Collaborative Intelligence: Harnessing Crowd Forecasting for National Security
“The decisions that humans make can be extraordinarily costly. The wars in Iraq and Afghanistan were multi-trillion dollar decisions. If you can improve the accuracy of forecasting individual strategies by just a percentage point, that would be worth tens of billions of dollars.” – Jason Matheny, CEO, RAND Corporation
Predicting the future—a notoriously hard problem—is a core function of the Office of the Director of National Intelligence (ODNI). Crowd forecasting methods offer a systematic approach to quantifying the U.S. intelligence community’s uncertainty about the future and predicting the impact of interventions, allowing decision-makers to strategize effectively and allocate resources by outlining risks and tradeoffs in a legible format. We propose that ODNI leverage its earlier investments in crowd-forecasting research to enhance intelligence analysis and interagency coordination. Specifically, ODNI should develop a next-generation crowd-forecasting program that balances academic rigor with policy relevance. To do this, we propose partnering a Federally Funded Research and Development Center (FFRDC) with crowd forecasting experience with executive branch agencies to generate high-value forecasting questions and integrate targeted forecasts into existing briefing and decision-making processes. Crucially, end users (e.g. from the NSC, DoD, etc.) should be embedded in the question-generation process in order to ensure that the forecasts are policy-relevant. This approach has the potential to significantly enhance the quality and impact of intelligence analysis, leading to more robust and informed national security decisions.
Challenge & Opportunity
ODNI is responsible for the daunting task of delivering insightful, actionable intelligence in a world of rapidly evolving threats and unprecedented complexity. Traditional analytical methods, while valuable, struggle to keep pace with the speed and intricacy of global events where dynamic reports are necessary. Crowd forecasting provides infrastructure for building shared understanding across the Intelligence Community (IC) with a very low barrier to entry. Through the process, each agency can share their assessments of likely outcomes and planned actions based on their intelligence, to be aggregated alongside other agencies. These techniques can serve as powerful tools for interagency coordination within the IC, quickly surfacing areas of consensus and disagreement. By building upon the foundation of existing Intelligence Advanced Research Projects Activity (IARPA) crowd forecasting research — including IARPA’s Aggregative Contingent Estimation (ACE) tournament and Hybrid Forecasting Competition (HFC) — ODNI has within its reach significant low-hanging fruit for improving the quality of its intelligence analysis and the use of this analysis to inform decision-making.
Despite the IC’s significant investment in research demonstrating the potential of crowd forecasting, integrating these approaches into decision-making processes has proven difficult. The first-generation forecasting competitions showed significant returns from basic cognitive debiasing training, above and beyond the benefits of crowd forecast aggregation. Yet, attempts to incorporate forecasting training and probabilistic estimates into intelligence analysis have fallen flat due in large part to internal politics. Accordingly, the incentives within and among agencies must be considered in order for any forecasting program to deliver value. Importantly, any new crowd forecasting initiative should be explicitly rolled out as a complement, not a substitute, to traditional intelligence analysis.
Plan of Action
The incoming administration should direct the Office of the Director of National Intelligence (ODNI) to resume its study and implementation of crowd forecasting methods for intelligence analysis. The following recommendations illustrate how this can be done effectively.
Recommendation 1. Develop a Next-Generation Crowd Forecasting Program
Direct a Federally Funded Research and Development Center (FFRDC) experienced with crowd forecasting methods, such as MITRE’s National Security Engineering Center (NSEC) or the RAND Forecasting Initiative (RFI), to develop a next-generation pilot program.
Prior IARPA studies of crowd-sourced intelligence were focused on the question: How accurate is the wisdom of the crowds on geopolitical questions? To answer this, the IARPA tournaments posed many forecasting questions, rapid-fire, over a relatively short period of time, and these questions were optimized for easy generation and resolution (i.e. straightforward data-driven questions) — at the expense of policy relevance. A next-generation forecasting program should build upon recent research on eliciting from experts the crucial questions that illuminate key uncertainties, point to important areas of disagreement, and estimate the impact of interventions under consideration.
This program should:
- Incorporate lessons learned from previous IARPA forecasting tournaments, including difficulties with getting buy-in from leadership to incentivize the participation of busy analysts and decision-makers at ODNI.
- Develop a framework for generating questions that balance rigor, resolvability, and policy relevance.
- Implement advanced aggregation and scoring methods, leveraging recent academic research and machine learning methods.
Recommendation 2. Embed the Decision-Maker in the Question Generation Process
Direct the FFRDC to work directly with one or more executive branch partners to embed end users in the process of eliciting policy-relevant forecasting questions. Potential executive branch partners could include the National Security Council, Department of Defense, Department of State, and Department of Homeland Security, among others.
A formal process for question generation and refinement should be established, which could include:
- A structured methodology for transforming policy questions of interest into specific, quantifiable forecasting questions.
- A review process to ensure that questions meet criteria for both forecasting suitability and policy relevance.
- Mechanisms for rapid question development in response to emerging crises or sudden shifts.
- Feedback mechanisms to refine and improve question quality over time, with a focus on policy relevance and decision-maker user experience.
Recommendation 3. Integrate Forecasts into Decision-Making Processes
Ensure that resulting forecasts are actively reviewed by decision-makers and integrated into existing intelligence and policy-making processes.
This could involve:
- Incorporating forecast results into regular intelligence briefings, as a quantitative supplement to traditional qualitative assessments.
- Developing visualizations/dashboards (Figure 1) to enable decision-makers to explore the reasoning, drivers of disagreement, unresolved uncertainties and changes in forecasts over time.
- Organizing training sessions for senior leadership on how to interpret and use probabilistic forecasts in decision-making.
- Establishing a simple, formal process by which policymakers can request forecasts on questions relevant to their work.
- Creating a review process to assess how forecasts influenced decisions and their outcomes.
- Using forecast as a tool for interagency coordination, to surface ideas and concerns that people may be hesitant to bring up in front of their superiors.
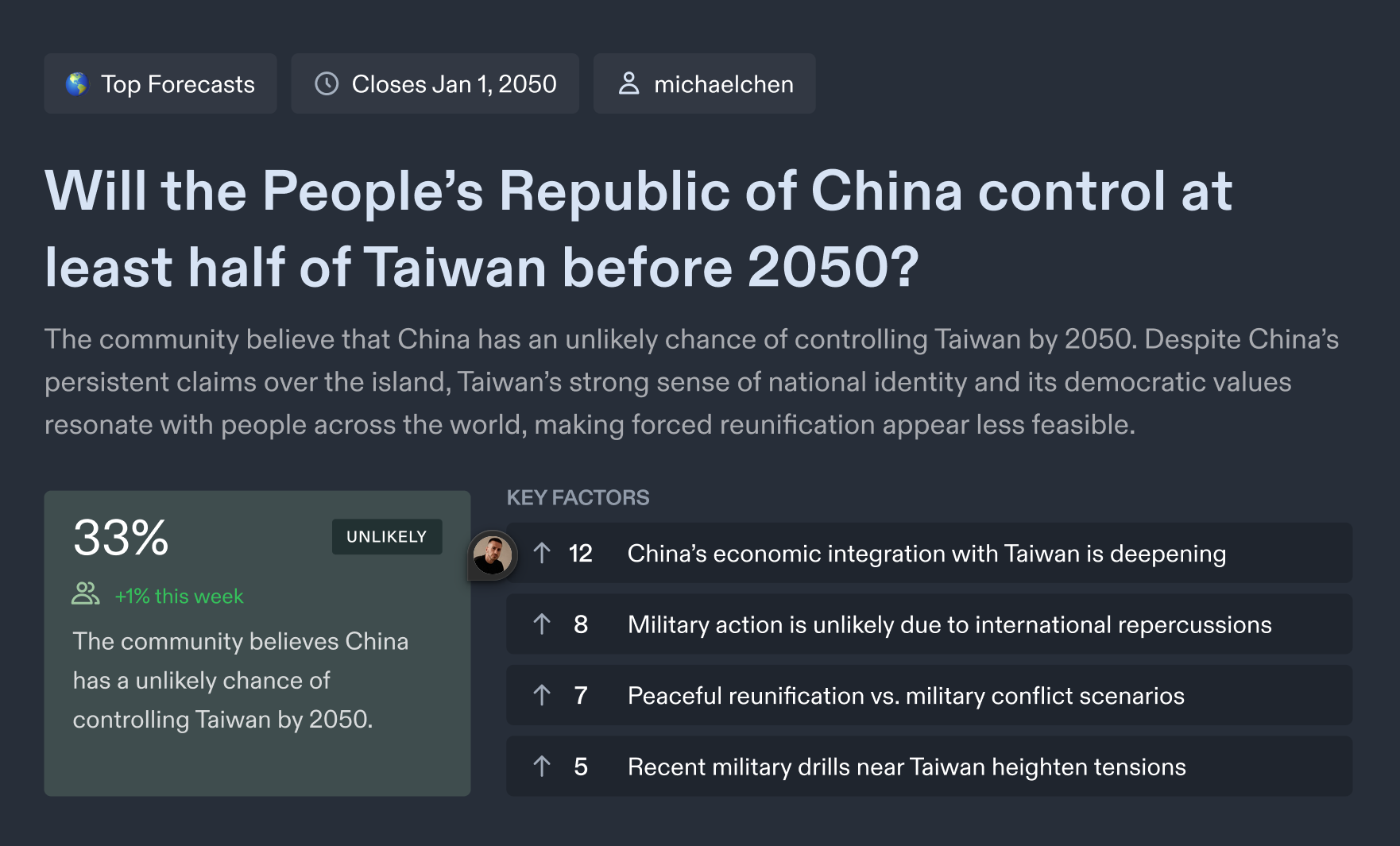
Figure 1. Example of prototype forecasting dashboards for end-users, highlighting key factors and showing trends in the aggregate forecast over time. (Source: Metaculus)
Conclusion
ODNI’s mission to “deliver the most insightful intelligence possible” demands continuous innovation. The next-generation forecasting program outlined in this document is the natural next step in advancing the science of forecasting to serve the public interest. Crowd forecasting has proven itself as a generator of reliable predictions, more accurate than any individual forecaster. In an increasingly complex information environment, our intelligence community needs to use every tool at its disposal to identify and address its most pressing questions about the future. By establishing a transparent and rigorous crowd-forecasting process, ODNI can harness the collective wisdom of diverse experts and analysts and foster better interagency collaboration, strengthening our nation’s ability to anticipate and respond to emerging global challenges.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
Expected Utility Forecasting for Science Funding
The typical science grantmaker seeks to maximize their (positive) impact with a limited amount of money. The decision-making process for how to allocate that funding requires them to consider the different dimensions of risk and uncertainty involved in science proposals, as described in foundational work by economists Chiara Franzoni and Paula Stephan. The Von Neumann-Morgenstern utility theorem implies that there exists for the grantmaker — or the peer reviewer(s) assessing proposals on their behalf — a utility function whose expected value they will seek to maximize.
Common frameworks for evaluating proposals leave this utility function implicit, often evaluating aspects of risk, uncertainty, and potential value independently and qualitatively. Empirical work has suggested that such an approach may lead to biases, resulting in funding decisions that deviate from grantmakers’ ultimate goals. An expected utility approach to reviewing science proposals aims to make that implicit decision-making process explicit, and thus reduce biases, by asking reviewers to directly predict the probability and value of different potential outcomes occurring. Implementing this approach through forecasting brings the added benefits of providing (1) a resolution and scoring process that could help incentivize reviewers to make better, more accurate predictions over time and (2) empirical estimates of reviewers’ accuracy and tendency to over or underestimate the value and probability of success of proposals.
At the Federation of American Scientists, we are currently piloting this approach on a series of proposals in the life sciences that we have collected for Focused Research Organizations (FROs), a new type of non-profit research organization designed to tackle challenges that neither academia or industry is incentivized to work on. The pilot study was developed in collaboration with Metaculus, a forecasting platform and aggregator, and is hosted on their website. In this paper, we provide the detailed methodology for the approach that we have developed, which builds upon Franzoni and Stephan’s work, so that interested grantmakers may adapt it for their own purposes. The motivation for developing this approach and how we believe it may help address biases against risk in traditional peer review processes is discussed in our article “Risk and Reward in Peer Review”.
Defining Outcomes
To illustrate how an expected utility forecasting approach could be applied to scientific proposal evaluation, let us first imagine a research project consisting of multiple possible outcomes or milestones. In the most straightforward case, the outcomes that could arise are mutually exclusive (i.e., only a single one will be observed). Indexing each outcome with the letter 𝑖, we can define the expected value of each as the product of its value (or utility; 𝓊𝑖) and the probability of it occurring, 𝑃(𝑚𝑖). Because the outcomes in this example are mutually exclusive, the total expected utility (TEU) of the proposed project is the sum of the expected value of each outcome1:
𝑇𝐸𝑈 = 𝛴𝑖𝓊𝑖𝑃(𝑚𝑖).
However, in most cases, it is easier and more accurate to define the range of outcomes of a research project as a set of primary and secondary outcomes or research milestones that are not mutually exclusive, and can instead occur in various combinations.
For instance, science proposals usually highlight the primary outcome(s) that they aim to achieve, but may also involve important secondary outcome(s) that can be achieved in addition to or instead of the primary goals. Secondary outcomes can be a research method, tool, or dataset produced for the purpose of achieving the primary outcome; a discovery made in the process of pursuing the primary outcome; or an outcome that researchers pivot to pursuing as they obtain new information from the research process. As such, primary and secondary outcomes are not necessarily mutually exclusive. In the simplest scenario with just two outcomes (either two primary or one primary and one secondary), the total expected utility becomes
𝑇𝐸𝑈 = 𝓊1𝑃(𝑚1⋂ not 𝑚2) + 𝓊2𝑃(𝑚2⋂ not 𝑚1) + (𝓊1 + 𝓊2)𝑃(𝑚1⋂𝑚2),
𝑇𝐸𝑈 = 𝓊1𝑃(𝑚1) – (𝑚1⋂ 𝑚2)) + 𝓊2𝑃(𝑚2) – 𝑃(𝑚1⋂ 𝑚2)) + (𝓊1 + 𝓊2)𝑃(𝑚1⋂𝑚2)
𝑇𝐸𝑈 = 𝓊1𝑃(𝑚1) + 𝓊2𝑃(𝑚2) – (𝓊1 + 𝓊2)𝑃(𝑚1⋂𝑚2).
As the number of outcomes increases, the number of joint probability terms increases as well. Assuming the outcomes are independent though, they can be reduced to the product of the probabilities of individual outcomes. For example,
𝑃(𝑚1⋂𝑚2) = 𝑃(𝑚1) * 𝑃(𝑚2)
On the other hand, milestones are typically designed to build upon one another, such that achieving later milestones necessitates the achievement of prior milestones. In these cases, the value of later milestones typically includes the value of prior milestones: for example, the value of demonstrating a complete pilot of a technology is inclusive of the value of demonstrating individual components of that technology. The total expected utility can thus be defined as the sum of the product of the marginal utility of each additional milestone and its probability of success:
𝑇𝐸𝑈 = 𝛴𝑖(𝓊𝑖 + 𝓊𝑖-1)𝑃(𝑚𝑖),
where 𝓊0 = 0.
Depending on the science proposal, either of these approaches — or a combination — may make the most sense for determining the set of outcomes to evaluate.
In our FRO Forecasting pilot, we worked with proposal authors to define two outcomes for each of their proposals. Depending on what made the most sense for each proposal, the two outcomes reflected either relatively independent primary and secondary goals, or sequential milestone outcomes that directly built upon one another (though for simplicity, we called all of the outcomes milestones).
Defining Probability of Success
Once the set of potential outcomes have been defined, the next step is to determine the probability of success between 0% and 100% for each outcome if the proposal is funded. A prediction of 50% would indicate the highest level of uncertainty about the outcome, whereas the closer the predicted probability of success is to 0% or 100%, the more certainty there is that the outcome will be one over the other.
Furthermore, Franzoni and Stephan decompose probability of success into two components: the probability that the outcome can actually occur in nature or reality and the probability that the proposed methodology will succeed in obtaining the outcome (conditional on it being possible in nature). The total probability is then the product of these two components:
𝑃(𝑚𝑖) = 𝑃nature(𝑚𝑖) * 𝑃proposal(𝑚𝑖)
Depending on the nature of the proposal (e.g., more technology-driven, or more theoretical/discovery driven), each component may be more or less relevant. For example, our forecasting pilot includes a proposal to perform knockout validation of renewable antibodies for 10,000 to 15,000 human proteins; for this project, 𝑃nature(𝑚𝑖) approaches 1 and 𝑃proposal(𝑚𝑖) drives the overall probability of success.
Defining Utility
Similarly, the value of an outcome can be separated into its impact on the scientific field and its impact on society at large. Scientific impact aims to capture the extent to which a project advances the frontiers of knowledge, enables new discoveries or innovations, or enhances scientific capabilities or methods. Social impact aims to capture the extent to which a project contributes to solving important societal problems, improving well-being, or advancing social goals.
In both of these cases, determining the value of an outcome entails some subjective preferences, so there is no “correct” choice, at least mathematically speaking. However, proxy metrics may be helpful in considering impact. Though each is imperfect, one could consider citations of papers, patents on tools or methods, or users of method, tools, and datasets as proxies of scientific impact. For social impact, some proxy metrics that one might consider are the value of lives saved, the cost of illness prevented, the number of job-years of employment generated, economic output in terms of GDP, or the social return on investment.
The approach outlined by Franzoni and Stephan asks reviewers to assess scientific and social impact on a linear scale (0-100), after which the values can be averaged to determine the overall impact of an outcome. However, we believe that an exponential scale better captures the tendency in science for a small number of research projects to have an outsized impact and provides more room at the top end of the scale for reviewers to increase the rating of the proposals that they believe will have an exceptional impact.
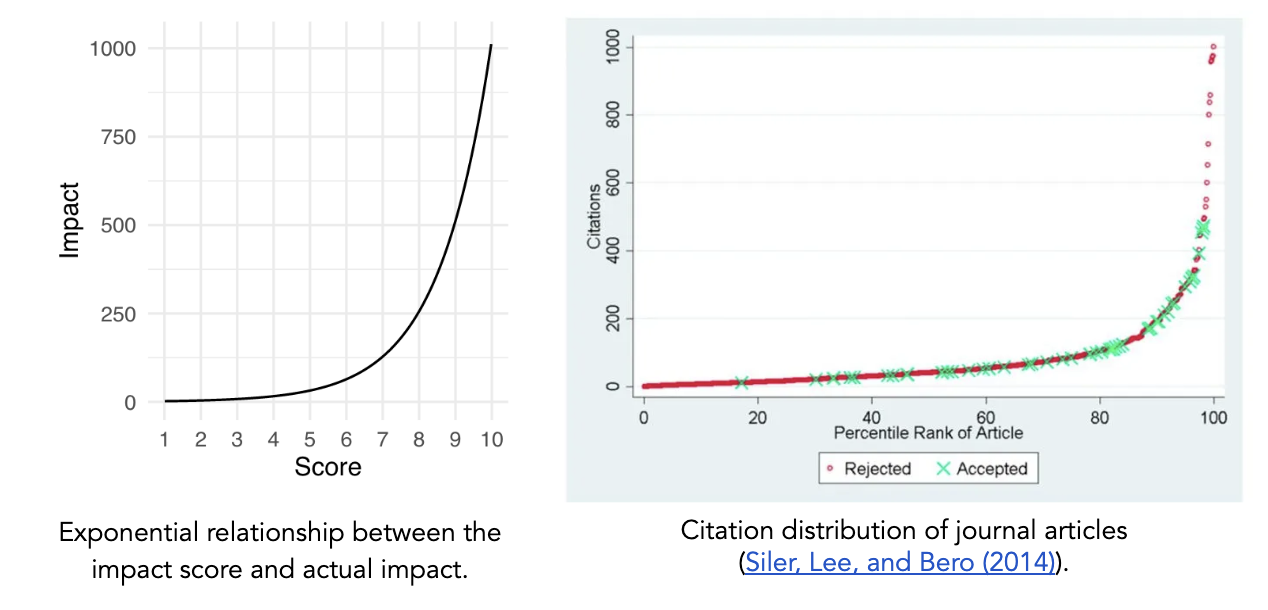
As such, for our FRO Forecasting pilot, we chose to use a framework in which a simple 1–10 score corresponds to real-world impact via a base 2 exponential scale. In this case, the overall impact score of an outcome can be calculated according to
𝓊𝑖 = log[2science impact of 𝑖 + 2social impact of 𝑖] – 1.
For an exponential scale with a different base, one would substitute that base for two in the above equation. Depending on each funder’s specific understanding of impact and the type(s) of proposals they are evaluating, different relationships between scores and utility could be more appropriate.
In order to capture reviewers’ assessment of uncertainty in their evaluations, we asked them to provide median, 25th, and 75th percentile predictions for impact instead of a single prediction. High uncertainty would be indicated by a narrow confidence interval, while low uncertainty would be indicated by a wide confidence interval.
Determining the “But For” Effect of Funding
The above approach aims to identify the highest impact proposals. However, a grantmaker may not want to simply fund the highest impact proposals; rather, they may be most interested in understanding where their funding would make the highest impact — i.e., their “but for” effect. In this case, the grantmaker would want to fund proposals with the maximum difference between the total expected utility of the research proposal if they chose to funded it versus if they chose not to:
“But For” Impact = 𝑇𝐸𝑈(funding) – 𝑇𝐸𝑈(no funding).
For TEU(funding), the probability of the outcome occurring with this specific grantmaker’s funding using the proposed approach would still be defined as above
𝑃(𝑚𝑖 | funding) = 𝑃nature(𝑚𝑖) * 𝑃proposal(𝑚𝑖),
but for 𝑇𝐸𝑈(no funding), reviewers would need to consider the likelihood of the outcome being achieved through other means. This could involve the outcome being realized by other sources of funding, other researchers, other approaches, etc. Here, the probability of success without this specific grantmaker’s funding could be described as
𝑃(𝑚𝑖 | no funding) = 𝑃nature(𝑚𝑖) * 𝑃other mechanism(𝑚𝑖).
In our FRO Forecasting pilot, we assumed that 𝑃other mechanism(𝑚𝑖) ≈ 0. The theory of change for FROs is that there exists a set of research problems at the boundary of scientific research and engineering that are not adequately supported by traditional research and development models and are unlikely to be pursued by academia or industry. Thus, in these cases it is plausible to assume that,
𝑃(𝑚𝑖 | no funding) ≈ 0
𝑇𝐸𝑈(no funding) ≈ 0
“But For” Impact ≈ 𝑇𝐸𝑈(funding).
This assumption, while not generalizable to all contexts, can help reduce the number of questions that reviewers have to consider — a dynamic which we explore further in the next section.
Designing Forecasting Questions
Once one has determined the total expected utility equation(s) relevant for the proposal(s) that they are trying to evaluate, the parameters of the equation(s) must be translated into forecasting questions for reviewers to respond to. In general, for each outcome, reviewers will need to answer the following four questions:
- If this proposal is funded, what is the probability that this outcome will occur?
- If this proposal is not funded, what is the probability that this outcome will still occur?
- What will be the scientific impact of this outcome occurring?
- What will be the social impact of this outcome occurring?
For the probability questions, one could alternatively ask reviewers about the different probability components (𝑃nature(𝑚𝑖), 𝑃proposal(𝑚𝑖), 𝑃other mechanism(𝑚𝑖), etc.), but in most cases it will be sufficient — and simpler for the reviewer — to focus on the top-level probabilities that feed into the TEU calculation.
In order for the above questions to tap into the benefits of the forecasting framework, they must be resolvable. Resolving the forecasting questions means that at a set time in the future, reviewers’ predictions will be compared to a ground truth based on the actual events that have occurred (i.e., was the outcome actually achieved and, if so, what was its actual impact?). Consequently, reviewers will need to be provided with the resolution date and the resolution criteria for their forecasts.
Resolution of the probability-based questions hinges mostly on a careful and objective definition of the potential outcomes, and is otherwise straightforward — though note that only one of the probability questions will be resolved, since they are mutually exclusive. The optimal resolution of the scientific and social impact questions may depend on the context of the project and the chosen approach to defining utility. A widely applicable approach is to resolve the utility forecasts by having either program managers or subject matter experts evaluate the results of the completed project and score its impact at the resolution date.
For our pilot, we asked forecasting questions only about the probability of success given funding (question 1 above) and the scientific and social impact of each outcome (questions 3 and 4); since we assumed that the probability of success without funding was zero, we did not ask question 2. Because outcomes for the FRO proposals were designed to be either independent or sequential, we did not have to ask additional questions on the joint probability of multiple outcomes being achieved. We chose to resolve our impact questions with a post-project panel of subject matter experts.
Additional Considerations
In general, there is a tradeoff in implementing this approach between simplicity and thoroughness, efficiency and accuracy. Here are some additional considerations on that tradeoff for those looking to use this approach:
- The responsibility of determining the range of potential outcomes for a proposal could be assigned to three different parties: the proposal author, the proposal reviewers, or the program manager. First, grantmakers could ask proposal authors to comprehensively define within their proposal the potential primary and secondary outcomes and/or project milestones. Alternatively, reviewers could be allowed to individually — or collectively — determine what they see as the full range of potential outcomes. The third option would be for program managers to define the potential outcomes based on each proposal, with or without input from proposal authors. In our pilot, we chose to use the third approach with input from proposal authors, since it simplified the process for reviewers and allowed us to limit the number of outcomes under consideration to a manageable amount.
- In many cases, a “failed” or null outcome may still provide meaningful value by informing other scientists that the research method doesn’t work or that the hypothesis is unlikely to be true. Considering the replication crises in multiple fields, this could be an important and unaddressed aspect of peer review. Grantmakers could choose to ask reviewers to consider the value of these null outcomes alongside other outcomes to obtain a more complete picture of the project’s utility. We chose not to address this consideration in our pilot for the sake of limiting the evaluation burden on reviewers.
- If grant recipients’ are permitted greater flexibility in their research agendas, this expected value approach could become more difficult to implement, since reviewers would have to consider a wider and more uncertain range of potential outcomes. This was not the case for our FRO Forecasting pilot, since FROs are designed to have specific and well-defined research goals.
Other Similar Efforts
Currently, forecasting is an approach rarely used in grantmaking. Open Philanthropy is the only grantmaking organization we know of that has publicized their use of internal forecasts about grant-related outcomes, though their forecasts do not directly influence funding decisions and are not specifically of expected value. Franzoni and Stephan are also currently piloting their Subjective Expected Utility approach with Novo Nordisk.
Conclusion
Our goal in publishing this methodology is for interested grantmakers to freely adapt it to their own needs and iterate upon our approach. We hope that this paper will help start a conversation in the science research and funding communities that leads to further experimentation. A follow up report will be published at the end of the FRO Forecasting pilot sharing the results and learnings from the project.
Acknowledgements
We’d like to thank Peter Mühlbacher, former research scientist at Metaculus, for his meticulous feedback as we developed this approach and for his guidance in designing resolvable forecasting questions. We’d also like to thank the rest of the Metaculus team for being open to our ideas and working with us on piloting this approach, the process of which has helped refine our ideas to their current state. Any mistakes here are of course our own.
Risk and Reward in Peer Review
This article was written as a part of the FRO Forecasting project, a partnership between the Federation of American Scientists and Metaculus. This project aims to conduct a pilot study of forecasting as an approach for assessing the scientific and societal value of proposals for Focused Research Organizations. To learn more about the project, see the press release here. To participate in the pilot, you can access the public forecasting tournament here.
The United States federal government is the single largest funder of scientific research in the world. Thus, the way that science agencies like the National Science Foundation and the National Institutes of Health distribute research funding has a significant impact on the trajectory of science as a whole. Peer review is considered the gold standard for evaluating the merit of scientific research proposals, and agencies rely on peer review committees to help determine which proposals to fund. However, peer review has its own challenges. It is a difficult task to balance science agencies’ dual mission of protecting government funding from being spent on overly risky investments while also being ambitious in funding proposals that will push the frontiers of science, and research suggests that peer review may be designed more for the former rather than the latter. We at FAS are exploring innovative approaches to peer review to help tackle this challenge.
Biases in Peer Review
A frequently echoed concern across the scientific and metascientific community is that funding agencies’ current approach to peer review of science proposals tends to be overly risk-averse, leading to bias against proposals that entail high risk or high uncertainty about the outcomes. Reasons for this conservativeness include reviewer preferences for feasibility over potential impact, contagious negativity, and problems with the way that peer review scores are averaged together.
This concern, alongside studies suggesting that scientific progress is slowing down, has led to a renewed effort to experiment with new ways of conducting peer review, such as golden tickets and lottery mechanisms. While golden tickets and lottery mechanisms aim to complement traditional peer review with alternate means of making funding decisions — namely individual discretion and randomness, respectively — they don’t fundamentally change the way that peer review itself is conducted.
Traditional peer review asks reviewers to assess research proposals based on a rubric of several criteria, which typically include potential value, novelty, feasibility, expertise, and resources. These criteria are given a score based on a numerical scale; for example, the National Institutes of Health uses a scale from 1 (best) to 9 (worst). Reviewers then provide an overall score that need not be calculated in any specific way based on the criteria scores. Next, all of the reviewers convene to discuss the proposal and submit their final overall scores, which may be different from what they submitted prior to the discussion. The final overall scores are averaged across all of the reviewers for a specific proposal. Proposals are then ranked based on their average overall score and funding is prioritized for those ranked before a certain cutoff score, though depending on the agency, some discretion by program administrators is permitted.
The way that this process is designed allows for the biases mentioned at the beginning—reviewer preferences for feasibility, contagious negativity, and averaging problems—to influence funding decisions. First, reviewer discretion in deciding overall scores allows them to weigh feasibility more heavily than potential impact and novelty in their final scores. Second, when evaluations are discussed reviewers tend to adjust their scores to better align with their peers. This adjustment tends to be greater when correcting in the negative direction than in the positive direction, resulting in a stronger negative bias. Lastly, since funding tends to be quite limited, cutoff scores tend to be quite close to the best score. This means that even if almost all of the reviewers rate a proposal positively, one very negative review can potentially bring the average below the cutoff.
Designing a New Approach to Peer Review
In 2021, the researchers Chiara Franzoni and Paula Stephan published a working paper arguing that risk in science results from three sources of uncertainty: uncertainty of research outcomes, uncertainty of the probability of success, and uncertainty of the value of the research outcomes. To comprehensively and consistently account for these sources of uncertainty, they proposed a new expected utility approach to peer review evaluations, in which reviewers are asked to
- Identify the primary expected outcome of a research proposal and, optionally, a potential secondary outcome;
- Assess the probability between 0 to 1 of achieving each expected outcome (P(j); and
- Assess the value of achieving each expected outcome (uj) on a numerical scale (e.g., 0 to 100).
From this, the total expected utility can be calculated for each proposal and used to rank them.1 This systematic approach addresses the first bias we discussed by limiting the extent to which reviewers’ preferences for more feasible proposals would impact the final score of each proposal.
We at FAS see a lot of potential in Franzoni and Stephan’s expected value approach to peer review, and it inspired us to design a pilot study using a similar approach that aims to chip away at the other biases in review.
To explore potential solutions for negativity bias, we are taking a cue from forecasting by complementing the peer review process with a resolution and scoring process. This means that at a set time in the future, reviewers’ assessments will be compared to a ground truth based on the actual events that have occurred (i.e., was the outcome actually achieved and, if so, what was its actual impact?). Our theory is that if implemented in peer review, resolution and scoring could incentivize reviewers to make better, more accurate predictions over time and provide empirical estimates of a committee’s tendency to provide overly negative (or positive) assessments, thus potentially countering the effects of contagion during review panels and helping more ambitious proposals secure support.
Additionally, we sought to design a new numerical scale for assessing the value or impact of a research proposal, which we call an impact score. Typically, peer reviewers are free to interpret the numerical scale for each criteria as they wish; Franzoni and Stephan’s design also did not specify how the numerical scale for the value of the research outcome should work. We decided to use a scale ranging from 1 (low) to 10 (high) that was base 2 exponential, meaning that a proposal that receives a score of 5 has double the impact of a proposal that receives a score of 4, and quadruple the impact of a proposal that receives a score of 3.
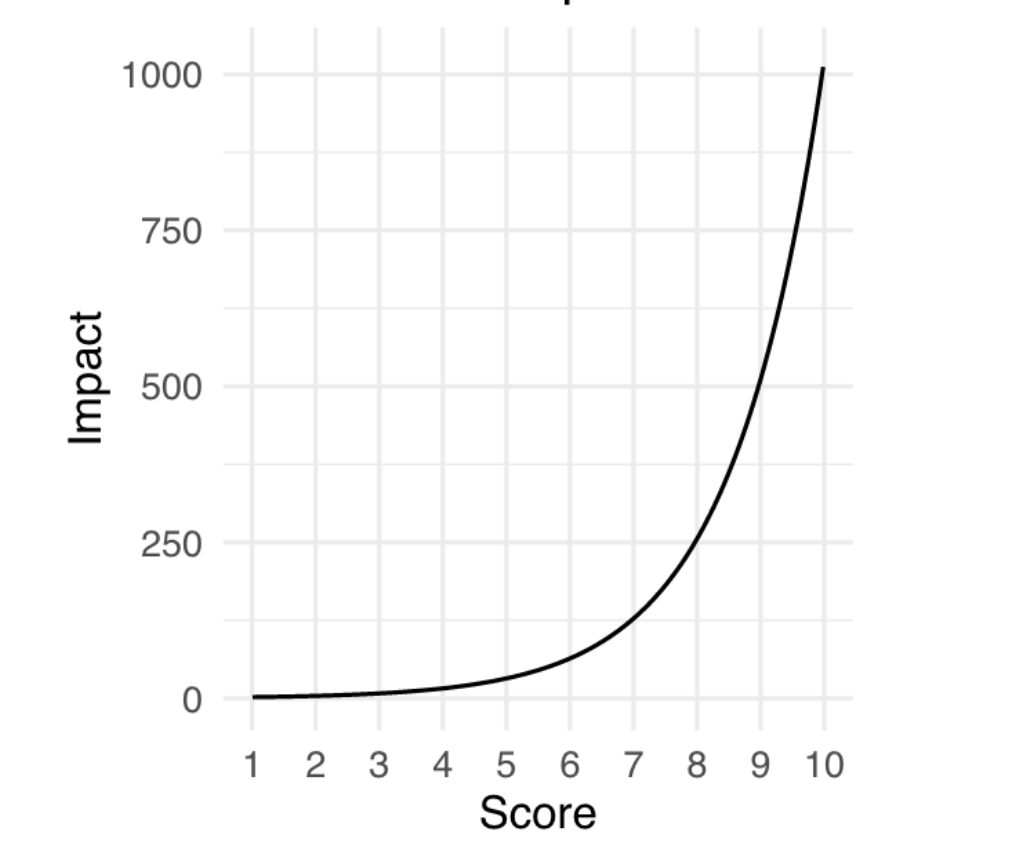
The choice of an exponential scale reflects the tendency in science for a small number of research projects to have an outsized impact (Figure 2), and provides more room at the top end of the scale for reviewers to increase the rating of the proposals that they believe will have an exceptional impact. We believe that this could help address the last bias we discussed, which is that currently, bad scores are more likely to pull a proposal’s average below the cutoff than good scores are likely to pull a proposal’s average above the cutoff.
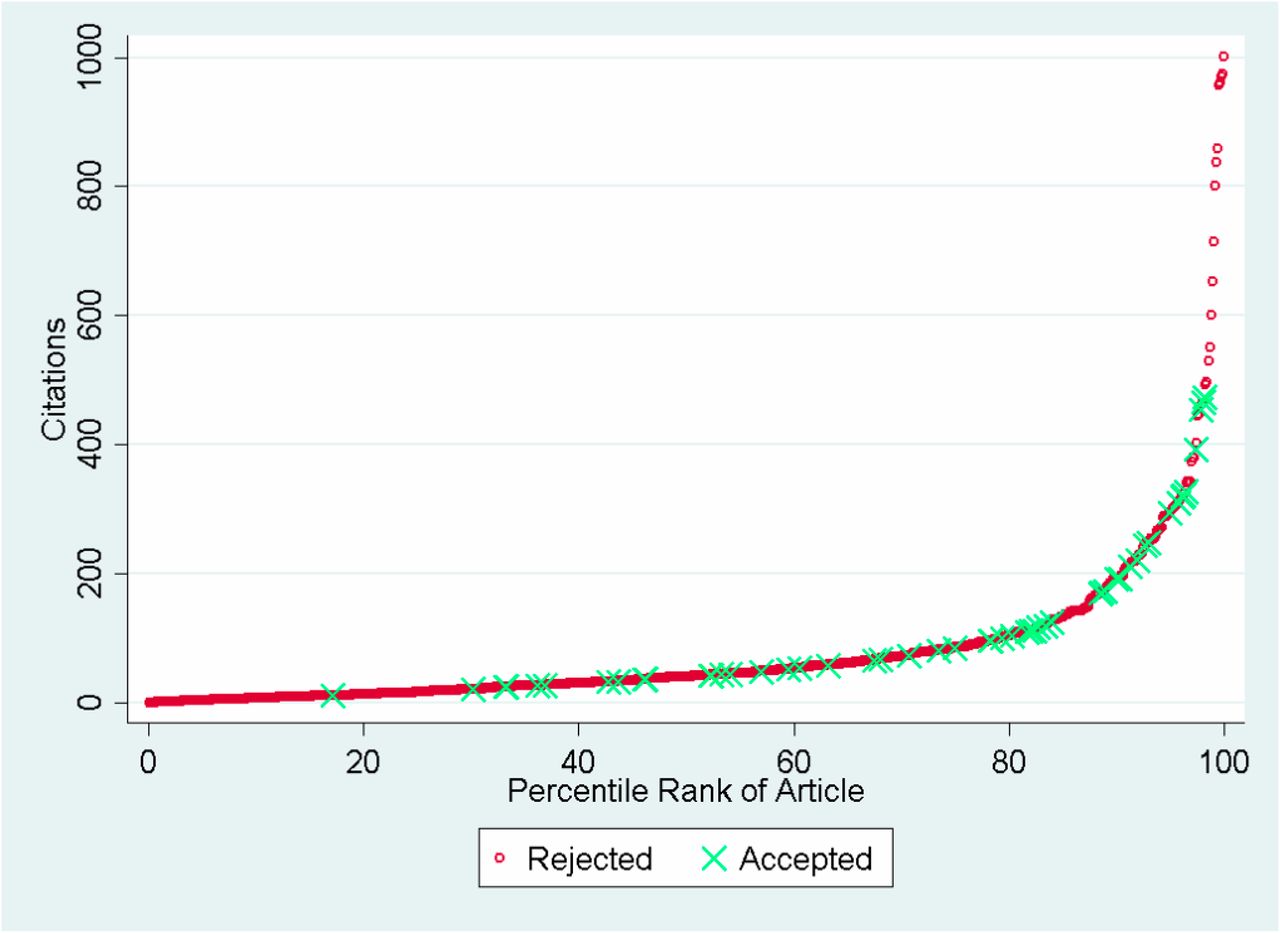
Source: Siler, Lee, and Bero (2014)
We are now piloting this approach on a series of proposals in the life sciences that we have collected for Focused Research Organizations, a new type of non-profit research organization designed to tackle challenges that neither academia or industry is incentivized to work on. The pilot study was developed in collaboration with Metaculus, a forecasting platform and aggregator, and will be hosted on their website. We welcome subject matter experts in the life sciences — or anyone interested! — to participate in making forecasts on these proposals here. Stay tuned for the results of this pilot, which we will publish in a report early next year.