exhibited greater prioritization of climate change policy, but cost concerns are driving an overhaul of the progressive Overton Window on climate change. In California, which contains perhaps the most climate-concerned electorate in the U.S., progressives have begun a “climate retreat” to recalibrate policy as “[e]lected officials are warning that ambitious laws and mandates are driving up the state’s onerous cost of living”. Nationally, a new progressive thought leadership think tank is encouraging Democrats to downplay climate change for electoral benefit. Importantly, they find that 61% of battleground voters acknowledge that “climate change is at least a very serious problem,” but that “it is far less important than issues like affordability.”
Similarly, veteran progressive thought leaders, such as the Progressive Policy Institute, now stress that “energy costs come first” in a new approach to environmental justice. While emphasising the continued importance of GHG emissions reductions, those policy leaders are making energy affordability the top priority, amid a broader Democratic messaging pivot from climate to the “cheap energy” agenda. The rise of cost-conscious progressives is particularly notable because the progressive electorate has expressed a higher willingness to pay to mitigate climate change than moderate and conservative electoral segments.
Economic tradeoffs, namely costs and more government control, has long been the central concern on climate policy for the conservative movement. The conventional climate movement messaged on fear and the need for economic sacrifice, which is the antithesis of the conservative electoral mantra: economic opportunity. Yet the conservative climate Overton Window emerged with a series of state and federal policy reforms when climate change mitigation aligned with expanded economic opportunity. However, pro-climate conservative thought leaders remain opposed to high cost policies, such as calling to phase out Inflation Reduction Act (IRA) subsidies for mature technologies.
Many leading conservative thought leaders continue to challenge the climate agenda writ large because of its association with high cost policies. For example, President Trump’s 2025 Climate Working Group report was expressly motivated by concerns over “access to reliable, affordable energy” while acknowledging that climate change is a real challenge. Similarly, a 2025 American Enterprise Institute report finds that the public is most interested in energy cost and reliability and unwilling to sacrifice much financially to address climate change. Meanwhile, climate-conscious conservative thought leaders like the Conservative Coalition for Climate Solutions and the R Street Institute continue to emphasize a market-driven, innovation-focused policy agenda that prioritizes American economic interests and drives a cleaner, more prosperous future. Altogether, it indicates a conservative Overton Window on negative and low-cost climate change mitigation.
While cost is driving the Overton Window within each political movement, it also buoys the potential for alignment across political movements. Political movements are not monoliths, but rather exhibit major subsets within each movement. The progressive movement has seen gains in popularity among its populist left flank, often identified as the “democratic socialist” wing, which contributes to ongoing debate about Democrats’ ideological direction. Climate policy initiated by this wing, however, is associated with high economic tradeoffs (e.g., degrowth) and has prompted a backlash within the progressive movement. By contrast, a subset of the progressive movement, sometimes labelled “abundance progressives,” has emerged to support a more pro-market, pro-development posture. This movement is especially responsive to energy cost concerns, and is an emerging substitute for the anti-development traditions of the progressive environmental movement. Overall, variances in the progressive movement are fairly straightforward to categorize linearly on the economic policy spectrum.
The Republican electorate views capitalism far more favorably than Democrats, but with modest decline in recent years. Republicans have trended away from consistently conservative positions associated with limited government, which historically emphasized the rule of law and a strict cost-benefit justification for government intervention in the market economy. They have migrated towards right-wing populism associated with the Make America Great Again (MAGA) movement. Right-wing populism is hard to operationalize for economic policy because it is not a standalone ideology, but a movement vaguely attached to conservative ideology. Generally, the “America First” orientation of MAGA implies positions based on the self-interest of the U.S., with the Trump administration prioritizing cost reductions in energy policy.
MAGA is further to the right of conventional conservatives on environmental regulation and general government reform. For example, conservatives have noted the contrast between conservative “limited, effective government” and the Department of Government Efficiency’s “gutted, ineffective government” reform approach. On the other hand, MAGA will occasionally back leftist policy instruments, such as coal subsidies, wind restrictions, executive orders to override state policies, and emergency authorities for fossil power plants. These are often justified to counteract the leftist policies passed by progressives (e.g., renewables subsidies, fossil restrictions, emergency authorities for renewables), resulting in dueling versions of industrial policy. In other words, ostensible overlap between MAGA and progressives on policy instrument choice actually reflects the use of similar tools used for conflicting purposes (e.g., restrictive permitting or subsidies for opposing resources; i.e. picking different “winners and losers”). Nevertheless, the disciplinary agent for right-wing energy populism has been cost concerns, which have influenced the Trump administration to pursue more traditionally conservative energy policies like permitting reform and lowering electric transmission costs.
This political economy identifies the broadest cross-movement Overton Window between moderate or “abundance progressives” and traditional conservatives. Regardless, both broad movements exhibit cost sensitivity and growing prioritization of U.S. self–interest. Distinguishing the domestic SCC from global SCC is essential to determine what policies are consistent with the self-interest of the U.S. versus the world as a whole. Traditionally, the U.S. government only considers domestic effects in cost-benefit analysis, yet the vast majority of domestic climate change abatement benefits accrue globally.
The first SCC, developed under the Obama administration, relied solely on a global SCC. Leading conservative scholars, including the former regulatory leads for President George W. Bush, criticized the use of the global SCC only to set federal regulations. They argued for a “domestic duty” to refocus regulatory analysis on domestic costs and benefits. Similarly, the first Trump administration used a domestic SCC. Although the second Trump administration moved to discard the SCC outright, this appears to be part of a regulatory containment strategy, not a reflection of the conservative movement’s dismissal of the negative effects of climate change. In other words, even if the SCC is not the explicit basis for policymaking, it is a useful heuristic for policymakers.
The proper value of the SCC is the subject of intense scholarly and political debate. It has fluctuated between $42/ton under President Obama, $1-$8/ton under President Trump, and $190/ton under the Biden administration (all values for 2020). The main methodological disagreement has been over whether to use a domestic or global SCC, with the Trump administration position guided by “domestic self-interest.” This suggests the original domestic and global SCC values may approximate the Overton Window parameters the best. This underscores the following policy taxonomy that characterizes climate abatement policies by cost relative to domestic and global SCC levels:
- Class I policy: negative abatement costs. Such policies are widely viewed as “no regrets” by scholars and political actors across the spectrum because they constitute sound economic policy that happens to carry climate co-benefits. The Overton Window is most robust for Class I policy. It typically takes the form of fixing government failure, such as permitting reform.
- Class II policy: positive abatement costs below the domestic SCC. These low-cost policies often fall within the Overton Window, because they advance U.S. self-interest (i.e., positive domestic net benefits). Class II policies have a small abatement cost range (e.g., up to $8/ton). One estimate puts them at 4-14 times smaller than the global SCC.
- Class III policy: abatement costs between the domestic SCC and global SCC. These medium-cost policies improve global social welfare, but are not in the self-interest of the U.S., excluding co-benefits. Most cost-additive policies that pass a global SCC test fall in this range, underscoring why climate change is an especially challenging strategic problem; those incurring abatement costs do not accrue most abatement benefits. Class III policies face inconsistent domestic support and often require international reciprocation to be in the self-interest of the U.S.
- Class IV policy: abatement costs exceeding the global SCC. These high-cost policies fail a climate-only cost-benefit test. In other words, Class IV policies erode social welfare, excluding co-benefits. Class IV policies may be effective at reducing emissions, but often leave society worse off. Class IV policies are challenging to pass and are hardest to sustain.
Policy Applications
There are myriad policies across the abatement cost spectrum. This analysis applies to particularly popular domestic policies already pursued or readily considered. This includes policies targeting the environmental market failure via direct abatement (GHG regulation) and indirect abatement (public spending, clean technology mandates, and fuel bans). It also includes policies targeting non-climate market failure, yet hold deep climate co-benefits (innovation policy). The analysis also examines policies that correct government failure and have major climate co-benefits (permitting, siting, and electric regulation reform).
Fuel Mandates and Bans
For the last two decades, the most prevalent climate policy type in the U.S. has been state level fuel mandates and bans. Last decade, the environmental movement came to prefer policies that explicitly promote or remove fuels or technologies, not emissions. This is despite ample evidence in the economics literature that market-based policies are more effective and carry far lower abatement costs. Nevertheless, the most common domestic climate policy instrument this century has been state renewable portfolio standards (RPS). The literature notes several key findings from RPS:
- RPS has substantial but diminishing abatement efficacy. RPS compliance drove the bulk of initial renewables deployment, but declined to 35% of U.S. renewables capacity additions in 2023. This reflects the improved economics of renewable energy, which went from an infant industry in the 2000s to a mature technology and the preferred choice of voluntary markets by the 2020s. Renewables also exhibit declining marginal abatement as penetration levels grow. This underscores the environmental underperformance of policies promoting fuel, not emissions reductions.
- Binding RPS increases costs, with large state variances based on target stringency and carveouts. RPS compliance costs average 4% of retail electricity bills in RPS states and reach 11-12% of retail bills in states with solar carve-outs. Stringency is a key factor, as some RPS are not binding due to strong market forces, whereas binding RPS increases costs. Abatement cost estimates of RPS vary widely, with one prominent study placing compliance with RPS from 1990-2015 at $60-$200/ton. Within the Mid-Atlantic region alone, implied states’ RPS compliance costs in 2025 ranged from $11/tonne to $66/tonne, with solar carveout compliance clocking in at $70/tonne to $831/tonne. The future abatement cost of renewables integration is highly sensitive to RPS stringency and technology cost assumptions, with one estimate of implied abatement costs ranging from zero (nonbinding) to $63/tonne at 90% requirement in 2050. This evidence qualifies RPS as a class II to class IV policy, depending on its design.
- States with stringent RPS face challenging compliance targets, prompting calls for reforms to mitigate cost. Compliance with interim targets has generally been strong but stringent RPS states are beginning to fall behind on their targets. For example, renewable energy credit (REC) costs are nearing alternative compliance payment levels. To reduce costs, popular reform ideas have included delaying compliance timelines, adopting a clean energy standard to capture broader resource eligibility, or making RECs emissions weighted.
- Modest RPS exists in some conservative states but aggressive RPS policy has, generally, only proven popular in progressive states. As of late 2024, 15 states plus the District of Columbia had RPS targets of at least 50% retail sales, and four have 100% RPS. Sixteen (16) states have adopted a broader 100% clean electricity standard, though the broad definition of clean energy dilutes expected abatement performance in some states. Overall, renewable or clean portfolio standards do not appear to hold broad Overton Window alignment potential beyond modest applications.
Micro-mandates have also sprung up, primarily in progressive states. These have often targeted the promotion of nascent or symbolic energy sources that the market would not otherwise provide, with the costs obscured from public view (e.g., rolled into non-bypassable electric customer charges). A good example is offshore wind requirements in the Northeast, which carries a high abatement cost (over $100/ton).
Fuel bans have become increasingly popular climate policy in progressive states and municipalities. Beginning in 2016, a handful of progressive states began banning coal. However, this does not appear to have created much cost or abatement benefit, as evidenced by a lack of commercial interest in coal expansion in areas without such restrictions. In fact, neither federal nor state regulation was responsible for steep emissions declines from coal retirements. Coal retirements were mostly driven by market forces, especially breakthroughs in low-cost natural gas production and high efficiency power plants. Policy factors, like the Mercury and Air Toxics Rule, were secondary drivers of coal plant retirement.
Around 2020, California, New York, and most New England states began adopting partial natural gas bans or de facto bans on new gas infrastructure through highly restrictive permitting and siting practices. Unlike coal restrictions, these laws have markedly decreased commercial activity, namely gas pipeline and power plant development, and in some cases caused economically premature retirements. This has caused “pronounced economic costs and reliability risk.” Resulting pipeline constraints drive steep gas price premiums in these states, which translate into a core driver of elevated electricity prices.
Insufficient pipeline service in the Northeast is especially problematic, as demonstrated by a December 2022 winter storm event that nearly led to an unprecedented loss of the Con Edison gas system in New York City that would have taken weeks or months to restore. Further, preventing gas infrastructure development does not provide a clear abatement benefit, because more infrastructure is needed to meet peak conditions even if gas burn declines. A prominent study found a 130 gigawatt increase in gas generation capacity by 2050 was compatible with a 95% decarbonization scenario.
Progressive states and municipalities have also pursued natural gas consumption bans. This policy may carry exceptional cost, especially for existing buildings, with potentially well over $1 trillion in investment cost to replace gas with electric infrastructure. One estimate put the cost of natural gas bans at over $25,600 per New York City household. A Stanford study projected a 56% electric residential rate increase in California from a natural gas appliance ban. Generally, conservative thought leaders and elected officials have opposed natural gas bans for cost as well as non-pecuniary reasons, including security concerns and the erosion of consumer choice. This applies even for prominent members of the Conservative Climate Caucus. Altogether, gas bans are considered class IV policy with virtually no Overton Window alignment.
GHG Transparency
GHG regulation takes various forms. The least stringent is GHG transparency, which addresses an information deficiency and lowers transaction costs in voluntary markets. This begins with reporting and accounting requirements on emitters (Scope 1 emissions). Public policy can help resolve measurement and verification problems that have eroded confidence in voluntary carbon markets. GHG transparency policy can also standardize terminology and provide indirect emissions platforms. For example, making locational marginal emissions rates on power systems publicly available lets market participants identify the indirect power emissions of power consumption (Scope 2 emissions). Progressives have consistently favored GHG transparency policy, while conservatives have typically supported light-touch versions of it like the Growing Climate Solutions Act.
The second Trump administration recently pursued removal of basic GHG reporting requirements on ideological grounds, specifically repeal of the GHG Reporting Program (GHGRP). This appears to reflect an optical deregulatory agenda over an effective one. Conservative groups have warned of the downsides of GHGRP repeal. Pressure to course correct may prove fruitful, given that the industry the Trump administration aims to assist – oil and natural gas – maintain that the U.S. Environmental Protection Agency (EPA) should retain the GHGRP. A recent analysis found that if states replace the GHGRP, new programs will be more expensive (Figure 2).
Many regulated industry and conservative groups instead support a low compliance cost GHG reporting regime with durability across future administrations. This not only applies to direct emissions reporting but indirect emissions reporting, as in the absence of federal policy industry faces a patchwork of compliance requirements across states and foreign governments. The same economic self-interest rationale justifies a role for limited government in emissions accounting, with an emphasis on the capital market appeal of showcasing the “carbon advantage” of the U.S. in emissions-intensive industries. An example is liquified natural gas, whose export market is enhanced by showcasing its lifecycle emissions advantage over foreign gas and coal.
The abatement effectiveness of GHG transparency has grown appreciably in the 2020s, as voluntary industry initiatives have sharply increased. This policy set enables an efficient “greening of the invisible hand” with staying power, as corporate environmental sustainability efforts appear resilient regardless of political sentiment, unlike corporate social endeavors. In fact, the aggregate willingness to pay for voluntary abatement from producers, consumers, and investors suggests that well-informed domestic markets go a long way towards self-correcting the externality of GHGs (e.g., convergence of the private and social cost curves). Certain voluntary corporate behaviors may even exceed the global SCC, especially commitments to nuclear, carbon capture, and other higher cost abatement generation financed by the largest sources of power demand growth. Well-functioning voluntary carbon markets could yield roughly one billion metric tons of domestic carbon dioxide abatement by 2030. Providing locational marginal emissions data can slash abatement costs from $19-$47/ton down to $8-$9/ton while doubling abatement levels from some power generation sources.
Overall, efficient GHG transparency policy described above is a low-cost mitigation strategy consistent with class II designation. Basic, federal GHG transparency policy may even constitute class I policy, because it avoids the higher compliance cost alternative of a patchwork of state and international standards that would manifest in the absence of federal policy. However, stringent GHG transparency policy may constitute class III or IV policy. Prominent examples include a recent California climate disclosure law and a former Securities and Exchange Commission proposed rule to require emissions disclosure related to assets a firm does not own or control (Scope 3). Such efforts may obfuscate material information on climate-related risk and worsen private-sector led emission mitigation efforts.
Direct GHG Regulation
Classic environmental regulation takes the form of a command-and-control approach. These instruments include applying emissions performance standards or technology-forcing mechanisms, typically for power plants or mobile sources. These policies vary widely in stringency and cost. Overall, command-and-control is widely considered in the economics literature to be an unnecessarily costly approach to reducing GHGs relative to market-based alternatives. It can also result in freezing innovation, by discouraging adoption of new technologies.
Federal command-and-control GHG programs have not been particularly environmentally effective, cost-effective, or demonstrated legal or political durability. The first power plant program was the Clean Power Plan, which was struck down in court, and yet its emissions target was achieved a decade early from favorable market forces and subnational climate policy. The most recent federal command-and-control approaches for GHG regulation were 2024 EPA rules for vehicles and power plants. A 2025 review of these and other federal climate regulations over the last two decades of federal climate regulations found:
- EPA’s cost estimates to be “extraordinarily conservative” with suspect methodology that was prone to error and inconsistent with economic theory;
- Assessed costs of $696 billion compared to regulators’ estimate of $171 billion, or an increase in abatement cost from $122/tonne to $487/tonne; and
- EPA is too optimistic in its assumptions of benefits.
The 2025 review study implies that past federal command-and-control had very high cost – well into class IV range. It has also been a top priority of conservatives to undercut. However, it is possible for modest command-and-control policy with class II or III costs.
Some conservatives, noting EPA’s legal obligation to regulate GHGs and the cost of regulatory uncertainty from decades of EPA policy oscillations between administrations, suggested modest requirements as a better option to replace high cost rules in order to mitigate legal risk and provide industry a predictable, low-cost compliance pathway. For example, conservatives argued that replacing high cost requirements for power plants to adopt carbon capture and storage (CCS) with low cost requirements for heat rate improvements may lower compliance costs more than attempting to repeal the Biden era rule for CCS outright. Similarly, the oil and gas industry opposed stringent GHG regulations on power plants and mobile sources, but often validated alternative low cost compliance requirements.
The first Trump administration pursued modest replace-and-repeal GHG regulation. The second Trump administration has opted for repeal policies and to eliminate the endangerment finding via executive rulemaking. However, regulated industry and many conservative thought leaders believe this is a strategic blunder, given the low odds of legal success, resulting in the perpetuation of “regulatory ping-pong that has plagued Washington, D.C., for decades.” If the courts uphold Massachusetts v. EPA and the associated endangerment finding, this implies that modest command-and-control policy may have durable political alignment potential. Yet this does not hold much abatement potential. In the absence of a legal requirement to regulate GHGs, there is unlikely to be broad political alignment for even modest command-and-control policy. Conservatives tend to view this as a gateway to more costly policies that will probably not meaningfully affect global GHG trajectories.
The 2025 review study understates the full cost of U.S. climate regulations because they exclude state and local levels. Although no comprehensive study of state climate regulation is known, command-and-control state regulations often raise major cost concerns as well. The cost and environmental performance of such state programs varies immensely, often owing to differences in the accuracy of abatement technology costs that regulatory decisions are based upon (e.g., the failure of California’s zero-emission vehicle program compared to success with its low-emission vehicle program). A recent example is California’s rail locomotive mandate, which projected to impose tens of billions of dollars in costs before being withdrawn. State command-and-control regulation is commonplace in progressive states, but not beyond, implying meager Overton Window alignment.
A more economical version of GHG regulation is a system of marketable allowances, or cap-and-trade (C&T). Over three decades of experience with C&T programs reveals two things. First, C&T is environmentally effective and economically cost effective relative to command-and-control policy. Second, C&T performance depends on its design quality and interaction with other policies. Abatement costs depend on stringency and other design features, but C&T in a backstop role is generally close to the domestic SCC, rendering it class II policy. Robust C&T generally falls in the class III policy range. C&T is an example of abatement policy that can be cost-effective on a per unit basis, but given the breadth of its coverage its total costs can be substantial. Recent developments in Pennsylvania indicate a possible preference for policies with higher per-unit abatement costs than C&T, which may reflect a political preference for policies with less cost transparency and lower aggregate costs.
Some environmental C&T complaints are valid, such as emissions leakage, but C&T effectiveness concerns are generally readily fixable design flaws. C&T effectiveness complaints are often the result of interference from other government interventions like fuel mandates, relegating C&T to a backstop role and suppressing allowance prices. Such state interventions triggered anti-competitive concerns in wholesale power markets overseen by the Federal Energy Regulatory Commission (FERC). This prompted conservative state electric regulators to call for a conference to validate mechanisms like C&T as a market-compatible alternative to high cost interventions. Conservative expert testimony at that conference, invited by conservative FERC leadership, explained that interventions layered on top of C&T merely reallocate emissions reduction under a binding cap, which raises costs, creates no additional abatement, and undermines innovation. This implies that such states might increase abatement and lower aggregate costs by upgrading the role of C&T and downgrading the role of costlier interventions.
In the 2000s, bipartisan interest in federal C&T policy arose, but it failed and has not resurfaced. In its absence, states have supplanted federal policy with subnational C&T programs. However, the durability of C&T beyond progressive states is unclear. Moderate states have sometimes joined a regional C&T program under Democratic leadership, but sometimes departed them under Republican leadership. Conservative state groups typically challenge C&T adoption and seek repeal of C&T programs like the Regional Greenhouse Gas Initiative. This suggests that C&T is at the fringe, but typically outside, an Overton Window across political movements.
Permitting and Siting
Permitting policy can base decisions explicitly on GHG criteria, or they can be based on non-GHG factors but hold indirect GHG consequences. Generally, only progressive states and presidents have pursued the former. Federally, these include the Obama administration’s “coal study” and Biden administration’s “pause” on liquified natural gas (LNG). The LNG pause did not provide any apparent emissions benefit, yet carried substantial foregone economic opportunity and strategic value to U.S. allies. Pragmatic progressive thought leaders expressed concern with the pause, noting the creation of economic and security risks, and suggested lifting the pause in exchange for companies to commit to strict, third-party verified methane emissions standards. Relatedly, some conservative thought leaders have supported policy that enables voluntary participation in certified programs that provide market clarity and confidence to harness private willingness to pay for lower GHG products. This has been buttressed by support from an industry-led effort to advance a market for environmentally differentiated natural gas based on a standard, secure certification process.
Permitting constraints on clean technology supply chains can have perverse economic and emissions effects. A prime example is critical minerals, which are essential components to clean energy technologies. A net-zero emission energy transition, relative to current consumption, would increase U.S. annual mineral demand by 121% for copper, 504% for nickel, 2,007% for cobalt, and 13,267% for lithium. Market forces, unsubsidized, are poised to produce a sufficient amount of domestic copper and lithium supply to satiate a large share of domestic demand, but face undue barriers to entry that restrict production far below its potential. To meet net-zero objectives, permitting reform allowing all currently proposed projects to enter the market would lower U.S. import reliance for copper from 74% to 41%, while dropping lithium import reliance from 100% to 51%.
Expanding domestic mining no doubt carries local environmental tradeoffs. However, the U.S. has some of the most stringent and comprehensive mining safeguards in the world. Thus, foregoing development domestically is likely to push mining toward foreign countries with inferior environmental, safety, and child labor protections. It is therefore critical that domestic permitting decisions account for the unintended effects of denying permits, not merely the direct consequences of approving a project.
Permitting and siting constraints on energy infrastructure also impose major costs and foregone abatement. These entry barriers largely exist as environmental safeguards, yet almost always inhibit projects with a superior emissions profile to the legacy resources they replace. In fact, 90% of planned and in progress energy projects on the federal dashboard were clean energy related as of July 2023. In 2023, the ratio of clean energy to fossil projects requiring an environmental impact statement to comply with the National Environmental Policy Act (NEPA) was 2:1 for the Department of Energy and nearly 4:1 for the Bureau of Land Management. A 2025 study estimated that bringing down permitting timelines from 60 months to 24 months would reduce 13% of U.S. electric power emissions.
Permitting has proven to be a litmus test for the progressive environmental movement, as the movement bifurcates between anti-development symbolists and pragmatic pro-abundance progressives. While a minority of mainstream environmental groups have become amenable to permitting reform, such as The Nature Conservancy and Audubon Society, the core of progressive environmental groups have not. Instead, new progressive groups like Clean Tomorrow and the Institute for Progress filled the pro-abundance void alongside traditional market-friendly progressive groups like the Progressive Policy Institute. This progressive subset has helped influence moderate Democrats to support permitting reform in a collaborative way with conservatives.
Permitting reform has long been championed by conservatives for its economic benefits, with climate considerations typically a secondary-at-best rationale. Yet permitting reform has become a priority for the newer climate-minded conservative movement. However, permitting has also proven to be a differentiator between conservatives and right-wing populists. The latter engages in forms of government intervention that sometimes contradict conservative principles. For example, the Trump administration enacted an offshore wind energy pause that followed the same problematic blueprint as the Biden administration’s LNG pause. This elevates the importance of technology-neutral permitting reforms with an emphasis on permitting permanence safeguards.
In recent years, a coalition of Republicans, centrist Democrats, and clean energy and abundance advocates have pressed for reform to NEPA. A broad suite of federal permitting reforms with bipartisan appeal was identified in a 2024 report by the Bipartisan Policy Center. Bipartisan alignment led to the passage of the Fiscal Responsibility Act of 2023 into law and the Senate passage of the Energy Permitting Reform Act of 2024 (EPRA). Although a 2025 Supreme Court decision suggests executive actions alone may substantially reduce NEPA obstacles, plenty of NEPA and other federal statutory reforms remain of high value and hold considerable bipartisan potential.
The positions of leading progressive, conservative, and centrist thought leadership organizations highlight alignment on various federal permitting and siting reforms. These include statutory changes to NEPA, the Endangered Species Act, the Clean Water Act, the Clean Air Act and the National Historic Preservation Act. Substantive alignment includes reforms that reduce litigation risk (e.g., judicial review reform), limit executive power to stop project approvals and undermine permitting permanence, maintain technology neutrality, strengthen federal backstop siting authority for interstate infrastructure, codify the Seven County decision, and streamline agency practices while ensuring sufficient state capacity.
Despite considerable positive momentum at the federal level, the greatest permitting and siting barriers generally reside at the state and local levels and trending sharply in a more restrictive direction. Wind and solar ordinances have grown by over 1,500% since the late 2000s. Oil and gas pipelines and power plants face mounting permitting and siting restrictions in progressive states, which not only raise costs but do not necessarily reduce emissions. In fact, the New England Independent System Operator said that a lack of natural gas infrastructure in the region has raised prices and pollution by forcing reliance on higher-cost resources like oil-fired power plants. The only major power generation resource with a less restrictive trend is nuclear, as six states recently modified or repealed nuclear moratoria to ease siting.
Motivation for opposing energy infrastructure permitting has included the well-known “not in my backyard” concerns, such as noise, construction disruptions, or land use conflicts. Interestingly, much opposition appears to come from perception, as much as substantiated negative effects. Relatedly, permitting resistance rationales increasingly appear to result from ideological opposition to particular energy sources. Finally, much opposition and most litigation of energy projects comes from non-governmental organizations, not the land owners directly affected. Altogether, this underscores the importance of permitting and siting reform that improves the quality of information to agencies and parties, ties decisionmaking to specific harms not speculative claims, limits standing to affected parties, and creates appeals processes for landowners to challenge obstructive local government laws and decisions. A key tension to overcome is that technology-agnostic legislation has been more likely to advance in states with one or more Republican chamber, yet environmental advocates resist “all-of-the-above” reforms.
Policies that reduce permitting and siting burdens are class I: they boost economic output and are increasingly key to emissions reductions. Permitting and siting policies that are restrictive on fossil development are not particularly effective at reducing emissions and often add considerable cost, granted costs vary widely depending on the nature of the policies and implementation. Effective fossil restrictions can range from class II to class IV policy, while ineffective ones actually increase emissions. The political economy of permitting and siting must overcome the lobby of entrenched suppliers, who seek to maintain competitive moats. An ironic example was incumbent asset owners funding environmental groups to oppose transmission infrastructure in the Northeast that would import emissions-free hydropower.
Electric Regulation
The power industry is at the forefront of energy cost concerns and decarbonization objectives. In the early 2020s, electric rates have risen most in Democratic states. These concerns reoriented progressives towards cost containment, even at the expense of climate objectives. In the 2024 election, cost of living concerns propelled Republicans to widespread victories as President Trump vowed to halve electricity prices. A year later, voter concerns over rising electricity rates in Georgia, New Jersey, and Virginia boosted Democrats in gubernatorial and public service commission (PSC) elections.
At the same time, electricity is arguably the most important sector for climate abatement given its emissions share and the indirect effects of electrifying other sectors, namely transportation and manufacturing. Ample pathways exist to reduce electric costs and emissions simultaneously, primarily by fixing profound government failure embedded in legacy regulation. Electric industrial organization shapes economic and climate outcomes, with market liberalization an advantage for both.
Electric regulation falls into two basic formats. The first is cost-of-service (CoS) regulation, where the role of government is to substitute for the role of competition in overseeing a monopoly utility. The alternative is for regulation to facilitate competition by using the “visible hand” of market rules to enable the “invisible hand” to go to work.
CoS regulation historically applied to power generation, though about a third of states enacted restructuring to introduce competition into power generation and retail services, in response to rising rates and the recognition that these are not natural monopoly services. Nearly all transmission and distribution (T&D) historically and today remains under CoS regulation. Importantly, CoS regulation motivates a utility to expand the regulated rate base upon which it earns a state-approved return. Generally, the main sources of cost discipline problems in the power industry stem from its CoS regulation segments: transmission, distribution, and the portion of generation that remains on CoS rates.
Generally, restructured jurisdictions see greater innovation and downward pressure on the supply portion of customer bills. The economic performance of restructuring is highly sensitive to the quality of implementation. This includes the quality of wholesale energy price formation and capacity market design. It also includes various elements of retail choice implementation. They have also seen improved governance, whereas CoS utilities are prone to cronyism and corruption given the inherent incentives of their business model. Competitive wholesale and retail power markets hold cost and emissions advantages through several mechanisms:
- Markets accelerate capital stock turnover when it is economic. With the brief exception of nuclear retirements, new entry is dominated by zero emission resources or high efficiency gas plants that displace legacy plants with higher emissions rates. Markets usher in new entry and induce retirements in response to economic conditions. Last decade saw markets outperform in the coal-to-gas transition, and this decade with advances in wind, solar, and storage economics. Texas, the most thoroughly restructured state, leads the country in solar, wind, and energy storage additions while placing second in gas additions. A review of restructuring found that competition worked as intended, facilitating new, low-cost entry while “driving inefficient, high-cost generation out of the market.” A new paper evaluating generator-level data found that from 2010–2023, regulated units were 45% less likely to retire than unregulated units.
- Markets encourage power plant operating efficiencies. Competitive generators adopt technologies and practices that use fuel more efficiently and improve environmental performance. The introduction of competition caused nuclear generators to adopt innovative practices to reduce refueling outage times, boosting operating efficiency by 10%. One study found 9% higher operating efficiencies in the thermal power fleet in restructured states. By contrast, CoS utilities sometimes engage in uneconomic operations because they are financially indifferent to market signals, resulting in overoperation of the fossil fleet.
- Markets reflect customer preferences, including clean power. Footprints with retail choice have seen much higher popularity of voluntary clean power programs. Competition lowers the “green premium” and customer choice allocates it equitably. This is critical as the willingness to pay for clean power varies enormously across customers. Notably, most growing power customers are large companies with ambitious corporate emissions reductions targets, which explains their commercial interest in advancing consumer choice.
- Markets better integrate unconventional resources, namely storage, wind, solar, and demand flexibility. The central planning of monopoly utilities struggles to account for the profile of variable (e.g., wind and solar) and use-limited (e.g., storage) resources. Demand flexibility is valuable to integrate more variable supply sources. Wholesale and retail competition are the only structural pairings that have elicited substantial shifts in demand in response to price signals, because they align the incentives of retailers and end-users to reduce consumption during high price periods.
- Markets induce lower-cost environmental compliance and better environmental lobbying behavior. Restructuring reoriented the incentives to influence and comply with public policy. Notably, competitive enterprises pursue more innovative, lower-cost compliance pathways that tend to deepen abatement. Monopoly utilities have a track record of lobbying for higher cost environmental laws. For example, monopolies have a preference for command-and-control regulation that pads their rate base, and have opposed market-based policies like the 1990 Clean Air Act amendments.
Electric cost increases are multifaceted, prompting many misdiagnoses that blame markets for non-market problems. Utilities have begun pushing campaigns in restructured states to revert back to CoS regulation, whereas the growing consumer segment – namely data centers and industrials – are organizing campaigns to expand consumer choice. Independent economic assessments warn against a return to CoS regulation, and instead encourage state regulators to implement restructuring better. This includes better market design, consumer exposure to wholesale prices, and effective coordination with transmission investment.
T&D costs, generally, are the core driver of electricity cost pressures nationwide. Over the last two decades, utility capital spending on distribution has increased 2.5 times while nearly tripling for transmission. This reflects profound flaws in CoS regulation of T&D, resulting in overinvestment in inefficient infrastructure and underinvestment in cost-effective infrastructure. This projects to worsen, given T&D expansion needed to meet grid reliability criteria as a result of aging infrastructure, turnover in the generation fleet, and load growth.
T&D expansion is also central to abatement. Even partial transmission reforms can reduce carbon dioxide emissions by hundreds of million of tons per year. This explains why progressives have made reforms that expand transmission a top priority. This needs to be reconciled with the cost concerns of consumers and conservatives to result in durable policy. Consumers and conservatives have a budding transmission agenda rooted in upgrading the existing system, removing barriers to voluntary transmission development, using sound economic practices for mandatorily planned transmission, streamlined permitting and siting, and improved governance. A particularly promising frontier is reforms to enhance the existing system, given the expedience of their cost relief and consistency with a Trump administration directive.
Recent federal regulatory actions have demonstrated bipartisan willingness to improve transmission policy and the related issue of interconnection, which has emerged as a major cost and emissions issue. In 2023, FERC passed Order 2023 on a bipartisan basis to reduce barriers to new power plants trying to interconnect to regional transmission systems. Subsequent reforms were motivated by a coalition of consumer groups and the center-right R Street Institute. In 2024, FERC passed Order 1920-A on a bipartisan basis to improve economic practices in regional transmission development. EPRA, a gamechanger for interregional transmission development, passed the Senate with bipartisan support in 2024.
Demand growth has sparked reliability concerns over tight supply margins and recently put upward pressure on wholesale market prices. However, states with the greatest price decreases typically had increasing demand from 2019 to 2024 (Figure 3). This shows the importance of infrastructure utilization on electric rate pressures, as many areas had supply slack previously. The past may not be prologue. Emerging conditions show supply-constrained scenarios where marginal generation and T&D costs increase steeply to meet new load increase. The Energy Information Administration observes steady retail price increases and projects further rises to exceed inflation.
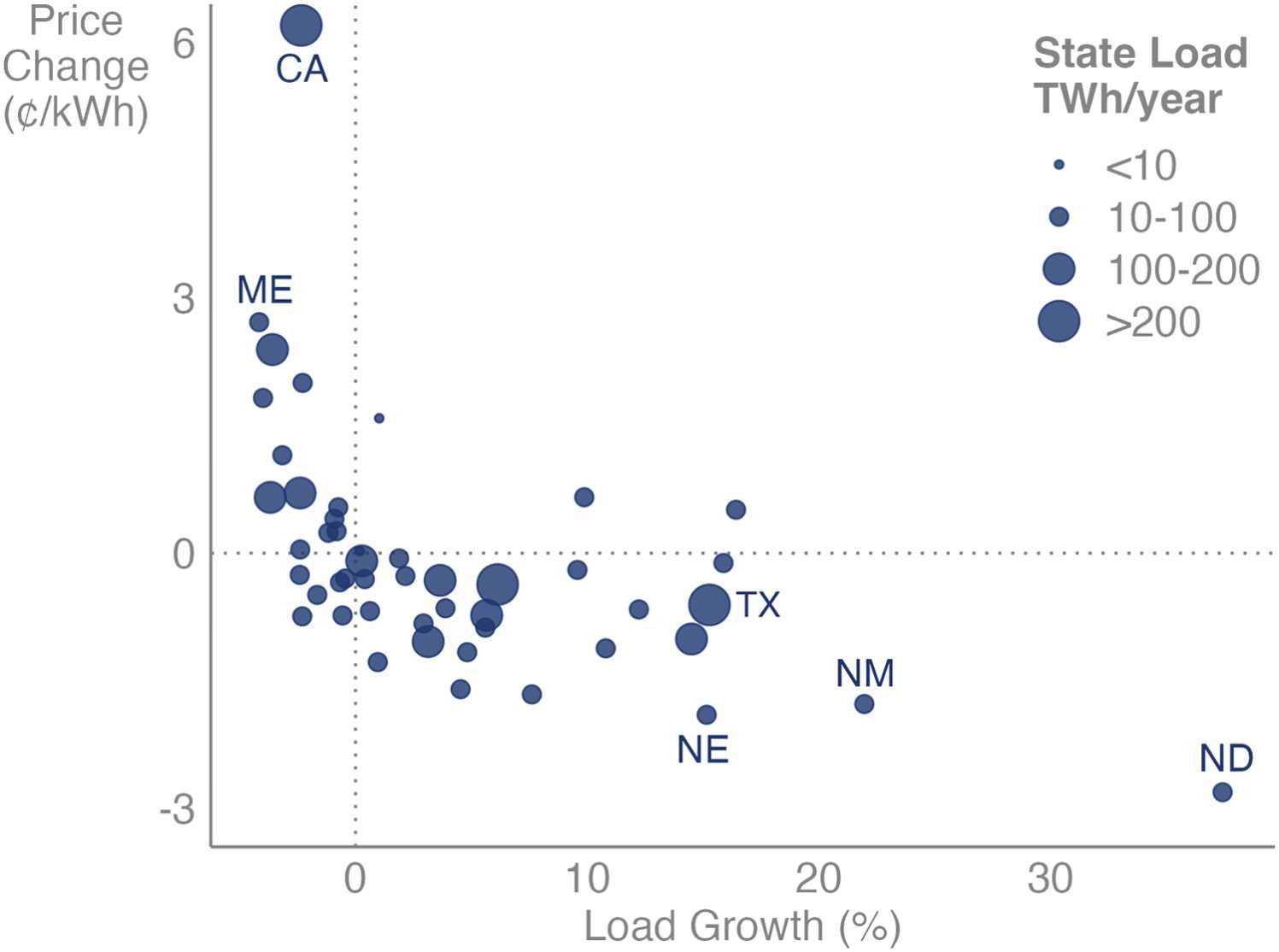
Source: Wiser et al., 2025.
In an era of resurgent power demand growth, the states poised to keep rates and emissions down have wholesale competition, retail competition, efficient generator interconnection processes, economical T&D practices, and low permitting and siting barriers. The only state that reasonably accomplishes all of these is Texas, which is experiencing the most commercial interest among competitive suppliers and growing power consumers. Texas has experienced industry-leading clean energy investment and earned the distinction of Newsweek’s “greenest state” in 2024.
All aforementioned electric reforms are considered class I policy. Despite cost-reduction appeal, power industry reforms have proven challenging for two reasons. First, reforms are highly technical in nature and face limited state capacity among legislative advisors and technocratic agencies, namely PSCs and FERC. For example, recent FERC and PSC activities reveal that these entities do not have the bandwidth or expertise to properly implement existing transmission policy, much less reform it. Secondly, reforms face strong resistance from incumbent utilities who hold concentrated interests in the status quo, creating a strong lobbying incentive. By contrast, the beneficiaries of reform, especially consumers, are dispersed interests that do not organize as effectively as a lobbying force.
Although the Texas electricity experiment and associated federal power market reforms under President George W. Bush is a conservative legacy, most restructured states are progressive. This reflects significant bipartisan historic appeal. However, traditional conservatives have sometimes conflated pro-utility positions as the “pro-business” position, while it is unclear whether right-wing populist influences will catalyze pro-market reforms by challenging the status quo or retrench monopoly utility interests based on technocratic market skepticism (e.g., Project 2025). CoS utilities also commonly oppose cost-effective T&D reform, especially vertically-integrated utilities, which is consistent with their financial incentives to expand rate base and deter lower-cost imports from third parties. Nonetheless, the political economy of bipartisan electric regulatory reform remains promising, given voters’ prioritization of reducing electricity costs.
Public Spending
Government spending occurs through direct spending outlays or indirect spending through tax expenditures. Spending takes the form of industrial policy or innovation policy. The economics literature is historically critical of industrial policy, while positive literature on industrial policy usually conflates it with innovation policy. A distinguishing element is that innovation policy selects policy instruments suited to specific market failures, namely the positive externalities of knowledge spillovers and learning-by-doing. These generally apply to research and development (R&D) and early stage technologies, including those in demonstration stage and infant industries that have not achieved economies of scale.
Predictably, progressives have been consistent backers of robust innovation policy, while conservatives typically scrutinize such expenses closely. Although differences of opinion exist on optimal funding levels, historically conservatives and progressives have agreed on a role for the government in supporting R&D. There is also a history of good governance agreement, such as a joint project between the Center for American Progress and the Heritage Foundation in 2013 on improving the performance of the national lab system. Improving outcomes-based Department of Energy program performance may have broad appeal, including better performance metrics, stronger linkages to private sector needs, and program reevaluation to determine government investment phase-out. Improvements to state capacity are paramount in this regard.
Conservatives are often critical of public spending on infant industry, where government failure can outweigh market failure. For example, policymakers often struggle to identify when to end industry support, while industry engages in rent-maintenance behavior even after it has achieved maturity. Historic evidence indicates that direct subsidies and tax exemptions for infant energy industry continue well after the targeted technologies mature. Conservative and progressive scholars have historically framed the merits over subsidies for infant industry as a debate over government versus market failure.
Since innovation policy targets non-climate market failures (e.g., knowledge spillovers) it may have a high static abatement cost. However, it is an inexpensive abatement policy when accounting for dynamic effects, because of induced innovation and learning-by-doing. Importantly, innovation policy holds massive climate benefits, because achieving abatement cost parity between clean and emitting resources is central to clean technology market adoption. Efficient R&D policy can be classified as class I policy, because the upfront cost of the policy is outweighed by long-term cost savings. Demonstration and infant industry support falls into class II-III range, depending on its implementation, and often exhibits substantial durability.
In recent years, climate-minded conservatives have shown stronger inclinations of public spending for innovation policy. However, there is a stark difference between conservatives and right-wing populism on innovation policy. Conservatives note that the adverse consequences of Department of Government Efficiency’s “gutted, ineffective government” approach to the Department of Energy is inconsistent with limited, effective government practice. The economic self-interest benefits of innovation policy may induce a course-correction with MAGA, which has not deliberately targeted innovation policy insomuch as sacrificing it amid a rash government downsizing exercise.
In contrast to innovation policy, industrial policy aims to directly promote a given industry, typically using mature technology, with interventions untethered to any underlying market failure (e.g., negative emissions externality). This generally takes the form of public spending on mature industries. For decades, traditional conservatives and climate-minded conservative scholars have been critical of green industrial policy for carrying high costs with modest emissions reductions.
The most relevant case study in climate industrial policy versus innovation policy is the Inflation Reduction Act (IRA) of 2022. IRA represented the “largest federal response to climate change to date.” It consisted mostly of subsidies for mature technologies, especially wind, solar, and electric vehicles (EVs). It also contained subsidies for infant industry. IRA was passed exclusively by Democrats, with Republicans voicing concerns over its cost. Republicans then passed the One Big Beautiful Big Act (OBBBA) in 2025, which phased-out subsidies for mature technologies, but generally retained those for infant industry. This underscores the political durability of innovation policy and the fragility of industrial policy.
A broader debrief on IRA and OBBBA reveals:
- Disregard for cost considerations preceded passage of the IRA. All known ex ante modeling of IRA’s abatement benefits before it passed ignored costs. This left Congress unequipped to weigh the merits and tradeoffs of the policy. A simplistic abatement cost technique in 2022 yielded a cost of $72/tonne for the renewable energy subsidies. A more sophisticated modeling exercise in 2023 projected an average abatement cost of $83/tonne. IRA could have been identified as a high abatement cost policy (class IV) before it passed. Before passage, R Street Institute analysis suggested meager additionality from subsidies and identified permitting and electric regulation flaws as the determining factors of energy emissions trajectories, yet Congress neglected those reforms.
- IRA abatement cost estimates escalated sharply after passage. The total abatement cost of IRA subsidies to taxpayers rose from $336/tonne in 2024 to $600/tonne in 2025. The initial 2022 IRA renewables subsidy cost estimate of $72/tonne rose to $142/tonne in 2024 and $208/tonne in 2025. The EV subsidy came in at $1,626/tonne. It is possible that this is understated, since the direction of the emissions effect of EV subsidies may depend on recipient qualifications, especially when accounting for the behavioral tendencies of EV adopters. The subsidies also undermined developer cost reduction in two ways: 1) motivated development in the least efficient areas and 2) weakened incentives for innovation that lowers costs, which translates into long-term cost increases relative to an unsubsidized baseline.
- Government failure precluded most of the anticipated climate benefits of the IRA. IRA abatement was overstated in 2022, because models understated artificial constraints on the core abatement driver: wind and solar deployment. The Energy Information Administration’s renewables projections in 2025, which reflected IRA subsidies, were close to their no-IRA estimates from 2022. Risk, not cost, has consistently been the barrier to wind and solar. A Brookings Institution analysis found that artificial barriers to entry were the leading causes of wind and solar project cancellations from 2016-2023, whereas the lowest cause was “lack of funding.” Renewables subsidies primarily constituted a wealth transfer from taxpayers to suppliers. One analysis suggested 80-90 percent of clean energy backed by the IRA would have occurred anyways. An S&P Global forecast projected OBBBA to cause a 15 percent decline in wind, solar, and battery storage capacity by 2035.
- Wind, solar, and EV tax credit phaseouts should lower costs and increase economic productivity, despite increasing electricity prices. Price and cost are related, but not the same thing. The phase-out of subsidies under OBBBA will put upward pressure on electricity prices. However, it will likely lower costs by restoring dynamic cost management incentives and removing distortions so investment reflects economic fundamentals. Electricity subsidies shift cost burdens from power generators and ratepayers to taxpayers. Because taxpayer funding is expensive – tax collection imposes considerable deadweight loss on the economy – the net effect of taxpayer subsidies tends to shrink economic output. The Tax Foundation projected that IRA would reduce U.S. gross domestic product by 0.2 percent, while OBBBA would increase long-run GDP by 1.2 percent, granted energy tax credits were only one factor in these analyses.
The takeaway from IRA and OBBBA is that subsidies for mature technologies are high cost, likely to erode social welfare, and not politically durable. Efficient public spending for RD&D, however, enhances social welfare and falls in the Overton Window due to its value for economic self-interest. Late-stage infant industry is at the fringe of the Overton Window. It is the area where conservative and progressive scholars have historically had contrasting views on whether market failure outweighs government failure, yet political outcomes have largely supported infant industry.
Generally, the literature finds strong evidence of opportunity cost neglect in public policy, which “creates artificially high demand for public spending.” The IRA was a case-in-point. Meanwhile, the opportunity cost of public spending is rapidly rising given the dire fiscal trajectory of the United States. In 2025, moderate experts emphasized a pivot away from unsustainable and ineffective “Green New Deal thinking” for clean technology subsidies in favor of an innovation-driven strategy.
Takeaways
This analysis finds chronic flaws of cost considerations in ex ante policy analysis. Many medium and high-cost policies have passed without any robust accounting of costs at all (e.g., IRA, fuel bans). Interventions with cost-benefit analysis have had a tendency to underestimate costs (e.g., regulation). These flaws contribute to public misconception and play into political economy dynamics that tend to incent policies with hidden costs over those with transparent ones.
High-cost policies have typically only been enacted by progressive governments and have come under greater scrutiny as energy costs escalate. This calls their social welfare effects and durability into question. It has cast climate action in the public eye as requiring deep economic sacrifice.
Conservatives have been hesitant to engage on climate policy outright, largely over dire economic tradeoff perceptions. Such concerns have instigated a conservative backlash to climate policy, including to policies that are compatible with U.S. economic interests. This has been exacerbated by right-wing populism, which often strays from limited government conservatism in pursuit of cultural identity objectives. For example, in a 2024 piece promoting energy affordability, the Heritage Foundation correctly attributed cost increases to renewable energy mandates, but incorrectly presumed that a broad shift towards renewable energy and away from fossil fuels would always increase costs.
High abatement cost policies not only risk reducing aggregate social welfare, but they create distributional concerns. Policies that raise energy costs tend to be regressive. This has challenged the social justice narrative of progressives, prompting a rethink by progressive leaders to take a “cost-first approach to [the] clean energy transition.” Although subsidies are a common response to lower burdens on low-income households, the most popular green subsidies pursued have exacerbated distributional concerns. Specifically, renewables subsidies favored by progressives have been challenged by conservatives as “green corporate welfare.” Progressives have also faced criticism for EV tax credits for disproportionately benefiting wealthy households.
Encouragingly, negative- and low-cost policies comprise a rising share of the abatement curve. The Overton Window for pursuing such policies has grown remarkably for “abundance progressives” and conventional conservatives. However, populist subsets within both movements challenge the potential for political alignment. Enacting negative-cost policies also faces the collection active problem of dispersed beneficiaries versus a concentrated incumbent supplier lobby favoring the status quo. Mobilizing consumer and taxpayer groups is an underappreciated strategy to enact these policies.
This analysis is far from comprehensive. A notable omission from this paper is transportation policy, the largest GHG sector in the U.S. A scan of the transportation literature underscores major abatement potential for negative and low-cost policies, including reducing government barriers to efficient heavy-duty transportation like railways, shipping, and heavier trucking. Further, the electrification of transportation requires extensive fixes to government failure, such as liberalizing markets to enable competitive charging infrastructure, which lowers costs. The merits of innovation and GHG transparency policy, previously discussed, also appear to hold promise for transportation applications such as aviation fuel. The transportation sector has also been the target of GHG regulation, mostly in progressive states, which warrants close assessment of costs. For example, one study identified a vast abatement cost range for fuel standards ($60-$2,272/tonne).
A shortcoming of this analysis is that it only characterizes costs by their efficiency (i.e., $/ton). Political decisions are highly sensitive to aggregate cost and its visibility to the public, which our taxonomy does not characterize. It is possible that efficient, transparent, and higher aggregate cost policies (e.g., C&T) fare less favorably in some political settings than inefficient, opaque, and sometimes lower aggregate cost policies (e.g., RPS solar carveouts).
Despite the limitations of this analysis, the sample of policies evaluated is sufficient to support the thesis. That is, a retooled climate policy agenda that prioritizes cost considerations should elevate social welfare and achieve greater abatement by selecting more durable policies.
Conclusion
Abatement costs have huge bearing on whether climate policies benefit society, their likelihood of passage, and whether they prove politically durable. Most abatement need not come from dedicated climate policy, per se, but rather sound economic policy that carries deep climate co-benefits. Chronic disregard for cost considerations has led to an overselection of high-cost policies and underpursuit of low- and negative-cost policies. This has undermined policy durability and exacerbated political polarization over climate change abatement.
This paper finds extensive abatement opportunities within negative-cost policies. These largely constitute fixes to government failure and include permitting, siting, and power regulation reforms. This analysis also finds considerable low-cost policies that are compatible with U.S. economic self-interests. These policies primarily spur voluntary private sector abatement through efficient innovation policy and GHG transparency.
We offer three sets of recommendations moving forward for influencers of the climate policy agenda:
- Focus on results. Climate change abatement is a function of global GHG concentrations. Too much attention pursues symbolic objectives, like preventing fossil fuel infrastructure. This tends to undermine abatement goals and impose high costs.
- Emphasize cost considerations in policy agenda setting, formulation, and maintenance. Negative abatement cost policies should take top priority, with an emphasis on mobilizing beneficiaries. Robust cost-benefit analyses should precede all cost-additive policies and be reconducted periodically to guide policy adjustments.
- Prioritize quality state capacity. The net benefits of abatement policies are sensitive to government capacity and performance. Public management is in great jeopardy in an era of institutional decay. Negative-cost policies are often highly technocratic and require sufficient staffing expertise and accountable management at public institutions like DOE, FERC, PSCs, and permitting and siting agencies.
In an era of energy affordability precedence, a reset climate agenda should anchor itself in good policy basics. That is, a sober-minded return to results-driven, net-benefits prioritized policy. This should improve the durability of climate policy and ensure it enhances social welfare. Executing reforms well requires a recommitment to improving the quality of institutions as much as the policy itself.