Strengthening Information Integrity with Provenance for AI-Generated Text Using ‘Fuzzy Provenance’ Solutions
Synthetic text generated by artificial intelligence (AI) can pose significant threats to information integrity. When users accept deceptive AI-generated content—such as large-scale false social media posts by malign foreign actors—as factual, national security is put at risk. One way to help mitigate this danger is by giving users a clear understanding of the provenance of the information they encounter online.
Here, provenance refers to any verifiable indication of whether text was generated by a human or by AI, for example by using a watermark. However, given the limitations of watermarking AI-generated text, this memo also introduces the concept of fuzzy provenance, which involves identifying exact text matches that appear elsewhere on the internet. As these matches will not always be available, the descriptor “fuzzy” is used. While this information will not always establish authenticity with certainty, it offers users additional clues about the origins of a piece of text.
To ensure platforms can effectively provide this information to users, the National Institute of Standards and Technology (NIST)’s AI Safety Institute should develop guidance on how to display to users both provenance and fuzzy provenance—where available—within no more than one click. To expand the utility of fuzzy provenance, NIST could also issue guidance on how generative AI companies could allow the records of their free AI models to be crawled and indexed by search engines, thereby making potential matches to AI-generated text easier to discover. Tradeoffs surrounding this approach are explored further in the FAQ section.
By creating a reliable, user-friendly framework for surfacing these details, NIST would empower readers to better discern the trustworthiness of the text they encounter, thereby helping to counteract the risks posed by deceptive AI-generated content.
Challenge and Opportunity
Synthetic Text and Information Integrity
In the past two years, generative AI models have become widely accessible, allowing users to produce customized text simply by providing prompts. As a result, there has been a rapid proliferation of “synthetic” text—AI-generated content—across the internet. As NIST’s Generative Artificial Intelligence Profile notes, this means that there is a “[l]owered barrier of entry to generated text that may not distinguish fact from opinion or fiction or acknowledge uncertainties, or could be leveraged for large scale dis- and mis-information campaigns.”
Information integrity risks stemming from synthetic text—particularly when generated for non-creative purposes—can pose a serious threat to national security. For example, in July 2024 the Justice Department disrupted Russian generative-AI-enabled disinformation bot farms. These Russian bots produced synthetic text, including in the form of social media posts by fake personas, meant to promote messages aligned with the interests of the Russian government.
Provenance Methods For Reducing Information Integrity Risks
NIST has an opportunity to provide community guidance to reduce the information integrity risks posed by all types of synthetic content. The main solution currently being considered by NIST for reducing the risks of synthetic content in general is provenance, which refers to whether a piece of content was generated by AI or a human. As described by NIST, provenance is often ascertained by creating a non-fungible watermark, or a cryptographic signature for a piece of content. The watermark is permanently associated with the piece of content. Where available, provenance information is helpful because knowing the origin of text can help a user know whether to rely on the facts it contains. For example, an AI-generated news report may currently be less trustworthy than a human news report because the former is more prone to fabrications.
However, there are currently no methods widely accepted as effective for determining the provenance of synthetic text. As NIST’s report, Reducing Risks Posed by Synthetic Content, details, “[t]he effectiveness of synthetic text detection is subject to ongoing debate” (Sec. 3.2.2.4). Even if a piece of text is originally AI-generated with a watermark (e.g., by generating words with a unique statistical pattern), people can easily copy a piece of text by paraphrasing (especially via AI), without transferring the original watermark. Text watermarks are also vulnerable to adversarial attacks, with malicious actors able to mimic the watermark signature and make text appear watermarked when it is not.
Plan of Action
To capture the benefits of provenance, while mitigating some of its weaknesses, NIST should issue guidance on how platforms can make available to users both provenance and “fuzzy provenance” of text. Fuzzy provenance is coined here to refer to exact text matches on the internet, which can sometimes reflect provenance but not necessarily (thus “fuzzy”). Optionally, NIST could also consider issuing guidance on how generative AI companies can make their free models’ records available to be crawled and indexed by search engines, so that fuzzy provenance information would show text matches with generative AI model records. There are tradeoffs to this recommendation, which is why it is optional; see FAQs for further discussion. Making both provenance and fuzzy provenance information available (in no more than one click) will give users more information to help them evaluate how trustworthy a piece of text is and reduce information integrity risks.
Combined Provenance and Fuzzy Provenance Approach
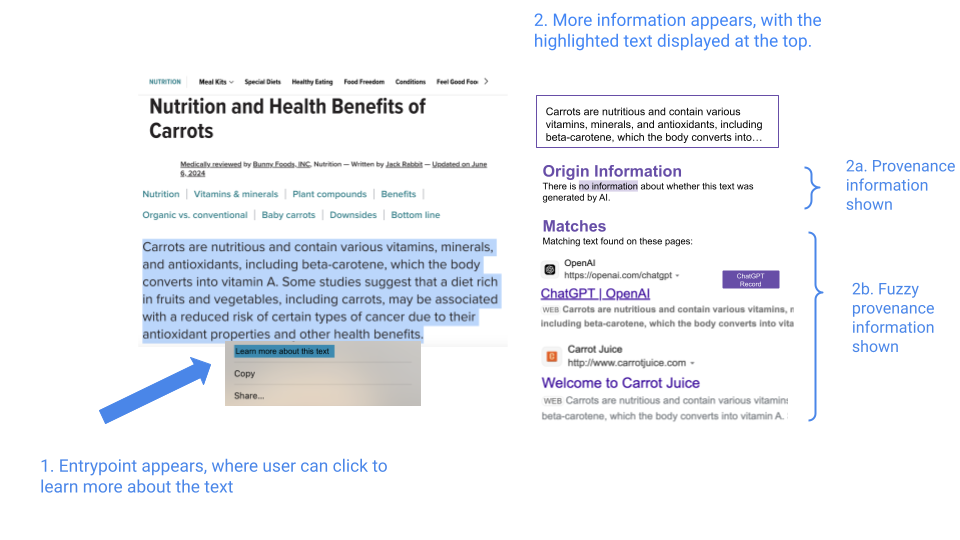
Figure 1. Mock implementation of combined provenance and fuzzy provenance
The above image captures what an implementation of the combined provenance and fuzzy provenance guidance might include. When a user highlights a piece of text that is sufficiently long, they can click “learn more about this text” to find more information.
There are ways to communicate provenance and fuzzy provenance so that it is both useful and easy-to-understand. In this concept showing the provenance of text, for example:
- Provenance information is shown under the heading “Origin Information”. This includes whether there is conclusive metadata (like watermarks) showing the text was generated by AI, according to C2PA standards, where available.
- Fuzzy provenance information is shown under the heading “Matches,” and includes other websites that have an exact text match to the highlighted text, similar to the results that come up when using a search engine. Furthermore, depending on NIST guidance, generative AI companies could have their free models’ records available to be crawled and indexed by search engines. This would enable these records to appear in the results if they contain an exact text match. These records would be clearly labeled (e.g., “ChatGPT Record”) and ranked at the top.
- See the following video for what this might look like for a user: user journeys.
Benefits of the Combined Approach
Showing both provenance and fuzzy provenance information provides users with critical context to evaluate the trustworthiness of a piece of text. Between provenance and fuzzy provenance, users would have access to information about many pieces of high-impact text, especially claims that could be particularly harmful for individuals, groups, or society at large. Making all this information immediately available also reduces friction for users so that they can get this information right where they encounter text.
Provenance information can be helpful to provide to users when it is available. For instance, knowing that a tech support company’s website description was AI-generated may encourage users to check other sources (like reviews) to see if the company is a real entity (and AI was used just to generate the description) or a fake entity entirely, before giving a deposit to hire the company (see user journey 1 in this video for an example).
Where clear provenance information is not available, fuzzy provenance can help fill the gap by providing valuable context to users in several ways:
- First, if there is no exact text match on the internet, it may indicate that the content is original—whether AI-generated or human-created—which can be especially relevant for assessing the trustworthiness of certain documents (see user journey 2 in this video for an example).
- Second, when presented with a misleading claim like “ginger is 10000x more effective than chemotherapy”, seeing that the text matches are from fact-check sites and unreliable sources such as other social media posts can encourage users to further investigate that claim (see user journey 3 in this video for an example).
- Third, absent any text matches from reliable sources, knowing that a claim (e.g., about carrots and cancer) matched an AI model’s record may cause a user to be skeptical, as they may realize that the text has the potential to be false content generated by AI (see user journey 4 in this video for an example).
{kind=link}
Fuzzy provenance is also effective because it shows context and gives users autonomy to decide how to interpret that context. Academic studies have found that users tend to be more receptive when presented with further information they can use for their own critical thinking compared to being shown a conclusion directly (like a label), which can even backfire or be misinterpreted. This is why users may trust contextual methods like crowdsourced information more than provenance labels.
Finally, fuzzy provenance methods are generally feasible at scale, since they can be easily implemented with existing search engine capabilities (via an exact text match search). Furthermore, since fuzzy provenance only relies on exact text matching with other sources on the internet, it works without needing coordination among text-producers or compliance from bad actors.
Conclusion
To reduce the information integrity risks posed by synthetic text in a scalable and effective way, the National Institute for Standards and Technology (NIST) should develop community guidance on how platforms hosting text-based digital content can make accessible (in no more than one click) the provenance and “fuzzy provenance” of the piece of text, when available. NIST should also consider issuing guidance on how AI companies could make their free generative AI records available to be crawled by search engines, to amplify the effectiveness of “fuzzy provenance”.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
Making free generative AI records available to be crawled by search engines includes tradeoffs, which is why it is an optional recommendation to consider. Below are some questions regarding implementation guidance, and trade offs including privacy and proprietary information.
Guidance could instruct AI model companies how to make their free generative AI conversation records available to be crawled and indexed by search engines. Similar to ChatGPT logs or Perplexity threads, a unique URL would be created for each conversation, capturing the date it occurred. The key difference is that all free model conversation records would be made available, but only with the AI outputs of the conversation, after removing personally identifiable information (PII) (see “Privacy considerations” section below). Because users can already choose to share conversations with each other (meaning the conversation logs are retained), and conversation logs for major model providers do not currently appear to have an expiration date, this requirement shouldn’t impose an additional storage burden for AI model companies.
Guidance could instruct search engines how to crawl and index these model logs so that queries with exact text matches to the AI outputs would surface the appropriate model logs. This would not be very different from search engines crawling/indexing other types of new URLs and should be well-within existing search engine capabilities. In terms of storage, since only free model logs would be crawled and indexed, and most free models rate-limit the number of user messages allowed, storage should also not be a concern. For instance, even with 200 million weekly active users for ChatGPT, the number of conversations in a year would only be on the order of billions, which is well-within the current scale that existing search engines have to operate to enable users to “search the web”.
- Output filtering on the AI outputs should be done to remove any personal identifiable information (PII) present in the model’s responses. However, it might still be possible to extrapolate who the original user was just by looking at the AI outputs taken together and inferring some of the user prompts. This is a privacy concern that should be further investigated. Some possible mitigations include additionally removing any location references of a certain granularity (i.e. removing mentions of neighborhoods, but retaining mentions of states) and presenting AI responses in the conversation in a randomized order.
- Removals should be made possible by a user-initiated process demonstrating privacy concerns, similar to existing search engine removal protocols.
- User consent would also be an important consideration here. NIST could propose that free model users must “opt-in”, or that free model record crawling/indexing be “opt-out” by default for users, though this may greatly compromise the reliability of fuzzy provenance.
- Training on AI-generated text: AI companies are concerned about accidentally picking up on too much AI-generated text on the web and training on that instead of higher human-generated text, thus degrading the quality of their own generative models. However, because they would have identifiable domain prefixes (ie chatgpt.com, perplexity.ai), it would be easy to exclude these AI-generated conversation logs if desired during training. Indeed, provenance and fuzzy provenance may help AI companies avoid unintentionally training on AI-generated text.
- Sharing model outputs: On the flipside, AI companies might be concerned that making so many AI-generated model outputs available for competitors to access may result in helping competitors improve their own models. This is a fair concern, though partially mitigated by a) specific user inputs are not available, and only the AI outputs; and b) only free model outputs would be logged, rather than any premium models, thus providing some proprietary protection. However, it is still possible that competitors may be able to enhance their own responses by training on the structure of AI outputs from other models at scale.
Blank Checks for Black Boxes: Bring AI Governance to Competitive Grants
The misuse of AI in federally-funded projects can risk public safety and waste taxpayer dollars.
The Trump administration has a pivotal opportunity to spot wasteful spending, promote public trust in AI, and safeguard Americans from unchecked AI decisions. To tackle AI risks in grant spending, grant-making agencies should adopt trustworthy AI practices in their grant competitions and start enforcing them against reckless grantees.
Federal AI spending could soon skyrocket. One ambitious legislative plan from a Senate AI Working Group calls for doubling non-defense AI spending to $32 billion a year by 2026. That funding would grow AI across R&D, cybersecurity, testing infrastructure, and small business support.
Yet as federal AI investment accelerates, safeguards against snake oil lag behind. Grants can be wasted on AI that doesn’t work. Grants can pay for untested AI with unknown risks. Grants can blur the lines of who is accountable for fixing AI’s mistakes. And grants offer little recourse to those affected by an AI system’s flawed decisions. Such failures risk exacerbating public distrust of AI, discouraging possible beneficial uses.
Oversight for federal grant spending is lacking, with:
- No AI-specific policies vetting discretionary grants
- Varying AI expertise on grant judging panels
- Unclear AI quality standards set by grantmaking agencies
- Little-to-no pre- or post-award safeguards that identify and monitor high-risk AI deployments.
Watchdogs, meanwhile, play a losing game, chasing after errant programs one-by-one only after harm has been done. Luckily, momentum is building for reform. Policymakers recognize that investing in untrustworthy AI erodes public trust and stifles genuine innovation. Steps policymakers could take include setting clear AI quality standards, training grant judges, monitoring grantee’s AI usage, and evaluating outcomes to ensure projects achieve their potential. By establishing oversight practices, agencies can foster high-potential projects for economic competitiveness, while protecting the public from harm.
Challenge and Opportunity
Poor AI Oversight Jeopardizes Innovation and Civil Rights
The U.S. government advances public goals in areas like healthcare, research, and social programs by providing various types of federal assistance. This funding can go to state and local governments or directly to organizations, nonprofits, and individuals. When federal agencies award grants, they typically do so expecting less routine involvement than they would with other funding mechanisms, for example cooperative agreements. Not all federal grants look the same—agencies administer mandatory grants, where the authorizing statute determines who receives funding, and competitive grants (or “discretionary grants”), where the agency selects award winners. In competitive grants, agencies have more flexibility to set program-specific conditions and award criteria, which opens opportunities for policymakers to structure how best to direct dollars to innovative projects and mitigate emerging risks.
These competitive grants fall short on AI oversight. Programmatic policy is set in cross-cutting laws, agency-wide policies, and grant-specific rules; a lack of AI oversight mars all three. To date, no government-wide AI regulation extends to AI grantmaking. Even when President Biden’s 2023 AI Executive Order directed agencies to implement responsible AI practices, the order’s implementing policies exempted grant spending (see footnote 25) entirely from the new safeguards. In this vacuum, the 26 grantmaking agencies are on their own to set agency-wide policies. Few have. Agencies can also set AI rules just for specific funding opportunities. They do not. In fact, in a review of a large set of agency discretionary grant programs, only a handful of funding notices announced a standard for AI quality in a proposed program. (See: One Bad NOFO?) The net result? A policy and implementation gap for the use of AI in grant-funded programs.
Funding mistakes damage agency credibility, stifle innovation, and undermines the support for people and communities financial assistance aims to provide. Recent controversies highlight how today’s lax measures—particularly in setting clear rules for federal financial assistance, monitoring how they are used, and responding to public feedback—have led to inefficient and rights-trampling results. In just the last few years, some of the problems we have seen include:
- The Department of Housing and Urban Development set few rules on a grant to protect public housing residents, letting officials off the hook when they bought facial recognition cameras to surveil and evict residents.
- Senators called for a pause on predictive policing grants, finding the Department of Justice failed to check that their grantees’ use of AI complied with civil rights laws—the same laws on which the grant awards were conditioned.
- The National Institute of Justice issued a recidivism forecasting challenge which researchers argued “incentivized exploiting the metrics used to judge entrants, leading to the development of trivial solutions that could not realistically work in practice.”
Any grant can attract controversy, and these grants are no exception. But the cases above spotlight transparency, monitoring, and participation deficits—the same kinds of AI oversight problems weakening trust in government that policymakers aim to fix in other contexts.
Smart spending depends on careful planning. Without it, programs may struggle to drive innovation or end up funding AI that infringes peoples’ rights. OMB, as well as agency Inspectors General, and grant managers will need guidance to evaluate what money is going towards AI and how to implement effective oversight. Government will face tradeoffs and challenges promoting AI innovation in federal grants, particularly due to:
1) The AI Screening Problem. When reviewing applications, agencies might fail to screen out candidates that exaggerate their AI capabilities—or fail to report bunk AI use altogether. Grantmaking requires calculated risks on ideas that might fail. But grant judges who are not experts in AI can make bad bets. Applicants will pitch AI solutions directly to these non-experts, and grant winners, regardless of their original proposal, will likely purchase and deploy AI, creating additional oversight challenges.
2) The grant-procurement divide. When planning a grant, agencies might set overly burdensome restrictions that dissuade qualified applicants from applying or otherwise take up too much time, getting in the way of grant goals. Grants are meant to be hands-off; fostering breakthroughs while preventing negligence will be a challenging needle to thread.
3) Limited agency capacity. Agencies may be unequipped to monitor grant recipients’ use of AI. After awarding funding, agencies can miss when vetted AI breaks down on launch. While agencies audit grantees, those audits typically focus on fraud and financial missteps. In some cases, agencies may not be measuring grantee performance well at all (slides 12-13). Yet regular monitoring, similar to the oversight used in procurement, will be necessary to catch emergent problems that affect AI outcomes. Enforcement, too, could be cause for concern; agencies clawback funds for procedural issues, but “almost never withhold federal funds when grantees are out of compliance with the substantive requirements of their grant statutes.” Even as the funding agency steps away, an inaccurate AI system can persist, embedding risks over a longer period of time.
Plan of Action
Recommendation 1. OMB and agencies should bake-in pre-award scrutiny through uniform requirements and clearer guidelines
- Agencies should revise funding notices to require applicants disclose plans to use AI, with a greater level of disclosure required for funding in a foreseeable high-risk context. Agencies should take care not to overburden applicants with disclosures on routine AI uses, particularly as the tools grow in popularity. States may be a laboratory to watch for policy innovation; Illinois, for example, has proposed AI disclosure policies and penalties for its state grants.
- Agencies should make AI-related grant policies clearer to prospective applicants. Such a change would be consistent with OMB policy and the latest Uniform Guidance, the set of rules OMB sets for agencies to manage their grants. For example, in grant notices, any AI-related review criteria should be plainly stated, rather than inferred from a project’s description. Any AI restrictions should be spelled out too, not merely incorporated by reference. More generally, agencies should consider simplifying grant notices, publishing yearly AI grant priorities, hosting information sessions, and/or extending public comment periods to significant AI-related discretionary spending.
- Agencies could consider generally-applicable metrics with which to evaluate applicants’ suggested AI uses. For example, agencies may require applicants to demonstrate they have searched for less discriminatory algorithms in the development of an automated system.
- OMB could formally codify pre-award AI risk assessments in the Uniform Guidance, the set of rules OMB sets for agencies to manage their grants. OMB updates its guidance periodically (with the most recent updates in 2024) and can also issue smaller revisions.
- Agencies could also provide resources targeted at less established AI developers, who might otherwise struggle to meet auditing and compliance standards.
Recommendation 2. OMB and grant marketplaces should coordinate information sharing between agencies
To support review of AI-related grants, OMB and grantmaking agency staff should pool knowledge on AI’s tricky legal, policy, and technical matters.
- OMB, through its Council on Federal Financial Assistance, should coordinate information-sharing between grantmaking agencies on AI risks.
- The White House Office of Science and Technology Policy, the National Institute of Standards and Technology, and the Administrative Conference of the United States (ACUS) should support agencies by devising what information agencies should collect on their grantee’s use of AI so as to limit administrative burden on grantees.
- OMB can share expertise on monitoring and managing grant risks, best practices and guides, and trade offs; other relevant interagency councils can share grant evaluation criteria and past performance templates across agencies.
- Online grants marketplaces, such as the Grants Quality Service Management Office Marketplace operated by the Department of Health and Human Services, should improve grantmakers’ decisions by sharing AI-specific information like an applicants’ AI quality, audit and enforcement history, where applicable.
Recommendation 3. Agencies should embrace targeted hiring and talent exchanges for grant review boards
Agencies should have experts in a given AI topic judging grant competitions. To do so requires overcoming talent acquisition challenges. To that end:
- Agency Chief AI Officers should assess grant office needs as part of their OMB-required assessments on AI talent. Those officers should also include grant staff in any AI trainings, and, when prudent, agency-wide risk assessment meetings
- Agencies should staff review boards with technical experts through talent exchanges and targeted hiring.
- OMB should coordinate drop-in technical experts who can sit in as consultants across agencies.
- OMB should support the training of federal grants staff on matters that touch AI– particularly as surveyed grant managers see training as an area of need.
Recommendation 4. Agencies should step up post-award monitoring and enforcement
You can’t improve what you don’t measure—especially when it comes to AI. Quantifying, documenting, and enforcing against careless AI uses can be a new task for grantmaking agencies. Incident reporting will improve the chances that existing cross-cutting regulations, including civil rights laws, can reel back AI gone awry.
- Congress can delegate investigative authority to agencies with AI audit expertise. Such an effort might mirror the cross-agency approach taken by the Department of Justice’s Procurement Collusion Strike Force, which investigates antitrust crimes in procurement and grantmaking.
- Congress can require agencies to cut off funds when grantees show repeated or egregious violations of grant terms pertaining to AI use. Agencies, where authorized, should voluntarily enforce against repeat bad players through spending clawbacks, cutoffs or ban lists.
- Agencies should consider introducing dispute resolution procedures that give redress to enforced-upon grantees.
Recommendation 5. Agencies should encourage and fund efforts to investigate and measure AI harms
- Agencies should invest in establishing measurement and standards within their topic areas on which to evaluate prospective applicants. For example, the National Institute of Justice recently opened funding to research evaluating the use of AI in the criminal legal system.
- Agencies should follow through on longstanding calls to encourage public whistleblowing on grantee missteps, particularly around AI.
- Agencies should solicit feedback from the public through RFIs on grants.gov on how to innovate in AI in their specific research or topic area.
Conclusion
Little limits how grant winners can spend federal dollars on AI. With the government poised to massively expand its spending on AI, that should change.
The federal failure to oversee AI use in grants erodes public trust, civil rights, effective service delivery and the promise of government-backed innovation. Congressional efforts to remedy these problems–starting probes, drafting letters–are important oversight measures, but only come after the damage is done.
Both the Trump and Biden administrations have recognized that AI is exceptional and needs exceptional scrutiny. Many of the lessons learned from scrutinizing federal agency AI procurement apply to grant competitions. Today’s confluence of public will, interest, and urgency is a rare opportunity to widen the aperture of AI governance to include grantmaking.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
Enabling statutes for agencies often are the authority for grant competitions. For grant competitions, the statutory language leaves it to agencies to place further specific policies on the competition. Additionally, laws, like the DATA Act and Federal Grant and Cooperative Agreement Act, offer definitions and guidance to agencies in the use of federal funds.
Agencies already conduct a great deal of pre-award planning to align grantmaking with Executive Orders. For example, in one survey of grantmakers, a little over half of respondents updated their pre-award processes, such as applications and organization information, to comply with an Executive Order. Grantmakers aligning grant planning with the Trump administration’s future Executive Orders will likely follow similar steps.
A wide range of states, local governments, companies, and individuals receive grant competition funds. Spending records, available on USASpending.gov, give some insight into where grant funding goes, though these records too, can be incomplete.
Fighting Fakes and Liars’ Dividends: We Need To Build a National Digital Content Authentication Technologies Research Ecosystem
The U.S. faces mounting challenges posed by increasingly sophisticated synthetic content. Also known as digital media ( images, audio, video, and text), increasingly, these are produced or manipulated by generative artificial intelligence (AI). Already, there has been a proliferation in the abuse of generative AI technology to weaponize synthetic content for harmful purposes, such as financial fraud, political deepfakes, and the non-consensual creation of intimate materials featuring adults or children. As people become less able to distinguish between what is real and what is fake, it has become easier than ever to be misled by synthetic content, whether by accident or with malicious intent. This makes advancing alternative countermeasures, such as technical solutions, more vital than ever before. To address the growing risks arising from synthetic content misuse, the National Institute of Standards and Technology (NIST) should take the following steps to create and cultivate a robust digital content authentication technologies research ecosystem: 1) establish dedicated university-led national research centers, 2) develop a national synthetic content database, and 3) run and coordinate prize competitions to strengthen technical countermeasures. In turn, these initiatives will require 4) dedicated and sustained Congressional funding of these initiatives. This will enable technical countermeasures to be able to keep closer pace with the rapidly evolving synthetic content threat landscape, maintaining the U.S.’s role as a global leader in responsible, safe, and secure AI.
Challenge and Opportunity
While it is clear that generative AI offers tremendous benefits, such as for scientific research, healthcare, and economic innovation, the technology also poses an accelerating threat to U.S. national interests. Generative AI’s ability to produce highly realistic synthetic content has increasingly enabled its harmful abuse and undermined public trust in digital information. Threat actors have already begun to weaponize synthetic content across a widening scope of damaging activities to growing effect. Project losses from AI-enabled fraud are anticipated to reach up to $40 billion by 2027, while experts estimate that millions of adults and children have already fallen victim to being targets of AI-generated or manipulated nonconsensual intimate media or child sexual abuse materials – a figure that is anticipated to grow rapidly in the future. While the widely feared concern of manipulative synthetic content compromising the integrity of the 2024 U.S. election did not ultimately materialize, malicious AI-generated content was nonetheless found to have shaped election discourse and bolstered damaging narratives. Equally as concerning is the accumulative effect this increasingly widespread abuse is having on the broader erosion of public trust in the authenticity of all digital information. This degradation of trust has not only led to an alarming trend of authentic content being increasingly dismissed as ‘AI-generated’, but has also empowered those seeking to discredit the truth, or what is known as the “liar’s dividend”.
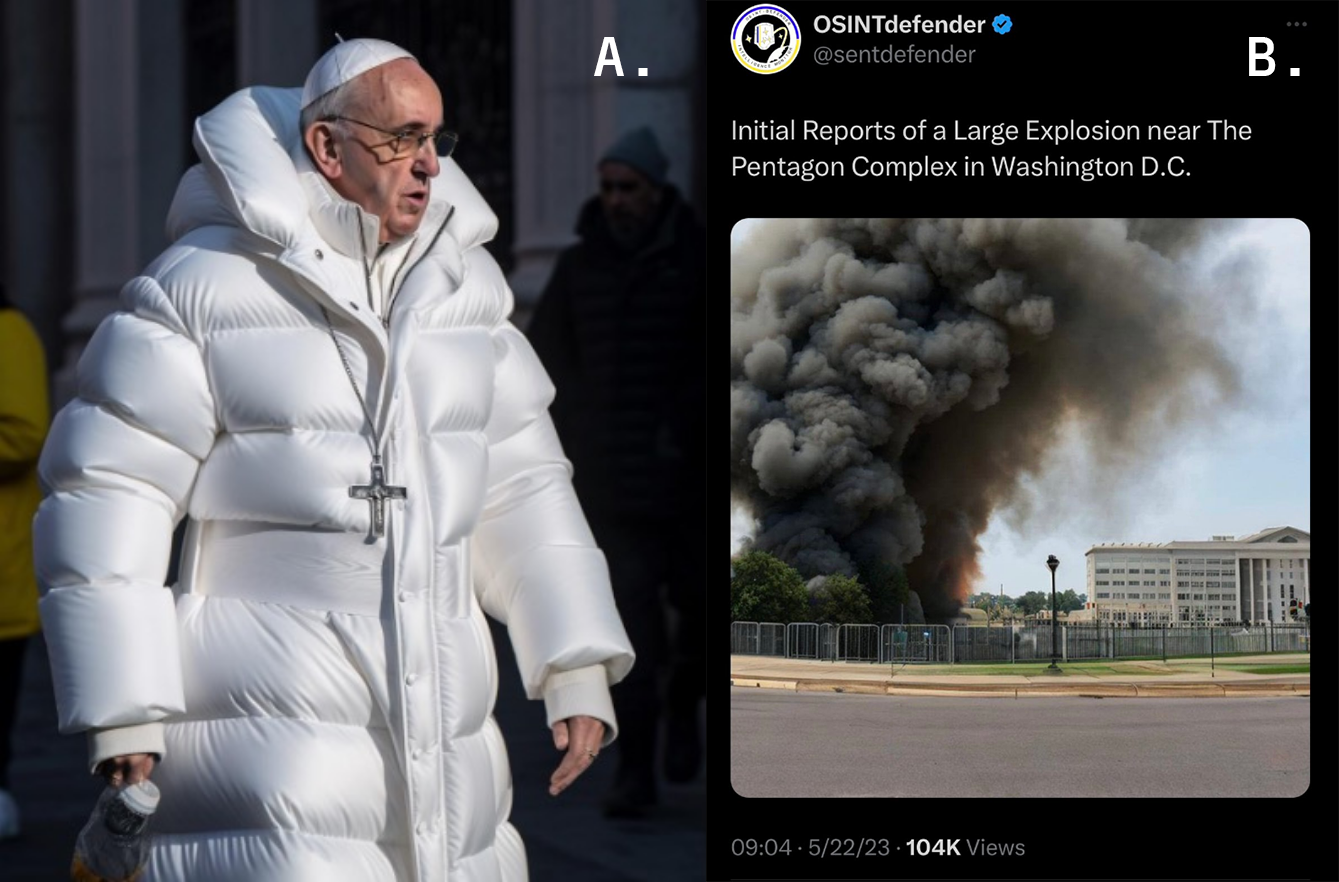
A. In March 2023, a humorous synthetic image of Pope Francis, first posted on Reddit by creator Pablo Xavier, wearing a Balenciaga coat quickly went viral across social media.
B. In May 2023, this synthetic image was duplicitously published on X as an authentic photograph of an explosion near the Pentagon. Before being debunked by authorities, the image’s widespread circulation online caused significant confusion and even led to a temporary dip in the U.S. stock market.
Research has demonstrated that current generative AI technology is able to produce synthetic content sufficiently realistic enough that people are now unable to reliably distinguish between AI-generated and authentic media. It is no longer feasible to continue, as we currently do, to rely predominantly on human perception capabilities to protect against the threat arising from increasingly widespread synthetic content misuse. This new reality only increases the urgency of deploying robust alternative countermeasures to protect the integrity of the information ecosystem. The suite of digital content authentication technologies (DCAT), or techniques, tools, and methods that seek to make the legitimacy of digital media transparent to the observer, offers a promising avenue for addressing this challenge. These technologies encompass a range of solutions, from identification techniques such as machine detection and digital forensics to classification and labeling methods like watermarking or cryptographic signatures. DCAT also encompasses technical approaches that aim to record and preserve the origin of digital media, including content provenance, blockchain, and hashing.
Evolution of Synthetic Media

Published in 2018, this now infamous PSA sought to illustrate the dangers of synthetic content. It shows an AI-manipulated video of President Obama, using narration from a comedy sketch by comedian Jordan Peele.

In 2020, a hobbyist creator employed an open-source generative AI model to ‘enhance’ the Hollywood CGI version of Princess Leia in the film Rouge One.

The hugely popular Tiktok account @deeptomcruise posts parody videos featuring a Tom Cruise imitator face-swapped with the real Tom Cruise’s real face, including this 2022 video, racking up millions of views.

The 2024 film Here relied extensively on generative AI technology to de-age and face-swap actors in real-time as they were being filmed.
Robust DCAT capabilities will be indispensable for defending against the harms posed by synthetic content misuse, as well as bolstering public trust in both information systems and AI development. These technical countermeasures will be critical for alleviating the growing burden on citizens, online platforms, and law enforcement to manually authenticate digital content. Moreover, DCAT will be vital for enforcing emerging legislation, including AI labeling requirements and prohibitions on illegal synthetic content. The importance of developing these capabilities is underscored by the ten bills (see Fig 1) currently under Congressional consideration that, if passed, would require the employment of DCAT-relevant tools, techniques, and methods.
However, significant challenges remain. DCAT capabilities need to be improved, with many currently possessing weaknesses or limitations such brittleness or security gaps. Moreover, implementing these countermeasures must be carefully managed to avoid unintended consequences in the information ecosystem, like deploying confusing or ineffective labeling to denote the presence of real or fake digital media. As a result, substantial investment is needed in DCAT R&D to develop these technical countermeasures into an effective and reliable defense against synthetic content threats.
The U.S. government has demonstrated its commitment to advancing DCAT to reduce synthetic content risks through recent executive actions and agency initiatives. The 2023 Executive Order on AI (EO 14110) mandated the development of content authentication and tracking tools. Charged by the EO 14110 to address these challenges, NIST has taken several steps towards advancing DCAT capabilities. For example, NIST’s recently established AI Safety Institute (AISI) takes the lead in championing this work in partnership with NIST’s AI Innovation Lab (NAIIL). Key developments include: the dedication of one of the U.S. Artificial Intelligence Safety Institute Consortium’s (AISIC) working groups to identifying and advancing DCAT R&D; the publication of NIST AI 100-4, which “examines the existing standards, tools, methods, and practices, as well as the potential development of further science-backed standards and techniques” regarding current and prospective DCAT capabilities; and the $11 million dedicated to international research on addressing dangers arising from synthetic content announced at the first convening of the International Network of AI Safety Institutes. Additionally, NIST’s Information Technology Laboratory (ITL) has launched the GenAI Challenge Program to evaluate and advance DCAT capabilities. Meanwhile, two pending bills in Congress, the Artificial Intelligence Research, Innovation, and Accountability Act (S. 3312) and the Future of Artificial Intelligence Innovation Act (S. 4178), include provisions for DCAT R&D.
Although these critical first steps have been taken, an ambitious and sustained federal effort is necessary to facilitate the advancement of technical countermeasures such as DCAT. This is necessary to more successfully combat the risks posed by synthetic content—both in the immediate and long-term future. To gain and maintain a competitive edge in the ongoing race between deception and detection, it is vital to establish a robust national research ecosystem that fosters agile, comprehensive, and sustained DCAT R&D.
Plan of Action
NIST should engage in three initiatives: 1) establishing dedicated university-based DCAT research centers, 2) curating and maintaining a shared national database of synthetic content for training and evaluation, as well as 3) running and overseeing regular federal prize competitions to drive innovation in critical DCAT challenges. The programs, which should be spearheaded by AISI and NAIIL, are critical for enabling the creation of a robust and resilient U.S. DCAT research ecosystem. In addition, the 118th Congress should 4) allocate dedicated funding to supporting these enterprises.
These recommendations are not only designed to accelerate DCAT capabilities in the immediate future, but also to build a strong foundation for long-term DCAT R&D efforts. As generative AI capabilities expand, authentication technologies must too keep pace, meaning that developing and deploying effective technical countermeasures will require ongoing, iterative work. Success demands extensive collaboration across technology and research sectors to expand problem coverage, maximize resources, avoid duplication, and accelerate the development of effective solutions. This coordinated approach is essential given the diverse range of technologies and methodologies that must be considered when addressing synthetic content risks.
Recommendation 1. Establish DCAT Research Institutes
NIST should establish a network of dedicated university-based research to scale up and foster long-term, fundamental R&D on DCAT. While headquartered at leading universities, these centers would collaborate with academic, civil society, industry, and government partners, serving as nationwide focal points for DCAT research and bringing together a network of cross-sector expertise. Complementing NIST’s existing initiatives like the GenAI Challenge, the centers’ research priorities would be guided by AISI and NAIIL, with expert input from the AISIC, the International Network of AISI, and other key stakeholders.
A distributed research network offers several strategic advantages. It leverages elite expertise from industry and academia, and having permanent institutions dedicated to DCAT R&D enables the sustained, iterative development of authentication technologies to better keep pace with advancing generative AI capabilities. Meanwhile, central coordination by AISI and NAIIL would also ensure comprehensive coverage of research priorities while minimizing redundant efforts. Such a structure provides the foundation for a robust, long-term research ecosystem essential for developing effective countermeasures against synthetic content threats.
There are multiple pathways via which dedicated DCAT research centers could be stood up. One approach is direct NIST funding and oversight, following the model of Carnegie Mellon University’s AI Cooperative Research Center. Alternatively, centers could be established through the National AI Research Institutes Program, similar to the University of Maryland’s Institute for Trustworthy AI in Law & Society, leveraging NSF’s existing partnership with NIST.
The DCAT research agenda could be structured in two ways. Informed by NIST’s report NIST AI 100-4, a vertical approach could be taken to centers’ research agendas, assigning specific technologies to each center (e.g. digital watermarking, metadata recording, provenance data tracking, or synthetic content detection). Centers would focus on all aspects of a specific technical capability, including: improving the robustness and security of existing countermeasures; developing new techniques to address current limitations; conducting real-world testing and evaluation, especially in a cross-platform environment; and studying interactions with other technical safeguards and non-technical countermeasures like regulations or educational initiatives. Conversely, a horizontal approach might seek to divide research agendas across areas such as: the advancement of multiple established DACT techniques, tools, and methods; innovation of novel techniques, tools, and methods; testing and evaluation of combined technical approaches in real-world settings; examining the interaction of multiple technical countermeasures with human factors such as label perception and non-technical countermeasures. While either framework provides a strong foundation for advancing DCAT capabilities, given institutional expertise and practical considerations, a hybrid model combining both approaches is likely the most feasible option.
Recommendation 2. Build and Maintain a National Synthetic Content Database
NIST should also build and maintain a national database of synthetic content database to advance and accelerate DCAT R&D, similar to existing federal initiatives such as NIST’s National Software Reference Library and NSF’s AI Research Resource pilot. Current DCAT R&D is severely constrained by limited access to diverse, verified, and up-to-date training and testing data. Many researchers, especially in academia, where a significant portion of DCAT research takes place, lack the resources to build and maintain their own datasets. This results in less accurate and more narrowly applicable authentication tools that struggle to keep pace with rapidly advancing AI capabilities.
A centralized database of synthetic and authentic content would accelerate DCAT R&D in several critical ways. First, it would significantly alleviate the effort on research teams to generate or collect synthetic data for training and evaluation, encouraging less well-resourced groups to conduct research as well as allowing researchers to focus more on other aspects of R&D. This includes providing much-needed resources for the NIST-facilitated university-based research centers and prize competitions proposed here. Moreover, a shared database would be able to provide more comprehensive coverage of the increasingly varied synthetic content being created today, permitting the development of more effective and robust authentication capabilities. The database would be useful for establishing standardized evaluation metrics for DCAT capabilities – one of NIST’s critical aims for addressing the risks posed by AI technology.
A national database would need to be comprehensive, encompassing samples of both early and state-of-the-art synthetic content. It should have controlled laboratory-generated along with verified “in the wild” or real world synthetic content datasets, including both benign and potentially harmful examples. Further critical to the database’s utility is its diversity, ensuring synthetic content spans multiple individual and combined modalities (text, image, audio, video) and features varied human populations as well as a variety of non-human subject matter. To maintain the database’s relevance as generative AI capabilities continue to evolve, routinely incorporating novel synthetic content that accurately reflects synthetic content improvements will also be required.
Initially, the database could be built on NIST’s GenAI Challenge project work, which includes “evolving benchmark dataset creation”, but as it scales up, it should operate as a standalone program with dedicated resources. The database could be grown and maintained through dataset contributions by AISIC members, industry partners, and academic institutions who have either generated synthetic content datasets themselves or, as generative AI technology providers, with the ability to create the large-scale and diverse datasets required. NIST would also direct targeted dataset acquisition to address specific gaps and evaluation needs.
Recommendation 3. Run Public Prize Competitions on DCAT Challenges
Third, NIST should set up and run a coordinated prize competition program, while also serving as federal oversight leads for prize competitions run by other agencies. Building on existing models such as the DARPA SemaFor’s AI FORCE and the FTC’s Voice Cloning challenge, the competitions would address expert-identified priorities as informed by the AISIC, International Network of AISI, and proposed DCAT national research centers. Competitions represent a proven approach to spurring innovation for complex technical challenges, enabling the rapid identification of solutions through diverse engagement. In particular, monetary prize competitions are especially successful at ensuring engagement. For example, the 2019 Kaggle Deepfake Detection competition, which had a prize of $1 million, fielded twice as many participants as the 2024 competition, which gave no cash prize.
By providing structured challenges and meaningful incentives, public competitions can accelerate the development of critical DCAT capabilities while building a more robust and diverse research community. Such competitions encourage novel technical approaches, rapid testing of new methods, facilitate the inclusion of new or non-traditional participants, and foster collaborations. The more rapid-cycle and narrow scope of the competitions would also complement the longer-term and broader research being conducted by the national DCAT research centers. Centralized federal oversight would also prevent the implementation gaps which have occurred in past approved federal prize competitions. For instance, the 2020 National Defense Authorization Act (NDAA) authorized a $5 million machine detection/deepfakes prize competition (Sec. 5724), and the 2024 NDAA authorized a ”Generative AI Detection and Watermark Competition” (Sec. 1543). However, neither prize competition has been carried out, and Watermark Competition has now been delayed to 2025. Centralized oversight would also ensure that prize competitions are run consistently to address specific technical challenges raised by expert stakeholders, encouraging more rapid development of relevant technical countermeasures.
Some examples of possible prize competitions might include: machine detection and digital forensic methods to detect partial or fully AI-generated content across single or multimodal content; assessing the robustness, interoperability, and security of watermarking and other labeling methods across modalities; testing innovations in tamper-evident or -proofing content provenance tools and other data origin techniques. Regular assessment and refinement of competition categories will ensure continued relevance as synthetic content capabilities evolve.
Recommendation 4. Congressional Funding of DCAT Research and Activities
Finally, the 118th Congress should allocate funding for these three NIST initiatives in order to more effectively establish the foundations of a strong DCAT national research infrastructure. Despite widespread acknowledgement of the vital role of technical countermeasures in addressing synthetic content risks, the DCAT research field remains severely underfunded. Although recent initiatives, such as the $11 million allocated to the International Network of AI Safety Institutes, are a welcome step in the right direction, substantially more investment is needed. Thus far, the overall financing of DCAT R&D has been only a drop in the bucket when compared to the many billions of dollars being dedicated by industry alone to improve generative AI technology.
This stark disparity between investment in generative AI versus DCAT capabilities presents an immediate opportunity for Congressional action. To address the widening capability gap, and to support pending legislation which will be reliant on technical countermeasures such as DCAT, the 118th Congress should establish multi-year appropriations with matching fund requirements. This will encourage private sector investment and permit flexible funding mechanisms to address emerging challenges. This funding should be accompanied by regular reporting requirements to track progress and impact.
One specific action that Congress could take to jumpstart DCAT R&D investment would be to reauthorize and appropriate the budget that was earmarked for the unexecuted machine detection competition it approved in 2020. Despite the 2020 NDAA authorizing $5 million for it, no SAC-D funding was allocated, and the competition never took place. Another action would be for Congress to explicitly allocate prize money for the watermarking competition authorized by the 2024 NDAA, which currently does not have any monetary prize attached to it, to encourage higher levels of participation in the competition when it takes place this year.
Conclusion
The risks posed by synthetic content present an undeniable danger to U.S. national interests and security. Advancing DCAT capabilities is vital for protecting U.S. citizens against both the direct and more diffuse harms resulting from the proliferating misuse of synthetic content. A robust national DCAT research ecosystem is required to accomplish this. Critically, this is not a challenge that can be addressed through one-time solutions or limited investment—it will require continuous work and dedicated resources to ensure technical countermeasures keep pace alongside increasingly sophisticated synthetic content threats. By implementing these recommendations with sustained federal support and investment, the U.S. will be able to more successfully address current and anticipated synthetic content risks, further reinforcing its role as a global leader in responsible AI use.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
An Agenda for Ensuring Child Safety in the AI Era
The next administration should continue to make responsible policy on Artificial intelligence (AI) and children, especially in K-12, a top priority and create an AI and Kids Initiative led by the administration. AI is transforming how children learn and live, and policymakers, industry, and educators owe it to the next generation to set in place a responsible policy that embraces this new technology while at the same time ensuring all children’s well-being, privacy, and safety is respected. The federal government should develop clear prohibitions, enforce them, and serve as a national clearinghouse for AI K-12 educational policy. It should also support comprehensive digital literacy related to AI.
Specifically, we think these policy elements need to be front of mind for decision-makers: build a coordinated framework for AI Safety; champion legislation to support youth privacy and online safety in AI; and ensure every child can benefit from the promise of AI.
In terms of building a coordinated framework for AI Safety, the next administration should: ensure parity with existing child data protections; develop safety guidance for developers, including specific prohibitions to limit harmful designs, and inappropriate uses; and direct the National Institute of Standards and Technology (NIST) to serve as the lead organizer for federal efforts on AI safety for children. When championing legislation to support youth privacy and online safety in AI, the next administration should support the passage of online safety laws that address harmful design features that can lead to medically recognized mental health disorders and patterns of use indicating addiction-like behavior, and modernize federal children’s privacy laws including updating The Family Educational Rights and Privacy Act (FERPA) and passing youth privacy laws to explicitly address AI data use issues, including prohibiting developing commercial models from students’ educational information, with strong enforcement mechanisms. And, in order to ensure every child can benefit from the promise of AI, the next administration should support comprehensive digital literacy efforts and prevent deepening the digital divide.
Importantly, policy and frameworks need to have teeth and need to take the burden off of individual states, school districts, or actors to assess AI tools for children. Enforcement should be tailored to specific laws, but should include as appropriate private rights of action, well-funded federal enforcers, and state and local enforcement. Companies should feel incentivized to act. The framework cannot be voluntary, enabling companies to pick and choose whether or not to follow recommendations.. We’ve seen what happens when we do not put in place guardrails for tech, such as increased risk of child addiction, depression and self-harm–and it should not happen again. We cannot say that this is merely a nascent technology and that we can delay the development of protections. We already know AI will critically impact our lives. We’ve watched tech critically impact lives and AI-enabled tech is both faster and potentially more extreme.
Challenge and Opportunity
AI is already embedded in children’s lives and education. According to Common Sense Media research, seven in ten teens have used generative AI, and the most common use is for help with homework. The research also found most parents are in the dark about their child’s generative AI use–only a third of parents whose children reported using generative AI were aware of such use. Beyond generative AI, machine learning systems are embedded in just about every application kids use at school and at home. Further, most teens and parents say schools have either no AI policy or have not communicated one.
Educational uses of AI are recognized to pose higher risk, according to the EU Artificial Intelligence Act and other international frameworks. The EU recognized that risk management requires special consideration when an AI system is likely to be accessed by children. The U.S. has developed a risk management framework, but the U.S. has not yet articulated risk levels or developed a specific educational or youth profile using NIST’s Risk Management Framework. There is still a deep need to ensure that AI systems likely to be accessed by children, including in schools, to be assessed in terms of risk management and impact on youth.
It is well established that children and teenagers are vulnerable to manipulation by technology. Youth report struggling to set boundaries from technology, and according to a U.S. Surgeon General report, almost a third of teens say they are on social media almost constantly. Almost half of youth say social media has reduced their attention span, and takes time away from other activities they care about. They are unequipped to assess sophisticated and targeted advertising, as most children cannot distinguish ads from content until they are at least eight years old, and most children do not realize ads can be customized. Additionally, social media design features lead, in addition to addiction, to teens suffering other mental or physical harm: from unattainable beauty filters to friend comparison to recommendation systems that promote harmful content, such as the algorithmic promotion of viral “challenges” that can lead to death. AI technology is particularly concerning given its novelness, and the speed and autonomy at which the technology can operate, and the frequent opacity even to developers of AI systems about how inputs and outputs may be used or exposed.
Particularly problematic uses of AI in products used in education and/or by children so far include products that use emotion detection, biometric data, facial recognition (built from scraping online images that include children), companion AI, automated education decisions, and social scoring. This list will continue to grow as AI is further adopted.
There are numerous useful frameworks and toolkits from expert organizations like EdSafe, and TeachAI, and from government organizations like NIST, the National Telecommunications and Information Administration (NTIA), and Department of Education (ED). However, we need the next administration to (1) encourage Congress to pass clear rules regarding AI products used with children, (2) have NIST develop risk management frameworks specifically addressing use of AI in education and by children more broadly, and serve as a clearinghouse function so individual actors and states do not bear that responsibility, and (3) ensure frameworks are required and prohibitions are enforced. This is also reflected in the lack of updated federal privacy and safety laws that protect children and teens.
Plan of Action
The federal government should take note of the innovative policy ideas bubbling up at the state level. For example, there is legislation and proposals in Colorado, California, Texas, and detailed guidance in over 20 states, including Ohio, Alabama, and Oregon.
Policymakers should take a multi-pronged approach to address AI for children and learning, recognizing they are higher risk and therefore additional layers of protection should apply:
Recommendation 1. Build a coordinated framework an AI Safety and Kids Initiative at NIST
As the federal government further details risk associated with uses of AI, common uses of AI by kids should be designated or managed as high risk. This is a foundational step to support the creation of guardrails or ensure protections for children as they use AI systems. The administration should clearly categorize education and use by children with in a risk level framework. For example, the EU is also considering risk in AI with the EU AI Act, which has different risk levels. If the risk framework includes education and AI systems that are likely to be accessed by children it provides a strong signal to policymakers at the state and federal level that these are uses that require protections (audits, transparency, or enforcement) to prevent or address potential harm.
NIST, in partnership with others, should develop risk management profiles for platform developers building AI products for use in Education and for products likely to be accessed by children. Emphasis should be on safety and efficacy before technology products come to market, with audits throughout development. NIST should:
- Develop a committee with ED,, FTC, and CPSC, to periodically update of risk management framework (RMF) profiles, including benchmarking standards related to safety.
- Refine risk levels and RMFs relevant to education, working in in partnership with NTIA and ED, through an open call to stakeholders.
Work in partnership with NTIA, FTC, CPSC, and HHS to refine risk levels and risk management profiles for AI systems likely to be accessed by children.
The administration should task NIST’s Safety Institute to provide clarity on how safety should be considered for the use of AI in education and for AI systems likely to be accessed by children. This is accomplished through:
- Developer guidance: Promulgate safety guidance for developers of AI systems likely to be accessed by children or used in education
- Procurement guidance: In collaboration with the Dept of Education to provide guidance on safety, efficacy, and privacy to support educational procurement of AI systems
- Information clearinghouse: To support state bodies and other entities developing guidance on use of AI systems by serving as a clearinghouse for information on the state of AI systems, developments in efficacy and safety, and to highlight through periodic reporting the concerns of and needs of users.
Recommendation 2. Ensure every child benefits from the promise of AI innovations
The administration should support comprehensive digital literacy and prevent a deepening of the digital divide.
- Highlighting Meaningful Use: Provide periodically updated guidance on best uses available for schools, teachers, students, and caregivers to support their use of AI technology for education.
- Support Professional Development: Dept of Ed and NSF can collaborate on Professional Development guidelines, and flag new areas for teacher training and administer funding to support educator professional development.
- Comprehensive Digital Literacy: NTIA, Dept of Ed should collaborate to administer funds for digital literacy efforts that support both students and caregivers. Digital literacy guidance should support both use and dynamically addresses concerns around current risks or safety issues as they arise.
- Clearinghouse for AI Developments: In addition to funding this work experts in government at NIST, NTIA, FTC, FCC, and Dept of Ed can work collaboratively to periodically alert and inform consumers and digital literacy organizations about developments with AI systems. Federal government can serve as a resource to alert stakeholders downstream on both positive and negative developments, for example the FCC Consumer Advisory Committee was tasked with developing recommendation with a consumer education outreach plan regarding AI generated robocalls.
Recommendation 3. Encourage Congress to pass clear enforceable rules re privacy and safety for AI products used by children
Champion Congressional updates to privacy laws like COPPA and FERPA to address use (especially for training) and sharing of personal information (PI) by AI tools. These laws can work in tandem, see for example recent proposed COPPA updates that would address use of technology in educational settings by children.
- Consumer Protections: In the consumer space, consider requirements generally prohibiting use of children’s PI for training AI models, unless deidentified or aggregated and with consent (see CA AB 2877).
- Education Protections: In education settings, it may be unclear when information about students shared with AI systems is subject to FERPA. Dept of Ed has acknowledged that educational uses of AI models may not be aligned with FERPA or state student privacy laws. FERPA should be updated to explicitly cover personal information collected by and shared with LLMs: covered education records must include this data; sharing of directory information for all purposes including AI should be limited; the statute should address when ed tech vendors operate as “school officials” and generally prohibit training AI models on student personal information.
Push for Congress to pass AI specific legislation addressing the development and deployment of AI systems for use by children
- Address High Risk Uses: Support legislation to prohibit the use of AI systems in high-risk educational contexts, or when likely to be accessed by children, unless committee-identified benchmarks are met. Use of AI in educational contexts and when accessed by children should be default deemed high risk unless it can be demonstrated otherwise. Specific examples of high risks uses in education include AI for threat detection and disciplinary uses, exam proctoring, automated grading and admissions, and generative and companion AI use by minor students.
- Require Third-Party Audits: Support legislation to require third-party audits at the application, model, and governance level, considering functionality, performance, robustness, security and privacy, safety, educational efficacy (as appropriate), accessibility, risks, and mitigation strategies.
- Require Transparency: Support legislation to require transparency reporting by AI developers.
Support Congressional passage of online safety laws that address harmful design features in technology–specifically addressing design features that can lead to medically recognized mental health disorders like anxiety, depression, eating disorders, substance use, and suicide, and patterns of use indicating addiction-like behavior, as in Title I of the Senate-passed Kids Online Safety and Privacy Act.
Moving Forward
One ultimate recommendation is that, critically, standards and requirements need teeth. Frameworks should require that companies comply with legal requirements or face effective enforcement (such as by a well-funded expert regulator, or private lawsuits), with tools such as fines and injunctions. We have seen with past technological developments that voluntary frameworks and suggestions will not adequately protect children. Social media for example has failed to voluntarily protect children and poses risks to their mental health and well being. From exacerbating body image issues to amplifying peer pressure and social comparison, from encouraging compulsive device use to reducing attention spans, from connecting youth to extremism, illegal products, and deadly challenges, the financial incentives do not appear to exist for technology companies to appropriately safeguard children on their own. The next Administration can support enforcement by funding government positions who will be enforcing such laws.
Antitrust in the AI Era: Strengthening Enforcement Against Emerging Anticompetitive Behavior
The advent of artificial intelligence (AI) has revolutionized business practices, enabling companies to process vast amounts of data and automate complex tasks in ways previously unimaginable. However, while AI has gained much praise for its capabilities, it has also raised various antitrust concerns. Among the most pressing is the potential for AI to be used in an anticompetitive manner. This includes algorithms that facilitate price-fixing, predatory pricing, and discriminatory pricing (harming the consumer market), as well as those which enable the manipulation of wages and worker mobility (harming the labor market). More troubling perhaps is the fact that the overwhelming majority of the AI landscape is controlled by just a few market players. These tech giants—some of the world’s most powerful corporations—have established a near-monopoly over the development and deployment of AI. Their dominance over necessary infrastructure and resources makes it increasingly challenging for smaller firms to compete.
While the antitrust enforcement agencies—the FTC and DOJ—have recently begun to investigate these issues, they are likely only scratching the surface. The covert and complex nature of AI makes it difficult to detect when it is being used in an anticompetitive manner. To ensure that business practices remain competitive in the era of AI, the enforcement agencies must be adequately equipped with the appropriate strategies and resources. The best way to achieve this is to (1) require the disclosure of AI technologies during the merger-review process and (2) reinforce the enforcement agencies’ technical strategy in assessing and mitigating anticompetitive AI practices.
Challenge & Opportunity
Since the late 1970s, antitrust enforcement has been in decline, in part due to a more relaxed antitrust approach put forth by the Chicago school of economics. Both the budgets and the number of full-time employees at the enforcement agencies have steadily decreased, while the volume of permitted mergers and acquisitions has risen (see Figure 1). This resource gap has limited the ability of the agencies to effectively oversee and regulate anticompetitive practices.
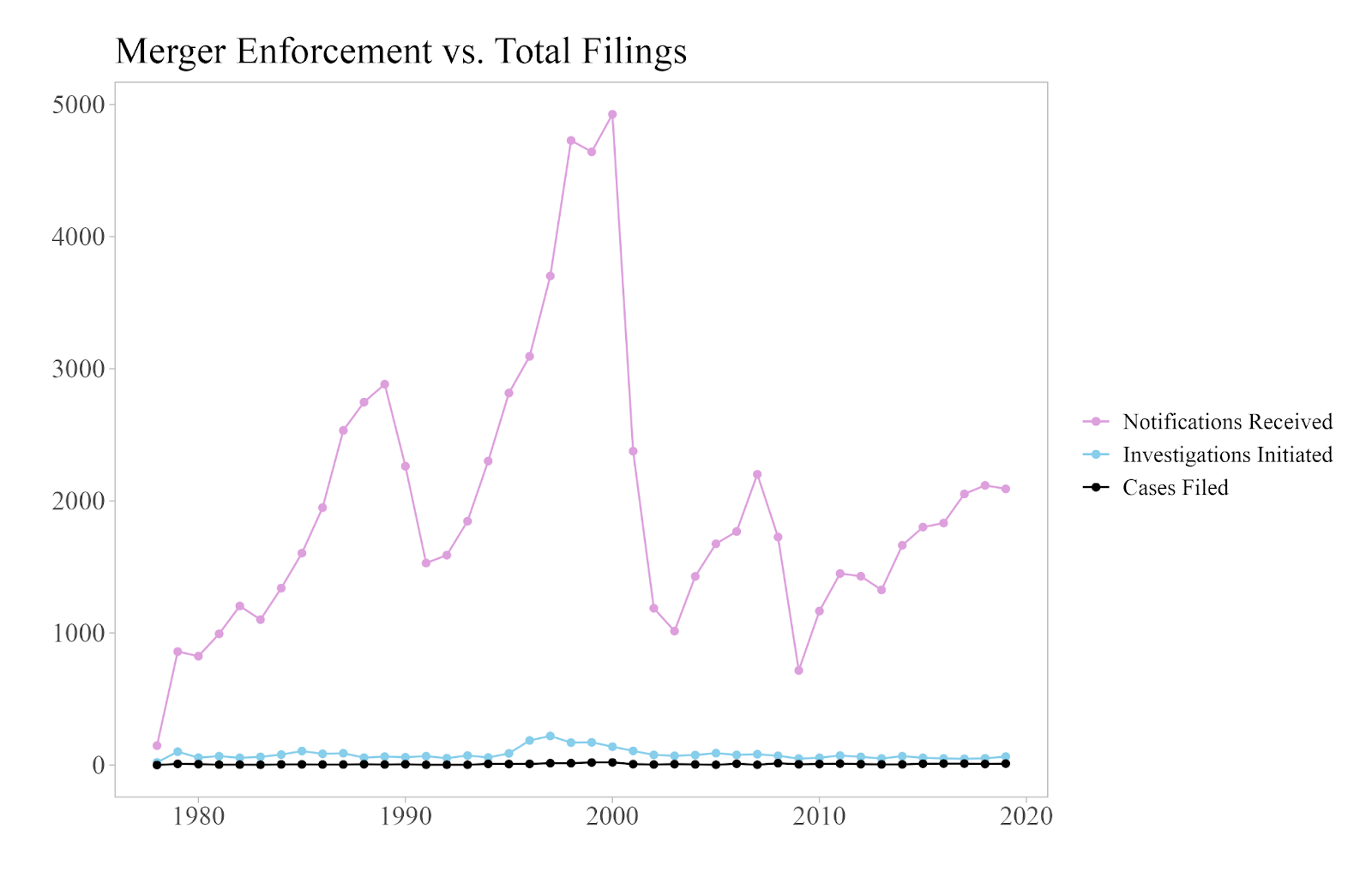
Changing attitudes surrounding big business, as well as recent shifts in leadership at the enforcement agencies—most notably President Biden’s appointment of Lina Khan to FTC Chair—have signaled a more aggressive approach to antitrust law. But even with this renewed focus, the agencies are still not operating at their full potential.
This landscape provides a significant opportunity to make some much-needed changes. Two areas for improvement stand out. First, agencies can make use of the merger review process to aid in the detection of anticompetitive AI practices. In particular, the agencies should be on the look-out for algorithms that facilitate price-fixing, where competitors use AI to monitor and adjust prices automatically, covertly allowing for tacit collusion; predatory pricing algorithms, which enable firms to undercut competitors only to later raise prices once dominance is achieved; and dynamic pricing algorithms, which allow firms to discriminate against different consumer groups, resulting in price disparities that may distort market competition. On the labor side, agencies should screen for wage-fixing algorithms and other data-driven hiring practices that may suppress wages and limit job mobility. Requiring companies to disclose the use of such AI technologies during merger assessments would allow regulators to examine and identify problematic practices early on. This is especially useful for flagging companies with a history of anticompetitive behavior or those involved in large transactions, where the use of AI could have the strongest anticompetitive effects.
Second, agencies can use AI to combat AI. Research has demonstrated that AI can be more effective in detecting anticompetitive behavior than other traditional methods. Leveraging such technology could transform enforcement capabilities by allowing agencies to cover more ground despite limited resources. While increasing funding for these agencies would be requisite, AI nonetheless provides a cost-effective solution, enhancing efficiency in detecting anticompetitive practices, without requiring massive budget increases.
The success of these recommendations hinges on the enforcement agencies employing technologists who have a deep understanding of AI. Their knowledge on algorithm functionality, the latest insights in AI, and the interplay between big data and anticompetitive behavior is instrumental. A detailed discussion of the need for AI expertise is covered in the following section.
Plan Of Action
Recommendation 1. Require Disclosure of AI Technologies During Merger-Review.
Currently, there is no formal requirement in the merger review process that mandates the reporting of AI technologies. This lack of transparency allows companies to withhold critical information that may help agencies determine potential anticompetitive effects. To effectively safeguard competition, it is essential that the FTC and DOJ have full visibility of businesses’ technologies, particularly those that may impact market dynamics. While the agencies can request information on certain technologies further in the review process, typically during the second request phase, a formalized reporting requirement would provide a more proactive approach. Such an approach would be beneficial for several reasons. First, it would enable the agencies to identify anticompetitive technologies they might have otherwise overlooked. Second, an early assessment would allow the agencies to detect and mitigate risk upfront, rather than having to address it post-merger or further along in the merger review process, when remedies may be more difficult to enforce. This is particularly applicable with regard to deep integrations that often occur between digital products post-merger. For instance, the merger of Instagram and Facebook complicated the FTC’s subsequent efforts to challenge Meta. As Dmitry Borodaenko, a former Facebook engineer, explained:
“Instagram is no longer viable outside of Facebook’s infrastructure. Over the course of six years, they integrated deeply… Undoing this would not be a simple task—it would take years, not just the click of a button.”
Lastly, given the rapidly evolving nature of AI, this requirement would help the agencies identify trends and better determine which technologies are harmful to competition, under what circumstances, and in which industries. Insights gained from one sector could inform investigations in other sectors, where similar technologies are being deployed. For example, the DOJ recently filed suit against RealPage, a property management software company, for allegedly using price-fixing algorithms to coordinate rent increases among competing landlords. The case is the first of its kind, as there had not been any previous lawsuit addressing price-fixing in the rental market. With this insight, however, if the agencies detect similar algorithms during the merger review process, they would be better equipped to intervene and prevent such practices.
There are several ways the government could implement this recommendation. To start, The FTC and DOJ should issue interpretive guidelines specifying that anticompetitive effects stemming from AI technologies are within the purview of the Hart-Scott-Rodino (HSR) Act, and that accordingly, such technologies should be disclosed in the pre-merger notification process. In particular, the agencies should instruct companies to report detailed descriptions of all AI technologies in use, how they might change post-merger, and their potential impact on competition metrics (e.g., price, market share). This would serve as a key step in signaling to companies that AI considerations are integral during merger review. Building on this, Congress could pass legislation mandating AI disclosures, thereby formalizing the requirement. Ultimately, in a future round of HSR revisions, the agencies could incorporate this mandate as a binding rule within the pre-merger framework. To avoid unnecessary burden on businesses, reporting should only be required when AI plays a significant role in the company’s operations or is expected to post-merger. What constitutes a ‘significant role’ should be left to the discretion of the agencies but could include AI systems central to core functions such as pricing, customer targeting, wage-setting, or automation of critical processes.
Recommendation 2. Reinforce the FTC and DOJ’s Technical Strategy in Assessing and Mitigating Anticompetitive AI Practices.
Strengthening the agencies’ ability to address AI requires two actions: integrating computational antitrust strategies and increasing technical expertise. A wave of recent research has highlighted AI as a powerful tool in helping detect anticompetitive behavior. For instance, scholars at the Stanford Computational Antitrust Project have demonstrated that methods such as machine learning, natural language processing, and network analysis can assist with tasks, ranging from uncovering collusion between firms to distinguishing digital markets. While the DOJ has already partnered with the Project, the FTC could benefit by pursuing a similar collaboration. More broadly, the agencies should deepen their technical expertise by expanding workshops and training with AI academic leaders. Doing so would not only provide them with access to the most sophisticated techniques in the field, but would also help bridge the gap between academic research and real-world implementation. Examples may include the use of machine learning algorithms to identify price-fixing and wage-setting; sentiment analysis, topic modeling, and other natural language processing tools to detect intention to collude in firm communications; or reverse-engineering algorithms to predict outcomes of AI-driven market manipulation.
Leveraging such computational strategies would enable regulators to analyze complex market data more effectively, enhancing the efficiency and precision of antitrust investigations. Given AI’s immense power, only a small—but highly skilled—team is needed to make significant progress. For instance, the UK’s Competition and Markets Authority (CMA) recently stood up a Data, Technology and Analytics unit, whereby they implement machine learning strategies to investigate various antitrust matters. For the U.S. agencies to facilitate this, the DOJ and FTC should hire more ML/AI experts, data scientists, and technologists, who could serve several key functions. First, they could conduct research on the most effective methods for detecting collusion and anticompetitive behavior in both digital and non-digital markets. Second, based on such research, they could guide the implementation of selected AI solutions in investigations and policy development. Third, they could perform assessments of AI technologies, evaluating the potential risks and benefits of AI applications in specific markets and companies. These assessments would be particularly useful during merger review, as previously discussed in Recommendation 1. Finally, they could help establish guidelines for transparency and accountability, ensuring the responsible and ethical use of AI both within the agencies and across the markets they regulate.
To formalize this recommendation, the President should submit a budget proposal to Congress requesting increased funding for the FTC and DOJ to (1) hire technology/AI experts and (2) provide necessary training for other selected employees on AI algorithms and datasets. The FTC may separately consider using its 6(b) subpoena powers to conduct a comprehensive study of the AI industry or of the use of AI practices more generally (e.g., to set prices or wages). Finally, the agencies should strive to foster collaboration between each other (e.g., establishing a Joint DOJ-FTC Computational Task Force), as well as with those in academia and the private sector, to ensure that enforcement strategies remain at the cutting edge of AI advancements.
Conclusion
The nation is in the midst of an AI revolution, and with it comes new avenues for anticompetitive behavior. As it stands, the antitrust enforcement agencies lack the necessary tools to adequately address this growing threat.
However, this environment also presents a pivotal opportunity for modernization. By requiring the disclosure of AI technologies during the merger review process, and by reinforcing the technical strategy at the FTC and DOJ, the antitrust agencies can strengthen their ability to detect and prevent anticompetitive practices. Leveraging the expertise of technologists in enforcement efforts can enhance the agencies’ capacity to monitor levels of competition in markets, as well as allow them to identify patterns between certain technologies and violations of antitrust.
Given the rapid pace of AI advancement, a proactive effort triumphs over a reactive one. Detecting antitrust violations early allows agencies to save both time and resources. To protect consumers, workers, and the economy more broadly, it is imperative that the FTC and DOJ adapt their enforcement strategies to meet the complexities of the AI era.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
A National Guidance Platform for AI Acquisition
Streamlining the procurement process for more equitable, safe, and innovative government use of AI
The federal government’s approach to procuring AI systems serves two critical purposes: it not only shapes industry and academic standards but also determines how effectively AI can enhance public services. By leveraging its substantial purchasing power responsibly, the government can encourage high-quality, inclusive AI solutions that address diverse citizen needs while setting a strong precedent for innovation and accountability. Guidance issued in October 2024 by the White House’s Office of Management and Budget (OMB) gives recommendations on how agencies should use AI systems, focusing on public trust and data transparency. However, it is unclear how these guidelines align with general procurement regulations like the Federal Acquisition Regulation (FAR).
To reduce bureaucratic hurdles and encourage safe government innovation, the General Services Administration (GSA) should develop a digital platform that guides federal agencies through an “acquisition journey” for AI procurement. This recommendation is for streamlining guidance for procuring AI systems and should not be confused with the use of AI to simplify the procurement process. The platform should be intuitive and easy to navigate by clearly outlining the necessary information, requirements, and resources at each process stage, helping users understand what they need at any point in the procurement lifecycle. Such a platform would help agencies safely procure and implement AI technologies while staying informed on the latest guidelines and adhering to existing federal procurement rules. GSA should take inspiration from Brazil’s well-regarded Public Procurement Platform for Innovation (CPIN). CPIN helps public servants navigate the procurement process by offering best practices, risk assessments, and contract guidance, ensuring transparency and fairness at each stage of the procurement process.
Challenges and Opportunities
The federal government’s approach to AI systems is a crucial societal benchmark, shaping standards that ripple through industries, academia, and public discourse. Along with shaping the market, the government also faces a delicate balancing act when it comes to its own use of AI: it must harness AI’s potential to dramatically enhance efficiency and effectiveness in public service delivery while simultaneously adhering to the highest AI safety and equity standards. As such, the government’s handling of AI technologies carries immense responsibility and opportunity.
The U.S. federal government procures AI for numerous different tasks—from analyzing weather hazards and expediting benefits claims to processing veteran feedback. Positive impacts could potentially include faster and more accurate public services, cost savings, better resource allocation, improved decision-making based on data insights, and enhanced safety and security for citizens. However, risks can include privacy breaches, algorithmic bias leading to unfair treatment of certain groups, over-reliance on AI for critical decisions, lack of transparency in AI-driven processes, and cybersecurity vulnerabilities. These issues could erode public trust, inhibit the adoption of beneficial AI, and exacerbate existing social inequalities.
The federal government has recently published several guidelines on the acquisition and use of AI systems within the federal government, specifically how to identify and mitigate systems that may impact public trust in these systems. For example:
- OMB Memo M-24-10 (2024): Guides federal agencies on the use of artificial intelligence. It emphasizes responsible AI development and deployment, focusing on key principles such as safety, security, fairness, and transparency. The memo outlines requirements for AI governance, risk management, and public transparency in federal AI applications.
- OMB Memo M-24-18 (2024): Provides Guidance on AI acquisitions, such as transparency, continued guidance for incident reporting on rights and safety impacting AI, data management, and specific advice for AI-based biometrics.
- Agency Memos (2024): Per M-24-10, many U.S. agencies have published their internal strategies for AI use.
- AI Use Case Inventory (2024): Requires agencies to perform an annual inventory of AI systems with information on Procurement Instrument Identifiers and potential for rights or safety impacts.
- Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence (2023) This requires agencies to adopt trustworthy and responsible AI practices. It mandates using AI safety standards, including rigorous testing, auditing, and privacy protections across federal systems.
- Executive Order 13960 (2020) promotes the use of trustworthy artificial intelligence in government and outlines the responsibilities of agencies to ensure their AI use is ethical, transparent, and accountable. It includes the need for agencies to consider risks, fairness, and bias in AI systems.
This guidance, coupled with the already extensive set of general procurement regulations such as the Federal Acquisition Regulation (FAR ), can be overwhelming for public servants. In conversations with the author of this memo, stakeholders, including agency personnel and vendors, frequently noted that they needed clarification about when impact and risk assessments should occur in the FAR process.
How can government agencies adequately follow their mandate to provide safe and trustworthy AI for public services while reducing the bureaucratic burden that can result in an aversion to government innovation? A compelling example comes from Brazil. The Public Procurement Platform for Innovation (CPIN), managed by the Brazilian Ministry of Development, Industry, Commerce, and Services (MDIC), is an open resource designed to share knowledge and best practices on public procurement for innovation. In 2023, the platform was recognized by the Federal Court of Auditors (TCU—the agency that oversees federal procurement) as an essential new asset in facilitating public service. The CPIN helps public servants navigate the procurement process by diagnosing needs and selecting suitable contracting methods through questionnaires. Then, it orients agencies through a procurement journey, identifying what procurement process should be used, what kinds of dialogue the agency should have with potential vendors and other stakeholders, guidance for risk assessments, and contract language. The platform is meant to guide public servants through each stage of the procurement process, ensuring they know their obligations for transparency, fairness, and risk mitigation at any given time. CPIN is open to the public and is meant to be a resource, not new requirements that supplant existing mandates by Brazilian authorities.
Here in the U.S., the Office of Federal Procurement (OFFP) within the Office of Management and Budget (OMB) in partnership with the General Services Administration (GSA) and the Council of Chief AI Officers (CAIO), should develop a similar centralized resource to help federal agencies procure AI technologies safely and effectively. This platform would ensure agencies have up-to-date guidelines on AI acquisition integrated with existing procurement frameworks.
This approach is beneficial because:
- Public-facing access reduces information gaps between government entities, vendors, and stakeholders, fostering transparency and leveling the playing field for mid- and small-sized vendors.
- Streamlined processes alleviate complexity, making it easier for agencies to procure AI technologies.
- Clear guidance for agencies throughout each step of the procurement process ensures that they complete essential tasks such as impact evaluations and risk assessments within the appropriate time frame.
GSA has created similar tools before. For example, the Generative AI Acquisition Resource Guide assists federal buyers in procuring and implementing generative AI technologies by describing key considerations, best practices, and potential challenges associated with acquiring generative AI solutions. However, this digital platform would go one step further and align best practices, recommendations, and other AI considerations within the processes outlined in the FAR and other procurement methods.
Plan of Action
Recommendation 1. Establish a Working Group led by the OMB OFPP, with participation from GSA, OSTP, and the CAIO Council, tasked with systematically mapping all processes and policies influencing public sector AI procurement.
This includes direct AI-related guidance and tangential policies such as IT, data management, and cybersecurity regulations. The primary objective is identifying and addressing existing AI procurement guidance gaps, ensuring that the forthcoming platform can provide clear, actionable information to federal agencies. To achieve this, the working group should:
Conduct a thorough review of current mandates (see the FAQ for a non-exhaustive list of current mandates), executive orders, OMB guidance, and federal guidelines that pertain to AI procurement. This includes mapping out the requirements and obligations agencies must meet during acquisition. Evaluate if these mandates come with explicit deadlines or milestones that need to be integrated into the procurement timeline (e.g., AI risk assessments, ethics reviews, security checks)
Conduct a gap analysis to identify areas where existing AI procurement guidance needs to be clarified, completed, or updated. Prioritize gaps that can be addressed by clarifying existing rules or providing additional resources like best practices rather than creating new mandates to avoid unnecessary regulatory burdens. For example, guidance on handling personally identifiable information within commercially available information, guidance on data ownership between government and vendors, and the level of detail required for risk assessments.
Categorize federal guidance into two main buckets: general federal procurement guidance (e.g., Federal Acquisition Regulation [FAR]) and agency-specific guidelines (e.g., individual AI policies from agencies such as DoD’s AI Memos or NASA’s Other Transaction Authorities [OTAs]). Ensure that agency-specific rules are clearly distinguished on the platform, allowing agencies to understand when general AI acquisition rules apply and when specialized guidance takes precedence. Since the FAR may take years to update to reflect agency best practices, this could help give visibility to potential gaps.
Recommendation 2. The OMB OFPP-GSA-CAIO Council Working Group should convene a series of structured engagements with government and external stakeholders to co-create non-binding, practical guidance addressing gaps in AI procurement to be included in the platform.
These stakeholders should include government agency departments (e.g., project leads, procurement officers, IT departments) and external partners (vendors, academics, civil society organizations). The working group’s recommendations should focus on providing agencies with the tools, content, and resources they need to navigate AI procurement efficiently. Key focus areas would include risk management, ethical considerations, and compliance with cybersecurity policies throughout the procurement process. The guidance should also highlight areas where more frequent updates will be required, particularly in response to rapid developments in AI technologies and federal policies.
Topics that these stakeholder convenings could cover include:
Procurement Process
- Acquisition Pathways: What acquisition methods (e.g., FAR, Other Transaction Authorities [OTA], and joint acquisition programs) can be leveraged for procuring AI? Identify the most appropriate mechanisms for different AI use cases. For example, agencies looking to develop an advanced AI system with the help of external researchers may want to consider OTA if that is available to them.
- Integrating New Guidance: How can recent AI-related guidance from OMB memos (like M-24-10 and M-24-18) be incorporated into existing procurement frameworks, especially within the FAR?
- Stakeholder Responsibilities: Clearly define the roles and obligations of each party in the AI procurement process, from agency departments (such as project teams, procurement offices, and IT) to vendors and contractors. Determine who manages AI-related risks, evaluates AI systems, and ensures compliance with relevant policies.
- NIST AI Risk Management Framework (RMF): Explore how the NIST AI RMF can be integrated into the acquisition process and ensure agencies are equipped to assess AI risks effectively within procurement.
Transparency
- Public Disclosure: Define what information must be shared with the public at various stages of the AI acquisition process. Ensure there is a balance between transparency and protecting sensitive information.
- Data Sharing and Protection: Identify resources to help agencies understand their obligations regarding data sharing and protection under OMB Memo M-24-18 or forthcoming memos from the new administration to ensure compliance with any data security and privacy requirements.
- Risk Communication: Establish when and how to communicate to relevant stakeholders (e.g., the public and civil society) that a potential AI acquisition could impact public trust in AI technologies. Outline the types of transparency that should accompany AI systems that carry such risks.
Resources:
- External Best Practices: Gather and share civil society toolkits, industry best practices, and academic evaluations that can help agencies ensure the trustworthy use of AI. This would provide agencies with access to external expertise to complement federal guidelines and standards. The stakeholder convening should deliberate on whether these best practices will just be linked to the platform or if they need some kind of endorsement from government agencies.
Recommendation 3. The OPPF, in collaboration with GSA and the United States Digital Service (USDS) should then develop an intuitive, easy-to-navigate digital platform that guides federal agencies through an “acquisition journey” for AI procurement.
While the focus of this memo is on the broader procurement of AI systems, this digital platform could also benefit from the incorporation of AI, for example, by using a chatbot that is able to refer government users to the specific regulations governing their use cases. At each process stage, the platform should clearly outline the necessary information collected during the previous phases of this project to help users understand exactly what is needed at any given point in the procurement lifecycle.
The platform should serve as a central repository that unites all relevant AI procurement requirements, guidance from federal regulations (e.g., FAR, OMB memos), and insights from stakeholder convenings (e.g., vendors, academics, civil society). Each procurement stage should feature the most up-to-date guidance, ensuring a comprehensive and organized resource for federal employees.
The system should be designed for ease of navigation, potentially modeled after Brazil’s CPIN, which is organized like a city subway map. Users can begin with a simple questionnaire recommending a specific “subway line” or procurement process. Each “stop” along the line would represent a key stage in the procurement journey, offering relevant guidance, requirements, and best practices for that phase.
OPPF and GSA must regularly update the platform to reflect the latest federal AI and procurement policies and evolving best practices from government, civil society, and industry sources. Regular updates ensure that agencies use the most current information, especially as AI technologies and policies evolve rapidly.
The Federal Acquisition Institute within OFPP should create robust training programs to familiarize public servants with the new platform and how to use it effectively. These programs should explain how the platform supports AI acquisition and links to broader agency AI strategies.
- Roll out the platform gradually through agency-specific capacity-building sessions, demonstrating its utility for different departments. These sessions should show how the resource can help public servants meet their AI procurement needs and align with their agency’s strategic AI goals.
- Develop specialized training modules for different government stakeholders. For example, project teams might focus on aligning AI systems with mission objectives, procurement specialists on contract compliance, and IT departments on technical evaluations and cybersecurity.
- To ensure broad understanding and transparency, host public briefings for external stakeholders such as vendors, civil society organizations, and researchers. These sessions would clarify AI procurement requirements, fostering trust and collaboration between the public and private sectors.
Conclusion
The proposed centralized platform would represent a significant step forward in streamlining and standardizing the acquisition of AI technologies across federal agencies. By consolidating guidance, resources, and best practices into a user-friendly digital interface, this initiative would address gaps in the current AI acquisition landscape without increasing bureaucracy. This initiative supports individual agencies in their AI adoption efforts. It promotes a cohesive, government-wide approach to responsible AI implementation, ultimately benefiting both public servants and the citizens they serve.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
There are so many considerations based on a particular agency’s many needs. A non-exhaustive list of legislation, executive orders, standards and other guidance relating to innovation procurement and agency use of AI can be found here. One approach to top-level simplification and communication is to create something similar to Brazil’s city subway map, discussed above.
The original Brazilian CPIN is designed for general innovation procurement and is agnostic to specific technologies or services. However, this memo focuses on artificial intelligence (AI) in light of recent guidance from the Office of Management and Budget (OMB) and the growing interest in AI from both the Biden Administration and the incoming Trump Administration. Establishing a platform specifically for AI system procurement could serve as a pilot for developing a broader innovation procurement platform.
The platform seeks to ensure responsible public sector AI by mitigating information asymmetries between government agencies and vendors, specifically by:
- Incorporating the latest OMB guidelines on AI system usage, focusing on human rights, safety, and data transparency. These guidelines are seamlessly integrated into each step of the procurement process.
- Throughout the “acquisition journey,” the platform should include clarifying checkpoints where agencies can demonstrate how their procurement plans align with established safety, equity, and ethical standards.
- Prompting agencies to consider how procured AI systems will address context-specific risks by integrating agency-specific guidance (e.g., the Department of Labor’s AI Principles) into the existing AI procurement frameworks.
Kickstarting Collaborative, AI-Ready Datasets in the Life Sciences with Government-funded Projects
In the age of Artificial Intelligence (AI), large high-quality datasets are needed to move the field of life science forward. However, the research community lacks strategies to incentivize collaboration on high-quality data acquisition and sharing. The government should fund collaborative roadmapping, certification, collection, and sharing of large, high-quality datasets in life science. In such a system, nonprofit research organizations engage scientific communities to identify key types of data that would be valuable for building predictive models, and define quality control (QC) and open science standards for collection of that data. Projects are designed to develop automated methods for data collection, certify data providers, and facilitate data collection in consultation with researchers throughout various scientific communities. Hosting of the resulting open data is subsidized as well as protected by security measures. This system would provide crucial incentives for the life science community to identify and amass large, high-quality open datasets that will immensely benefit researchers.
Challenge and Opportunity
Life science has left the era of “one scientist, one problem.” It is becoming a field wherein collaboration on large-scale research initiatives is required to make meaningful scientific progress. A salient example is Alphafold2, a machine learning (ML) model that was the first to predict how a protein will fold with an accuracy meeting or exceeding experimental methods. Alphafold2 was trained on the Protein Data Bank (PDB), a public data repository containing standardized and highly curated results of >200,000 experiments collected over 50 years by thousands of researchers.
Though such a sustained effort is laudable, science need not wait another 50 years for the ‘next PDB’. If approached strategically and collaboratively, the data necessary to train ML models can be acquired more quickly, cheaply, and reproducibly than efforts like the PDB through careful problem specification and deliberate management. First, by leveraging organizations that are deeply connected with relevant experts, unified projects taking this approach can account for the needs of both the people producing the data and those consuming it. Second, by centralizing plans and accountability for data and metadata standards, these projects can enable rigorous and scalable multi-site data collection. Finally, by securely hosting the resulting open data, the projects can evaluate biosecurity risk and provide protected access to key scientific data and resources that might otherwise be siloed in industry. This approach is complementary to efforts that collate existing data, such as the Human Cell Atlas and UCSD Genome Browser, and satisfy the need for new data collection that adheres to QC and metadata standards.
In the past, mid-sized grants have allowed multi-investigator scientific centers like the recently funded Science and Technology Center for Quantitative Cell Biology (QCB, $30M in funding 2023) to explore many areas in a given field. Here, we outline how the government can expand upon such schemes to catalyze the creation of impactful open life science data. In the proposed system, supported projects would allow well-positioned nonprofit organizations to facilitate distributed, multidisciplinary collaborations that are necessary for assembling large, AI-ready datasets. This model would align research incentives and enable life science to create the ‘next PDBs’ faster and more cheaply than before.
Plan of Action
Existing initiatives have developed processes for creating open science data and successfully engaged the scientific community to identify targets for the ‘next PDB’ (e.g., Chan Zuckerberg Initiative’s Open Science program, Align’s Open Datasets Initiative). The process generally occurs in five steps:
- A multidisciplinary set of scientific leaders identify target datasets, assessing the scale of data required and the potential for standardization, and defining standards for data collection methods and corresponding QC metrics.
- Collaboratively develop and certify methods for data acquisition to de-risk the cost-per-datapoint and utility of the data.
- Data collection methods are onboarded at automation partner organizations, such as NSF BioFoundries and existing National Labs, and these automation partners are certified to meet the defined data collection standards and QC metrics.
- Scientists throughout the community, including those at universities and for-profit companies, can request data acquisition, which is coordinated, subsidized, and analyzed for quality.
- Data becomes publicly available and is hosted in a stable, robustly maintained database with biosecurity, cybersecurity, and privacy measures in perpetuity for researchers to access.
The U.S. Government should adapt this process for collaborative, AI-ready data collection in the life sciences by implementing the following recommendations:
Recommendation 1. An ARPA-like agency — or agency division — should launch a Collaborative, AI-Ready Datasets program to fund large-scale dataset identification and collection.
This program should be designed to award two types of grants:
- A medium-sized “phase 1” award of $1-$5m to fund new dataset identification and certification. To date, roadmapping dataset concepts (Steps 1-2 above) has been accomplished by small-scale projects of $1-$5M with a community-driven approach. Though selectively successful, these projects have not been as comprehensive or inclusive as they could otherwise be. Government funding could more sustainably and systematically permit iterative roadmapping and certification in areas of strategic importance.
- A large “phase 2” award of $10-$50m to fund the collection of previously identified datasets. Currently, there are no funding mechanisms designed to scale up acquisition (Steps #3-4 above) for dataset concepts that have been deemed valuable and derisked. To fill this gap, the government should leverage existing expertise and collaboration across the nonprofit research ecosystem by awarding grants of $10-50m for the coordination, acquisition, and release of mature dataset concepts. The Human Genome project is a good analogy, wherein a dataset concept was identified and collection was distributed amongst several facilities.
Recommendation 2. The Office of Management and Budget should direct the NSF and NIH to develop plans for funding academics and for-profits traunched on data deposition.
Once an open dataset is established, the government can advance the use and further development of that dataset by providing grants to academics that are traunched on data deposition. This approach would be in direct alignment with the government’s goals for supporting open, shared resources for AI innovation as laid out in section 5.2 of the Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence.
Agencies’ approaches to meeting this priority could vary. In one scenario, a policy or program could be established in which grantees would use a portion of the funds disbursed to them to pay for open data acquisition at a certified data provider. Analogous structures have enabled scientists to access other types of shared scientific infrastructure, such as the NSF’s ACCESS program. In the same way that ACCESS offers academics access to compute resources, it could be expanded to offer academic access to data acquisition resources at verified facilities. Offering grants in this way would incentivize the scientific community to interact with and expand upon open datasets, as well as encourage compliance through traunching.
Efforts to support use and development of open, certified datasets could also be incorporated into existing programs, including the National AI Research Resource, for which complementary programs could be developed to provide funding for standardized data acquisition and deposition. Similar ideas could also be incorporated into core programs within NSF and NIH, which already disburse funds after completion of annual progress reports. Such programs could mandate checks for data deposition in these reports.
Conclusion
Collaborative, AI-Ready datasets would catalyze progress in many areas of life science, but realizing them requires innovative government funding. By supporting coordinated projects that span dataset roadmapping, methods and standards development, partner certification, distributed collection, and secure release on a large scale, the government can coalesce stakeholders and deliver the next generation of powerful predictive models. To do so, it should combine small-sized, mid-sized, and traunched grants in unified initiatives that are orchestrated by nonprofit research organizations, which are uniquely positioned to execute these initiatives end-to-end. These initiatives should balance intellectual property protection and data availability, and thereby help deliver key datasets upon which new scientific insights depend.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
Roadmapping dataset opportunities, which can take up to a year, requires convening experts across multiple disciplines, including experimental biology, automation, machine learning, and others. In collaboration, these experts assess both the feasibility and impact of opportunities, as well as necessary QC standards. Roadmapping culminates in determination of dataset value — whether it can be used to train meaningful new machine learning models.
To mitigate single-facility risk and promote site-to-site interoperability, data should be collected across multiple sites. To ensure that standards and organization holds across sites, planning and documentation should be centralized.
Automation partners will be evaluated according to the following criteria:
- Commitment to open science
- Rigor and consistency in methods and QC procedures
- Standardization of data and metadata ontologies
More specifically, certification will depend upon the abilities of partners to accommodate standardized ontologies, capture sufficient metadata, and reliably pass data QC checks. It will also require partners to have demonstrated a commitment to data reusability and replicability, and that they are willing to share methods and data in the open science ecosystem.
Today, scientists have no obligation to publish every piece of data they collect. In an Open Data paradigm, all data must eventually be shared. For some types of data, a short, optional embargo period would enable scientists to participate in open data efforts without compromising their ability to file patents or publish papers. For example, in protein engineering, the patentable product is the sequence of a designed protein, making immediate release of data untenable. An embargo period of one to two years is sufficient to alleviate this concern and may even hasten data sharing by linking it to a fixed length of time after collection, rather than to publication. Whether or not an embargo should be implemented and its length should be determined for each data type, and designed to encourage researchers to participate in acquisition of open data.
Biological data is a strategic resource and requires stewardship and curation to ensure it has maximum impact. Thus, data that is generated through the proposed system should be hosted by high-quality providers that adhere to biosecurity standards and enforce embargo periods. Appropriate biosecurity standards will be specific to different types of data, and should be formulated and periodically reevaluated by a multidisciplinary group of stakeholders. When access to certified, post-embargo data is requested, the same standards will apply as will export controls. In some instances, for some users, restricting access may be reasonable. For offering this suite of valuable services, hosting providers should be subsidized through reimbursements.
From Strategy to Impact: Establishing an AI Corps to Accelerate HHS Transformation
To unlock the full potential of artificial intelligence (AI) within the Department of Health and Human Services (HHS), an AI Corps should be established, embedding specialized AI experts within each of the department’s 10 agencies. HHS is uniquely positioned for—and urgently requires—this investment in AI expertise, as it plays a pivotal role in delivering efficient healthcare to millions of Americans. HHS’s responsibilities intersect with areas where AI has already shown great promise, including managing vast healthcare datasets, accelerating drug development, and combating healthcare fraud.
Modeled after the success of the Department of Homeland Security (DHS)’s existing AI Corps, this program would recruit top-tier professionals with advanced expertise in AI, machine learning, data science, and data engineering to drive innovation within HHS. While current HHS initiatives like the AI Council and AI Community of Practice provide valuable strategic guidance, they fall short in delivering the on-the-ground expertise necessary for meaningful AI adoption across HHS agencies. The AI Corps would fill this gap, providing the hands-on, agency-level support necessary to move beyond strategy and into the impactful implementation intended by recent federal actions related to AI.
This memo uses the Food and Drug Administration (FDA) as a case study to demonstrate how an AI Corps member could spearhead advancements within HHS’s agencies. However, the potential benefits extend across the department. For instance, at the Centers for Disease Control and Prevention (CDC), AI Corps experts could leverage machine learning for more precise outbreak modeling, enabling faster, more targeted public health responses. At the National Institutes of Health (NIH), they could accelerate biomedical research through AI-driven analysis of large-scale genomic and proteomic data. Similarly, at the Centers for Medicare and Medicaid Services (CMS), they could improve healthcare delivery by employing advanced algorithms for patient data analytics, predicting patient outcomes, and enhancing fraud detection mechanisms.
Challenge and Opportunity
AI is poised to revolutionize not only healthcare but also the broad spectrum of services under HHS, offering unprecedented opportunities to enhance patient outcomes, streamline administrative processes, improve public health surveillance, and advance biomedical research. Realizing these benefits and defending against potential harms demands the effective implementation and support of AI tools across HHS. The federal workforce, though committed and capable, currently lacks the specialized expertise needed to fully harness AI’s potential, risking a lag in AI adoption that could impede progress.
The public sector is responding well to this opportunity since it is well positioned to attract leading experts to help leverage new technologies. However, for federal agencies, attracting technical experts has been a perennial challenge, resulting in major setbacks in government tech projects: Of government software projects that cost more than $6 million, only 13% succeed.
Without introducing a dedicated AI Corps, existing employees—many of whom lack specialized AI expertise—would be required to implement and manage complex AI tools alongside their regular duties. This could lead to the acquisition or development of AI solutions without proper evaluation of their suitability or effectiveness for specific use cases. Additionally, without the necessary expertise to oversee and monitor these systems, agencies may struggle to ensure they are functioning correctly and ethically. As a result, there could be significant inefficiencies, missed opportunities for impactful AI applications, and an increased reliance on external consultants who may not fully understand the unique challenges and needs of each agency. This scenario not only risks undermining the effectiveness of AI initiatives but also heightens the potential for errors, biases, and misuse of AI technologies, ultimately hindering HHS’s mission and objectives.
HHS’s AI Strategy recognizes the need for AI expertise in government; however, its focus has largely been on strategic oversight rather than the operational execution needed on the ground, with the planned establishment of an AI Council and AI Community of Practice prioritizing policy and coordination. While these entities are crucial, they do not address the immediate need for hands-on expertise within individual agencies. This leaves a critical gap in the hands-on expertise required to safely implement AI solutions at the agency level. HHS covers a wide breadth of functions, from administering national health insurance programs like Medicare and Medicaid to conducting advanced biomedical research at the NIH, with each agency facing distinct challenges where AI could provide transformative benefits. However, without dedicated support, AI adoption risks becoming fragmented, underutilized, or ineffective.
For example, at the CDC, AI could significantly improve infectious disease surveillance systems, enabling more timely interventions and enhancing the CDC’s overall preparedness for public health crises, moving beyond traditional methods that often rely on slower, manual analysis. Furthermore, the Administration for Children and Families (ACF) could leverage AI to better allocate resources, improve program outcomes, and support vulnerable populations more effectively. There are great opportunities to use machine learning algorithms to accelerate data processing and discovery in fields such as cancer genomics and personalized medicine. This could help researchers identify new biomarkers, optimize clinical trial designs, and push forward breakthroughs in medical research faster and more efficiently. However, without the right expertise, these game-changing opportunities could not only remain unrealized but also introduce significant risks. The potential for biased algorithms, privacy breaches, and misinterpretation of AI outputs poses serious concerns. Agency leaders may feel pressured to adopt technologies they don’t fully understand, leading to ineffective or even harmful implementations. Embedding AI experts within HHS agencies is essential to ensure that AI solutions are deployed responsibly, maximizing benefits while mitigating potential harms.
This gap presents an opportunity for the federal government to take decisive action. By recruiting and embedding top-tier AI professionals within each agency, HHS could ensure that AI is treated not as an ancillary task but as a core component of agency operations. These experts would bring the specialized knowledge necessary to integrate AI tools safely and effectively, optimize processes, and drive innovation within each agency.
DHS’s AI Corps, launched as part of the National AI Talent Surge, provides a strong precedent for recruiting AI specialists to advance departmental capabilities. For instance, AI Corps members have played a vital role in improving disaster response by using AI to quickly assess damage and allocate resources more effectively during crises. They have also enhanced cybersecurity efforts by using AI to detect vulnerabilities in critical U.S. government systems and networks. Building on these successes, a similar effort within HHS would ensure that AI adoption moves beyond a strategic objective to a practical implementation, with dedicated experts driving innovation across the department’s diverse functions.
Case Study: The Food and Drug Administration (FDA)
The FDA stands at the forefront of the biotechnology revolution, facing the dual challenges of rapid innovation and a massive influx of complex data. Advances in gene editing, personalized medicine, and AI-driven diagnostics promise to transform healthcare, but they also present significant regulatory hurdles. The current framework, though robust, struggles to keep pace with these innovations, risking delays in the approval and implementation of groundbreaking treatments.
This situation is reminiscent of the challenges faced in the 1980s and 1990s, when advances in pharmaceutical science outstripped the FDA’s capacity to review new drugs, leading to the so-called “drug lag.” The Prescription Drug User Fee Act of 1992 was a pivotal response, streamlining the drug review process by providing the FDA with additional resources. However, the continued reliance on scaling resources may not be sustainable as the complexity and volume of data increase.
The FDA has begun to address this new challenge. For example, the Center for Biologics Evaluation and Research has established committees like the Artificial Intelligence Coordinating Committee and the Regulatory Review AI Subcommittee. However, these efforts largely involve existing staff who must balance AI responsibilities with their regular duties, limiting the potential impact. Moreover, the focus has predominantly been on regulating AI rather than leveraging it to enhance regulatory processes.
Placing an AI expert from the HHS AI Corps within the FDA could fundamentally change this dynamic. By providing dedicated, expert support, the FDA could accelerate its regulatory review processes, ensuring timely and safe access to innovative treatments. The financial implications are significant: the value of accelerated drug approvals, as demonstrated by the worth of Priority Review Vouchers (acceleration of four months = ~$100 million), indicates that effective AI adoption could unlock billions of dollars in industry value while simultaneously improving public health outcomes.
Plan of Action
To address the challenges and seize the opportunities outlined earlier, the Office of the Chief Artificial Intelligence Officer (OCAIO) within HHS should establish an AI Corps composed of specialized experts in artificial intelligence, machine learning, data science, and data engineering. This initiative will be modeled after DHS’s successful AI Corps and tailored to the unique needs of HHS and its 10 agencies.
Recommendation 1. Establish an AI Corps within HHS.
Composition: The AI Corps would initially consist of 10 experts hired to temporary civil servant positions, with one member allocated to each of HHS’s 10 agencies, and each placement lasting one to two years. These experts will possess a range of technical skills—including AI, data science, data engineering, and cloud computing—tailored to each agency’s specific needs and technological maturity. This approach ensures that each agency has the appropriate expertise to effectively implement AI tools and methodologies, whether that involves building foundational data infrastructure or developing advanced AI applications.
Hiring authority: The DHS AI Corps utilized direct hiring authority, which was expanded by the Office of Personnel Management under the National AI Talent Surge. HHS’s AI Corps could adopt a similar approach. This authority would enable streamlined recruitment of individuals into specific AI roles, including positions in AI research, machine learning, and data science. This expedited process would allow HHS to quickly hire and onboard top-tier AI talent.
Oversight: The AI Corps would be overseen by the OCAIO, which would provide strategic direction and ensure alignment with HHS’s broader AI initiatives. The OCAIO would also be responsible for coordinating the activities of the AI Corps, setting performance goals, and evaluating outcomes.
Budget and Funding
Estimated cost: The AI Corps is projected to cost approximately $1.5 million per year, based on an average salary of $150,000 per corps member. This estimate includes salaries and operational costs such as training, travel for interagency collaboration, and participation in conferences.
Funding source: Funding would be sourced from the existing HHS budget, specifically from allocations set aside for digital transformation and innovation. Given the relatively modest budget required, reallocation within these existing funds should be sufficient.
Recruitment and Training
Selection process: AI Corps members would be recruited through a competitive process, targeting individuals with proven expertise in AI, data science, and related fields.
Training: Upon selection, AI Corps members would undergo an intensive orientation and training program to familiarize them with the specific needs and challenges of HHS’s various agencies. This also includes training on federal regulations, ethics, and data governance to ensure that AI applications comply with existing laws and policies.
Agency Integration
Deployment: Each AI Corps member would be embedded within a specific HHS agency, where they would work closely with agency leadership and staff to identify opportunities for AI implementation. Their primary responsibility would be to develop and deploy AI tools that enhance the agency’s mission-critical processes. For example, an AI Corps member embedded at the CDC could focus on improving disease surveillance systems through AI-driven predictive analytics, while a member at the NIH could drive advancements in biomedical research by using machine learning algorithms to analyze complex genomic data.
Collaboration: To ensure cross-agency learning and collaboration, AI Corps members would convene regularly to share insights, challenges, and successes. These convenings would be aligned with the existing AI Community of Practice meetings, fostering a broader exchange of knowledge and best practices across the department.
Case Study: The FDA
AI Corps Integration at the FDA
Location: The AI Corps member assigned to the FDA would be based in the Office of Digital Transformation, reporting directly to the chief information officer. This strategic placement would enable the expert to work closely with the FDA’s leadership team, ensuring that AI initiatives are aligned with the agency’s overall digital strategy.
Key responsibilities
Process improvement: The AI Corps member would collaborate with FDA reviewers to identify opportunities for AI to streamline regulatory review processes. This might include developing AI tools to assist with data analysis, automate routine tasks, or enhance decision-making capabilities.
Opportunity scoping: The expert would engage with FDA staff to understand their workflows, challenges, and data needs. Based on these insights, the AI Corps member would scope and propose AI solutions tailored to the FDA’s specific requirements.
Pilot projects: The AI Corps member would lead pilot projects to test AI tools in real-world scenarios, gathering data and feedback to refine and scale successful initiatives across the agency.
Conclusion
Establishing an AI Corps within HHS is a critical step toward harnessing AI’s full potential to enhance outcomes and operational efficiency across federal health agencies. By embedding dedicated AI experts within each agency, HHS can accelerate the adoption of innovative AI solutions, address current implementation gaps, and proactively respond to the evolving demands of the health landscape.
While HHS may currently have less technological infrastructure compared to departments like the Department of Homeland Security, targeted investment in in-house expertise is key to bridging that gap. The proposed AI Corps not only empowers agencies like the FDA, CDC, NIH, and CMS to enhance their missions but also sets a precedent for effective AI integration across the federal government. Prompt action to establish the AI Corps will position HHS at the forefront of technological innovation, delivering tangible benefits to the American public and transforming the way it delivers services and fulfills its mission.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
The AI Corps is designed to be the opposite of bureaucracy—it’s about action, not administration. These experts will be embedded directly within agencies, working alongside existing teams to solve real-world problems, not adding paperwork. Their mission is to integrate AI into daily operations, making processes more efficient and outcomes more impactful. By focusing on tangible results and measurable improvements, the AI Corps will be judged by its ability to cut through red tape, not create it.
Innovation can present challenges, but the AI Corps is designed to address them effectively. These experts will not only bring technical expertise but also serve as facilitators who can translate advanced AI capabilities into practical applications that align with existing agency cultures. A key part of their role will be to make AI more accessible and understandable, ensuring it is valuable to all levels of staff, from frontline workers to senior leadership. Their success will depend on their ability to seamlessly integrate advanced technology into the agency’s everyday operations.
AI isn’t just another tool; it’s a force multiplier that can help solve those other pressing issues more effectively. Whether it’s accelerating drug approvals at the FDA or enhancing public health responses across HHS, AI has the potential to improve outcomes, save time, and reduce costs. By embedding AI experts within agencies, we’re not just addressing one problem—we’re empowering the entire department to tackle multiple challenges with greater efficiency and impact.
For top AI talent, the AI Corps offers a unique opportunity to make a difference at a scale that few private-sector roles can match. It’s a chance to apply their skills to public service, tackling some of the nation’s most critical challenges in healthcare, regulation, and beyond. The AI Corps members will have the opportunity to shape the future of AI in government, leaving a legacy of innovation and impact. The allure of making a tangible difference in people’s lives can be a powerful motivator for the right kind of talent.
While outsourcing AI talent or using consultants can offer short-term benefits, it often lacks the sustained engagement necessary for long-term success. Building in-house expertise through the AI Corps ensures that AI capabilities are deeply integrated into the agency’s operations and culture. A notable example illustrating the risks of overreliance on external contractors is the initial rollout of HealthCare.gov. The website faced significant technical issues at launch due to coordination challenges and insufficient in-house technical oversight, which hindered public access to essential healthcare services. In contrast, recent successful government initiatives—such as the efficient distribution of COVID-19 test kits and the timely processing of economic stimulus payments directly into bank accounts—demonstrate the positive impact of having the right technical experts within government agencies.
Collaboration is crucial to the AI Corps’ success. Instead of working in isolation, AI Corps members will integrate with existing IT and data teams, bringing specialized AI knowledge that complements the teams’ expertise. This partnership approach ensures that AI initiatives are well-grounded in the agencies’ existing infrastructure and aligned with ongoing IT projects. The AI Corps will serve as a catalyst, amplifying the capabilities of existing teams rather than duplicating their efforts.
The AI Corps is focused on augmentation, not replacement. The primary goal is to empower existing staff with advanced tools and processes, enhancing their work rather than replacing them. AI Corps members will collaborate closely with agency employees to automate routine tasks and free up time for more meaningful activities. A 2021 study by the Boston Consulting Group found that 60% of employees view AI as a coworker rather than a replacement. This reflects the intent of the AI Corps—to build capacity within agencies and ensure that AI is a tool that amplifies human effort, fostering a more efficient and effective workforce.
Success for the AI Corps program means that each HHS agency has made measurable progress toward integrating AI and related technologies, tailored to their specific needs and maturity levels. Within one to two years, agencies might have established robust data infrastructures, migrated platforms to the cloud, or developed pilot AI projects that address key challenges. Success also includes fostering a culture of innovation and experimentation, with AI Corps members identifying opportunities and creating proofs of concept in low-risk environments. By collaborating across agencies, these experts support each other and amplify the program’s impact. Ultimately, success is reflected in enhanced capabilities and efficiencies within agencies, setting a strong foundation for ongoing technological advancement aligned with each agency’s mission.
Public Comment on Executive Branch Agency Handling of CAI containing PII
Public comments serve the executive branch by informing more effective, efficient program design and regulation. As part of our commitment to evidence-based, science-backed policy, FAS staff leverage public comment opportunities to embed science, technology, and innovation into policy decision-making.
The Federation of American Scientists (FAS) is a non-partisan, nonprofit organization committed to using science and technology to benefit humanity by delivering on the promise of equitable and impactful policy. FAS believes that society benefits from a federal government that harnesses science, technology, and innovation to meet ambitious policy goals and deliver impactful results to the public.
We are writing in response to your Request for Information on the Executive Branch Agency Handling of Commercially Available Information (CAI) Containing Personally Identifiable Information (PII). Specifically, we will be answering questions 2 and 5 in your request for information:
2. What frameworks, models, or best practices should [the White House Office of Management and Budget] consider as it evaluates agency standards and procedures associated with the handling of CAI containing PII and considers potential guidance to agencies on ways to mitigate privacy risks from agencies’ handling of CAI containing PII?
5. Agencies provide transparency into the handling of PII through various means (e.g., policies and directives, Privacy Act statements and other privacy notices at the point of collection, Privacy Act system of records notices, and privacy impact assessments). What, if any, improvements would enhance the public’s understanding of how agencies handle CAI containing PII?
Background
In the digital landscape, commercially available information (CAI) represents a vast ecosystem of personal data that can be easily obtained, sold, or licensed to various entities. The Executive Order on Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence (EO 14110) defines CAI comprehensively as information about individuals or groups that is publicly accessible, encompassing details like device information and location data.
A 2017 report by the Georgetown Law Review found that 63% of Americans can be uniquely identified using just three basic attributes—gender, birth date, and ZIP code—with an astonishing 99.98% of individuals potentially re-identifiable from a dataset containing only 15 fundamental characteristics. This vulnerability underscores the critical challenges of data privacy in an increasingly interconnected world.
CAI takes on heightened significance in the context of artificial intelligence (AI) deployment, as these systems enable both data collection and the use of advanced inference models to analyze datasets and produce predictions, insights, and assumptions that reveal patterns or relationships not directly evident in the data. Some AI systems can allow the intentional or unintentional reidentification of supposedly anonymized private data. These capabilities raise questions about privacy, consent, and the potential for unprecedented levels of personal information aggregation and analysis, challenging existing data protection frameworks and individual rights.
The United States federal government is one of the largest customers of commercial data brokers. Government entities increasingly use CAI to empower public programs, enabling federal agencies to augment decision-making, policy development, and resource allocation and enrich research and innovation goals with large yet granular datasets. For example, the National Institutes of Health have discussed within their data strategies how to incorporate commercially available data into research projects. The use of commercially available electronic health records is essential for understanding social inequalities within the healthcare system but includes sensitive personal data that must be protected.
However, government agencies face significant public scrutiny over their use of CAI in areas including law enforcement, homeland security, immigration, and tax administration. This scrutiny stems from concerns about privacy violations, algorithmic bias, and the risks of invasive surveillance, profiling, and discriminatory enforcement practices that could disproportionately harm vulnerable populations. For example, federal agencies like Immigration and Customs Enforcement (ICE) and Customs and Border Protection (CBP) have used broker-purchased location data to track individuals without warrants, raising constitutional concerns.
In 2020, the American Civil Liberties Union filed a Freedom of Information Act lawsuit against several Department of Homeland Security (DHS) agencies, arguing that the DHS’s use of cellphone data and data from smartphone apps constitutes unreasonable searches without a warrant and violates the Fourth Amendment. A report by the Electronic Frontier Foundation found that CAI was used for mass surveillance practices, including geofence warrants that query all phones in specific locations, further challenging constitutional protections.
While the Privacy Act of 1974 covers the use of federally collected personal information by agencies, there is no explicit guidance governing federal use of third-party data. The bipartisan Fourth Amendment is Not for Sale Act (H.R.4639) would bar certain technology providers—such as remote computing service and electronic communication service providers—from sharing the contents of stored electronic communications with anyone (including government actors) and from sharing customer records with government agencies. The bill has passed the House of Representatives in the 118th Congress but has yet to pass the Senate as of December 2024. Without protections in statute, it is imperative that the federal government crafts clear guidance on the use of CAI containing PII in AI systems. In this response to the Office of Management and Budget’s (OMB) request for information, FAS will outline three policy ideas that can improve how federal agencies navigate the use of CAI containing PII, including in AI use.
Summary of Recommendations
The federal government is responsible for ensuring the safety and privacy of the processing of personally identifiable information within commercially available information used for the development and deployment of artificial intelligence systems. For this RFI, FAS brings three proposals to increase government capacity in ensuring transparency and risk mitigation in how CAI containing PII is used, including in agency use of AI:
- Enable FedRAMP to Create an Authorization System for Third-Party Data Sources: An authorization framework for CAI containing PII would ensure a standardized approach for data collection, management, and contracting, mitigating risks, and ensuring ethical data use.
- Expand Existing Privacy Impact Assessments (PIA) to Incorporate Additional Requirements and Periodic Evaluations: Regular public reports on CAI sources and usage will enable stakeholders to monitor federal data practices effectively.
- Build Government Capacity for the Use of Privacy Enhancing Technologies to Bolster Anonymization Techniques by harnessing existing resources such as the United States Digital Service (USDS).
Recommendation 1. Enable FedRAMP to Create an Authorization System for Third-Party Data Sources
Government agencies utilizing CAI should implement a pre-evaluation process before acquiring large datasets to ensure privacy and security. OMB, along with other agencies that are a part of the governing board of the Federal Risk and Authorization Management Program (FedRAMP), should direct FedRAMP to create an authorization framework for third-party data sources that contract with government agencies, especially data brokers that provide CAI with PII, to ensure that these vendors comply with privacy and security requirements. FedRAMP is uniquely positioned for this task because of its previous mandate to ensure the safety of cloud service providers used by the federal government and its recent expansion of this mandate to standardize AI technologies. The program could additionally harmonize its new CAI requirements with its forthcoming AI authorization framework.
When designing the content of the CAI authorization, a useful benchmark in terms of evaluation criteria is the Ag Data Transparent (ADT) certification process. Companies applying for this certification must submit contracts and respond to 11 data collection, usage, and sharing questions. Like the FedRAMP authorization process, a third-party administrator reviews these materials for consistency, granting the ADT seal only if the company’s practices align with its contracts. Any discrepancies must be corrected, promoting transparency and protecting farmers’ data rights. The ADT is a voluntary certification, and therefore does not provide a good model for enforcement. However, it does provide a framework for the kind of documentation that should be required. The CAI authorization should thus include the following information required by the ADT certification process:
- Data source: The origin or provider of the data, such as a specific individual, organization, database, device, or system, that supplies information for analysis or processing, as well as the technologies, platforms, or applications used to collect data. For example, the authorization framework should identify if an AI system collected, compiled, or aggregated a CAI dataset.
- Data categories: The classification of data based on its format or nature, such as structured (e.g., spreadsheets), unstructured (e.g., text or images), personal (e.g., names, Social Security numbers), or non-personal (e.g., aggregated statistics).
- Data ownership: A description of any agreements in place that define which individual or organization owns the data and what happens when that ownership is transferred.
- Third-party data collection contractors: An explanation of whether or not partners or contractors associated with the vendor have to follow the company’s data governance standards.
- Consent and authorization to sell to third-party contractors: A description of whether or not there is an explicit agreement between data subjects (e.g., an individual using an application) that their data can be collected and sold to the government or another entity for different purposes, such as use to train or deploy an AI system. In addition, a description of the consent that has been obtained for that use.
- Opt out and deletion: Whether or not the data can be deleted at the request of a data subject, or if the data subject opt out of certain data use. A description of the existing mechanisms where individuals can decline or withdraw consent for their data to be collected, processed, or used, ensuring they retain control over their personal information.
- Security safeguards and breach notifications: The measures and protocols implemented to protect data from unauthorized access, breaches, and misuse. These include encryption, access controls, secure storage, vulnerability testing, and compliance with industry security standards.
Unlike the ADT, a FedRAMP authorization process can be strictly enforced. FedRAMP is mandatory for all cloud service providers working with the executive branch and follows a detailed authorization process with evaluations and third-party auditors. It would be valuable to bring that assessment rigor to federal agency use of CAI, and would help provide clarity to commercial vendors.
The authorization framework should also document the following specific protocols for the use of CAI within AI systems:
- Provide a detailed explanation of which datasets were aggregated and the efforts to minimize data. According to a report by the Information Systems Audit and Control Association (ISACA), singular data points, when combined, can compromise anonymity, especially when placed through an AI system with inference capabilities.
- Type of de-identification or anonymization technique used. Providing this information helps agencies assess whether additional measures are necessary, particularly when using AI systems capable of recognizing patterns that could re-identify individuals.
By setting these standards, this authorization could help agencies understand privacy risks and ensure the reliability of CAI data vendors before deploying purchased datasets within AI systems or other information systems, therefore setting them up to create appropriate mitigation strategies.
By encouraging data brokers to follow best practices, this recommendation would allow agencies to focus on authorized datasets that meet privacy and security standards. Public availability of this information could drive market-wide improvements in data governance and elevate trust in responsible data usage. This approach would support ethical data governance in AI projects and create a more transparent, publicly accountable framework for CAI use in government.
Recommendation 2. Expand Privacy Impact Assessments (PIA) to Incorporate Additional Requirements and Periodic Evaluations
Public transparency regarding the origins and details of government-acquired CAI containing PII is critical, especially given the largely unregulated nature of the data broker industry at the federal level. Privacy Impact Assessments (PIAs) are mandated under Section 208 of the 2002 E-Government Act and OMB Memo M-03-22, and can serve as a vital policy tool for ensuring such transparency. Agencies must complete PIAs at the outset of any new electronic information collection process that includes “information in identifiable form for ten or more persons.” Under direction from Executive Order 14110 on Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence, OMB issued a request for information in April 2024 to explore updating PIA guidance for AI-era privacy concerns, although new guidance has not yet been issued.
To ensure that PIAs can effectively provide transparency into government practices on CAI that contains PII, we recommend that OMB provide updated guidance requiring agencies to regularly review and update their PIAs at least every three years, and also require agencies to report more comprehensive information in PIAs. We provide more details on these recommendations below.
First, OMB should guide agencies to periodically update their PIAs to ensure evolutions in agency data practices are publicly captured, which is increasingly important as data-driven AI systems are adopted by government actors and create novel privacy concerns. Under OMB Memo M-03-22, agencies must initiate or update PIAs when new privacy risks or factors emerge that affect the collection and handling of PII, including when agencies incorporate PII obtained from commercial or public sources into existing information systems. However, a public comment submitted by the Electronic Privacy Information Center (EPIC) pointed out that many agencies fail to publish and update required PIAs in a timely manner, indicating that a stricter schedule is needed to maintain accountability for PIA reporting requirements. As data privacy risks evolve through the advancement of AI systems, increased cybersecurity risks, and new legislation, it is essential that a minimum standard schedule for updating PIAs is created to ensure agencies provide the public with an up-to-date understanding of the potential risks resulting from using CAI that includes PII. For example, the European Union’s General Data Protection Regulation (Art. 35) requires PIAs to be reconducted every three years.
Second, agency PIAs should report more detailed information on the CAI’s source, vendor information, contract agreements, and licensing arrangements. A frequent critique of existing PIAs is that they contain too little information to inform the public of relevant privacy harms. Such a lack of transparency risks damaging public trust in government. One model for expanded reporting frameworks for CAI containing PII is the May 2024 Policy Framework for CAI, established for the Intelligence Community (IC) by the Office of the Director of National Intelligence (ODNI). This framework requires the IC to document and report “the source of the Sensitive CAI and from whom the Sensitive CAI was accessed or collected” and “any licensing agreements and/or contract restrictions applicable to the Sensitive CAI”. OMB should incorporate these reporting practices into agency PIA requirements and explicitly require agencies to identify the CAI data vendor in order to provide insight into the source and quality of purchased data.
Many of these elements are also present in Recommendation 1, for a new FedRAMP authorization framework. However, that recommendation does not include existing agency projects using CAI or agencies that could contract CAI datasets outside of the FedRAMP authorization. Including this information within the PIA framework also allows for an iterative understanding of privacy risks throughout the lifecycle of a project using CAI.
By obligating agencies to provide more frequent PIA updates and include additional details on the source, vendor, contract and licensing arrangements for CAI containing PII, the public gains valuable insight into how government agencies acquire, use, and manage sensitive data. These updates to PIAs would allow civil society groups, journalists, and other external stakeholders to track government data management practices over time during this critical juncture where federal uptake of AI systems is rapidly increasing.
Recommendation 3. Build Government Capacity for the Use of Privacy Enhancing Technologies to Bolster Anonymization Techniques
Privacy Enhancing Technologies (PETs) are a diverse set of tools that can be used throughout the data lifecycle to ensure privacy by design. They can also be powerful tools in ensuring that PII within CAI) is adequately anonymized and secure. OMB should collect information on current agency PET usage, gather best practices, and identify deployment gaps. To address these gaps, OMB should collaborate with agencies like the USDS to establish capacity-building programs, leveraging initiatives like the proposed “Responsible Data Sharing Core” to provide expert consultations and enhance responsible data-sharing practices.
Meta’s Open Loop project identified eight types of PETs that are ripe to be deployed in AI systems, categorizing them into maturity levels, context of deployment, and limitations. One type of PET is differential privacy, a mathematical framework designed to protect individuals’ privacy in datasets by introducing controlled noise to the data. This ensures that the output of data analysis or AI models does not reveal whether a specific individual’s information is included in the dataset. The noise is calibrated to balance privacy with data utility, allowing meaningful insights to be derived without compromising personal information. Differential privacy is particularly useful in AI models that rely on large-scale data for training, as it prevents the inadvertent exposure of PII during the learning process. Within the federal government, the U.S. Census Bureau is using differential privacy to anonymize data while preserving its aggregate utility, ensuring compliance with privacy regulations and reducing re-identification within datasets.
Scaling the use of PETs in other agencies has been referenced in several U.S. government strategy documents, such as the National Strategy to Advance Privacy-Preserving Data Sharing and Analytics, which encourages federal agencies to adopt and invest in the development of PETs, and the Executive Order (EO) on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence, which calls for federal agencies to identify where they could use PETs. As a continuation of this EO, the National Science Foundation and the Department of Energy established a Research Coordination Network on PETs that will “address the barriers to widespread adoption of PETs, including regulatory considerations.”
Although the ongoing research and development of PETS is vital to this growing field, there is an increasing need to ensure these technologies are implemented across the federal government. To kick this off, OMB should collect detailed information on how agencies currently use PETs, especially in projects that use CAI containing PII. This effort should include gathering best practices from agencies with successful PET implementations, such as the previous U.S. Census Bureau’s use of differential privacy. Additionally, OMB should identify gaps in PET deployment, assessing barriers such as technical capacity, funding, and awareness of relevant PETs. To address these gaps, OMB should collaborate with other federal agencies to design and implement capacity-building programs, equipping personnel with the knowledge and tools needed to integrate PETs effectively. For example, a forthcoming FAS’ Day One Project publication, “Increasing Responsible Data Sharing Capacity throughout Government,” seeks to harness existing government capabilities to build government capacity in deploying PETs. This proposal aims to enhance responsible data sharing in government by creating a capacity-building initiative called the “Responsible Data Sharing Core” (RDSC). Managed by the USDS, the RDSC would deploy fellows and industry experts to agencies to consult on data use and sharing decisions and offer consultations on which PETs are appropriate for different contexts.
Conclusion
The federal government’s increasing reliance on CAI containing PII presents significant privacy challenges. The current landscape of data procurement and AI deployment by agencies like ICE, CBP, and others raises critical concerns about potential Fourth Amendment violations, discriminatory profiling, and lack of transparency.
The ideas proposed in this memo—implementing FedRAMPamp authorization for data brokers, expanding privacy impact assessment requirements, and developing capacity-building programs for privacy-enhancing technologies—represent crucial first steps in addressing these systemic risks. As AI systems become increasingly integrated into government processes, maintaining a delicate balance between technological advancement and fundamental constitutional protections will be paramount to preserving individual privacy, promoting responsible adoption, and maintaining public trust.
We appreciate the opportunity to contribute to this Request for Information on Executive Branch Agency Handling of Commercially Available Information Containing Personally Identifiable Information. Please contact clangevin@fas.org if you have any questions or need additional information.
Teacher Education Clearinghouse for AI and Data Science
The next presidential administration should develop a teacher education and resource center that includes vetted, free, self-guided professional learning modules, resources to support data-based classroom activities, and instructional guides pertaining to different learning disciplines. This would provide critical support to teachers to better understand and implement data science education and use of AI tools in their classroom. Initial resource topics would be:
- An Introduction to AI, Data Literacy, and Data Science
- AI & Data Science Pedagogy
- AI and Data Science for Curriculum Development & Improvement
- Using AI Tools for Differentiation, Assessment & Feedback
- Data Science for Ethical AI Use
In addition, this resource center would develop and host free, pre-recorded, virtual training sessions to support educators and district professionals to better understand these resources and practices so they can bring them back to their contexts. This work would improve teacher practice and cut administrative burdens. A teacher education resource would lessen the digital divide and ensure that our educators are prepared to support their students in understanding how to use AI tools so that each and every student can be college and career ready and competitive at the global level. This resource center would be developed using a process similar to the What Works Clearinghouse, such that it is not endorsing a particular system or curriculum, but is providing a quality rating, based on the evidence provided.
Challenge and Opportunity
AI is an incredible technology that has the power to revolutionize many areas, especially how educators teach and prepare the next generation to be competitive in higher education and the workforce. A recent RAND study showed leaders in education indicating promise in adapting instructional content to fit the level of their students and for generating instructional materials and lesson plans. While this technology holds a wealth of promise, the field has developed so rapidly that people across the workforce do not understand how best to take advantage of AI-based technologies. One of the most crucial areas for this is in education. AI-enabled tools have the potential to improve instruction, curriculum development, and assessment, but most educators have not received adequate training to feel confident using them in their pedagogy. In a Spring 2024 pilot study (Beiting-Parrish & Melville, in preparation), initial results indicated that 64.3% of educators surveyed had not had any professional development or training in how to use AI tools. In addition, more than 70% of educators surveyed felt they did not know how to pick AI tools that are safe for use in the classroom, and that they were not able to detect biased tools. Additionally, the RAND study indicated only 18% of educators reported using AI tools for classroom purposes. Within those 18%, approximately half of those educators used AI because they had been specifically recommended or directly provided a tool for classroom use. This suggests that educators need to be given substantial support in choosing and deploying tools for classroom use. Providing guidance and resources to support vetting tools for safe, ethical, appropriate, and effective instruction is one of the cornerstone missions of the Department of Education. This education should not rest on the shoulders of individual educators who are known to have varying levels of technical and curricular knowledge, especially for veteran teachers who have been teaching for more than a decade.
If the teachers themselves do not have enough professional development or expertise to select and teach new technology, they cannot be expected to thoroughly prepare their students to understand emerging technologies, such as AI, nor the underpinning concepts necessary to understand these technologies, most notably data science and statistics. As such, students’ futures are being put at risk from a lack of emphasis in data literacy that is apparent across the nation. Recent results from the National Assessment of Education Progress (NAEP), assessment scores show a shocking decline in student performance in data literacy, probability, and statistics skills – outpacing declines in other content areas. In 2019, the NAEP High School Transcript Study (HSTS) revealed that only 17% of students completed a course in statistics and probability, and less than 10% of high school students completed AP Statistics. Furthermore, the HSTS study showed that less than 1% of students completed a dedicated course in modern data science or applied data analytics in high school. Students are graduating with record-low proficiency in data, statistics, and probability, and graduating without learning modern data science techniques. While students’ data and digital literacy are failing, there is a proliferation of AI content online; they are failing to build the necessary critical thinking skills and a discerning eye to determine what is real versus what has been AI-generated, and they aren’t prepared to enter the workforce in sectors that are booming. The future the nation’s students will inherit is one in which experience with AI tools and Big Data will be expected to be competitive in the workforce.
Whether students aren’t getting the content because it isn’t given its due priority, or because teachers aren’t comfortable teaching the content, AI and Big Data are here, and our educators don’t have the tools to help students get ready for a world in the midst of a data revolution. Veteran educators and preservice education programs alike may not have an understanding of the essential concepts in statistics, data literacy, or data science that allow them to feel comfortable teaching about and using AI tools in their classes. Additionally, many of the standard assessment and practice tools are not fit for use any longer in a world where every student can generate an A-quality paper in three seconds with proper prompting. The rise of AI-generated content has created a new frontier in information literacy; students need to know to question the output of publically available LLM-based tools, such as Chat-GPT, as well as to be more critical of what they see online, given the rise of AI-generated deep fakes, and educators need to understand how to either incorporate these tools into their classrooms or teach about them effectively. Whether educators are ready or not, the existing Digital Divide has the potential to widen, depending on whether or not they know how to help students understand how to use AI safely and effectively and have the access to resources and training to do so.
The United States finds itself at a crossroads in the global data boom. Demand in the economic marketplace, and threat to national security by way of artificial intelligence and mal-, mis-, and disinformation, have educators facing an urgent problem in need of an immediate solution. In August of 1958, 66 years ago, Congress passed the National Defense Education Act (NDEA), emphasizing teaching and learning in science and mathematics. Specifically in response to the launch of Sputnik, the law supplied massive funding to, “insure trained manpower of sufficient quality and quantity to meet the national defense needs of the United States.” The U.S. Department of Education, in partnership with the White House Office of Science and Technology Policy, must make bold moves now to create such a solution, as Congress did once before.
Plan of Action
In the years since the Space Race, one problem with STEM education persists: K-12 classrooms still teach students largely the same content; for example, the progression of high school mathematics including algebra, geometry, and trigonometry is largely unchanged. We are no longer in a race to space – we’re now needing to race against data. Data security, artificial intelligence, machine learning, and other mechanisms of our new information economy are all connected to national security, yet we do not have educators with the capacity to properly equip today’s students with the skills to combat current challenges on a global scale. Without a resource center to house the urgent professional development and classroom activities America’s educators are calling for, progress and leadership in spaces where AI and Big Data are being used will continue to dwindle, and our national security will continue to be at risk. It’s beyond time for a new take on the NDEA that emphasizes more modern topics in the teaching and learning of mathematics and science, by way of data science, data literacy, and artificial intelligence.
Previously, the Department of Education has created resource repositories to support the dissemination of information to the larger educational praxis and research community. One such example is the What Work Clearinghouse, a federally vetted library of resources on educational products and empirical research that can support the larger field. The WWC was created to help cut through the noise of many different educational product claims to ensure that only high-quality tools and research were being shared. A similar process is happening now with AI and Data Science Resources; there are a lot of resources online, but many of these are of dubious quality or are even spreading erroneous information.
To combat this, we suggest the creation of something similar to the WWC, with a focus on vetted materials for educator and student learning around AI and Data Science. We propose the creation of the Teacher Education Clearinghouse (TEC) underneath the Institute of Education Sciences, in partnership with the Office of Education Technology. Currently, WWC costs approximately $2,500,000 to run, so we anticipate a similar budget for the TEC website. The resource vetting process would begin with a Request for Information from the larger field that would encourage educators and administrators to submit high quality materials. These materials would be vetted using an evaluation framework that looks for high quality resources and materials.
For example, the RFI might request example materials or lesson goals for the following subjects:
- An Introduction to AI, Data Literacy, and Data Science
- Introduction to AI & Data Science Literacy & Vocabulary
- Foundational AI Principles
- Cross-Functional Data Literacy and Data Science
- LLMs and How to Use Them
- Critical Thinking and Safety Around AI Tools
- AI & Data Science Pedagogy
- AI and Data Science for Curriculum Development & Improvement
- Using AI Tools for Differentiation, Assessment & Feedback
- Data Science for Safe and Ethical AI Use
- Characteristics of Potentially Biased Algorithms and Their Shortcomings
A framework for evaluating how useful these contributions might be for the Teacher Education Clearinghouse would consider the following principles:
- Accuracy and relevance to subject matter
- Availability of existing resources vs. creation of new resources
- Ease of instructor use
- Likely classroom efficacy
- Safety, responsible use, and fairness of proposed tool/application/lesson
Additionally, this would also include a series of quick start guide books that would be broken down by topic and include a set of resources around foundational topics such as, “Introduction to AI” and “Foundational Data Science Vocabulary”.
When complete, this process would result in a national resource library, which would house a free series of asynchronous professional learning opportunities and classroom materials, activities, and datasets. This work could be promoted through the larger DoE as well as through the Regional Educational Laboratory program and state level stakeholders. The professional learning would consist of prerecorded virtual trainings and related materials (ex: slide decks, videos, interactive components of lessons, etc.). The materials would include educator-facing materials to support their professional development in Big Data and AI alongside student-facing lessons on AI Literacy that teachers could use to support their students. All materials would be publicly available for download on an ED-owned website. This will allow educators from any district, and any level of experience, to access materials that will improve their understanding and pedagogy. This especially benefits educators from less resourced environments because they can still access the training they need to adequately support their students, regardless of local capacity for potentially expensive training and resource acquisition. Now is the time to create such a resource center because there currently isn’t a set of vetted and reliable resources that are available and accessible to the larger educator community and teachers desperately need these resources to support themselves and their students in using these tools thoughtfully and safely. The successful development of this resource center would result in increased educator understanding of AI and data science such that the standing of U.S. students increases on such international measurements as the International Computer and Information Literacy Study (ICILS), as well as increased participation in STEAM fields that rely on these skills.
Conclusion
The field of education is at a turning point; the rise of advancements in AI and Big Data necessitate increased focus on these areas in the K-12 classroom; however, most educators do not have the preparation needed to adequately teach these topics to fully prepare their students. For the United States to continue to be a competitive global power in technology and innovation, we need a workforce that understands how to use, apply, and develop new innovations using AI and Data Science. This proposal for a library of high quality, open-source, vetted materials would support democratization of professional development for all educators and their students.
Modernizing AI Analysis in Education Contexts
The 2022 release of ChatGPT and subsequent foundation models sparked a generative AI (GenAI) explosion in American society, driving rapid adoption of AI-powered tools in schools, colleges, and universities nationwide. Education technology was one of the first applications used to develop and test ChatGPT in a real-world context. A recent national survey indicated that nearly 50% of teachers, students, and parents use GenAI Chatbots in school, and over 66% of parents and teachers believe that GenAI Chatbots can help students learn more and faster. While this innovation is exciting and holds tremendous promise to personalize education, educators, families, and researchers are concerned that AI-powered solutions may not be equally useful, accurate, and effective for all students, in particular students from minoritized populations. It is possible that as this technology further develops that bias will be addressed; however, to ensure that students are not harmed as these tools become more widespread it is critical for the Department of Education to provide guidance for education decision-makers to evaluate AI solutions during procurement, to support EdTech developers to detect and mitigate bias in their applications, and to develop new fairness methods to ensure that these solutions serve the students with the most to gain from our educational systems. Creating this guidance will require leadership from the Department of Education to declare this issue as a priority and to resource an independent organization with the expertise needed to deliver these services.
Challenge and Opportunity
Known Bias and Potential Harm
There are many examples of the use of AI-based systems introducing more bias into an already-biased system. One example with widely varying results for different student groups is the use of GenAI tools to detect AI-generated text as a form of plagiarism. Liang et. al found that several GPT-based plagiarism checkers frequently identified the writing of students for whom English is not their first language as AI-generated, even though their work was written before ChatGPT was available. The same errors did not occur with text generated by native English speakers. However, in a publication by Jiang (2024), no bias against non-native English speakers was encountered in the detection of plagiarism between human-authored essays and ChatGPT-generated essays written in response to analytical writing prompts from the GRE, which is an example of how thoughtful AI tool design and representative sampling in the training set can achieve fairer outcomes and mitigate bias.
Beyond bias, researchers have raised additional concerns about the overall efficacy of these tools for all students; however, more understanding around different results for subpopulations and potential instances of bias(es) is a critical aspect of deciding whether or not these tools should be used by teachers in classrooms. For AI-based tools to be usable in high-stakes educational contexts such as testing, detecting and mitigating bias is critical, particularly when the consequences of being incorrect are so high, such as for students from minoritized populations who may not have the resources to recover from an error (e.g., failing a course, being prevented from graduating school).
Another example of algorithmic bias before the widespread emergence of GenAI which illustrates potential harms is found in the Wisconsin Dropout Early Warning System. This AI-based tool was designed to flag students who may be at risk of dropping out of school; however, an analysis of the outcomes of these predictions found that the system disproportionately flagged African American and Hispanic students as being likely to drop out of school when most of these students were not at risk of dropping out). When teachers learn that one of their students is at risk, this may change how they approach that student, which can cause further negative treatment and consequences for that student, creating a self-fulfilling prophecy and not providing that student with the education opportunities and confidence that they deserve. These examples are only two of many consequences of using systems that have underlying bias and demonstrate the criticality of conducting fairness analysis before these systems are used with actual students.
Existing Guidance on Fair AI & Standards for Education Technology Applications
Guidance for Education Technology Applications
Given the harms that algorithmic bias can cause in educational settings, there is an opportunity to provide national guidelines and best practices that help educators avoid these harms. The Department of Education is already responsible for protecting student privacy and provides guidelines via the Every Student Succeeds Act (ESSA) Evidence Levels to evaluate the quality of EdTech solution evidence. The Office of Educational Technology, through support of a private non-profit organization (Digital Promise) has developed guidance documents for teachers and administrators, and another for education technology developers (U.S. Department of Education, 2023, 2024). In particular, “Designing for Education with Artificial Intelligence” includes guidance for EdTech developers including an entire section called “Advancing Equity and Protecting Civil Rights” that describes algorithmic bias and suggests that, “Developers should proactively and continuously test AI products or services in education to mitigate the risk of algorithmic discrimination.” (p 28). While this is a good overall guideline, the document critically is not sufficient to help developers conduct these tests.
Similarly, the National Institute of Standards and Technology has released a publication on identifying and managing bias in AI . While this publication highlights some areas of the development process and several fairness metrics, it does not provide specific guidelines to use these fairness metrics, nor is it exhaustive. Finally demonstrating the interest of industry partners, the EDSAFE AI Alliance, a philanthropically-funded alliance representing a diverse group of companies in educational technology, has also created guidance in the form of the 2024 SAFE (Safety, Accountability, Fairness, and Efficacy) Framework. Within the Fairness section of the framework, the authors highlight the importance of using fair training data, monitoring for bias, and ensuring accessibility of any AI-based tool. But again, this framework does not provide specific actions that education administrators, teachers, or EdTech developers can take to ensure these tools are fair and are not biased against specific populations. The risk to these populations and existing efforts demonstrate the need for further work to develop new approaches that can be used in the field.
Fairness in Education Measurement
As AI is becoming increasingly used in education, the field of educational measurement has begun creating a set of analytic approaches for finding examples of algorithmic bias, many of which are based on existing approaches to uncovering bias in educational testing. One common tool is called Differential Item Functioning (DIF), which checks that test questions are fair for all students regardless of their background. For example, it ensures that native English speakers and students learning English have an equal chance to succeed on a question if they have the same level of knowledge . When differences are found, this indicates that a student’s performance on that question is not based on their knowledge of the content.
While DIF checks have been used for several decades as a best practice in standardized testing, a comparable process in the use of AI for assessment purposes does not yet exist. There also is little historical precedent indicating that for-profit educational companies will self-govern and self-regulate without a larger set of guidelines and expectations from a governing body, such as the federal government.
We are at a critical juncture as school districts begin adopting AI tools with minimal guidance or guardrails, and all signs point to an increase of AI in education. The US Department of Education has an opportunity to take a proactive approach to ensuring AI fairness through strategic programs of support for school leadership, developers in educational technology, and experts in the field. It is important for the larger federal government to support all educational stakeholders under a common vision for AI fairness while the field is still at the relative beginning of being adopted for educational use.
Plan of Action
To address this situation, the Department of Education’s Office of the Chief Data Officer should lead development of a national resource that provides direct technical assistance to school leadership, supports software developers and vendors of AI tools in creating quality tech, and invests resources to create solutions that can be used by both school leaders and application developers. This office is already responsible for data management and asset policies, and provides resources on grants and artificial intelligence for the field. The implementation of these resources would likely be carried out via grants to external actors with sufficient technical expertise, given the rapid pace of innovation in the private and academic research sectors. Leading the effort from this office ensures that these advances are answering the most important questions and can integrate them into policy standards and requirements for education solutions. Congress should allocate additional funding to the Department of Education to support the development of a technical assistance program for school districts, establish new grants for fairness evaluation tools that span the full development lifecycle, and pursue an R&D agenda for AI fairness in education. While it is hard to provide an exact estimate, similar existing programs currently cost the Department of Education between $4 and $30 million a year.
Action 1. The Department of Education Should Provide Independent Support for School Leadership Through a Fair AI Technical Assistance Center (FAIR-AI-TAC)
School administrators are hearing about the promise and concerns of AI solutions in the popular press, from parents, and from students. They are also being bombarded by education technology providers with new applications of AI within existing tools and through new solutions.
These busy school leaders do not have time to learn the details of AI and bias analysis, nor do they have the technical background required to conduct deep technical evaluations of fairness within AI applications. Leaders are forced to either reject these innovations or implement them and expose their students to significant potential risk with the promise of improved learning. This is not an acceptable status quo.
To address these issues, the Department of Education should create an AI Technical Assistance Center (the Center) that is tasked with providing direct guidance to state and local education leaders who want to incorporate AI tools fairly and effectively. The Center should be staffed by a team of professionals with expertise in data science, data safety, ethics, education, and AI system evaluation. Additionally, the Center should operate independently of AI tool vendors to maintain objectivity.
There is precedent for this type of technical support. The U.S. Department of Education’s Privacy Technical Assistance Center (PTAC) provides guidance related to data privacy and security procedures and processes to meet FERPA guidelines; they operate a help desk via phone or email, develop training materials for broad use, and provide targeted training and technical assistance for leaders. A similar kind of center could be stood up to support leaders in education who need support evaluating proposed policy or procurement decisions.
This Center should provide a structured consulting service offering a variety of levels of expertise based on the individual stakeholder’s needs and the variety of levels of potential impact of the system/tool being evaluated on learners; this should include everything from basic levels of AI literacy to active support in choosing technological solutions for educational purposes. The Center should partner with external organizations to develop a certification system for high-quality AI educational tools that have passed a series of fairness checks. Creating a fairness certification (operationalized by third party evaluators) would make it much easier for school leaders to recognize and adopt fair AI solutions that meet student needs.
Action 2. The Department of Education Should Provide Expert Services, Data, and Grants for EdTech Developers
There are many educational technology developers with AI-powered innovations. Even when well-intentioned, some of these tools do not achieve their desired impacts or may be unintentionally unsafe due to a lack of processes and tests for fairness and safety.
Educational Technology developers generally operate under significant constraints when incorporating AI models into their tools and applications. Student data is often highly detailed and deeply personal, potentially containing financial, disability, and educational status information that is currently protected by FERPA, which makes it unavailable for use in AI model training or testing.
Developers need safe, legal, and quality datasets that they can use for testing for bias, as well as appropriate bias evaluation tools. There are several promising examples of these types of applications and new approaches to data security, such as the recently awarded NSF SafeInsights project, which allows analysis without disclosing the underlying data. In addition, philanthropically-funded organizations such as the Allen Institute for AI have released LLM evaluation tools that could be adapted and provided to Education Technology developers for testing. A vetted set of evaluation tools, along with more detailed technical resources and instructions for how to use them would encourage developers to incorporate bias evaluations early and often. Currently, there are very few market incentives or existing requirements that push developers to invest the necessary time or resources into this type of fairness analysis. Thus, the government has a key role to play here.
The Department of Education should also fund a new grant program that tasks grantees with developing a robust and independently validated third-party evaluation system that checks for fairness violations and biases throughout the model development process from pre-processing of data, to the actual AI use, to testing after AI results are created. This approach would support developers in ensuring that the tools they are publishing meet an agreed-upon minimum threshold for safe and fair use and could provide additional justification for the adoption of AI tools by school administrators.
Action 3. The Department of Education Should Develop Better Fairness R&D Tools with Researchers
There is still no consensus on best practices for how to ensure that AI tools are fair. As AI capabilities evolve, the field needs an ongoing vetted set of analyses and approaches that will ensure that any tools being used in an educational context are safe and fair for use with no unintended consequences.
The Department of Education should lead the creation of a a working group or task force comprised of subject matter experts from education, educational technology, educational measurement, and the larger AI field to identify the state of the art in existing fairness approaches for education technology and assessment applications, with a focus on modernized conceptions of identity. This proposed task force would be an inter-organizational group that would include representatives from several different federal government offices, such as the Office of Educational Technology and the Chief Data Office as well as prominent experts from industry and academia. An initial convening could be conducted alongside leading national conferences that already attract thousands of attendees conducting cutting-edge education research (such as the American Education Research Association and National Council for Measurement in Education).
The working group’s mandate should include creating a set of recommendations for federal funding to advance research on evaluating AI educational tools for fairness and efficacy. This research agenda would likely span multiple agencies including NIST, the Institute of Education Sciences of the U.S. Department of Education, and the National Science Foundation. There are existing models for funding early stage research and development with applied approaches, including the IES “Accelerate, Transform, Scale” programs that integrate learning sciences theory with efforts to scale theories through applied education technology program and Generative AI research centers that have the existing infrastructure and mandates to conduct this type of applied research.
Additionally, the working group should recommend the selection of a specialized group of researchers who would contribute ongoing research into new empirically-based approaches to AI fairness that would continue to be used by the larger field. This innovative work might look like developing new datasets that deliberately look for instances of bias and stereotypes, such as the CrowS-Pairs dataset. It may build on current cutting edge research into the specific contributions of variables and elements of LLM models that directly contribute to biased AI scores, such as the work being done by the AI company Anthropic. It may compare different foundation LLMs and demonstrate specific areas of bias within their output. It may also look like a collaborative effort between organizations, such as the development of the RSM-Tool, which looks for biased scoring. Finally, it may be an improved auditing tool for any portion of the model development pipeline. In general, the field does not yet have a set of universally agreed upon actionable tools and approaches that can be used across contexts and applications; this research team would help create these for the field.
Finally, the working group should recommend policies and standards that would incentivize vendors and developers working on AI education tools to adopt fairness evaluations and share their results.
Conclusion
As AI-based tools continue being used for educational purposes, there is an urgent need to develop new approaches to evaluating these solutions to fairness that include modern conceptions of student belonging and identity. This effort should be led by the Department of Education, through the Office of the Chief Data Officer, given the technical nature of the services and the relationship with sensitive data sources. While the Chief Data Officer should provide direction and leadership for the project, partnering with external organizations through federal grant processes would provide necessary capacity boosts to fulfill the mandate described in this memo.As we move into an age of widespread AI adoption, AI tools for education will be increasingly used in classrooms and in homes. Thus, it is imperative that robust fairness approaches are deployed before a new tool is used in order to protect our students, and also to protect the developers and administrators from potential litigation, loss of reputation, and other negative outcomes.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.
When AI is used to grade student work, fairness is evaluated by comparing the scores assigned by AI to those assigned by human graders across different demographic groups. This is often done using statistical metrics, such as the standardized mean difference (SMD), to detect any additional bias introduced by the AI. A common benchmark for SMD is 0.15, which suggests the presence of potential machine bias compared to human scores. However, there is a need for more guidance on how to address cases where SMD values exceed this threshold.
In addition to SMD, other metrics like exact agreement, exact + adjacent agreement, correlation, and Quadratic Weighted Kappa are often used to assess the consistency and alignment between human and AI-generated scores. While these methods provide valuable insights, further research is needed to ensure these metrics are robust, resistant to manipulation, and appropriately tailored to specific use cases, data types, and varying levels of importance.
Existing approaches to demographic post hoc analysis of fairness assume that there are two discrete populations that can be compared, for example students from African-American families vs. those not from African-American families, students from an English language learner family background vs. those that are not, and other known family characteristics. However in practice, people do not experience these discrete identities. Since at least the 1980s, contemporary sociological theories have emphasized that a person’s identity is contextual, hybrid, and fluid/changing. One current approach to identity that integrates concerns of equity that has been applied to AI is “intersectional identity” theory . This approach has begun to develop promising new methods that bring contemporary approaches to identity into evaluating fairness of AI using automated methods. Measuring all interactions between variables results in too small a sample; these interactions can be prioritized using theory or design principles or more advanced statistical techniques (e.g., dimensional data reduction techniques).
Driving Equitable Healthcare Innovations through an AI for Medicaid (AIM) Initiative
Artificial intelligence (AI) has transformative potential in the public health space – in an era when millions of Americans have limited access to high-quality healthcare services, AI-based tools and applications can enable remote diagnostics, drive efficiencies in implementation of public health interventions, and support clinical decision-making in low-resource settings. However, innovation driven primarily by the private sector today may be exacerbating existing disparities by training models on homogenous datasets and building tools that primarily benefit high socioeconomic status (SES) populations.
To address this gap, the Center for Medicare and Medicaid Innovation (CMMI) should create an AI for Medicaid (AIM) Initiative to distribute competitive grants to state Medicaid programs (in partnership with the private sector) for pilot AI solutions that lower costs and improve care delivery for rural and low-income populations covered by Medicaid.
Challenge & Opportunity
In 2022, the United States spent $4.5 trillion on healthcare, accounting for 17.3% of total GDP. Despite spending far more on healthcare per capita compared to other high-income countries, the United States has significantly worse outcomes, including lower life expectancy, higher death rates due to avoidable causes, and lesser access to healthcare services. Further, the 80 million low-income Americans reliant on state-administered Medicaid programs often have below-average health outcomes and the least access to healthcare services.
AI has the potential to transform the healthcare system – but innovation solely driven by the private sector results in the exacerbation of the previously described inequities. Algorithms in general are often trained on datasets that do not represent the underlying population – in many cases, these training biases result in tools and models that perform poorly for racial minorities, people living with comorbidities, and people of low SES. For example, until January 2023, the model used to prioritize patients for kidney transplants systematically ranked Black patients lower than White patients – the race component was identified and removed due to advocacy efforts within the medical community. AI models, while significantly more powerful than traditional predictive algorithms, are also more difficult to understand and engineer, resulting in the likelihood of further perpetuating such biases.
Additionally, startups innovating the digital health space today are not incentivized to develop solutions for marginalized populations. For example, in FY 2022, the top 10 startups focused on Medicaid received only $1.5B in private funding, while their Medicare Advantage (MA)-focused counterparts received over $20B. Medicaid’s lower margins are not attractive to investors, so digital health development targets populations that are already well-insured and have higher degrees of access to care.
The Federal Government is uniquely positioned to bridge the incentive gap between developers of AI-based tools in the private sector and American communities who would benefit most from said tools. Accordingly, the Center for Medicare and Medicaid Innovation (CMMI) should launch the AI for Medicaid (AIM) Initiative to incentivize and pilot novel AI healthcare tools and solutions targeting Medicaid recipients. Precedents in other countries demonstrate early success in state incentives unlocking health AI innovations – in 2023, the United Kingdom’s National Health Service (NHS) partnered with Deep Medical to pilot AI software that streamlines services by predicting and mitigating missed appointment risk. The successful pilot is now being adopted more broadly and is projected to save the NHS over $30M annually in the coming years.
The AIM Initiative, guided by the structure of the former Medicaid Innovation Accelerator Program (IAP), President Biden’s executive order on integrating equity into AI development, and HHS’ Equity Plan (2022), will encourage the private sector to partner with State Medicaid programs on solutions that benefit rural and low-income Americans covered by Medicaid and drive efficiencies in the overall healthcare system.
Plan of Action
CMMI will launch and operate the AIM Initiative within the Department of Health and Human Services (HHS). $20M of HHS’ annual budget request will be allocated towards the program. State Medicaid programs, in partnership with the private sector, will be invited to submit proposals for competitive grants. In addition to funding, CMMI will leverage the former structure of the Medicaid IAP program to provide state Medicaid agencies with technical assistance throughout their participation in the AIM Initiative. The programs ultimately selected for pilot funding will be monitored and evaluated for broader implementation in the future.
Sample Detailed Timeline
- 0-6 months:
- HHS Secretary to announce and launch the AI for Medicaid (AIM) Initiative within CMMI (e.g., delineating personnel responsibilities and engaging with stakeholders to shape the program)
- HHS to include AIM funding in annual budget request to Congress ($20M allocation)
- 6-12 months:
- CMMI to engage directly with state Medicaid agencies to support proposal development and facilitate connections with private sector partners
- CMMI to complete solicitation period and select ~7-10 proposals for pilot funding of ~$2-5M each by end of Year 1
- Year 2-7: Launch and roll out selected AI projects, led by state Medicaid agencies with continued technical assistance from CMMI
- Year 8: CMMI to produce an evaluative report and provide recommendations for broader adoption of AI tools and solutions within Medicaid-covered and other populations
Risks and Limitations
- Participation: Success of the initiative relies on state Medicaid programs and private sector partners’ participation. To mitigate this risk, CMMI will engage early with the National Association of Medicaid Directors (NAMD) to generate interest and provide technical assistance in proposal development. These conversations will also include input and support from the HHS Office of the Chief AI Officer (OCAIO) and its AI Council/Community of Practice. Further, startups in the healthcare AI space will be invited to engage with CMMI on identifying potential partnerships with state Medicaid agencies. A secondary goal of the initiative will be to ensure a number of private sector partners are involved in AIM.
- Oversight: AI is at the frontier of technological development today, and it is critical to ensure guardrails are in place to protect patients using AI technologies from potential adverse outcomes. To mitigate this risk, state Medicaid agencies will be required to submit detailed evaluation plans with their proposals. Additionally, informed consent and the ability to opt-out of data sharing when engaging with personally identifiable information (PII) and diagnostic or therapeutic technologies will be required. Technology partners (whether private, academic, or public sector) will further be required to demonstrate (1) adequate testing to identify and reduce bias in their AI tools to reasonable standards, (2) engagement with beneficiaries in the development process, and (3) leveraging testing environments that reflect the particular context of the Medicaid population. Finally, all proposals must adhere to guidelines published by AI guidelines adopted by HHS and the federal government more broadly, such as the CMS AI Playbook, the HHS Trustworthy AI Playbook, and any imminent regulations.
- Longevity: As a pilot grant program, the initiative does not promise long-term results for the broader population and will only facilitate short-term projects at the state level. Consequently, HHS leadership must remain committed to program evaluation and a long-term outlook on how AI can be integrated to support Americans more broadly. AI technologies or tools considered for acquisition by state Medicaid agencies or federal agencies after pilot implementation should ensure compliance with OMB guidelines.
Conclusion
The AI for Medicaid Initiative is an important step in ensuring the promise of artificial intelligence in healthcare extends to all Americans. The initiative will enable the piloting of a range of solutions at a relatively low cost, engage with stakeholders across the public and private sectors, and position the United States as a leader in healthcare AI technologies. Leveraging state incentives to address a critical market failure in the digital health space can additionally unlock significant efficiencies within the Medicaid program and the broader healthcare system. The rural and low-income Americans reliant on Medicaid have too often been an afterthought in access to healthcare services and technologies – the AIM Initiative provides an opportunity to address this health equity gap.
This action-ready policy memo is part of Day One 2025 — our effort to bring forward bold policy ideas, grounded in science and evidence, that can tackle the country’s biggest challenges and bring us closer to the prosperous, equitable and safe future that we all hope for whoever takes office in 2025 and beyond.
PLEASE NOTE (February 2025): Since publication several government websites have been taken offline. We apologize for any broken links to once accessible public data.