How to Safely Bring AI into Law Enforcement: The Case of AI-Generated Police Reports
Commercial artificial intelligence tools have recently emerged that are able to produce police reports. Some police departments have already adopted this technology. Also, some individual officers are using publicly-available AI tools. If AI could greatly reduce the time spent producing police reports, this could either substantially reduce the cost of policing, or free up police officers for other work. However, if the resulting reports are inaccurate, incomplete or biased, or if the process leaks confidential information, this could undermine the criminal justice system and harm citizens, perhaps causing an innocent person to be charged with a crime while the actual criminal is overlooked. At this time, both the benefits and the risks are poorly understood.
Yet, despite the uncertainty, each of the more than 18 thousand law enforcement agencies in the U.S. must make its own decision about the use of AI. These agencies do not have the expertise or resources to assess whether any of the AI-based products on the market are right for them, and if so, what training, departmental policies and deployment strategies are needed to use the technology both safely and effectively.
This memo proposes fostering innovation in AI for policing without sacrificing safety through a combination of centralized actions by the U.S. Department of Justice and independent actions by state and local law enforcement agencies. The Department of Justice, through its National Institute of Justice, should establish a new research and evaluation program that will give state and local government agencies the information they need to make the best decisions about use of AI for police reports given their own needs and resources, and keep Congress and the Department of Justice abreast of AI use in policing nationwide as well. Each state and local agency should use this information to devise its own strategy, addressing issues such as whether to adopt AI, officer training, technology choice, budget, transparency, and other policies and procedures to use the technology where it is safe and effective.
While this memo focuses on use of AI for police reports, the recommended solution serves as a model for other AI use cases as well. Similar problems occur every time a large number of local government agencies are contemplating the use of AI in scenarios where the pros and cons are poorly understood, and there is potential for significant harm.
Challenge and Opportunity
Why Police Departments are Considering AI for Police Reports
Police reports are a cornerstone of law enforcement. These reports serve as the official record and generally the only written record of significant interactions between police officers and individuals, including arrests, crimes reported, and car crashes observed. The contents of police reports can influence important decisions, such as whether an individual is charged with a crime. When police officers testify in court about an incident that occurred months or years earlier, they typically rely on the police reports that they wrote soon after the incident to get the details right. When insurance companies want to assess liability, their decisions often depend on police reports. When police officers are accused of misconduct, investigators study the relevant police reports. When compiling crime statistics on which policy decisions will be made, critical data comes from police reports. It is therefore important for police reports to be accurate, complete, and unbiased.
Given the importance, it is no surprise that many police officers spend hours per day producing these reports. This comes at a cost. If the time spent on police reports could be reduced, then police departments could reduce the number of officers employed and thereby greatly reduce expenses, or reallocate officer time to other productive tasks, or some combination of the two. Many police departments in the U.S. are especially motivated now to free up their officers’ time, because there is a national shortage of qualified officers, and many departments have unfilled positions.
A number of companies have announced products that integrate AI into the writing of police reports. Some vendors such as Truleo and Axon have claimed that AI assistance can reduce the total time spent on police reports by 80% to 90%, which would yield tremendous cost savings if true. In response to such promises, some police departments have already adopted this technology. Given financial and staffing pressures, more departments are likely to follow.
But are the cost savings real? Are the reports produced when using AI reliable enough for their intended purpose? And what strategies for adoption will maximize both cost savings and report quality? Most police departments do not have the AI expertise on staff to answer those questions. Indeed, roughly three fourths of law enforcement agencies in the U.S. have fewer than 25 police officers, and thus very few IT professionals.
How AI Would Be Used
The general idea is that information about the incident is fed into an AI-based system which produces a draft report of what a particular police officer did and observed, which that officer must review. The details vary from one AI-based product to another. In some cases, police officers feed this information into the system by typing relevant facts on a computer. In others, officers participate in an interactive oral interview with the system. In the most ambitious system, the AI system is fed information about an incident by uploading recordings from a body-worn camera, with no direct involvement from the officer. These systems transcribe the audio and use the resulting text; some analyze video as well. In all of these cases, once the AI-based system produces an initial draft, the officer inspects the draft, makes any changes he or she wishes, and signs off on the result.
The Risks of Using AI for Police Reports are Poorly Understood
AI-based products for police reports use generative AI, where an AI system is trained from a set of prior examples to understand which words and phrases are frequently used together. The system can then generate entirely new text for new circumstances by using the relationships observed in its training in combination with some new input data and some elements that are entirely random to avoid repetition and unnaturally formulaic text. Regardless of the domain, producing text using generative AI can be problematic.
First, generative AI can randomly produce “hallucinations,” i.e. information that is roughly consistent with the training data but incorrect in the current circumstance.
Second, when an AI model is trained on biased data, it produces biased results. For example, if reckless driving citations in the training data are more likely to involve alcohol with young drivers than with old drivers, then hallucinations involving alcohol may be more likely with young drivers. Companies are rarely transparent about their training data sources, but some sources from law enforcement could easily be biased with respect to factors such as race, age and gender.
Third, some generative AI models leak information in unexpected and often unseen ways. For example, if the system uses new inputs from users to improve (or “train”) the model, then a new input may later be revealed to other users. This happens with the widely-used generative AI services that are offered for free to the public, and some officers already use those free tools. Even if new inputs are not used in this way, those new inputs could be transferred to a provider of AI-based services with weak defenses. If a police department allows its officers to use a system with inadequate protections, this would risk citizens’ privacy and possibly compromise future court cases. It is technically possible to design systems with better protection against leakage, but police departments typically have no way to tell which services have done so effectively. Given all of these risks, it is no surprise that some localities have sought to prohibit use of AI for police reports.
Of the various methods of putting information into the system described above, using recordings from body-worn cameras could save the most officer time, but it also brings additional risks that must be assessed. For example, when an officer in Utah uploaded the recording of an incident that occurred while a movie was playing in the background, the AI reportedly produced a police report claiming that the officer transformed into a frog. An error like that does no harm because it is easy to detect, but a different movie might have produced a far more dangerous error. Also, audio transcription is less reliable when people speak with accents or with an African-American Vernacular. Using AI to accurately turn video into text can be even more challenging. Finally, with this approach there is no opportunity to record an officer’s subjective experience before the officer is influenced by AI-generated text, which some people have argued is important. Testing is required to understand the seriousness of these potential risks, and any mitigation strategies.
In 2025, I organized a research project at Carnegie Mellon University (CMU) to investigate use of generative AI for police reports. We produced police reports using three different kinds of generative AI technology, and observed that material inaccuracies do occur. For example, in one assault case, an input to the AI indicated that the victim was not transported to a medical facility without providing a reason, but the resulting report inaccurately claimed that the victim refused transport to a medical facility. We also observed that error rates varied from one AI product to another, as well as from one type of police report to another, perhaps because some types of reports are more complex than others. Thus, it matters which AI technology a police department chooses and under what circumstances it directs its officers to use that technology.
As long as AI is only used to produce the first draft of a report, problematic text does not compromise report quality if the police officer finds this text and rewrites it before submitting the final report. That may or may not be sufficient. As explained by MIT professor David Autor and Alphabet Senior Vice President James Manyika, AI systems that augment humans without replacing them can fail if the AI is not designed to collaborate with humans, such as when human pilots could not prevent an Air France flight from crashing after the autopilot failed because the tool gave the pilots limited situational awareness. It is even less obvious, but the converse is also true: problems can occur if humans are not explicitly trained to collaborate with AI.
The CMU researchers conducted experiments in which experienced police officers were asked to make corrections to prewritten police reports which contained hallucinations, omissions, and “event swaps” in which things occur in the wrong chronological order. We observed that officers missed many problems, including those that might matter in legal proceedings, such as when a report incorrectly indicated that a suspect was holding a knife when encountered. It is important to note that this occurred in a university research exercise rather than a professional setting, and that the officers had never been explicitly trained to edit AI-generated text, i.e. to collaborate with AI. Better results might be possible in real police departments that have adopted the right kind of training, but this requires more investigation.
Even an error that is not directly material to the case can do harm. A memo from the King County Prosecuting Attorney’s Office reports that, thanks to AI, “an otherwise excellent report included a reference to an officer who was not even at the scene. … And when an officer on the stand alleges that their report is accurate — they will be proven wrong…we do not want your officers certifying false police reports. The consequences will be devastating for the case, the community and the officer.” Defense attorneys can bring up this error every time that officer testifies for many years to come.
The Benefits of Using AI for Police Reports are Poorly Understood
On the positive side, many departments would save money if AI reduced the amount of time that each officer spends on police reports by just tens of minutes per week. This reduction could be within reach. One prominent survey found that 62% of officers spend more than two hours per day on police reports and 14% spend more than four, and there have been news articles quoting police officers who said that time savings from AI were substantial, although this is anecdotal. Yet the most rigorous study to date did not find any reduction in time spent when AI was introduced. This issue also deserves more investigation. Moreover, the impact of AI on time spent and police budgets will vary greatly between departments, so a single one-size fits-all conclusion is inadequate. Savings depend on factors like the number of police incidents per week, the types of incidents that are most common, and how pervasive technology already is in the department.
The benefits and risks associated with AI also depend on the deployment strategy. For example, police departments may choose to use AI in cases where time savings are great and risks are low, or when time savings are insignificant and risks are high. Departments may choose to use AI in a transparent manner in which problems are easily observed and quickly corrected, or in an opaque manner. Research could provide guidance to police departments on whether and how to adopt this technology while minimizing risks.
Unfortunately, this research will rarely occur under current policies. Individual police departments are unlikely to invest their limited resources into testing commercial AI software products, developing new officer training programs, measuring whether AI saves time or money, or collecting best practices for adoption. If the federal government fails to act, some states or cities may fund useful work. However, even the state and local agencies with the largest budgets, such as the New York City Police Department and the California Highway Patrol, have little incentive to bear the full cost of making new discoveries and then informing the nation’s 18 thousand law enforcement agencies, most of which are small and have needs and resources that are quite different. There are university researchers doing this kind of work, but very few, and most police do not read academic journals. Informed decisions will only happen if the federal government takes action.
Plan of Action
Most of the actual decisions about whether police should use AI technologies at all, which specific AI technologies to acquire, and how those AI technologies should be used will be made by local officials. The specific decision-maker varies from locality to locality. For most of these decisions, police chiefs are critical. They can weigh in directly on issues such as officer training and department policies governing technology use, or can delegate that role. In some jurisdictions, police departments make independent decisions about procuring technology such as AI, whereas in others municipal Chief Information Officers may play a more decisive role. It should be the responsibility of the federal government to inform these decisions, regardless of which state or local official has the final say in any locality. Thus, this memo will make actionable recommendations to two audiences: the federal Department of Justice, and those who make decisions for state and local law enforcement agencies.
Recommendation 1. The Department of Justice, through the National Institute of Justice (NIJ) and in consultation with the National Institute for Standards and Technology (NIST), should create ongoing projects whose goal is to provide information to state and local agencies that helps these agencies make better decisions regarding use of generative AI for police reports.
The introduction of AI for police reports raises technical and operational questions that individual law enforcement agencies are poorly positioned to answer on their own. Addressing these questions falls within the mission of the National Institute of Justice (NIJ), the Department of Justice’s research and evaluation arm. NIJ is well positioned to generate and disseminate this evidence at a national scale, reducing duplication across thousands of agencies and enabling more consistent, evidence-based adoption decisions.
The NIJ should draw on expertise from multiple institutions to address these important questions. Universities should play a central role, because the best academic researchers are accustomed to inventing entirely new methods that address novel challenges and emerging technologies. NIJ should therefore establish a funding program to support external research. Others already work for NIJ, where understanding of the problem domain is deep, so important work can also be done internally. Although they typically lack law enforcement expertise, there are also experienced AI researchers at NIST’s Center for AI Standards and Innovation, so consultation with that center could help. Below are some examples of research that is needed.
Research on Evaluation Methodology for AI Products and Services
A new methodology must be created that can assess AI-based products and services for police reports, and quantitatively determine their ability to produce reports that are both accurate and complete under a wide variety of scenarios. This methodology should also assess the risk of leaking confidential information.
Research on how to train police to edit AI-generated reports
Even when reports are generated by AI, it is the responsibility of a police officer to ensure quality through editing. Simply having a human involved does not mean that the report will be anywhere near as accurate or complete as if a human wrote it. Detecting and correcting subtle mistakes in text that someone else wrote is challenging, and few police officers have experience with the task. Extensive training may prove critical. For example, officers might first learn enough about how AI-based tools work to dispel any illusions that they are infallible. Then officers might learn the types of mistakes that AI tends to make, which are different from the types of mistakes that humans tend to make. Research is needed to develop training strategies, and determine their effectiveness.
Research on Benefits and Costs of AI
The primary motivation for adopting AI is to save time and money. Do AI tools really reduce the time spent on police reports, and if so, by how much? What are the lifecycle costs, including software, storage, IT support, and officer training? How do expected cost savings depend on factors that vary by police department, such as number of officers, the types of police report that are most common in the department, and existing IT infrastructure? How do they depend on technology choices, such as whether officers feed the AI by typing in information, participating in an audio interview, or uploading recordings from a body-worn camera?
Research on how departments can perform quality control
Any organization that introduces a technology with unknown impact should have a way of measuring quality in context on an ongoing basis, and not just before deployment. How does a police department know if the reports generated with AI assistance are good enough, or if its officers are well-trained? One possibility might be to routinely assess the completed reports, such as by comparing AI-generated reports with video footage in a monthly audit as the Boulder Police Department tried or with officer-written reports as the Oklahoma City Police Department tried. Doing this as efficiently and effectively as possible may require a new method. Another might be to artificially inject errors of the kind that AI is likely to produce, and monitor whether injected errors are corrected. (One existing product from Axon already injects errors. Effectiveness may be limited because the injected errors are unlike those that AI is likely to produce, but this requires testing.) If a few officers consistently submit reports with injected errors or other problems, this may indicate that those officers need further training. If many officers consistently do so, then this may indicate a more systemic problem.
Other types of research and analysis are perennial and therefore should generally be led by staff within NIJ, although outside researchers could play a smaller role. Outside researchers tend to be less effective when success requires the trust of law enforcement agencies, or when being consistently accurate is more important than inventing something new. Examples include:
- Assessment of products and services on the market today: Once the research described above produces a methodology to evaluate the quality of an AI product or service, that method should be applied to each product. DoJ staff should use that methodology to assess every new product or major update of an existing product that comes on the market, and the results should be made available to law enforcement agencies and municipalities across the country.This is comparable to the NIST program which tests facial recognition products.
- Identifying best practices and tracking use: With thousands of law enforcement agencies making independent decisions about the use of AI, it is inevitable that some will adopt better strategies than others. One ongoing mission of this program should be to collect information about what law enforcement agencies are doing with AI and its impact, both positive and negative.From this, they should produce a set of best practices which can be widely disseminated, and continually revise these best practices over time.
All results and recommendations from this program should be made available directly to all of the 18 thousand law enforcement agencies in the U.S.The program should disseminate results to organizations that train police officers, including future police chiefs.This includes the FBI National Academy and state organizations like the California Commission on Peace Officer Standards and Training.It should also disseminate results through national organizations that serve state and local decision-makers, such as the National Association of Chiefs of Police, the Association of Public-Safety Communications Officials International, the U.S. Council of Mayors, and the National Association of State Chief Information Officers.
The program should also provide annual summaries of use of AI for police reports in the U.S. to Congress, the Department of Justice, and the general public, so it is possible to track trends over time and detect potential concerns before they become problematic.
Recommendation 2. Any state or local law enforcement agency that is seriously considering adoption of AI for police reports should first produce a strategic plan using information provided by NIJ, knowledge of local needs and resources, and other available information.
Without an appropriate strategy in place, the use of AI for police reports is likely to produce reports that fail to meet the needs of the criminal justice system, potentially putting innocent people at risk, and wasting taxpayer money. An effective strategic plan can mitigate these risks. This plan should address the following.
- Choice of AI technology: Police departments must choose products and services carefully, and incorporate DoJ recommendations from the research program above into existing procurement processes. For example, they should not procure an AI system in which the data that is entered can be used to train the model as this can make the data accessible and thus undermine privacy, or a system in which the risks of hallucination, omission or bias are deemed to be high. The National Association of State Procurement Officials should also include these recommendations in its guides. Given that individual officers can and already do use AI even when their department has not adopted it, departments should also explicitly prohibit officers from using publicly-available AI systems.
- Phased deployment: When rolling out any technology that carries risk, it is helpful for an organization to deploy in phases, such that each phase expands the extent of use. After each phase, the organization must carefully assess whether deployment was successful before deciding whether to advance. Whenever problems are observed in these assessments, those problems must be addressed before proceeding. This has proven to be an important approach when adopting AI. In this case, that probably means initially using AI only for reports for which the consequence of errors is lower and/or the risk of inaccuracy is lower, e.g. traffic incidents rather than felony arrests.It also may mean initially using AI only by a small group of police officers who are already comfortable with the technology rather than scaling quickly to all officers.
- Transparency and oversight:The use of AI should be sufficiently transparent to stakeholders, the relevant legislative bodies (e.g. city councils, state legislatures), civilian oversight boards, and the community. For example, the policies and procedures about use of AI discussed above should be stated in advance and publicly accessible, as should plans for large-scale procurements. This is important both as a means of quickly detecting and correcting any problems that may emerge before they become serious, and for fostering community buy-in by keeping police use of AI consistent with public expectations and goals. In addition, when a police officer uses AI-based tools to produce a report, there should be an indication on that report regarding what role AI played, something that some police departments have deliberately concealed.There should also be an indication of where the information that was fed into the AI system came from, e.g. whether that input includes recordings from body-worn cameras, audio from interactions with dispatchers, etc.This allows all stakeholders, including defense and prosecuting attorneys, to apply an appropriate form of scrutiny to the resulting police reports.
- Policies and procedures: Disasters are possible even with good technology. Police departments should establish effective policies and procedures before using AI for actual reports, also considering DoJ recommendations. This includes creating an effective training program for officers, where effective training goes well beyond just knowing the features of the software and addresses effective quality control. It also includes determining whether officers are allowed to see AI-generated content before they have written their own observations, given the “elasticity of human memory.” Departments may adapt the process by which a police report is reviewed by people other than the author, e.g. by supervisors or experts. Departments should also define policies regarding which intermediate datasets used by AI software to produce police reports are retained, and who can access them. For example, if audio recordings are transcribed and summarized before generating reports, how long should the original recordings be retained?
Conclusion
In recent years, the capabilities of generative AI have advanced at an astonishing rate, leaving our understanding of how to make use of those capabilities far behind. This is particularly challenging for those who would like to use the potentially transformative capabilities of generative AI for producing police reports, and for other AI applications that share two qualities. First, there are dire consequences if use of the technology goes badly, such as the possibility that a flawed police report could lead authorities to charge the wrong person with a crime. Second, most of the decisions with significant impact are made by 18 thousand independent local government agencies with different needs and limited resources and AI expertise. It is hard to imagine how all of these agencies could make informed decisions regarding use of an emerging technology that is still poorly understood by tech-savvy institutions.
Some agencies will avoid the risk by never even considering AI for a purpose like this. However, they forgo any possibility of reaping potential benefits, such as a significant reduction in costs, or a reallocation of police time from paperwork to other productive activities. Other agencies will adopt AI, but in a way that does more harm than good, perhaps because they chose the wrong product or because they used it poorly. This paper proposes a two-pronged strategy that will give state and local decision-makers both the information they need to make good decisions, and the confidence that their decisions are right for their respective agencies.
The U.S. Department of Justice, through its National Institute of Justice, should establish a set of programs that all have the goal of providing actionable information to law enforcement agencies about use of AI for police reports. This includes the pros and cons of adopting the technology and how both vary from agency to agency, the strengths and weaknesses of AI products on the market, how to train officers in use of AI for police reports, how to perform continual quality control, and other best practices.
Each state or local law enforcement agency that is considering AI for police reports should produce a strategic plan that makes use of information provided by NIJ. Topics in the strategic plan would likely include the types of AI that should and should not be used, a phased approach to adoption, a transparency strategy that makes it easier to identify issues before they become highly problematic, and other policies and procedures.
My thanks to my CMU colleagues who worked on a 2025 research project on AI and police reports: Dr. Aleecia McDonald, Dylan Bonanno, Kai Collins, Ayana Curto, Katie Eisenman, Madeline Falk, Jane Fleischman, Harrison Green, En Hung, Wendy Jiang, Lily Klucinec, Isabella Krisky, Skylar Lukic, Tzen-Chuen Ng, Nicholas Ortiz, Miguel Rivera-Lanas, Christopher Rodas Ochoa, Keya Sharma, Autumn Swartz, Morgan van der Linde, Maximilian Vieweg, Sophie Vincens, Kemp Winkler, Avi Wong.
Yes. General-purpose generative AI tools have been available to the public for several years, including OpenAI’s ChatGPT, Google’s Gemini, Anthropic’s Claude, and Microsoft’s CoPilot. Police departments did not officially embrace these tools, but individual officers have. For example, it was discovered that an ICE agent used ChatGPT to produce reports, which led the judge to respond that this “may explain the inaccuracy of these reports.” This is inevitable unless police departments adopt policies that prohibit use of these tools and actively inform officers about those policies.
Since then, companies have built tools intended for law enforcement by adopting a general-purpose AI-based tool, and adding features specific to police reports, such as additional training data and police-friendly interfaces. Relevant companies include Axon, Caseify, Central Square, Code Four, Police1, PoliceNarratives.ai, Policereports.ai and Truleo.
Building on general-purpose models gives companies the opportunity to outperform general-purpose models, perhaps by improving accuracy or reducing risk of information leakage. However, since the technical details underlying commercial products developed for law enforcement are typically opaque and proprietary, many potential buyers cannot know whether improvements are present. Evaluation by a trusted organization could address this problem, by testing the product directly and demanding technical details about product design.
The greatest risk is that AI tools will produce police reports with flaws that are not corrected in editing. Generative AI is inherently vulnerable to hallucinations that produce inaccurate information. AI tools can also omit critical facts, or put events in the wrong chronological order. AI can produce biased text, i.e. text may depend on characteristics of individuals in the report such as race, gender or age when those characteristics should be irrelevant. When an AI system is trained from biased data, the system is likely to perpetuate those biases.
Inaccuracies, omissions, event swaps and biased text can all be material in important decisions. Seemingly minor inaccuracies or omissions have serious consequences, such as making an innocent bystander look deceptively guilty, or making it appear that police did not comply with applicable laws when they did. Inaccuracies can undermine legal proceedings. Even errors that are not material to the case can become problematic if a police officer later testifies that the police report is entirely correct, as this could put the officer’s entire testimony and reputation in doubt. Research is needed to understand these risks.
Yes, these recommendations are intended both for use of AI to produce police reports, and as a model for advancing safe, impactful and innovative adoption of AI and other technologies in similar cases. The goal is to adopt AI where (and only where) it brings improvements. The issues are similar whenever the following characteristics are present.
First, the technology being considered offers significant potential for benefits and significant risks for harm, so that “move fast and break things” is not the best approach. Adoption can be accelerated by addressing the concerns of potential adopters and building confidence.
Second, much is not known about how to use the technology safely, perhaps because the technology is as new as generative AI. Thus, someone should produce and disseminate information that will enable good informed decisions.
Third, local government agencies are the primary decision-makers. Unlike federal agencies and large companies, local governments have limited resources to investigate new technologies. Most for-profit companies that would advise them simply want to make a sale.
When these three characteristics are present, the federal government can provide critical information to decision-makers. Also, local governments can benefit from phased deployments with assessments after every phase, and transparency provisions.
The Trump Administration’s executive orders do not address AI for police reports specifically, but they seek ways to advance AI innovation and adoption using a strategy that is consistent with the recommendations in this memo.
President Trump issued an executive order calling for an AI action plan. America’s AI Action Plan has three pillars, the first of which is innovation. According to the Plan, “the United States needs to innovate faster and more comprehensively than our competitors in the development and distribution of new AI technology across every field, and dismantle unnecessary regulatory barriers that hinder the private sector in doing so.” Consistent with America’s AI Action Plan, this memo recommends creation of federal programs that foster innovation wherever that innovation benefits society without imposing barriers on state and local governments.
America’s AI Action Plan explicitly recommends evaluation, stating that “rigorous evaluations can be a critical tool in defining and measuring AI reliability and performance in regulated industries,” and directing the federal government to “support the development of the science of measuring and evaluating AI models, led by NIST at DOC, DOE, NSF, and other Federal science agencies” This clearly includes NIJ assessments of AI for police reports.
Congress has passed no laws that specifically address use of AI for police reports, but two states have: Utah and California. These laws are consistent with this memo’s recommendations.
Under Utah’s Law Enforcement Usage of Artificial Intelligence Law, agencies must have policies that indicate which generative AI technologies employees can use, and for what tasks. The law also mandates that any police report created with AI assistance should include a disclaimer describing the role of AI, and a certification that the author reviewed the report for accuracy.
California’s Law Enforcement Agencies: Artificial Intelligence Law similarly mandates that police reports created with AI assistance include a disclaimer, and that agencies retain the initial draft of the report which was created entirely by AI and an audit trail of subsequent changes. Finally, the law prohibits vendors of AI-based tools from selling information that they obtain in this process.
These policies are consistent with recommendations of this memo, although this memo is not proposing mandates from the federal government. This memo would recommend that the NIJ collect data on the consequences of any state law, and use the lessons learned to recommend best practices to the other states.
How State Governments Should Purchase AI to Ensure Fair, Transparent, and Accountable Use
State and local governments are rapidly procuring AI systems, but the contracts governing these tools overwhelmingly lack provisions for transparency, fairness, and accountability. While attention has been paid to the way the federal government procures AI, comparatively little attention has been paid to procurement by state and local governments. However, some of the most consequential AI systems spanning areas such as criminal justice, healthcare, and education are being deployed at these levels of government. Our analysis of thousands of state AI contracts across California, Florida, and Utah finds that 77% of provisions are standard boilerplate. 3.0% of these provisions address cybersecurity, 5.3% address transparency, and 2.4% address fairness and accountability. Meanwhile, these procurement decisions lock in governance choices for years, with some contracts spanning a decade or more.
Procurement is not merely an administrative function—it is how AI enters government and the first line of defense for responsible AI in the public sector. Contract language is often a relatively low friction and politically viable tool that can generate concrete governance benefits without requiring new AI legislation. State governments should adopt three reforms: (1) standardized responsible AI contract clauses aligned with the NIST AI Risk Management Framework, (2) risk-tiered procurement review processes modeled on proven approaches in San José and Colorado, and (3) mandatory AI vendor fact sheets as a condition of contract award and renewal.
Challenge and Opportunity
Procurement is the first line of defense for responsible AI in the public sector
Governments adopt AI to save money and improve efficiency. But poorly written contracts can hard-code opacity, vendor lock-in, and weak accountability for years or decades. They also waste scarce public resources in ways that are difficult to unwind. According to our analysis of the Electronic Privacy Information Center (EPIC)’s dataset of more than 600 state contracts (2023), the median contract value is approximately $1 million.
Although procurement may sound like a technical or unfamiliar term to many, it is not merely an administrative function. It is a core governance tool. Anyone who cares about how technology is used in government should care about procurement, because it is how technology enters government. Procurement is the first line of defense for ensuring responsible AI in the public sector. Most AI policy debates focus downstream on regulation, but some of the most consequential decisions are made upstream in contracts. Legislation and regulation of AI can be difficult, especially at the state level. AI procurement promises to be a potent tool for security, transparency, fairness, and accountability, not just compliance and cost containment.
In either case, AI-specific considerations rarely enter the process. For example, agencies may not ask about bias testing, government access to training data, or requirements for vendor to disclose how the model makes decisions. A joint National Association of Statement Procurement Officers (NASPO) and National Association of State Chief Information Officers (NASCIO) report recommended that states prioritize bias mitigation, transparency, and accountability in AI procurement. Standard procurement evaluates cost, vendor qualifications, and compliance with existing regulations, but typically lacks the government capacity to assess algorithmic risk.
There is a growing race between technological change and government capacity
State and local governments are rapidly procuring AI systems, with EPIC documenting 600 such contracts in 2023 and our analysis identifying over 1000 just in the states of California, Utah, and Florida. Governments are acquiring AI through both stand alone procurements and renewals of broader technology contracts that now embed AI features. In both cases, procurement capacity has not kept pace with technical complexity, leaving many agencies ill-equipped to evaluate performance, negotiate price and scope, and ensure these tools are used effectively and responsibly.
Cooperative procurement can save time and resources, but it can also concentrate risk by locking many jurisdictions into the same contractual terms
Because procurement takes time and resources, governments often rely on cooperative purchasing agreements (arrangements in which one state competitively bids and negotiates a contract that other states and local governments can adopt without rerunning the procurement process) to buy goods and services together and reduce administrative costs. The National Association of State Procurement Officials (NASPO) is often the institutional vehicle for this process. It was founded in 1944 during World War II, following President Franklin D. Roosevelt’s signing of the Surplus War Property Disposal Act. In the EPIC dataset, more than 4 out of 5 state AI contracts were negotiated through the NASPO ValuePoint platform (NASPO’s flagship cooperative contract program). Cooperative procurement can increase bargaining power and reduce administrative costs for participating states. Yet it also makes the initial contract especially consequential, as boilerplate language often becomes the template for all participating jurisdictions.
In our ongoing research, we analyzed AI contracts from three states—Utah (which initiated many NASPO agreements), California, and Florida—classifying 3,771 individual contract provisions across 215 contracts.
We found that 77% of provisions are standard boilerplate, such as force majeure and indemnification clauses. Transparency provisions (audit rights, reporting obligations) are the most common substantive category at 5.3%. Cybersecurity provisions (data encryption, breach notification, access controls) account for 3.0%, and fairness and accountability provisions (non-discrimination, bias testing algorithmic accountability) are about 2.4%.
Long term contracts are often poorly suited to rapidly evolving technologies and governance norms
Contract terms may also be lengthy. In the EPIC data, the average contract length was seven years. Some contracts even span a decade. When governments experience a failed AI implementation, they often respond by signing longer, not shorter, contracts. In the aftermath of failure, agencies may turn to more established vendors that appear credible and reliable, even if they are more expensive.
In 2013, Michigan’s Unemployment Insurance Agency entered into a $47 million contract with Fast Enterprises to design and run the Michigan Integrated Data Automated System, or MiDAS. The system incorporated algorithm-based fraud detection tools. From 2013 to 2015, MiDAS wrongly accused more than 34,000 unemployed individuals of fraud. In 2022, the state replaced it with the Deloitte-developed Unemployment Framework for Automated Claim and Tax Services, known as uFACTS. It is projected to cost about $78 million over a 10 year contract. Throughout this fiasco, little attention was paid to how the original contract was negotiated and structured. Nor was there meaningful scrutiny of whether procurement practices improved when the state later signed an even larger contract with Deloitte.
Critically, neither the original $52 million MiDAS contract nor the replacement $78 million uFACTS agreement included meaningful provisions for algorithmic transparency, bias testing, or independent performance auditing—precisely the types of clauses that could have flagged the system’s 93% false-positive rate before it devastated tens of thousands of families. The MiDAS debacle cost the state over $125 million across two contracts, falsely accused 40,000 residents, and resulted in a $20 million class-action settlement. In short, the absence of responsible AI contract provisions creates real-world harm.
Locking in AI governance decisions for years, or even a decade, leaves little room to adapt. It places states and local governments in a vulnerable position, as the underlying models and risks can evolve dramatically within just a few years. Once a contract is signed, the window for negotiating transparency, fairness, or accountability provisions largely closes. Revisiting core terms mid-contract is costly and legally complex, which means the initial procurement decision effectively sets the governance framework for the system’s entire operational life.
Vendor lock-in compounds these risks. Once an AI system is deployed under a long-term contract, governments may lose meaningful control over the data the system processes. Vendors may retain proprietary rights over training data, model architectures, or performance analytics, making it difficult for the government to audit system behavior or switch providers. When institutional knowledge becomes embedded in vendor-controlled platforms—as happened when Arkansas could not explain the details of a model used to determine Medicaid benefits—the dependency becomes nearly irreversible. In Idaho, a state agency refused to disclose its benefits allocation formula, claiming it was a vendor trade secret, effectively shielding a public decision-making system from public accountability.
Contracts are an underutilized policy lever
Although state governments rarely include responsible AI provisions in their contracts, these clauses represent an important policy lever. Based on the EPIC data, all 50 states, as well as DC and Guam, have entered into AI related contracts.
Contract language is often a relatively low friction and politically viable tool that can generate concrete governance benefits without requiring new AI legislation. Moreover, vendors tend to be repeat players, with companies such as Deloitte, Accenture, and Pondera providing various types of government technology. This fact creates opportunities to negotiate principles across various AI products. Clearer contract language standards also benefit smaller companies and new entrants by demystifying expectations and lowering the barrier for bidders that lack dedicated government affairs teams.
Nonetheless, a contract’s leverage is time sensitive. Once it is signed, the window of opportunity largely closes. Revisiting or unwinding core terms can be difficult and costly. Governments therefore need to use the negotiation process to exercise their purchasing power to reduce risk and strengthen transparency and accountability. The cost of failing to do so is substantial. These agreements are often sticky and are frequently reused as boilerplate language, allowing weaknesses to persist across agencies and over time.
What role do policy networks play in AI procurement reform?There are growing AI communities within state and local governments that view procurement as an underutilized governance tool. The GovAI Coalition, launched by San José in 2023, has expanded to more than 3,000 members across 900 government agencies. In April 1976, the San José City Council approved the Coalition’s transition into an independent nonprofit organization. Within the coalition, procurement is one of the core committees, and vendors are not permitted to serve on it. There are also networks such as the National Association of State Chief Information Officers and the Beeck Center for Social Impact and Innovation’s State Chief Data Officers Network, where best practice sharing, information gathering, and coalition building are active. These networks enable state and local governments to use their collective purchasing power more strategically in their dealings with vendors.
Plan of Action
State governments have both the authority and the practical tools to strengthen AI procurement today. The following three recommendations can be implemented through existing procurement authority, without requiring new legislation, and draw on proven models already in use.
Recommendation 1. State procurement offices should adopt standardized responsible AI contract clauses aligned with the NIST AI Risk Management Framework.
AI procurement should not rely solely on traditional cost benefit analysis, but also incorporate a systematic risk benefit assessment. The EU’s AI Act, which entered into force in 2024, distinguishes between high and low risk AI systems and is accompanied by model contractual clauses tailored to different risk categories. In the U.S, the National Institute of Standards and Technology (NIST) has developed the AI Risk Management Framework (2023), a cross sector tool to guide risk evaluation and mitigation. Aligning these risk assessment frameworks with standardized contract clauses would substantially improve responsible AI procurement practices across state and local governments, while also reducing administrative burdens. Even if adoption is not mandatory, such resources can encourage more proactive engagement with responsible AI provisions by lowering the cost of asking the right questions, identifying relevant information, and translating risk considerations into clear contractual language.
IEEE Standard 3119-2025, an international standard specifically for AI procurement, provides a ready-made framework covering problem definition, solicitation, vendor evaluation, and contract monitoring. A multi-state working group convened through NASPO—building on its existing collaboration with NASCIO on AI procurement—could adapt these standards into model contract clauses within 12 months. At minimum, clauses should address: data governance and retention, algorithmic bias testing, explainability requirements for high-risk decisions, breach notification procedures specific to AI systems, and performance benchmarks with renewal contingencies. Canada’s Algorithmic Impact Assessment and the EU’s model contractual clauses for AI offer proven international templates.
Recommendation 2. States should implement risk-tiered AI procurement review processes, modeled on San José’s Digital Privacy Office approach.
The City of San José, located in the heart of Silicon Valley, has alreadyadopted this risk analysis approach. When a city department submits a procurement request, the Digital Privacy Office assesses its risk level. If the system is deemed low risk, the request is approved without creating a backlog. If it is classified as high risk, the office conducts an impact assessment and requires the vendor to complete a structuredAI FactSheet. This simple document helps government officials know what questions to ask and how to communicate with vendors about them. It covers training and test data, model characteristics, update procedures, performance metrics, and related information. These materials are then reviewed by cybersecurity and privacy teams, followed by testing and ongoing monitoring.
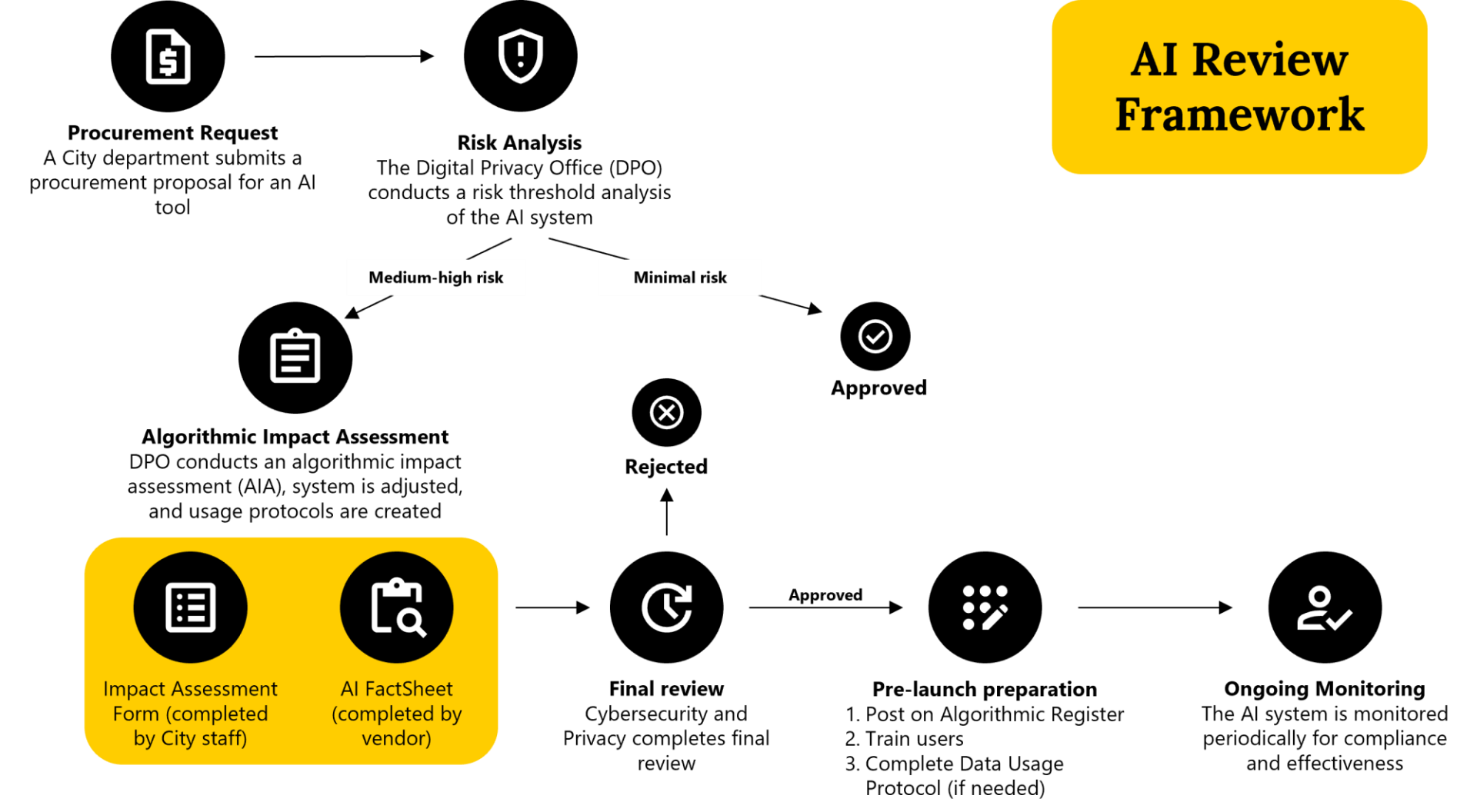
City of San José website (2026)
This approach can be elevated to the state level by establishing a similar risk analysis procedure within the procurement process. The Colorado Office of Information Technology (OIT) already uses a NIST-based risk assessment framework to evaluate all generative AI use cases and ensure that procurement complies with state law and data security requirements, providing a state-level proof of concept.
States with existing AI governance infrastructure are natural pilots. California’s Governor issued an executive order in 2023 directing the development of AI procurement guidelines, and the state has since published purchasing rules for generative AI. Colorado’s AI Act (SB 24-205) already requires reasonable care for high-risk AI systems. These states, alongside jurisdictions active in the GovAI Coalition could pilot risk-tiered review processes within existing procurement office budgets. San José’s Digital Privacy Office operates within the city’s IT department without a dedicated budget line, demonstrating that this model can be implemented by designating existing staff rather than creating new offices. NASCIO, which has made AI governance a top priority for 2026.
Recommendation 3. State governments should require AI vendors to complete structured AI fact sheets as a condition of contract award and renewal.
One relatively easy to implement reform is to adopt shorter term contracts with built in opportunities for revision or modification after a clearly defined period of use and evaluation. This recommendation aligns with the call to avoid rigid procurement cycles and embrace more modular, outcome-driven buys by Lewis and Pahlka (2025). Renewal should be contingent on demonstrated performance. The guiding principle is simple: no test, no renewal. As part of contract negotiations, vendors should be required to provide an AI fact sheet and update it as needed. No high-risk, high-impact, high-stakes AI system should be launched or renewed without appropriate testing and ongoing monitoring.
The AI fact sheet can serve as a condition of contract award and renewal. It should function as a “nutrition label” for government AI systems, modeled on San Josés vendor-facing template and inspired by IBM Research’s AI FactSheets 360. At minimum, the template should capture: training data provenance and representativeness, model performance metrics and known limitations, bias audit results across protected classes, update and versioning procedures, data retention and deletion policies, and human oversight mechanisms. Fact sheets should be updated whenever the model is retrained or its scope of use changes, and must be submitted as a condition of both initial contract award and each renewal cycle. New York City’s Local Law 144 demonstrates that mandatory AI disclosure requirements are implementable, though its enforcement challenges underscore the importance of tying disclosure to the procurement process itself—where the government has direct leverage—rather than relying solely on post-deployment regulation.
There is a role for the federal government
The federal government can also reinforce and scale these organic, though still scattered, reform efforts. The AI in Government Act of 2020 and Office of Management and Budget Memorandum M-25-21 offer a federal-level template that states can adapt to their own procurement contexts. Perhaps the most effective thing the federal government can do in this space is avoid preempting state efforts to innovate. Recent legislation and executive orders, including proposed moratoriums on state AI rulemaking advanced in federal budget and regulatory packages, have attempted to create regulatory ceilings on state efforts. Such efforts could prematurely stunt useful state innovation.
Conclusion
Procurement is how technology, including AI, enters government. It is the first line of defense for responsible AI in the public sector. When procurement fails, the downstream consequences can be significant and long-lasting.AI procurement is not a narrow technical issue. It is the mechanism through which governments quietly govern AI at scale. Strengthening procurement today will shape AI outcomes for decades. By adopting standardized contract clauses, risk-tiered review processes, and mandatory vendor fact sheets, state governments can use their existing procurement authority to build transparency, fairness, and accountability into AI systems from the outset.
When a state agency needs an AI system, it follows one of three paths: issuing a competitive request for proposals (RFP), using an exemption (for emergencies or sole-source purchases), or purchasing through a cooperative agreement like those administered by NASPO ValuePoint, where a single “lead state” negotiates terms that dozens of other states can adopt. In competitive bidding, agencies define the problem, draft an RFP specifying scope and terms, evaluate vendor bids on cost and technical merit, negotiate final contract terms, and monitor vendor performance through the contract’s life. However, as EPIC’s report documents, many AI systems enter government through cooperative purchasing agreements or emergency exemptions that bypass competitive bidding entirely — meaning AI-specific considerations like bias testing and data governance never get evaluated. EPIC identified 621 AI contracts across all 50 states, finding that the top ten vendors alone accounted for over $715 million in potential contract value.
Cooperative procurement allows multiple government entities to purchase goods and services under a single contract, reducing administrative costs and increasing bargaining power. The National Association of State Procurement Officials (NASPO) facilitates this through the ValuePoint platform. In the EPIC dataset, more than 4 out of 5 state AI contracts were negotiated through NASPO ValuePoint. While this efficiency is valuable, it means a single contract’s terms—including any gaps in AI governance provisions—can propagate across dozens of jurisdictions.
Once an AI system is deployed under a long-term contract, governments may lose meaningful control over the data the system processes and the decisions it produces. Vendors may retain proprietary rights over training data, model architectures, or performance analytics, making it difficult for the government to audit system behavior or switch providers. Over time, institutional knowledge becomes embedded in vendor-controlled platforms — staff learn the vendor’s system rather than the underlying process, and the data needed to transition to a new provider may not be readily exportable. These dynamics create high switching costs and reduce the government’s bargaining power at renewal. Shorter contract terms with performance-contingent renewal clauses (Recommendation 3) help mitigate these risks by preserving the government’s ability to reassess and, if necessary, change course.
Risk-tiered review ensures low-risk AI systems are approved quickly—San José’s model only triggers full review for high-risk systems, avoiding bottlenecks. Standardized contract clauses and fact sheet templates actually reduce negotiation time by providing ready-made language that procurement officers can adopt rather than draft from scratch. Also, the cost of upfront review is far less than the cost of failure downstream: Cooperative procurement means the review investment is shared across participating jurisdictions.
Several federal frameworks support the recommendations in this memo. The AI in Government Act of 2020 established requirements for federal AI governance. OMB Memorandum M-25-21 emphasizes structured governance, accountability, and public trust in federal AI use. The NIST AI Risk Management Framework provides a cross-sector tool for risk evaluation. While procurement is primarily a state and local function, federal guidance can reinforce state-level reforms by encouraging contract transparency and model standards.
OIT AI governance framework was implemented by designating existing staff rather than creating a new office. A NASPO-convened working group could develop model contract clauses once for shared use across all member states, amortizing development costs across dozens of jurisdictions. IEEE 3119-2025 provides a ready-made procurement framework that reduces the need for states to develop standards independently. The cost of inaction—failed AI deployments, legal liability, and harm to constituents—far exceeds the cost of reform. AI initiative failure rates in government settings reach 70-85%, and the federal government already spends 80% of its $100 billion IT budget maintaining legacy systems.
Finally, implementation costs should be understood not only as personnel expenses but also as internal coordination burdens created by fragmented procurement processes. Clear ownership across agencies is essential to manage these risks and ensure accountable, responsible AI procurement from start to finish.
Federation of American Scientists, Future of Life Institute Present Converging Risks Report, AI Impact Awards at Gala
FAS AI Impact Awards Presented to Advocates, Civil Society Entrepreneurs, Industry Experts, and Policymakers
Washington, D.C. – May 20, 2026 – Tonight at the International Spy Museum in downtown Washington, D.C., the Federation of American Scientists (FAS), a non-partisan, nonprofit science and technology policy organization, in partnership with the Future of Life Institute, the world’s oldest and largest AI think tank, conclude an 18 month project to investigate the implications of artificial intelligence on global risk.
FAS and FLI partnered to build a series of convenings and reports across the intersections of artificial intelligence (AI) with biosecurity, cybersecurity, nuclear command and control, military integration, and frontier AI governance. This project brought together leaders across these areas and created a space that was rigorous, transpartisan, and solutions-oriented to approach how we should think about how AI is rapidly changing global risks. Adapting to this reality will demand that policy entrepreneurs take action; scientific and technological expertise is a must for successful policymaking.
“FAS is dedicated to developing evidence-based policies to address national challenges, and the technical advances of artificial intelligence are already outpacing our expectations. We recognized an urgency in convening expertise across disciplines to better understand how we can reduce risk and increase societal rewards,” says FAS CEO Daniel Correa.
“AI is no longer a single-domain challenge. It is a force multiplier reshaping the risk landscape across nuclear, biological, cyber, and military systems simultaneously, and it is doing so faster than our institutions can adapt,” says Future of Life President and CEO, Anthony Aguirre. “That is precisely why this partnership with FAS has mattered so much. The report gives decision-makers a clear-eyed map of how these threats are compounding, and what we can do about it. The window to put sensible guardrails in place is open, but it is closing quickly. The leaders we are honoring show that rigorous, bipartisan action on the most consequential technology of our era is both necessary and possible.”
The AI x Global Risk Gala, moderated by Ashley Gold, Senior Technology Policy Reporter at Axios, will highlight a capstone report and present awards in recognition of AI policy leaders. Bloomberg‘s cyber and emerging tech reporter, Katrina Manson will host a discussion panel about the report. The panel will include FAS board member and former Acting Under Secretary for Science and Technology at the Department of Homeland Security, Dr. Daniel Gerstein.
‘Converging Risks’ Report
The primary report, Converging Risks: AI and the Future of Global Security, is the synthesis of sector-specific investigations into nuclear policy, cyber policy, biotechnology, defense, and critical infrastructure. Increasingly, AI cuts across all of them simultaneously.
The FAS team evaluated risks through the “Threat, Vulnerability, and Consequence” or “TVC” framework, a powerful acknowledgement of how stakes rise alongside introduction and interaction with multiple factors.
The report illustrates how AI is complicating the risk calculus, adding complexity to systems and events, changing the speed at which we need to respond, and often increasing the scale of the risk.
“Despite the very real risks artificial intelligence presents, our report is not fatalistic,” says Dr. Jedidah Isler, FAS’s Chief Science Officer. “We know that productive conversations and proactive policy cannot happen if we operate from a state of hype, fear or ignorance. As scientists, we must use all of the tools at our disposal to reckon with what is very likely to be one of the most consequential technologies of this era. It’s innately a sociotechnical problem: it’s not just the technology, but what we think about it and how we collaborate in the face of tremendous change. We must begin by building government capacity, coordination, and translation infrastructure now.”
FAS AI Impact Award Winners
FAS will also present four awards at the Gala: the AI Advocacy Award, AI Impact Award for Civil Society, AI Impact Award for Industry, and the AI Policy Award.
Joseph Gordon Levitt, AI Impact Award for Advocacy
Joseph Gordon Levitt, the UN’s first global advocate for “human-centric digital governance”, will receive the AI Impact Award for Advocacy for his work raising awareness of AI risks to non-technical audiences using his skills as a writer, director, communicator, and educator.
Mr. Levitt’s recent advocacy includes speaking out about Meta’s AI chatbots endangering children (September, 2025) and supporting an AI and child safety bill in Utah (January 2026).
Mr. Levitt and his organization, HITRECORD, explore the intersection of technology and society through both his creative work and advocacy around digital governance.
Sneha Revanur, AI Impact Award for Civil Society
Sneha Revanur will receive the AI Impact Award for Civil Society for her work founding a civil society organization, Encode, that works to influence federal AI policy that unifies pro-AI, pro-human perspectives.
Ms. Revanur began her activism work at age 15 when she learned that California was considering replacing its cash bail system with a risk-based algorithm and that the algorithm had serious racial bias baked into it. She organized a statewide coalition of high school students, fought the ballot measure, and helped defeat it by 13 percentage points.
Today, Ms. Revanur continues her activism work in AI regulation to ensure that trust and fairness are built into the often invisible systems that can have enormous impact on daily life.
Chris Meserole, AI Impact Award for Industry
Chris Meserole, Executive Director of the Frontier Model Forum, will receive the AI Impact Award for Industry for his work examining the security risks associated with artificial intelligence. He’s working to determine best practices to ensure strong interconnection between industry, research, and government.
Prior to the Frontier Model Forum, Chris served as Director of the AI and Emerging Technology Initiative at the Brookings Institution and a fellow in its Foreign Policy program.
Today, Mr. Meserole works extensively on safeguarding large-scale AI systems against the risks of accidental or malicious use.
Senator Blackburn (R-TN) and Senator Blumenthal (D-CT),
AI Impact Awards for Policy Leadership
How we govern AI’s impact on society is of utmost importance. Decisions made today will drive outcomes for years, and potentially decades, to come. FAS is presenting two AI Impact Award for Policy Leadership to honor work that anticipates and addresses future risks presented by artificial intelligence.
Senator Marsha Blackburn (R-TN), Senator Richard Blumenthal (D-CT) will be presented with the AI Impact Awards for Policy Leadership for their respective leadership navigating fast-moving technology and its implications.
Senator Blackburn of Tennessee has been a bold and consequential leader on AI policy. Last summer she successfully fought to remove a provision from federal legislation that would have blocked states from protecting their own citizens from AI harms for a decade. In December, she put forward a comprehensive national framework for AI governance that requires companies to conduct real risk assessments and establishes concrete rules on training data and deepfakes. Senator Blackburn also leads the Transparency and Responsibility for Artificial Intelligence Networks (TRAIN) Act, a bipartisan bill aimed at helping musicians, artists, writers, and other copyright holders determine whether their work has been used to train generative artificial intelligence models.
Senator Blackburn’s forward thinking on AI has driven leadership on quantum computing development. She is advancing bipartisan legislation like the National Quantum Initiative Reauthorization Act to provide necessary infrastructure for future AI capabilities.
Senator Blackburn serves on the Senate Committee on Commerce, Science, and Transportation, of which she is Chairman of the Consumer Protection, Technology, and Data Privacy Subcommittee, as well as on the Senate Judiciary Committee, of which she is Chairman of the Privacy, Technology, and the Law Subcommittee.
Senator Blumenthal of Connecticut has been one of the earliest and most consistent voices on Capitol Hill regarding technology and its implications for society. He has been using his voice to demand that Congress show up for this moment. He brought Sam Altman to Congress for the first time back in 2023 to help educate lawmakers and urge them to act. He has since pushed for his AI Accountability and Personal Data Protection Act, bipartisan legislation to hold AI companies accountable for how they use copyrighted material to train their models. He also introduced the bipartisan AI Risk Evaluation Act which would create a dedicated AI risk-evaluation program within the Department of Energy focused specifically on national security, civil liberties, and labor protections. Senator Blumenthal co-leads the bipartisan Guidelines for User Age-verification and Responsible Dialogue (GUARD) Act to protect children against harms from AI bots, and this legislation is advancing in the Senate.
Senator Blumenthal serves on Senate Committees on Armed Services, Judiciary, and Homeland Security and Government Affairs.
Two senators. Different parties. Different states. Different politics. Same conclusion: Congress cannot afford to sit this one out.
Policymakers in Attendance
Additional policymakers invited to the Gala have demonstrated leadership in advancing evidence-based artificial intelligence legislation, including:
Congressman Jim Himes (D-CT) serves as Ranking Member on the House Permanent Select Committee on Intelligence, has deep experience and unique insights into how U.S. intelligence agencies and the national security apparatus integrate artificial intelligence models, including how models could be used for hacking and cyberdefense. He will be a panelist at the gala.
Senator Elissa Slotkin (D-MI) serves on the Senate Armed Services Committee as Ranking Member of the Subcommittee on Emerging Threats and Capabilities, and introduced the AI Guardrails Act to address AI use around lethal force, spying on Americans and nuclear weapons. The bill seeks to codify two existing Defense Department guidelines into law: that AI cannot autonomously decide to kill a target and that the technology cannot be used to conduct mass surveillance on Americans. It would also ban the use of artificial intelligence for launching or detonating a nuclear weapon.
Congressman Don Bacon (R-NE) serves on the House Armed Services Committee as Chairman of the Subcommittee on Cyber, Information Technology and Innovation. Congressman Bacon has championed and overseen the passage of numerous provisions pertaining to AI and risk in the FY26 NDAA. Bacon joined the Congressional probe into Elon Musk’s Grok AI over allegations of antisemitism and ‘deeply alarming messages’ (July 2025).
Congressman Bill Foster (D-IL), Congress’s only member holding a PhD in physics, introduced the bipartisan Responsible and Ethical AI Labeling (REAL) Act, which would mandate a “clear, conspicuous, and prominently displayed” disclaimer notifying readers or viewers that content was created with or manipulated by AI.
Congressman Rich McCormick (R-GA) serves on the House Armed Services Committee and as the chairman of the Subcommittee on Oversight and Investigations. He also serves on the Armed Services Committee, Oversight and Government Reform Committee, and is a former member of the bipartisan Task Force on Artificial Intelligence.
###
About the Federation of American Scientists (FAS)
The Federation of American Scientists (FAS) works to advance progress on a broad suite of contemporary issues where science, technology, and innovation policy can deliver transformative impact, and seeks to ensure that scientific and technical expertise have a seat at the policymaking table. Established in 1945 by scientists in response to the atomic bomb, FAS continues to bring scientific rigor and analysis to address national challenges. More information about FAS’s work at fas.org.
About the Future of Life Institute
The Future of Life Institute (FLI) is the world’s oldest and largest AI think tank, with a team of 35+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefiting life and away from extreme large-scale risks since its founding in 2014. Find out more at futureoflife.org.
RESOURCES
AI x Global Risk Nexus Project
Converging Risks: AI and the Future of Global Security (and briefing booklet)
- AI and Nuclear Command, Control, and Communications
- AI and Military Integration
- AI and Biological Risks
- AGI and Global Risk
- AI, Cyber, and Global Risk
- AI and Nuclear Risks
FAS AI Impact Award Winners
More on AI Advocacy Award winner Joseph Gordon Levitt
More on AI Impact Award for Civil Society winner Sneha Revanur and Encode
More on AI Impact Award winner Chris Meserole and Frontier Model Forum
More on AI Impact Awards for Policy winners Senator Marsha Blackburn (R-TN) and Senator Richard Blumenthal (D-CT)
Converging Risks: AI and the Future of Global Security
Artificial intelligence (AI) is no longer a standalone technology policy issue. It is becoming a general-purpose capability embedded in domains central to global security. As AI systems enter biological research, cyber operations, nuclear stability, military decision-making, and other security contexts, they are changing how global risks emerge, spread, and interact.
This report provides an evidence-based foundation for how policymakers, national security practitioners, technical experts, funders, and civil society leaders should think about the convergence of AI and global risks. It builds on a series of convenings by the Federation of American Scientists (FAS) and Future of Life Institute (FLI) focused on AI and biosecurity, cyber, nuclear risk, and military integration. Across those conversations, a common theme emerged: AI risk does not sit within any single domain or threat actor. It emerges from the interactions between increasingly capable tools and the institutions and infrastructures they operate through.
Rather than predicting a single future for AI, this report aims to help decision-makers navigate uncertainty across multiple trajectories. It recommends policies that can reduce uncertainty and remain robust across a range of possible futures.
This report focuses on general-purpose “frontier” AI systems: highly capable systems that can support many kinds of work, including analysis, coding, planning, scientific reasoning, tool use, synthetic media generation, and autonomous workflows. As of May 2026, leading frontier systems can synthesize and query large bodies of text, write and debug software, analyze technical and scientific materials, generate realistic synthetic media, and help users plan multi-step scientific or operational tasks, though their performance remains uneven and context-dependent. These capabilities are dual-use. A system that helps a researcher analyze a biological dataset may also lower barriers to harmful experimentation. A system that helps defenders identify cyber vulnerabilities may also help attackers exploit them faster.
The report starts with the three broad views of AI’s future trajectory that shape policy discourse today. The “mirage” perspective sees today’s AI discourse as overhyped and focuses on risks such as premature deployment, fraud, capital misallocation, and policymaker distraction. The “normal technology” view treats AI as a powerful but ultimately manageable general-purpose technology that requires serious planning, governance, and institutional adaptation. Under this view, the main risks come from uneven diffusion, brittle deployment, automation bias, and the expansion of capability to a wider set of actors. Finally, the “autonomous power” perspective argues that rapid advances in current systems may point toward increasingly autonomous or superhuman systems. From this perspective, the main risks include power concentration and loss of control over systems far more powerful than humans, with potentially existential consequences.
This report examines AI’s impact on global risk largely through the “normal technology” and “autonomous power” lenses. While the “mirage” view remains important because it cautions against hype for specific AI applications, the global-risk questions at the center of this report are most visible when viewing AI as either: 1) a powerful dual-use technology diffusing through fallible institutions or; 2) a pathway toward more autonomous and powerful systems that may become harder to monitor, constrain, or control. Policymakers will need to make decisions under conditions of uncertainty. AI capabilities are evolving quickly in a period of geopolitical tension, and waiting for definitive evidence before acting may itself carry risks.
This report uses a familiar national security framework as part of the analysis: Risk = Threat × Vulnerability × Consequence (TVC). Threat refers to the actors, intentions, and capabilities that generate pathways to harm. Vulnerability refers to weaknesses in technical systems, institutions, infrastructure, human-machine teams, or governance arrangements that allow threats to manifest. Consequence refers to the harms that result when threats exploit vulnerabilities, including casualties, escalation, systemic disruption, loss of trust, or long-term institutional damage.
AI may affect all three components at once. AI may increase what malicious state and non-state actors can do. It also introduces complexity to opaque systems, which increases vulnerability to something slipping through the cracks. It may also compress response timelines and make failures harder to address, which increases consequence. In autonomous power scenarios, the boundary between threat and vulnerability may blur: vulnerabilities in the oversight of powerful AI systems could result in a loss of control, resulting in AI systems that themselves pose a threat.
How Policymakers Should Use This Report – Five Questions, A Solid Foundation, and Five Pillars
As policymakers grapple with uncertain futures and rapidly advancing capabilities, we recommend these guiding questions as a way to both reduce uncertainty and surface assumptions:
- First, who or what does this proposal treat as the relevant actor: humans, human–AI systems, or AI systems themselves?
- Second, what arguments, evidence, and historical reference classes does this proposal rely on (implicitly or explicitly)?
- Third, what kind of risk or opportunity is this proposal particularly focused on?
- Fourth, what evidence would challenge or support the existence of these risks or opportunities?
- Fifth, is that evidence likely to arrive in time for policymakers to update course before the relevant risks or benefits are locked in, and can the evidence collection be accelerated?
Policymakers should also build policies that create layered defenses to reduce threat, vulnerability, and consequence. We frame policy options around a foundation and five pillars:
- Foundation. Government capacity, coordination, and translation infrastructure. Agencies need technical expertise, access to tools, trusted channels with AI developers, cross-domain coordination, and the ability to evaluate claims about AI capabilities without relying entirely on private-sector assurances.
- Pillar 1. Stronger testing, evaluation, verification, and validation (TEVV). This requires better evaluations, construct-valid benchmarks, post-deployment monitoring, and indicators for changes in AI’s trajectory, including AI-enabled R&D automation.
- Pillar 2. Robust technical layer governance. This includes model security, access controls, transparency obligations, incident reporting, and mitigating capabilities that create disproportionate risks.
- Pillar 3. Thoughtful AI deployment in institutions and high-consequence systems. High-risk uses, such as military decision support, cyber operations, biological design workflows, and nuclear-adjacent systems, require risk-tiered approval, independent review, audit logs, human-factors testing, and other interventions to ensure meaningful human control.
- Pillar 4. Shifting the offense-defense balance of novel capabilities. This includes delaying and restricting broad access to capabilities that advantage attackers while strengthening AI use in cyber defense and other defense settings.
- Pillar 5. Building resilience. While resilience should not excuse preventable upstream risks, governments and institutions will need stronger cyber resilience, public health plans, and crisis communication protocols to manage future threats in these domains.
AI is already consequential, but its future trajectory remains contested. Policymakers should make their assumptions explicit, focus on what can be shaped rather than what can be perfectly predicted, and build institutions that can learn and respond as evidence changes.
Face Recognition Performance, Bias, and the Limits of Technical Fixes
Christopher Gatlin was arrested for a brutal assault he didn’t commit after AI Face Recognition Technology (FRT) said he matched the suspect. He spent 17 months behind bars, and clearing his name took two years. As of March 2026, there were at least nine documented U.S. wrongful arrests tied to face recognition misidentification, mostly involving Black people. From 2012 to 2020 Rite Aid customers, disproportionately in non-white neighborhoods, were flagged by FRT as shoplifters, confronted, and sometimes expelled, including the searching of an 11 year old girl, all on the basis of bad matches.
Errors made by FRT are one cause of these harms, and these systems are known to make more errors on certain populations, including Black people, women, East Asians, and older people. But the way these systems are used by humans is a key component of these errors. Christopher Gatlin was identified based on a grainy photo of a hooded, partially obscured face, which could not be expected to lead to reliable identification. Moreover, police arrested him despite a lack of corroborating evidence. Harms caused by Rite Aid were due in part to a decision to mainly deploy face recognition in disproportionately non-white communities, as well as a lack of proper user training and the use of poor quality photos.
At the same time, face recognition does provide real benefits. In controlled, cooperative settings such as unlocking phones, banking apps, or passport verification, modern systems can be highly accurate. NIST evaluations show dramatic improvement over time, with errors occurring about one time in 1,000, depending on conditions. Millions of Americans use face recognition daily for convenience and security.
In tasks involving uncontrolled settings with uncooperative subjects however, such as identifying people from surveillance images, accuracy is much lower and more difficult to measure. Law enforcement and child-protection organizations have still used face recognition to identify suspects, locate missing children, and support trafficking investigations, but the potential from harms from inaccurate results in high stakes settings is much greater. Furthermore, the effect of biased performance is magnified in these uncontrolled settings, in which the number of errors seems to be much greater for some subpopulations. This report focuses on the causes of this bias, its potential harms and possible steps to reduce these harms. The use of face recognition in mass surveillance obviously raises other serious potential concerns, but these are outside the scope of this report.
Harms from FRT result both from technical errors and flaws in the ways humans use these systems. This suggests two parallel strategies for reducing the negative effects of biased face recognition. One approach is to reduce the bias in face recognition systems directly. Bias can occur due to training FRT using biased datasets that do not accurately reflect the demographics of the overall population. This can be difficult to eliminate due to the massive scale of data used to train FRT, which makes it difficult to control or even understand the demographics of the data. But further efforts can be made to reduce demographic bias in the data. Numerous other external factors that are more difficult to control may also create biased performance. Consequently, in the near term it may be practical to reduce, but not to completely eliminate biased performance.
A complementary approach to reducing harms from biased face recognition is to ensure that FRT are used appropriately by human operators. This solution is much easier to implement in the near term than the previous technical solution. It is not sufficient, however, simply to ensure there is a human in the loop confirming the results of FRT, since often FRT are more accurate than humans, their errors occur on challenging cases, and people may be unable to correct these errors. Behavioral policy interventions range from research aimed at better measuring bias and understanding when FRT results are not trustworthy to clear standards for how human operators use and interpret the results of FRT and restricting the use of FRT when potential harms outweigh the benefits.
In this report we provide an overview of face recognition performance and differential performance between different demographic groups. We summarize results from the National Institute of Standards and Technology assessing performance of numerous commercial face recognition systems. And we provide an overview of potential policies to reduce harms from face recognition bias.
Acknowledgements
Our understanding of this topic has benefitted greatly from conversations with Kevin Bowyer, Leah Frazier, Patrick Grother, Anil Jain, Brendan Klare, Alice O’Toole, Jonathan Phillips, Jay Stanley, and Nathan Wessler. We also received insightful comments and suggestions from Clara Langevin and Caroline Siegal Singh. Any failure in understanding is due to the authors.
Contents
Introduction
Face Recognition Technology Has Caused Significant Harms
Improper development or use of face recognition technology (FRT) can lead to serious harms. One such example occurred in 2020 when Christopher Gatlin was arrested for a brutal assault he didn’t commit after a face recognition system proposed him as a possible match for the suspect. He spent 17 months behind bars, and clearing his name took two years. Porcha Woodruff, eight months pregnant, spent 11 hours in detention for a carjacking after another bad match, even though surveillance footage showed the suspect was not pregnant. As of March 2026, there are at least nine documented U.S. wrongful arrests tied to face recognition misidentification.
In another example of this dynamic, Rite Aid, a major pharmacy chain, deployed face recognition technology widely in stores to spot alleged serial shoplifters. Impacted customers, disproportionately in non-white neighborhoods, were flagged, confronted, and sometimes banned from stores, including searching an 11 year old girl, all on the basis of bad facial recognition matches. Federal regulators later banned the company from deploying facial recognition technology in stores for five years, noting higher false-positive rates in stores serving predominantly Black and Asian communities and improper pre-deployment safeguards (more details here).
These instances of incorrect matching and arrests have mostly involved non-white people. But, while errors may be more prevalent among these populations, as FRT use grows it can increasingly affect all people. For example, police recently released a white Tennessee grandmother who had been wrongly jailed for nearly six months based on FRT results. She was arrested while babysitting four children, accused of committing bank fraud in North Dakota, although she had never been there. Unable to pay her bills, she lost her home.

Figure 1. On the left is a surveillance photo taken at a crime scene. On the right is the image of Robert Williams that was incorrectly matched to this photo by an automatic face recognition system.
The harms described above were instigated by flawed matches produced by FRT—computational models that perform face recognition. However, these models always form part of a larger system in which humans apply FRT to some task. The failures were not just the product of a bad model, but of human failure to follow effective procedures. In many cases, face recognition searches are performed using low resolution images, with faces partially obscured. Figure 1 shows the surveillance photo used to identify Robert Williams, who was wrongly arrested for theft on the basis of this image. He later stated, “My daughters can’t unsee me being handcuffed and put into a police car.” In some cases, police have violated accepted practice with suggestive remarks that prompt witnesses to confirm the results of automatic face recognition technology. In the Rite Aid case, poor employee training, the use of low quality images, and many other deployment decisions contributed to a large number of mistaken identifications.
Face Recognition Technology is Increasingly Widely Used
Face recognition technology has become increasingly accurate and widely adopted. It is estimated that 131 million Americans use face recognition on a daily basis for applications such as unlocking their phones or banking apps, providing convenience and improving security. FRT usage is especially prevalent in applications in which the person being recognized cooperates with the system. In controlled, cooperative settings, face recognition systems have improved rapidly, with error rates roughly halving every two years in some evaluations. Under ideal conditions, top-performing systems may make a mistake only once in several hundred attempts.
Face recognition is also increasingly used by law enforcement agencies to identify uncooperative subjects, identify criminal suspects, and find missing children. Its use in surveillance is also growing. For example, Immigration and Customs Enforcement (ICE) is using FRT to identify people and determine their immigration status. In these applications, FRT often successfully identifies individuals, but their accuracy is not as high, and the potential for harmful errors increases. An incorrect match in this instance can potentially result in wrongful detention or deportation of American citizens. As face recognition use grows, so will its benefits and harms, making it an urgent matter to understand its properties, impact, and effective policy interventions.

Figure 2. Each column shows a pair of images of the same person. Experimental subjects find the images on the left easiest to match, while it is most difficult to determine that the images on the right come from the same individual.
Face Recognition Difficulty Varies Significantly
The difficulty of face recognition problems varies tremendously depending on the setting. Figure 1 has already shown a difficult operational setting, in which a poor quality surveillance image must be matched. A human examining these images has a hard time telling whether they are of the same person. Figure 2 shows that even when images are of good quality, it is not always easy to tell whether they come from the same person, due to changes in things like hairstyle.
What Do We Mean by Bias in Face Recognition?
Bias in face recognition has been the subject of significant public concern and extensive research over the past decade, particularly as these systems have been deployed in high-stakes settings such as law enforcement and surveillance. This report examines the nature, causes, and consequences of this bias, and in this introduction we begin with a brief discussion of what we mean by “bias”.
Face recognition is meant to solve a problem that has an objectively correct solution; do these two images come from the same person? We say the system displays bias against certain demographic groups if it makes more errors on these groups than on the general population. We will use the terms “bias” and “differential performance” interchangeably.
FRT have consistently shown worse performance on women than men and worse performance on Black people than on white people, and many FRT display worse performance on East Asian people than white Americans. One way that bias can occur is through training FRT models using unbalanced data that better represents some groups. When this occurs, bias can be mitigated by augmenting the training set to represent different groups more equally.
However, defining demographic subgroups exactly can be difficult, making it hard to balance data. Studies that compare performance on men and women generally ignore subtleties of gender identity. Groups of Black or white people used in studies certainly contain many individuals of mixed race and, for example, Black people in the United States might have a different distribution of traits than Black people from East Africa. Different studies sample demographic subgroups in different ways, and therefore may not be evaluating exactly the same questions.
Moreover, it is unclear how best to define demographic subgroups. For example, is it more fruitful to measure differential performance between white and Black people, or between light-skinned and dark-skinned people? Black people can differ from white people not just in skin tone but also in structural properties of their face. At this time, it is unclear which aspects of appearance account for differential performance and how this would align with all possible subgroups. Most studies have been limited to a few broad demographic categories and it is not known, for example, whether performance would differ between specific nationality groups within a similar region such as Vietnamese and Korean people.
Outline of the Rest of the Report
This article aims to provide necessary background to assess the trajectory and risks of bias in face recognition technology. We do not address other important concerns about FRT, such as maintenance of privacy and the use of FRT in mass surveillance.
In the next section we will briefly describe how face recognition systems work. We will then discuss the world-wide scope of face recognition. Next we summarize the accuracy of FRT and how this has progressed. We then discuss the nature of bias in FRT, and consider the causes of this bias. Next we consider FRT as part of a socio-technical system, and the impact of human users on FRT harms. Finally, we suggest possible policy interventions to reduce these harms.
This report makes the following points:
1. Improvements in accuracy have not eliminated bias.
Face recognition systems have become significantly more accurate in recent years, but they continue to exhibit differential performance across demographic groups.
2. Bias is difficult to measure and difficult to fully eliminate.
In real-world, uncontrolled settings, bias is harder to quantify and may be larger than benchmark results suggest. While technical interventions can reduce disparities, there is no simple or complete solution.
3. Harms arise from both technical errors and how systems are used.
Errors in face recognition can lead to significant harms, including wrongful arrests and other adverse outcomes. These harms are often amplified by deployment decisions, such as where systems are used and how results are interpreted.
4. Face recognition should be understood as a sociotechnical system.
Bias and harm arise not only from the underlying models, but also from human judgment and organizational practices. Inappropriate use of face recognition results can be more significant than technical error.
5. Policy interventions can reduce harms even without perfect technical solutions.
Effective policies include improving transparency and evaluation, supporting research on real-world performance. Furthermore, just having humans check the results of FRT is not sufficient to avoid errors; this requires establishing clear, detailed protocols governing when and how face recognition may be used.
6. Governance of use is as important as improving the technology.
Auditing data and system outputs, developing tools that signal when results are unreliable, and enforcing strict use protocols can significantly reduce the risk that errors lead to harmful outcomes.
Glossary
How Face Recognition Works
Face recognition is based on machine learning, and highly dependent on the use of large-scale data sets. This data is difficult to carefully control or characterize.
Face Recognition refers to the process of automatically identifying a person from a photo. It is divided into two tasks. In verification (or one-to-one matching), two images of faces are compared to provide a yes/no answer to the question of whether they come from the same person. This is used, for example, in border control, when a live image of someone may be compared to their passport photo. In identification (or one-to-many matching), a single probe face image is compared to a potentially large gallery of images to determine which, if any faces in the gallery match the probe image. The gallery might contain, for example, mug shot images of people who have been arrested, driver’s license photos, images of people who have been barred from access to casinos, or a large collection of images scraped from the internet. A system performing identification might declare that it finds no match, return a single match, or return a potentially large collection of images that might resemble the probe image. In the latter case it is expected that these potential matches will be assessed by the user to identify valid matches. FRT may also return a confidence level about the correctness for each match, although these may not correspond to the true probability that the match is right.
A Brief History of Face Recognition
The first fully automatic face recognition system was developed 50 years ago as the subject of the PhD thesis of Takeo Kanade, who went on to become one of the pioneers in the field of computer vision. It identified landmarks on the face, such as the corner of the mouth, and used their position to compare images. Early methods like this, based on face geometry, had limited effectiveness. Scientists began to develop more useful and accurate face recognition systems through the growing use of machine learning, beginning in the late 1990s. These methods are trained with numerous face images, called a training set, to automatically extract representations of faces that can be used to compare them more robustly.
Progress accelerated rapidly as researchers began to appreciate the power of using an approach known as neural networks, which allowed them to leverage massive datasets of faces to “teach” the computer how to recognize new faces. While neural networks were used by FRT by the late ’90s, their use became dominant in the mid-2010s after further breakthroughs in machine learning with large neural networks, a technique known as deep learning. Since the mid-2010s, improvements in model architectures, training methods, and data scale have driven substantial gains in measured accuracy, especially on standardized benchmarks. At the same time, these advances have enabled rapid adoption of face recognition across a range of applications, from smartphone authentication to large-scale identification systems used by governments and private firms, even as performance in real-world settings remains highly dependent on context.
How Face Recognition Models Are Trained
To perform accurately, an FRT must be able to determine that two images of the same person are similar, even if the images are taken at different times, from different viewpoints, under different lighting conditions. This is done by training the machine learning model to extract a representation that captures facial properties that can distinguish one person from another, but that are not significantly affected by viewing conditions or even some aging. The similarity between two faces can be given a numerical score that represents the degree of difference between the representation of each face.
In its simplest form, training occurs by incrementally adjusting the parameters of a neural network. In most current publicly available systems these parameters consist of tens of millions of numbers that control the network’s behavior. If it is shown two images of the same person, the parameters are adjusted to increase the similarity score. If the images are of two different people, parameters are changed to lower the score. Once the model is trained, if two images produce a similarity score above a chosen number, known as the cutoff, the system declares the two images to be the same person; if it falls below that cutoff, the system says they are different.
Once the model has been trained, it can perform identification using a gallery of faces by comparing a representation of the probe to representations of the gallery images. That is, it can verify or identify images of people who were not in the training set, because it has learned a general representation that should apply to any faces.
The large data sets used in training are typically scraped from the internet. For example, one influential early data set, Labeled Faces in the Wild, made use of face images detected in Yahoo! news stories, with identifying captions. A number of large scale datasets containing millions of images have been developed using photos of celebrities available on the internet. Some companies, such as Meta and Google have made use of internal data that users have uploaded and labeled; these training data sets may contain more than 100 million images. Clearview, a face recognition company, claims to use data sets of more than 70 billion face images scraped from the internet. Given the high cost and diminishing returns of training with so many images it is unlikely that all of these images are used for training, and this large corpus is more likely to be used to form the gallery.
Academic FRT generally train on datasets of images of public figures, such as the MS-Celeb-1M dataset, which contains ten million images of about 100,000 individuals. These massive datasets capture how a person’s appearance can vary with age, lighting, viewpoint, expression, and other conditions, which helps improve accuracy of systems trained on the datasets. Commercial systems do not generally provide details of their training sets, but it is expected that they include similarly large sets of images scraped from the internet, or provided by users, as in the case of Google and Meta. However, because these data sets are assembled at enormous scale—often from uncontrolled sources—they are difficult to audit, regulate, or correct when they embed systematic biases.
Face Recognition in Use Today
Face recognition use is increasing rapidly, becoming more prevalent in numerous high-stakes applications.
The global face recognition market was almost nine billion dollars in 2025, with projected growth to over 30 billion by 2034. Over a third of this market is in the U.S., but there is wide adoption of FRT around the world. One of the primary applications of face recognition is to efficiently and reliably identify people. This can make access to financial systems more secure, potentially preventing identity theft. It can also make hospital admissions quicker and more accurate, and speed up passport verification. In these applications, a human subject opts-in to using the FRT, cooperating to allow consistency in viewpoint, avoiding unusual facial expressions, and enabling controlled lighting. This leads to highly accurate systems. In many cases, such as using FRT to unlock cell phones, users opt-in to the technology for added convenience and device security. When entering the country, U.S. citizens may opt-in to face recognition systems, and their photos are deleted after 12 hours, while non-citizens are required to participate, with photos retained for 75 years.
Face recognition is also widely used in surveillance and law enforcement. Ten percent of U.S. police departments use FRT. The NYPD made 2,878 arrests resulting from FRT in the first five years of its use. The Metropolitan Police in London report 100 arrests using FRT in conjunction with mounted security cameras, including a suspect accused of kidnapping. Police in New Delhi used FRT to identify almost 3,000 missing children, and FRT has been used to identify refugee children who have been separated from their family. The National Center for Missing & Exploited Children (NCMEC) has used a tool called Spotlight, which makes use of FRT, to identify children who are victims of sex trafficking. In 2023, the FBI worked with NCMEC to identify or arrest 68 suspects of trafficking. A large number of retail stores use FRT to track customers to understand traffic patterns, and despite the Rite Aid case, retailers such as Wegmans still use FRT to spot accused shoplifters. Immigration and Customs Enforcement (ICE) is using FRT to identify people and determine their immigration status.
Face recognition has been widely used for surveillance of the Uyghur population by the Chinese government., FRT are used by the Israeli government to track and surveil Palestinians.
These applications of face recognition can solve crimes, enhance security and make access more convenient, but also raise troubling concerns about mass surveillance, repression of civil liberties, and high-stakes errors which materially harm people. In surveillance and criminal investigations, subjects are not cooperative, and probe images used are often of poor quality, as illustrated in Figure 1, which produces much higher error rates. An awareness of mass surveillance can also have a chilling effect on people’s ability and willingness to participate in Constitutionally protected activities such as protest or dissent.
As face recognition has grown more practical, a large number of companies have developed and marketed FRT. This includes large tech companies such as Amazon, Microsoft, Toshiba, NEC and Apple, and smaller companies that focus more narrowly on face recognition, biometrics and security, such as Clearview, Idemia, and Rank One Computing. Clearview is one of the most widely used by federal and local law enforcement in the U.S.
Early in the development of face recognition technology, the best performing systems were produced by academics and used openly available architectures and data. However, with its rapid commercial growth, state of the art FRT are generally developed by companies that provide little transparency about how they work or what data they use. As we will discuss in more detail, the National Institute of Standards and Technology evaluates the performance of some of these systems, but this evaluation is voluntary and not all companies participate.
Face Recognition Performance Across Different Conditions
Face recognition performance has improved rapidly, but recognition can still be quite difficult in many settings.
Two types of errors can occur in face recognition. With false positives, a FRT incorrectly states that two images come from the same individual. With false negatives, the system incorrectly states that two images do not come from the same individual. The cutoff is what determines the balance between false positives and false negatives. Tightening it makes the system more cautious about declaring a match (reducing false positives) but also more likely to miss legitimate matches (increasing false negatives).

Figure 3. The ACLU found that Amazon’s face recognition system matched 28 members of Congress to mugshots of other people.
The significance of this cutoff is illustrated well by the American Civil Liberty Union’s (ACLU’s) evaluation of Amazon’s FR system, “Rekognition” and the subsequent controversy. The ACLU reported that they had tested Rekognition, and that it incorrectly identified 28 members of Congress with people who had committed crimes (Figure 3). A significantly disproportionate number of these false matches were people of color. Amazon responded by arguing that although the ACLU had used the default cutoff, or confidence threshold, of 80% for Rekognition, this was more appropriate for finding celebrities on social media, and that their documentation recommended a much more stringent cutoff of 99% for use in high stakes applications such as law enforcement. Amazon also pointed out that the bias in the results may have been due to bias in the gallery of images used by the ACLU. If the ACLU compared images to a gallery that disproportionately contained people of color it would be more likely to produce false matches for people of color in congress. The ACLU replied by stressing the dangers of a system that was inaccurate with default thresholds and a lack of guidance for the system’s use.
One lesson from the Amazon Rekognition controversy is that the potential harms of an FRT depend not just on its technical accuracy but also on how users apply these systems. It also provides some indication that Rekognition was more prone to false positive errors when applied to people of color, at least at one significant cutoff threshold.

Figure 4. Three images of a researcher at the National Institute of Standards and Technology. The left image simulates a passport or similar photo, the middle image simulates images that might be taken while going through immigration, the right image simulates an image taken by a kiosk.

Figure 5. Two pairs of images, each pair shows the same person under identical imaging conditions except for a change in lighting (images from the Multi-PIE dataset).
Challenges in Real-World Face Recognition
The most rigorous experiments measuring face recognition accuracy are conducted under tightly controlled conditions. As a result, reported performance often overstates how systems perform in real-world settings, where error rates can be much higher.
The difficulty of face recognition tasks can vary widely. Frequently, identification is performed by performing verification between the probe image and all gallery images. Identification becomes more difficult as the gallery size grows and the number of opportunities for false positive matches increases. The difficulty of face recognition tasks also depends very much on the conditions under which images were taken. For example, in border control, the subject can be required to face the camera with their face fully visible, lighting can be controlled, and camera quality can be ensured.
Figure 4 shows that even images taken at a kiosk can be much harder to match, due, for example, to changes in viewpoint. Figure 5 illustrates the effect that a change of lighting can have on the difficulty of matching faces. As previously shown in Figure 1, when images come from surveillance cameras, the subject may not be facing the camera, they may not be close to the camera, so image resolution can be low, and their hair or hand or another object may obscure part of the face. Identification with poor imaging conditions may have many orders of magnitude more errors than verification under tightly controlled conditions.
By all metrics, there seems to be little doubt that face recognition accuracy has been improving rapidly. The National Institute of Standards and Technology (NIST) Face Recognition Vendor Test (FRVT) evaluations illustrate this increase (most recent results here). NIST evaluates verification performance on two high quality images of frontal facing individuals. From 2020 to 2025 the error rate fell by a factor of three. (They set a threshold for matching to achieve a false positive rate of 0.003%, so about one false identification in 33,000 attempted matches. They then measure the false negative rate, the number of correct matches missed. The best performing system as of January 2025 achieved a false negative rate of 0.13%, a little more than one correct match missed in 800.) Similarly, the error rate on an identification task that matched a mug shot probe image to a large gallery of mugshots fell by a factor of 5 during the same period. (The best performing method, when using a threshold to produce a false positive identification rate of 0.3%, had a false negative error rate of 0.05%. This means that the system would falsely identify a probe image in the gallery (of 1,600,000 mugshots) one time in about 300, while missing a correct match about one time in 2,000.) Some results are shown in Figure 6, as of March 2025. Over a period of decades, NIST has found that errors have generally fallen by about a factor of two every two years. Under controlled conditions, FRT are now much more accurate. For example, on the best performer as of March 30, 2026, when performing verification on two mugshots, using a cutoff set to make a false positive match one time in a million, a false negative failure to find a match will occur one time in 500. This sharp increase in accuracy in a short period has happened alongside widespread adoption in applications like border control or unlocking a phone.
These experiments represent relatively ideal conditions. FRT in the real world may face much higher failure rates. This can occur due to more challenging imaging conditions, such as using a surveillance image as a probe, instead of a mugshot, or other factors such as changes in the subject’s appearance. For example, when the best performing system at mugshot identification is applied in a scenario in which the gallery contains visa images and the probe is taken from a kiosk, the error rate increases by a factor of about 18 with a false negative error about one time in 30 instead of one time in 500. This is a fairly typical increase, and still represents relatively idealized conditions compared to the most challenging ones.
Defining and Measuring Bias in Face Recognition
Face recognition performs with different levels of accuracy on different demographic groups. As face recognition becomes more accurate, this may limit the effects of this disparity in some applications, but it can still be quite significant in high-stakes applications.
Going back more than 30 years, researchers have observed different rates of accuracy in face recognition systems depending on demographic properties of the subject, including race, gender and age. For example, in 2011 a study showed that Western face recognition algorithms performed better on Caucasian faces than East Asian faces, while East Asian face recognition systems performed better on East Asian faces than Caucasian ones. In 2018, the influential Gender Shades paper examined differential performance not in face recognition, but in a related facial analysis problem of determining gender from a face, showing much poorer performance on images of dark skinned females than light skinned males.
Absolute vs. Relative Error
In considering differential performance, it is important to distinguish between absolute and relative differences in performance. We define the absolute difference in two error rates as the difference between the larger and smaller error. For example, if an FRT produces 2% error on male faces and 4% error on female faces, we would say that the absolute difference is 4% – 2% = 2%. We describe the relative error as the ratio between the larger and smaller value, which in this case would be 4%/2% = 2. As overall performance improves, the absolute error tends to decrease, while the relative error rate might or might not decrease. For example, if a new generation of FRT reduces error on male faces to 1% and reduces error on female faces to 2%, absolute error decreases from 2% to 1%, while relative error remains constant.
Whether absolute or relative error is more important depends on the operational considerations and use of the system. When performance is very high, absolute error will tend to shrink. If this translates into operational settings, then relative error may become unimportant. For example, if an FRT makes a mistake once in a billion queries on one population, and twice in a billion on another, errors for either population may be so rare that they are insignificant. In practice, the impact of absolute error also depends on how widely deployed a system is. As systems become more accurate, they may become more widely deployed, which can paradoxically result in more accurate systems producing more errors.
Even though current FRT achieve quite low error rates under ideal conditions, these error rates tend to grow much higher under more challenging conditions, and errors can be quite common. Although it is difficult to study error rates accurately under the most challenging conditions, high relative error under ideal conditions may predict relative error that is just as high or higher under challenging conditions that also have high absolute error. That is, while absolute error in operational contexts is of greatest importance, relative error in highly controlled conditions may predict high absolute error in less controlled conditions. Consequently, it is premature to think that FRT are so accurate that relative error is no longer important. A more nuanced view would hold that continuingly high relative error rates may be less important for some applications, such as unlocking phones, and still be quite important in other applications, such as criminal investigations.
NIST Experiments on Demographic Variation
Since 2019 NIST has performed extensive evaluations of demographic variations in performance on hundreds of face recognition systems. They have access to large collections of non-public images that they use to evaluate FRT submitted by companies. The large size and private nature of the dataset makes it especially unlikely that models are overfit to the data by, for example, selecting parameters that boost their performance on this particular data. NIST computes false negative rates using over a million pairs of images, comparing one high quality image of an individual to a medium quality image of the same person. False positive rates are computed using over a billion pairs of high quality images from different individuals. Image quality reflects applications such as passport checks at airports, but does not include more challenging problems such as police investigations using surveillance footage. All images come with demographic information, including the age, gender and country of origin of the subject. Country of origin is used as a proxy for race, focusing on countries that are less racially diverse, but this is not a perfect proxy.
NIST finds a relatively small demographic variation in false negative rates, in which a correct match is missed, and a much larger variation in false positive rates, in which an incorrect match is accepted. For example, the top performing FRT as of March 2025 produced 358 times as many false positives for West African females over 65 as for Eastern European males aged 35-50, with the false match rate increasing from about one in 15,000 to about one in 50. Among the top ten performing systems, the false positive rate for all West Africans was about 23 times higher, on average, than the rate for Eastern Europeans. The false positive rate for these performers on average is about 4.6 times higher for females than males, and about 2.9 times higher for people over 65 compared to people aged 20-35. The evaluations also show poorer performance on people from South or East Asia, relative to Eastern Europeans. Many additional studies have also found that FRT generally perform better on white people than people from other racial groups, and on males compared to females.
These studies do have important limitations. More narrowly defined groups (e.g. West African women over 65) will have less data, leading to noisy estimates, and when we take the ratio of two noisy estimates we amplify the noise. Also, images taken in different countries may differ in ways beyond the race of the subject, such as in the types of cameras or lighting used. Also, incorrect labels may have a significant effect on accuracy. If a visa photo is associated with the wrong name, this can lead to a false match, and these incorrect labels may be more prevalent in some countries than others. Finally, measures of bias may vary depending on the specific ways in which performance is measured. The chief scientist of a leading face recognition company has stated that in practice they find differential performance between racial groups of a factor of approximately 1.5, rather than the higher numbers found in NIST studies. (Brendan Klare, personal communication.)
Challenges in Measuring Bias in Face Recognition
There is decades of evidence of differential performance of face recognition between demographic groups, particularly affecting non-white people and females. However, these studies generally make use of relatively high quality images, and may not accurately reflect the degree of differential performance in challenging operational cases, such as the use of surveillance footage in criminal investigations or in identifying people on a watch list. This is due to the fact that it is quite difficult to accurately characterize and sample images from challenging environments. And while large scale photo collections with known identities and some demographic information exist, such as passport photos, we do not have large scale collections of photos taken in challenging conditions that have this information. While this problem is elusive, there is some evidence that differential performance increases with the difficulty of the recognition task.
Another limitation occurs because races are not well-defined biological categories but social constructs. It is not clear how to systematically divide a population into different races, especially in the case of multi-racial individuals. This is particularly challenging when images are scraped from the internet, and need to be labeled by race. Some studies have focused on skin darkness rather than race, but this is also difficult to determine accurately from photos due to the effect of unknown lighting conditions on apparent skin color. In spite of these limitations, there is a clear consensus among researchers that differences in FRT performance exist between racial groups.
An important question is how differential performance in face recognition is evolving over time. Is this a problem that was initially ignored, but is now being effectively addressed, or one that is recalcitrant? While there is no question that absolute differences in accuracy are shrinking over time, as FRT become more accurate, the behavior of relative differences is less clear. This is difficult to judge, since new test sets come out frequently, and experimental performance is generally measured over an ever changing landscape of conditions. Perhaps the most stable evaluation framework is NIST’s, which has consistently evaluated new FRT under the same conditions including systems developed from 2018 to 2026. Some of the top performing FRT have evolved, with multiple versions being released over this time period. When we examine these, we see that some have significantly reduced the amount of bias over time, while others have not, and have even seen increased bias. This suggests that it may be possible to reduce systematic bias through model design. More details can be found in the appendix.
Sources of Bias in Face Recognition Systems
Bias in face recognition systems arises from a combination of imbalanced training data, differences in image quality and gallery composition, and other technical and operational factors that are difficult to fully control or eliminate.
False negatives often arise when image quality is poor or facial features are obscured, while false positives are more likely when different individuals appear similar to the system, which can be exacerbated by limitations in training data or representation. For example, if we compare two images of the same person, and one of these images is blurry or has bad lighting or low resolution, the images may appear dissimilar due to these effects. FRT are trained to be somewhat robust to changes in viewing condition, but they are still likely to make errors when these changes are large. On the other hand, if a system is trained using few images of one demographic group, the system may not learn representations that distinguish between a wide range of appearances within that group. For example, if one trained an FRT using images of only one Black person, the system would likely learn to associate dark skin with that individual, and would not learn features that effectively distinguish between different Black people. This is an extreme example, but it is generally found that deep neural networks become more effective as the amount of relevant data increases.
We focus on false positive errors, as these show the greatest differences across demographic groups and are most closely associated with documented harms, such as wrongful arrests. In this section, we will discuss two key points. First, while it may be straightforward to improve demographic balance in datasets, completely eliminating demographic bias is complex and difficult. Second, while demographic bias in the data may be responsible for some bias in false positives, it is not necessarily the only source of these differences. Various research results present conflicting evidence of the importance of dataset bias in practice.
The Contribution of Dataset Bias
Face datasets collected in the last 15-20 years have generally consisted of images scraped from the internet. This enables the creation of large scale datasets that capture a wide range of variations in viewing conditions. These datasets often used well-known people with many online photos, without specific regard to accurately representing the distribution of people of different races or genders in the population as a whole. For example, an early and very influential dataset, Labeled Faces in the Wild (LFW), consisted of 77.5% images of men and 22.5% images of women. LFW was based on people who had appeared in Yahoo! news stories that were identified in captions, making it easier to build a large dataset of known people. However, these people were obviously not representative of the overall population.
Some more recent datasets pay closer attention to capturing the true distribution of people in the world. However, creating unbiased datasets can sometimes be a subtle and difficult problem. For example, the BUPT-Balancedface (BUPT) dataset was constructed to have equal numbers of images of Caucasian, Indian, Asian and African faces. However, subsequent analysis revealed that the Asian and Indian faces consistently appeared as a larger size in the dataset. So although the number of images was balanced, the viewing conditions of the images could still vary significantly. This discrepancy might, for example, lead to biased performance at test time.
The reason for systematic biases in datasets is often not well understood, but it is plausible that when scraping images from the internet, photos from different countries might follow different conventions, use different cameras, or differ in myriad other ways. Therefore, to judge whether a dataset is biased is not as simple as counting the number of images from each population.
A deeper difficulty is even defining what it means to have an unbiased dataset. BUPT represented four demographics equally. But it is unclear what should count as a racial category. For example, should Asian faces be counted as one category? Should Chinese and Japanese people be considered two separate racial categories? What about multiracial individuals? The concept of race is not biological, but a social construct that is not well defined. It is also problematic to correctly label the racial origins of large scale datasets, which may contain images of millions of people. It seems clear that paying attention to demographic diversity will produce less biased datasets than building datasets based on arbitrary selection of celebrities. However, it is also clear that creating completely unbiased datasets is an ill-defined problem. Even with a given definition of “unbiased” it remains very challenging and beyond current technology.
There is certainly strong evidence that dataset bias can produce differential performance, and bias can be reduced through improving the training data balance. It has been found that while Western face recognition algorithms perform better on Caucasian faces than on East Asian faces, algorithms developed in East Asia perform better on East Asian faces, a result that is likely due to dataset bias. After the Gender Shades paper demonstrated that Microsoft’s gender identification algorithm performed much more poorly on Black women than white men, Microsoft quickly improved performance dramatically on Black women by balancing its datasets.
Differential performance can also occur because of biases in the gallery data or probe data. When the gallery is formed from images scraped from the internet, the properties and number of these images may vary drastically from individual to individual, or even from group to group. It has been shown, for example, that if one group is more highly represented in the gallery, this will lead to more false positives among that group because there is greater potential for the gallery to contain faces similar to the probe. As another example, if one group, such as women, frequently have longer hair that covers more of their face in the probe image, this can also lead to higher error rates. Also, if a gallery image is of low quality, not showing a clear image of the face, it may be matched to a similar low quality probe image of a different person. Rite Aid’s use of low-quality images in its gallery is believed to have contributed to the large number of false matches it produced, which in turn led to customers—disproportionately in non-white neighborhoods—being wrongly flagged, confronted, and sometimes expelled from stores. When companies such as Clearview make use of billions of images scraped from the internet it is extremely challenging to balance these datasets or ensure uniformity in their quality.
Assessing dataset bias in commercial systems is complicated further by the fact that companies generally do not make their datasets publicly available or disclose many details about them. Moreover, NIST experiments on dataset bias do not make use of the galleries used by commercial systems. Therefore any bias due to galleries would not be detected.
Sources of Bias Beyond the Data
Other factors besides data may also significantly influence differential performance. Some experiments have shown that even balanced datasets do not produce equal performance on men and women, or between races, and that sometimes more biased datasets produce less biased and better results. Furthermore, demographic groups may have properties that make them easier or harder to recognize. For example, there may be greater variation in hairstyle in one gender than another, and males in different countries may have different trends in facial hair. If someone has an unusual beard, for example, this may make him easier to recognize, or harder to recognize if he shaves his beard. It is difficult to determine the effects on differential performance of social conventions affecting appearance. It has also been noted that darker skin may require different types of lighting to bring out the facial structure. This could result in more recognition errors for people with darker skin when lighting is not controlled.
In summary, it is clear that extreme dataset bias produces biased results. It is quite challenging to produce perfectly unbiased datasets, and less clear to what extent the differential performance observed in modern face recognition systems may be due to dataset bias, especially since these systems are built with proprietary data that is not open to public examination.
Reductions in Bias Over Time
From a policy perspective, perhaps the most important question is whether companies have the ability to produce less biased FRT. To address this question we examined NIST measurements of the performance of models produced by leading companies. NIST has assessed the degree of bias in multiple models produced over time by some companies, allowing us to see how their performance has evolved. Based on NIST reports, we find that some companies have significantly reduced the absolute and relative bias in their systems in two or three years after initial evaluation, while other companies have not reduced relative bias, and in some cases it has increased, even while absolute bias decreases due to improved overall accuracy. Details of this analysis may be found in the appendix.
These results suggest that companies are capable of reducing bias, although this is certainly not definitive. In a conversation with one of the authors, the chief scientist at a leading face recognition company confirmed that NIST evaluations have helped them identify certain variants of differential performance between racial groups, enabling them to take effective steps to proactively identify and reduce bias whenever the company becomes aware of it. (Brendan Klare, personal communication.)
The Human Factor: Face Recognition Systems as part of a Socio-Technical System
Many errors in face recognition are due not just to mistakes by the technology, but to the way in which people make use of it.
The preceding sections focused on the technical properties of face recognition systems. However, these systems do not operate in isolation. They are embedded in what researchers call a sociotechnical system, in which the technology interacts with human judgment and organizational practices. The real-world effects of face recognition therefore depend not only on technical FRT performance, but also on how human users interpret and act on its results. In practice, this interaction can create distinctive failure modes. For example, users may rely too heavily on algorithmic matches without considering other evidence or fail to appreciate how image quality and threshold choices affect reliability.
Limitations of Human Oversight
Some authors argue that these human factors can be structured to correct for technical weaknesses in face recognition systems. One commentator contends that: “it is stunningly easy to build protocols around face recognition that largely wash out the risk of discriminatory impacts…. A simple policy requiring additional confirmation before relying on algorithmic face matches would probably do the trick… one has to wonder why so few researchers who identify bias in artificial intelligence ever go on to ask whether the bias they’ve found could be controlled with such measures.”
However, empirical evidence suggests that this confidence in human oversight may be misplaced. First, FRT tends to make errors on difficult cases, in which humans also make errors. Studies show that humans are unable to identify many of the errors made by automatic systems. Furthermore, human performance on face recognition suffers from similar differential performance as machine learning systems. Dubbed the other-’race’ effect, it has long been known that humans are more accurate in recognizing faces from their own race than from others (it has been posited that this also stems from dataset bias, in that people encounter more individuals of their own race than of others). Some work indicates that current automated systems recognize faces more accurately than the typical person, and that in some cases, combining a less effective human judgement with an automatic system may actually lead to lower accuracy than simply using the results of the automatic system. Human judgements can in some cases be used to improve algorithmic accuracy but it may be difficult to determine when that is the case. In general, we cannot assume that human judgements will be accurate or that human oversight can be counted on to correct errors made by automatic systems.

Figure 7. Christopher Gaitlin, right, was identified using the security photo on the left.
User Errors
Consistent with these findings, many of the known cases of false arrests due to FRT errors involved questionable practices by investigators. Christopher Gatlin was arrested for the brutal assault of a security guard, after an FRT flagged him as a possible suspect, based on a low quality image (Figure 7). Police steered the security guard to identify Gatlin, in what they later admitted was improper behavior.
Robert Williams was arrested for burglary one year after the crime, based on applying FRT to a surveillance video. Lacking witnesses, police showed the surveillance video to an employee of the store’s insurance company, who identified Williams from a photo array, although the video was of poor quality and his face was obscured by a shadow (Figure 1). The police failed to take basic steps such as investigating Williams’ alibi. The police chief at the time, James Craig, said that “this was clearly sloppy, sloppy investigative work.” In other cases, police have shown a single suspect’s photo to a witness, violating best practices by being unduly suggestive. This led to an arrest despite the suspect’s convincing alibi.
In cases where FRT lead to false arrests, it seems that police may in fact give undue weight to the results of FRT, rather than catching their errors, an example of “automation bias”. In another case in which recommended procedures were not followed, police were unable to obtain face recognition results due to the low quality of the surveillance image. A detective felt that the surveillance image resembled the actor Woody Harrelson, and used a picture of him to search for matches, rather than the suspect’s photo.
Failures in the use of FRT occur not only in police investigations. In the Rite Aid case mentioned in the introduction, the FTC’s complaint highlighted not just algorithmic errors but significant governance failures in how the system was operated by store employees. The commission found that Rite Aid did not take reasonable steps to train or oversee store employees who were responsible for acting on match alerts, including failing to teach staff how to interpret alerts or warn them that false positives could occur. The company also failed to test or monitor the technology’s accuracy once deployed, enforce image-quality standards, or implement any procedure for tracking false positive alerts and employee responses. As a result, employees in hundreds of stores routinely followed, confronted, searched, or even called police on customers based solely on system alerts—actions taken without meaningful training on the system’s limitations or appropriate safeguards. These shortcomings in training, oversight, and procedural controls were central to the FTC’s determination that Rite Aid had failed to prevent foreseeable consumer harm from the technology’s use.
In summary, it may be difficult for humans to correct mistakes made by algorithms, and in some cases they may place undue confidence on FRT results that are questionable and based on low quality images. In many applications, such as drug stores that are looking for known shop lifters, the people making use of FRT may not be expert investigators or well trained in the appropriate use of these systems.
Policy Interventions to Address Bias in Face Recognition Systems
Many errors can be addressed by better understanding and regulation of the way in which the technology is used.
A wide variety of policy interventions are available to deal with potential harms caused by bias in FRT. These include research, transparency in documenting bias, voluntary or mandatory guidelines governing the use of face recognition, and outright bans on the use of face recognition in certain contexts. As noted above, FRT make positive contributions in law enforcement and other applications, and these positives must be weighed against potential harms in crafting policy. Numerous institutions have suggested policy changes to address bias in FRT, including a comprehensive set of proposals in a recent report from the National Academies.
Research
Federal agencies already support substantial research on face recognition. NIST conducts ongoing evaluations of performance and demographic disparities, and agencies such as the Office of the Director of National Intelligence (ODNI) and the Intelligence Advanced Research Projects Activity (IARPA) have funded foundational research in face recognition systems. However, important gaps remain, particularly in understanding how these systems perform under operational conditions and how human users interact with their outputs. Additional federal funding could expand independent research in these areas, either by strengthening NIST’s evaluation programs or by supporting academic and nonprofit research focused specifically on bias mitigation and real-world deployment risks.
Two research priorities are especially important. First, evaluation frameworks should better reflect real-world conditions. Current large-scale benchmarks often rely on relatively high-quality images, whereas many high-stakes uses—such as criminal investigations—depend on low-resolution or poorly lit surveillance images. While efforts such as the IARPA Janus Surveillance Video Benchmark (IJB-S) dataset have begun to address this issue, broader and more systematic testing under operational conditions would provide policymakers with a clearer understanding of real-world risk.
Second, research is needed to develop tools that help human operators interpret and appropriately limit their reliance on face recognition results. For example, systems could assess probe image quality, estimate the likelihood that a reliable match can be produced, and warn users when results are unlikely to be dependable. Such tools could reduce the risk that investigators or retail employees draw strong conclusions from low-quality, unreliable inputs.
Measure and Reduce Bias
A better understanding of the bias in FRT can inform the procurement decisions of potential customers and encourage companies to take steps to reduce bias. Transparency in bias can be promoted in a number of ways. NIST is already conducting regular and impactful evaluations of bias in FRT, which can be thought of as an application of the Common Task Method (such evaluations have long been common in the computer vision community). This can be continued and potentially expanded. Regulations or government procurement guidelines can be used to incentivize or require companies to participate in evaluations and make these results public. Since criminal investigations are conducted by the government, procurement guidelines are a strong potential lever in promoting transparency. In addition to transparency in performance, these approaches could also be used to promote transparency in the data used to train FR systems. Making training data public may raise significant privacy concerns, but the government could incentivize the release of information describing the data and the steps taken to enhance the demographic balance of these data sets.
Regulate Sociotechnical use of Face Recognition
If we view FR as part of a sociotechnical system, it makes sense also to govern the way in which face recognition is applied, not just the technical performance of the underlying algorithm. In practice, “responsible use” protocols need to specify who can run searches, what minimum image-quality standards apply, what form results can take, and what documentation and oversight are required. They should also define the permissible purposes for which searches may be conducted, restrict access to trained and certified personnel, require supervisory approval for high-stakes uses, and mandate that face recognition results be treated only as investigative leads rather than as dispositive evidence. Protocols can require minimum similarity thresholds below which no candidate match is returned, prohibit the use of face recognition on images that fall below objective quality metrics, and require contemporaneous documentation explaining why a search was initiated and how results were interpreted.
Additional safeguards could include audit trails of all searches and outcomes, periodic independent audits of performance and demographic disparities, disclosure requirements when face recognition contributed to an arrest or charging decision, and exclusionary consequences if required procedures are not followed. Agencies could also be required to collect and publish aggregate statistics on the number of searches conducted, the rate at which matches lead to arrests, and the frequency of erroneous identifications.
As an example of governance procedures, the FBI has established guidelines on the use of face recognition. These include limiting situations in which it can be used and the type of probe images used. They require that all face queries be evaluated by trained examiners and mandate that face recognition be used for investigative leads that must be corroborated.
As another example, the New York City police department (N.Y.P.D.) has spelled out a detailed protocol for the use of FRT. This requires investigators to submit face images to a special facial identification section of the department (the Real Time Crime Center, Facial Identification Section) that will, for example, ensure that image quality is sufficient and that use of FRT is warranted. The section can reject unsuitable probe images and reviews matches. Critically, a “possible match candidate” is meant to be “treated as an investigative lead only” and does not establish probable cause to make an arrest. The unit also retains records of searches and results. It has been reported that in other localities, investigating officers have accessed FRT directly, without supervision. Specific requirements could be mandated, with legal consequences if they are not followed, such as disallowing evidence produced in subsequent investigation.
However, in spite of N.Y.P.D. guidelines, FRT did lead to the false arrest of Trevis Williams. After FRT identified him as a suspect in a crime, the victim identified him from a photo lineup, although he was eight inches taller and 70 pounds heavier than her initial description of the suspect, in addition to other exculpatory evidence. This illustrates the difficulty of ensuring that guidelines effectively prevent errors and false arrests.
Regulation may be applied not only to government agencies, such as police departments, but also to private companies that are increasingly deploying face recognition systems in commercial settings. RiteAid’s use of face recognition illustrates how governance failures can arise outside of law enforcement. According to the FTC complaint, “Rite Aid failed to consider or address foreseeable harms to consumers flowing from its use of facial recognition technology, failed to test or assess the technology’s accuracy before or after deployment, failed to enforce image quality standards that were necessary for the technology to function accurately, and failed to take reasonable steps to train and oversee the employees charged with operating the technology in Rite Aid stores.” These deficiencies were not primarily algorithmic; they reflected a lack of risk assessment, testing, training, oversight, and ongoing monitoring.
The FTC’s enforcement action demonstrates that existing consumer protection laws can be applied to address some forms of misuse. However, as commercial deployment expands, more explicit regulatory standards may be necessary to prevent similar failures. Such standards could require companies to conduct pre-deployment accuracy and bias testing, implement image-quality controls, establish employee training and supervision protocols, monitor and document false positive rates, and assess foreseeable risks before using face recognition in customer-facing environments. Clear statutory or regulatory requirements would provide ex ante guardrails rather than relying solely on ex post enforcement after harms have occurred. Regulations could also require clear disclosure when face recognition is used—both to affected individuals and in aggregate public reporting—so that its role in decision-making can be scrutinized, evaluated, and corrected where harms emerge.
Policymakers should be willing to ask if using facial recognition is appropriate at all in certain circumstances. In higher-risk contexts, policymakers could impose outrights bans, limit use to specified categories of serious crimes, require a warrant, or mandate corroborating evidence before an individual identified through face recognition is included in a lineup or arrested.
As an example of use restrictions, the state of Maryland has limited the use of automatic face recognition to specific, serious crimes, and requires that defense attorneys be notified when it was used in a case. Montana and Utah require police to obtain warrants in the use of face recognition. In Detroit, police must obtain corroborating evidence before placing a suspect identified through face recognition in a line up. Several cities have banned the police use of face recognition, including San Francisco and Boston, while Portland has banned the use of face recognition by private entities in all public places.
At the federal level, members of Congress have introduced legislation that would impose a nationwide moratorium on government uses of face recognition technology absent explicit congressional authorization. Together, these restrictions illustrate a broader policy approach: limiting deployment in high-risk settings until adequate safeguards, transparency, and accountability mechanisms are in place.
Conclusions
Face recognition systems have improved dramatically in accuracy over the past decade, and in tightly controlled environments they now perform at very high levels. At the same time, substantial differences in performance across demographic groups persist, particularly in the false positive errors most closely associated with wrongful arrests and other harms. As overall error rates decline, these disparities may matter less in low-risk settings, but increasing deployment in high-stakes and uncontrolled contexts may lead to continued harms.
Technical improvements can reduce some sources of bias. Developers can improve dataset balance, adjust thresholds, and refine model design. However, eliminating differential performance entirely is beyond the current state of the art, particularly in operational environments involving low-quality images and large search databases. Policymakers should not assume that continued technical progress alone will resolve these disparities.
Perhaps most importantly, policymakers should view the regulation of face recognition through a sociotechnical lens, considering the interaction between the technical system and the humans who use it.
We cannot wait for perfect sociotechnical systems, but must govern the deployment of imperfect ones. Policymakers must decide where face recognition is not legitimate. If face recognition is used in high-stakes applications, it should be subject to clear limitations, transparency requirements, and enforceable protocols designed to prevent errors from cascading into wrongful arrests or other serious harms.
Appendix: Variations in Bias Over Time
We examined the performance of face recognition systems evaluated by NIST on different demographic groups. All results are based on data on a verification task, updated on March 5, 2025. More recent data on somewhat different tasks shows similar levels of bias. False positive matches are measured when comparing two high quality, visa-like images of two different people of the same sex, age group and region of birth. Demographic disparities are computed by taking the ratio of the false positive rate for two different demographic groups. For example, the ratio of the false positive rate on faces of people born in Western Africa to the false positive rate for people born in Eastern Europe for the highest performing FRT was 17.42, meaning that a false positive match was 17.42 times as likely for someone from Western Africa.
NIST has evaluated differential performance of commercial systems for over five years. Many companies have submitted multiple versions of their FRT over time, as the systems have improved. This allows us to determine how the bias in these systems has changed. We considered the 20 systems with best overall performance, which originated from 12 different companies. Eight of these companies had submitted at least four different versions of their FRT for evaluation, and so we focused on these eight systems.
Figure 8 shows the change in the ratio of differential performance for three pairs of demographic groups. For illustrative purposes, we show results from two different companies. The curves from Sensetime illustrate differential performance that has increased over time, while the curves from Rank One Computing (ROC) show differential performance that has decreased. Solid curves show the ratio of false positives for subjects of West African birth compared to Eastern Europeans. The dashed curves show performance on females compared to males. The dashed-dotted curves show an older age group (65+) compared to a younger cohort (20-35).
Table 1 shows the correlation between the passage of time and the ratio of differential performance for all eight companies. A negative correlation indicates that bias has dropped over time, while a positive correlation shows an overall increase in bias. If the correlation is close to 1 or -1, this means that the change in performance over time is highly consistent, while a correlation close to 0 means that there is no clear trend in the increase or reduction in bias. We can see that Toshiba, Idemia, and ROC have reduced biased performance over all three ratios, while Sensetime has increased bias, with other companies showing mixed performance.
Building Human Infrastructure to Mitigate AI Fairness Harms in K-12 Education
The rapid introduction of tools powered by artificial intelligence (AI) in K-12 education offers promises of data-driven personalized learning, real-time feedback, and relief for educators’ overstretched workloads. However, increasing access to emerging technologies alone is insufficient for achieving this vision. Without sustained, high-quality professional learning (PL), AI risks deepening a “digital design divide“— a gap where educators lack the support necessary to transform learning experiences by leveraging technology responsibly and effectively.
This challenge is not new. It mirrors a long-standing phenomenon in K-12 education where significant technology acquisitions occur without due efforts to sustainably build educator capacity. To mitigate this risk, state legislatures and education agencies must prioritize investments in human infrastructure– especially teachers, moving beyond systems that prioritize short-term tool training toward durable, high-quality professional learning systems.
Challenge and Opportunity
While a majority of U.S. educators now use AI in their work, the necessary support to use these tools effectively and responsibly lags significantly. According to RAND, half of the nations’ school districts have not provided training on AI, and high-poverty districts are even less likely to have provided training compared to their low-poverty counterparts. The failure to provide this essential support and the resulting disparity poses a dual fairness risk for vulnerable student groups. They may be subjected to biased or harmful AI practices, and they are also more likely to miss out on the innovative uses of AI, including deeply personalized learning responsive to their strengths, backgrounds, experiences, prior knowledge, and needs.
Furthermore, recent research identifies four systemic issues in current systems that govern professional learning (PL) for high-quality, technology-enabled instruction:
- Inconsistent Definitions: While K-12 leaders share a vision for student-centered instruction where technology like AI deepens and accelerates learning, few have a formal definition of what this looks like in practice or how PL supports it.
- Short-Term Funding Defaults: Funding often targets “one-off” workshops for specific tools and platforms. These meet immediate rollout needs but fail to build durable educator capacity in a rapidly evolving landscape.
- Compliance-Driven Monitoring: Tracking the impact of PL efforts often focuses on box-checking for relevant laws and regulations, rather than using data to refine instructional strategy.
- Lack of Documented Models: State leaders struggle to synthesize and disseminate locally-initiated, well-documented PL programs with evidence of success.
The real opportunity of AI lies not just in the tools, but in an educator workforce prepared to wield them. High-quality PL must thus move beyond short-term tool training to focus on areas necessary for equitable implementation, such as AI fairness and bias mitigation, ethical use of data, critical thinking, data foundations, and deep integration of AI-enabled tools into standards-aligned, high-quality instruction. When done right, this investment in human infrastructure ensures AI accelerates learning outcomes for all students, closing the “digital design divide.”
State legislatures and education agencies are pivotal actors who must address this issue through strategic policy levers. While individual districts manage much of the budget implementation and programmatic decisions, states set the conditions for local success by aligning funding streams and defining clear instructional visions.
Plan of Action
Recommendation 1. Define and Promote Aligned Visions of AI-Enabled Instruction
- Establish Definitions: Led by the state education agency and developed with broad input from stakeholders (e.g., educators, students, families, industry, research), publish and embed a statewide definition of high-quality, AI-enabled instruction in existing guidance and policy. For instance, states have leveraged frameworks like the ISTE Standards, CSTA Learning Priorities, and Universal Design for Learning guidelines to inform their definitions.
- Align Funding Streams: Require districts applying for PL funds, including the $2 billion Title II-A program under the Elementary and Secondary Education Act (ESEA), to describe how their proposed activities align with the state’s articulated vision.
- Provide Exemplars: Curate sample classroom artifacts and PL tools that reflect the vision.
Recommendation 2. Align Funding With Instructional Priorities
- Name Allowable Uses: Explicitly list AI and digital learning supports as allowable uses in guidance for various PL funding streams.
- Ensure Deliberate Procurement: Develop guidelines that encourage the procurement of safe, evidence-based, inclusive, usable, and interoperable tools, as well as risk and impact assessments for AI-powered edtech.
- Synchronize Cycles: Align grant cycles and reporting deadlines so districts can plan coherent, multi-year PL investments.
Recommendation 3. Leverage Compliance Structures for Continuous Improvement
- Shift Monitoring Metrics: Create systems that prompt districts to report not only educator attendance in PL efforts, but also shifts in practice and student impact, with a focus on non-punitive, streamlined data collection to minimize administrative burden.
- Collaborative Coaching: Use monitoring meetings as coaching sessions in addition to compliance audits, providing clear, actionable feedback to improve PL activities.
Recommendation 4. Encourage Durable Professional Learning Models
- Prioritize Sustainable Roles: Structure funding to prioritize ongoing coaching networks and dedicated AI readiness specialists over standalone training.
- Regional Infrastructure: Partner with regional education service centers to provide shared coaching staff across multiple districts.
- Elevate Educator Voice: Encourage PL programs establish formal mechanisms for teacher input in design, iteration, and evaluation to ensure practical relevance and quality.
Recommendation 5. Work Across Silos in State Leadership
- Cross-Departmental Collaboration: Establish regular touchpoints between key staff—specifically federal programs directors (e.g., ESEA Title program leads), curriculum leads, and edtech leaders—to align priorities and ensure funding streams work in concert.
- Joint Guidance and Pilots: Publish guidance that connects AI literacy directly to curriculum standards and assessment strategies. Launch pilot projects that combine resources from multiple departments, such as blending AI literacy PL with new project-based learning initiatives, and evaluate them together.
Recommendation 6. Document, Highlight, and Scale What Works
- State Repositories: Launch an online hub or in-person showcases where districts can share artifacts of model PL activities and road maps for implementing effective coaching initiatives.
- Responsible Innovation Amplification: Create awards or public recognition programs that spotlight measurable progress in AI-enabled instruction, helping to inspire others.
State education agencies specifically can adapt these recommendations based on their current capacity and context. For example:
- Low-Intensity
- Explicitly note across existing guidance documents (e.g., ESEA Title program funding guidance) that federal and state funds can support PL tied to AI-enabled instruction.
- Curate aligned PL examples to model high-quality investments into human infrastructure.
- Medium-Intensity
- Publish a statewide vision for AI-enabled instruction and responsible AI use, and integrate this vision into grantmaking processes.
- Convene alignment workshops and develop sample braided budgets that connect various streams of funding.
- Create and disseminate a high-quality PL model on AI fairness and use for optional adoption by districts, encouraging delivery through local or regional coaching networks for maximum relevance and sustainability
- High-Intensity
- Codify durable PL structures in policy, including by embedding roles like instructional technology coaches in state regulations or quality standards, prioritizing the development of internal educator capacity and clear teacher-to-coach career pathways.
- Institutionalize cross-departmental collaboration by establishing offices or leadership teams that coordinate curriculum, assessment, technology, and professional learning.
Conclusion
According to SETDA’s edtech trends survey, AI is currently the leading state edtech priority and top state initiative. However, with only a small group of states currently prioritizing existing funds for technology training, there is an immediate need to improve the systems governing professional learning. By investing in the “human infrastructure,” as exemplified by states like Wyoming and Massachusetts, state leaders can ensure that AI becomes a tool for accelerating outcomes for all students.
Who Governs Government AI? The Challenge of Federal Implementation
Public Trust and the Stakes of Federal AI Regulation
Americans are skeptical that their government can regulate artificial intelligence. A Pew Research Center study from October 2025 found that while large majorities in countries like India (89%), Indonesia (74%), and Israel (72%) trust their governments to regulate AI effectively, only 44% of Americans say the same, and a greater number, 47%, express distrust. Globally, more people trust the European Union (53%) to regulate AI than the United States (37%). Americans will only realize the benefits of AI if they have confidence that these systems are used safely, fairly, and in ways that improve their lives.
Trust is not a soft concern: it is the foundation for the adoption, legitimacy, and long-term success of any technology. When people doubt that AI systems are governed responsibly, they are less likely to accept their use in sensitive domains like healthcare, education, public benefits, or national security. Public skepticism can slow innovation, undermine compliance, and deepen polarization around emerging technologies. Encouragingly, this is not a partisan issue. Republicans and Democrats alike have emphasized that trustworthy AI use is a prerequisite for public adoption and lasting legitimacy. If the U.S. is going all-in on AI, then building and maintaining that trust is therefore not simply a communications challenge; it is a governance imperative.
The federal government plays a starring role in meeting that imperative—not only as a regulator, but also as a model user of AI. It deploys some of the most consequential and high-risk AI systems, including those that shape access to benefits, guide law enforcement priorities, manage immigration processes, and support national security decisions. The federal approach to deploying these systems does more than affect service delivery or cost savings; it sets expectations for industry standards, academic research, and public perception of the technology. In effect, the federal government serves as a societal-level proving ground for AI governance. Because it uses AI in high-risk contexts, it must demonstrate that these systems can be governed effectively through transparency, oversight, accountability, and meaningful safeguards. Failure to do so would not only diminish confidence in AI as an economic and societal asset, but weaken the already tenuous trust the public has in government as a manager of risk and opportunity
Two use cases illustrate this point. One existing high-potential but high-risk application is the Veteran’s Administration’s (VA) REACH VET program, which uses predictive models to identify veterans at elevated suicide risk so clinicians can proactively reach out. Because it draws on health records and includes explicit race coding, one would be concerned about opaque modeling choices and the possibility of inequitable or incorrect flags. The stakes are high. If veterans feel that an algorithm is driving interventions without clear transparency, clinical guardrails, and accountability or if it misses potential intervention needs, trust can erode, not only in REACH VET but in the VA’s broader use of AI, and its mental health screening and treatment programs.
Planned uses of AI in the current administration are also concerning. CMS’s planned Medicare WISeR Model would test whether “enhanced technologies,” including AI, can “expedite the prior authorization processes for select items and services that have been identified as particularly vulnerable to fraud, waste, and abuse, or inappropriate use.” In practice, this could result in automated systems delaying or denying coverage for medically necessary prescriptions or treatments if a model incorrectly flags them as suspicious. The trust risk is immediate: prior authorization already feels like a barrier to care, and adding AI without appropriate guardrails or adjudication can make delays or denials seem more automated, less explainable, and more complicated to challenge, especially for older or medically complex beneficiaries. If people perceive AI as prioritizing cost control over care, it will quickly undermine confidence in Medicare and in government AI more broadly.
These two use cases show how setting parameters around federal AI governance is not an abstract compliance exercise; it directly shapes whether people experience AI as a helpful tool or as an unaccountable gatekeeper in some of the most sensitive and consequential interactions they have with the government. Federal guidance on incorporating elements like risk assessments, inventory documentation, and recourse processes into agency deployment play an outsized role in fomenting trust in government use of AI.
Attempting to meet this challenge, both the Biden and Trump administrations have issued major federal guidance on how agencies should govern their use of AI. In 2024, the Biden administration’s Office of Management and Budget released OMB Memorandum M-24-10: Advancing Governance, Innovation, and Risk Management for Agency Use of Artificial Intelligence as part of their role in establishing how federal agencies operate and implement government-wide regulations. This memorandum set forth a government-wide framework for the responsible use of AI, including requirements for risk assessments, transparency, safeguards for high-impact systems, and clear waiver processes. However, we previously found that the growing body of AI-specific guidance, layered on top of existing procurement rules such as the Federal Acquisition Regulation (FAR), can be difficult for agencies and vendors to navigate, particularly when determining at what stage in the acquisition process risk and impact assessments should occur.
Last year, the Trump Administration’s OMB superseded OMB M-24-10 with new guidance: M-25-21: Accelerating Federal Use of AI through Innovation, Governance, and Public Trust. This memo includes elements similar to the Biden administration guidance but, because of its more flexible, agency-driven model, also makes consistent implementation more challenging. The shift toward greater agency discretion could be explained by the Administration’s emphasis on accelerating AI adoption and reducing centralized compliance requirements that could slow experimentation or deployment. Agencies now shoulder greater responsibility for building their own governance and compliance structures, a task that depends heavily on available resources and technical capacity. Well-funded agencies may be positioned to meet these expectations, while smaller or resource-constrained agencies, including those whose tools have the greatest impact on low-income or marginalized communities, may struggle to develop and implement the same safeguards. The result is a growing risk of fragmented governance across the federal landscape, with uneven protections for the people most affected by AI systems.
With this context in mind, it’s worth examining how each administration has approached the challenge of governing high-risk AI, and what these differences mean for agency accountability and public trust.
From “Rights- and Safety-Impacting” to “High-Impact”: A Change in Orientation
AI Risk Thresholds
OMB Guidance M-24-10, issued under the Biden administration, established a government-wide framework for identifying and managing artificial intelligence systems that pose elevated risks to rights or safety. The memo introduced two formal designations: “rights-impacting AI” and “safety-impacting AI.” Rights-impacting systems are those whose outputs serve as a principal basis for decisions or actions with legally significant effects on individuals’ civil rights, liberties, privacy, or equitable access to services such as housing, education, credit, or employment. Safety-impacting systems are those whose decisions or actions have the potential to significantly affect human life or well-being, the environment, critical infrastructure, or national and strategic assets.
Under the Trump administration, OMB M-25-21 replaced the dual “rights-impacting” and “safety-impacting” categories with a single unified definition of “high-impact AI.” This term covers any AI system whose “output serves as a principal basis for a decision or action that has legal, material, binding, or similarly significant effects on individuals or entities.” Examples still include systems affecting civil rights, access to government programs or resources, health and safety, critical infrastructure, or other vital assets. While the framework remains centered on AI systems that serve as a principal basis for consequential decisions, the new memo consolidates the prior rights- and safety-based categories into a single, more generalized standard.
This shift is not merely semantic. The way OMB defines high-risk or high-impact AI determines which federal agencies must apply heightened safeguards, conduct impact assessments, and implement specific oversight and accountability measures. It also signals to contractors, state and local governments, and private-sector partners the types of AI use that warrant the most stringent governance practices. As discussed below, consolidating the categories may affect the scope, clarity, and structure of minimum risk-mitigation requirements across agencies.
Minimum Risk Management Practices
Reaching a designated risk threshold, whether categorized as “rights- or safety-impacting” under the Biden administration or “high-impact” under the Trump Administration, does not bar an AI system from being used in government. Instead, both administrations require agencies to meet a set of minimum risk management practices before deploying such systems. These requirements, summarized in the table below, establish the baseline safeguards for high-risk AI use.
While there are consistent practices among both guidance documents, including AI impact assessments, ongoing monitoring and evaluation, and workforce training, there are a few elements noticeably absent from the Trump administration’s M-25-21. For example, the new guidance does not have opt-out considerations, has a looser procedure for remedies of high impact systems, and does not go into as much detail on what ongoing risk monitoring should look like. Independent review in the Biden administration formalized the inclusion of the Chief AI Officer (CAIO) or another agency advisory board, while the Trump administration has more flexibility in who can review high-impact use cases.
The Trump administration also differs in including a new element: pilot projects. These pilot AI programs are exempt from full risk-management requirements if they are limited in scale and duration, approved and centrally tracked by the agency’s Chief AI Officer, allow participants to opt in or out with proper notice when possible, and still apply risk-management practices wherever practicable.
Waivers
If, for whatever reason, agencies decide to not undergo the aforementioned minimum practices, both guidance documents offer waivers that give the agency’s CAIO authority to supersede a minimum risk practice. These waivers are centrally tracked and reported to OMB.
Whereas the Biden administration portrayed this as a procedural element, M-25-21 shifts the tone and purpose of these waivers. Under this system, an agency’s CAIO, in coordination with relevant officials, can grant a waiver from one or more of the minimum practices whenever strict compliance would impede mission-critical operations or increase overall risk. The memo explicitly allows waivers when compliance might “create an unacceptable impediment” to agency objectives, a broader, more permissive standard than under Biden.
By introducing a flexible pilot program model and more permissive and vague language risk management practices, the framework places substantial discretion in the hands of agencies and their CAIOs. In practice, agencies will exercise this discretion unevenly because they vary widely in governance maturity, technical capacity, and oversight infrastructure, an issue discussed in more detail below. These disparities are compounded by differences in how CAIO roles are structured across agencies: some CAIOs are career officials with dedicated staff and technical expertise, while others serve in an acting or dual-hatted capacity, combining AI oversight with unrelated portfolios and limited institutional support. The absence of uniform qualification requirements or minimum resource standards further increases the likelihood that implementation will diverge significantly across agencies.
Agency Snapshots: A Disjointed Compliance Landscape
Federal AI governance operates at two distinct levels: (1) centralized policy direction issued by OMB, and (2) agency-level compliance processes that operationalizes those policies. While policy sets uniform expectations, compliance is implemented through agency-specific procedures shaped by capacity, mission, and internal governance maturity. The interaction between these layers determines whether federal AI governance appears coherent or fragmented.
Under Trump’s OMB Memorandum M-25-21, every federal agency is required to publish both an AI Strategy and an AI Compliance Plan outlining how it will govern its high-impact AI systems and manage its waiver processes. The majority of these plans were published in September and October 2025. The following agencies provide a useful snapshot of how different parts of the government are approaching compliance with this guidance.
It is appropriate for agencies to develop risk evaluation approaches that reflect their distinct missions and deployment contexts. Sector-specific risks vary enormously: the harms posed by clinical decision-support tools differ from those associated with benefits administration, law enforcement, or worker-protection considerations. Agencies need the flexibility to evaluate risks within their own operational contexts.
However, differences in the content of sectoral risks and differences in the processes agencies use to manage those risks are not the same thing. Allowing agencies wide latitude in interpreting minimum risk management practices and in designing their waiver procedures creates the possibility of procedural divergence, not just divergence in substantive sector-specific requirements.This is where inconsistency becomes a governance problem, not just a technical one.
Agencies have long struggled to apply their own policies consistently across programs and time. A 2023 study of Biden-era AI governance practices found that fewer than 40 percent of mandated actions under key federal AI authorities were verifiably implemented, and that nearly half of federal agencies failed to publish required AI use-case inventories despite demonstrable use of machine-learning systems. Although the Trump administration may grant more discretion in agency AI governance, we see that the ability to consistently apply guidance is a structural issue that spans administrations. Without a baseline of procedural consistency, OMB may struggle in its mission to oversee these compliance plans.
The Importance of State Capacity
When each agency is left to design its own compliance architecture, implementation will also inevitably diverge according to capacity rather than mission need. This will produce a fragmented governance landscape that closely resembles the “patchwork” often cited as a concern in broader AI regulatory debates. Some agencies have already demonstrated the ability to produce relatively robust internal guidance because they possess deeper technical benches, established governance bodies, and more mature risk assessment processes. As shown in Table 2, for example, DHS has established centralized AI governance structures, published detailed AI inventories and use-case documentation, and built out internal review mechanisms to assess high-risk systems. Similarly, the DoL has developed agency-wide AI plans and formal oversight processes that integrate risk assessment, transparency, and workforce training components. But smaller, under-resourced agencies, such as the Court Services and Offender Supervision Agency (CSOSA) references in Table 1, may struggle even to stand up the foundational processes needed to comply with M-25-21.
At the core of this capacity gap is a workforce challenge. Effective AI governance depends not only on the right guidance but also on sufficient and well-deployed talent. This includes AI talent – staff with expertise in machine learning, data science, and model evaluation, and AI-enabling talent, which includes product managers, procurement specialists, privacy and civil liberties experts, domain specialists, and program managers who can integrate understanding of technical systems into real-world decisions and operations. AI governance bodies, risk assessment frameworks, and waiver adjudication processes cannot function without personnel who understand the technology and the agency’s mission context, and who can manage and adapt agency learning and implementation systems over time. A single brilliant CAIO is a smart first step, but long term effectiveness relies on the agency’s ability to enable a “flywheel” of adaptation, growing AI and AI enabling capacity over time.
The Biden administration had an AI Talent Surge with the explicit focus on bringing in AI and AI-enabling talent into the federal government, and was able to bring at least 200 experts into public service while advising agencies on structure and capacity-building. While M-25-21 prompts agencies to develop and retain AI and AI-enabling talent, it’s unclear how that matches up with the fact that 317,000 federal workers have left the government in 2025. Because many of the Biden-era AI hires were still within their probationary period, therefore vulnerable to layoffs, and because some entire digital teams, such as GSA’s 18F and the DHS’ own AI Corps, were slashed, it is now difficult to determine where federal AI talent resides or how much of that capacity remains in government.
Recent Trump administration moves have recognized some of this gap, but the emphasis on early-career vs. institutional adaptation is limiting. Late last year, the Office of Personnel Management issued a “Building the AI Workforce of the Future” guidance document, with emphasis on the launched TechForce (hiring early-career technologists for limited terms of two years), Project Management and Data Science Fellows programs, and other early-career oriented programs.
Conclusion
The divergence between M-24-10 and M-25-21, coupled with the uneven compliance plans that have followed, reveal a federal AI governance landscape marked by structural fragmentation, one that carries real implications for public trust. Agencies with robust technical resources are positioned to comply with these requirements if they choose to, while others will struggle to keep pace. Compounding this disparity, the dissolution of digital teams and loss of probationary AI hires have obscured the government’s understanding of its AI workforce, weakening its capacity to implement trusted and transparent governance.
Ultimately, M-25-21’s compliance plans will not fulfill their intended purpose unless agencies receive the funding, staffing, and political support required to carry them out. A compliance plan is only as strong as the people and resources behind it. Robust, transparent governance is impossible without investments in the civil service capacity needed to implement it, and without such trust-building capacity, agencies risk forgoing the responsible adoption of AI systems that could improve public services and operational effectiveness.
What exactly does “all lawful use” of AI mean? No one knows.
What exactly does “all lawful use” of AI mean? No one knows.
As a result of this weekend’s highly-publicized Department of Defense (DoD)-Anthropic dispute, we’re hearing a lot about the “lawful use” of frontier AI systems in classified environments.
“Lawful” is a legal floor that will look increasingly shaky as AI capabilities advance. It doesn’t answer whether we have adequate civil liberties guardrails or technical safety standards in place. Company “red lines” only matter if they are backed by enforceable technical and contractual safeguards. Otherwise, they function primarily as signaling. From use to testing to deployment, the scaffolding for responsible integration of AI into high-risk use cases is just not there.
Privacy is a major concern for experts and the public alike. When increasingly capable models are paired with large-scale government data holdings—including commercially purchased data on Americans—the result could materially change the practical boundaries of surveillance, even if each underlying dataset was obtained legally. AI systems expand the possibility of large-scale inference, enabling automated link analysis, behavioral pattern detection, and probabilistic assessments about individuals’ networks or intent across disparate datasets.
Next, there’s the reliability problem. Frontier systems remain probabilistic and brittle, particularly in adversarial settings. The companies building this technology do not yet have a mature testing, evaluation, validation, and verification (TEVV) ecosystem for high-stakes national security uses. At the same time, DoD strategy documents are calling for a “wartime” posture toward eliminating blockers in testing and deployment. That tension should concern us all.
Then, there are the numerous cybersecurity risks. Agentic systems that access sensitive data, ingest untrusted inputs, and can take external actions create new attack surfaces that adversaries will probe and exploit. In classified environments, these risks might be mitigated, but they don’t disappear. Subtle manipulation or model failure inside a military workflow can propagate quickly.
Capability is advancing quickly, but policymakers shouldn’t adopt faster than we can test and govern.
A National AI Laboratory to Support the Administration’s AI Agenda at the Department of Commerce
The United States faces intensifying international competition in Artificial Intelligence (AI). The Trump administration’s AI Action Plan places the Department of Commerce at the center of its agenda to strengthen international standards-setting, protect intellectual property, enforce export controls, and ensure the reliability of advanced AI systems. Yet no existing federal institution combines the flexibility, scale, and technical depth needed to fully support these functions.
To deliver on this agenda, Commerce should expand their AI capability by sponsoring a new Federally Funded Research and Development Center (FFRDC), the National AI Laboratory (NAIL). NAIL would:
- Advance the science of AI,
- Ensure that the United States leads in international AI standards and promotes the trusted adoption of U.S. AI products abroad,
- Identify and mitigate AI security risks,
- Protect U.S. technologies through effective export controls.
While the National Institute of Standards and Technology’s (NIST’s) Center for AI Standards and Innovation (CAISI) within Commerce provides a base of expertise to advance these goals, a dedicated FFRDC offers Commerce the scale, flexibility, and talent recruitment necessary to deliver on this broader commercial and strategic agenda. Together with complementary efforts to strengthen CAISI and expand public-private partnerships, NAIL would serve as the backbone of a more capable AI ecosystem within Commerce. By aligning with Commerce’s broader mission, NAIL will give the Administration a powerful tool to advance exports, protect American leadership, and counter foreign competition.
Challenge
AI’s breakneck pace is having a real-world impact. The Trump administration has made clear that widespread adoption of AI, backed by strong export promotion and international standards leadership, is essential for maintaining America’s position as the world’s technology leader. The Department of Commerce sits at the center of this agenda: advancing AI trade, developing international standards, advancing the science of AI, promoting exports, and ensuring effective export controls on critical technology.
Even as companies and countries race to adopt AI, the U.S. lacks the capacity to fully characterize the behavior and risks of AI systems and ensure leadership across the AI stack. This gap has direct consequences for Commerce’s core missions. First, advances in the science of AI are necessary to ensure that AI systems are sufficiently robust and well understood to be widely adopted at home and abroad. Second, without trusted methods for evaluating AI, the U.S. cannot credibly lead the development of international standards, an area where allies are seeking American leadership and where adversaries are pushing their own approaches. Third, this deep understanding of AI models is needed to identify and mitigate security concerns present in both foreign and domestic models. Fourth, deep technical expertise within the federal government is required to properly create and enforce export controls, ensuring that sensitive AI technologies and underlying hardware are not misused abroad. A deep bench of subject matter experts in AI models and infrastructure is increasingly critical to these efforts.
As AI systems become more capable, the lack of predictable and understandable behavior risks further eroding public trust in AI and inhibiting beneficial AI adoption. Jailbreaking attacks, in which carefully crafted prompts get around Large Language Model (LLM) guardrails, can produce unexpected behavior of models. For example, jailbreaking can prime LLMs for use in cyberattacks, which can cause significant economic harms, or cause them to leak personal information, or produce toxic content, causing legal liability and reputational harm to companies using these models. As companies deploy custom models built on top of LLMs they need to know that medical assistants will not produce harmful recommendations, or that agentic AI systems will not misspend personal funds. Addressing these concerns is an extremely challenging technical problem that requires more effective and consistent methods of evaluating and predicting model performance.
The ability to effectively characterize these models is central to the Trump administration’s AI Action Plan, which highlights widespread adoption of AI as a major policy priority, while also recognizing that the government has a key role to play in managing emerging national security threats. The AI Action Plan gives Commerce a central role in addressing these concerns; nearly two fifths of the plan’s recommendations involve Commerce. Commerce’s responsibilities include:
- Creating methods of AI model evaluation and developing international standards.
- Identifying security risks.
- Promoting research on AI interpretability, control and robustness.
- Recruiting leading AI researchers.
- Promoting exports of AI technology.
For a full list of AI Action Plan recommendations involving Commerce, see Appendix A.
While Commerce has an impressive track record in AI, including through its work at the National Institute of Standards and Technology and CAISI, it will face immense institutional challenges in delivering on the ambitions of the AI Action Plan, which require broad and deep expertise. Like other U.S. government entities, Commerce operates under federal hiring rules that make it difficult to quickly recruit and retain top technical talent. The government also struggles to match AI industry pay scales. For example, fresh PhDs joining AI companies frequently receive total compensation that is twice the cap set for the overwhelming majority of government workers, and senior researchers earn five times this cap or more. In some cases, top researchers may also hold equity in private companies, further complicating their employment by the government. Without a new institutional mechanism designed to attract and deploy world-class expertise, Commerce will struggle to execute on the ambitious goals of the AI Action Plan.
Opportunity
To deliver on the scope of the AI Action Plan, the Department of Commerce needs a dedicated institution with the resources, flexibility, and talent pipeline that existing structures cannot provide. A Federally Funded Research and Development Center (FFRDC) offers this capacity. Unlike traditional government offices, an FFRDC can recruit competitively from the same pools as industry, while remaining mission-driven and independent of commercial interests.
At its core, a new FFRDC, the National AI Laboratory (NAIL), would provide the technical expertise Commerce needs to carry out its central responsibilities. Specifically, NAIL would:
- Advance the science of AI, including the measurement and evaluation of AI models.
- Develop the methods and benchmarks that underpin international standards and ensure U.S. companies remain the trusted source for global AI solutions.
- Identify and mitigate AI security risks, ensuring U.S. technologies are not exploited by adversaries.
- Provide the technical expertise needed to support export promotion, export controls, and international trade negotiations.
NAIL would equip Commerce with the authoritative science and engineering base it needs to advance America’s commercial and strategic AI leadership.
FFRDCs are unique in combining the flexibility of private organizations with the mission focus of federal agencies. Their long-term partnership with a sponsoring agency ensures alignment with government priorities, while their independent status allows them to provide objective analysis and rapid technical response. This hybrid structure is particularly well-suited to the fast-moving and security-relevant domain of frontier AI. More background information on FFRDCs can be found in Appendix C.
The current talent landscape underscores the value of the FFRDC model. While industry salaries are high, many senior researchers are constrained by proprietary agendas and limited opportunities to pursue foundational, publishable work. To obtain greater freedom in their research, many top industry researchers have been seeking positions at universities, despite drastically lower salaries. An FFRDC focused on frontier model understanding, interpretability, and security offers a rare combination: freedom to pursue scientifically important problems, the ability to publish, and a mission anchored in national competitiveness and public service. This environment can attract researchers who would not join the civil service but are motivated by high-impact scientific and policy goals.
FFRDCs have repeatedly demonstrated their ability to deliver large-scale technical capability for federal sponsors. For example, NASA’s Jet Propulsion Laboratory has successfully built and landed multiple rovers on Mars, among many other achievements. The Departments of Energy and Defense have led much of the U.S.’ efforts in science and technology assisted by more than two dozen FFRDCs. Their track record shows that FFRDCs are uniquely suited to problems where neither academia nor industry is structured to meet federal needs—exactly the situation Commerce now faces in AI. Commerce currently supports one FFRDC, the fourth smallest. As advanced AI technology grows even more central to Commerce’s mission, it makes sense to add to this capacity.
Plan of Action
Recommendation 1. Establish an FFRDC to support the AI Mission at Commerce.
Commerce should establish a new FFRDC within two years with a mission to begin important research and timely evaluations. Establishing a new FFRDC requires the sponsoring organization (Commerce in this case) to satisfy the criteria laid out in the Federal Acquisition Regulations (48 CFR 35.017-2) for creating a new FFRDC. Key requirements involve demonstrating needs that are not met by existing sources and that Commerce has sufficient expertise to evaluate the FFRDC. It will require consistent government support through appropriations, and Commerce must identify an appropriate organization to manage it. The rapid pace of AI development makes it an urgent priority to move forward as soon as possible. Recent FFRDCs have taken about 18 months to establish after initial announcement, a significant length of time in the AI field. Further details related to establishing an FFRDC can be found in Appendix D.
Recommendation 2. NAIL should focus on topics that will advance the Administration’s AI Agenda, including recommendations given to Commerce in the AI Action Plan.
These topics should include:
- Development of a standardized federal science of measurement that enables evaluation and comparison of models. These evaluations should be predictive of their performance on real-world tasks. NIST has already laid out how measurement science can advance AI innovation in this report.
- Use of these advances in the science of AI measurement for the development of unified AI standards. This would build greater confidence in models, promoting adoption and U.S. AI exports.
- Development of comprehensive methods to assess security implications of models. This includes security concerns in foreign models and vulnerabilities, such as jailbreaks, backdoors, and leakage of sensitive data, and their susceptibility to data poisoning attacks. Of particular note are attacks that can obtain dangerous information related to topics such as biological weapons. While much of this work can be done without access to classified information, NAIL workers may need security clearances, for example, to determine whether models could leak specific secure data. NAIL should also promote AI security by advancing technical work on AI interpretability, robustness, and control, which was highlighted as a priority in the AI Action Plan.
- Determination of whether AI models or hardware provide capabilities that might warrant export controls.
The proposed FFRDC should pursue activities that range from longer term, fundamental research to rapid response to new developments. Much of the knowledge needed to fulfill Commerce’s mandate lies at the heart of the most significant research questions in AI. This requires deep research, which is also important in attracting top tier talent. On a shorter time scale, it will be important for the FFRDC to provide regular evaluations of models as they progress, including the evaluation of security concerns in foreign models. NAIL can speed up these time critical security evaluations. It will also need to use these evaluations to help create and update procurement guidelines for federal agencies and assess the state of international AI competition. Finally, the FFRDC should be a source of expertise that can support Commerce in a wide range of topics such as export control and development of a workforce trained to appropriately take advantage of AI tools.
The FFRDC will also need to work closely with industry to develop standards for the evaluation of models, and support efforts to create international standards. For example, it may seek to facilitate an industry consensus on the evaluation of new models for security concerns. NIST is well known for similar efforts in many technical areas. Finally, the FFRDC should provide a capacity for rapid response to significant AI developments, including possible urgent security concerns.
Recommendation 3. Provide a sufficient budget to cover the necessary scale of work.
There are different possible scales at which NAIL might be created. It is important to note that creating industry scale models from scratch can cost tens or hundreds of millions of dollars. However, the task of evaluating models may be undertaken without this expense by experimenting on models that have already been trained. Much of the published work on model evaluation takes this course. Such evaluations and experiments still require access to significant computational resources, requiring millions of dollars a year in compute, depending on the size of the effort. The FFRDC’s research might also include experiments in which smaller models are built from scratch at a much smaller expense than what is required to train industry sized models.
We consider two alternatives as to the size and budget of the proposed FFRDC:
- Testbed for AI Competitiveness and Knowledge (TACK): A smaller, prototype effort involving dozens of researchers and support staff, including staff that will facilitate collaborations with industry and other agencies. Such a small-scale effort will not be able to address the full range of problems that Commerce has been tasked with, but will be able to contribute to important missions and demonstrate the value of such an FFRDC on an accelerated timeline. This might cost a few tens of millions of dollars per year, on the scale of Commerce’s current National Cybersecurity FFRDC (NCF).
- Full NAIL: A larger-scale effort could address the full range of tasks outlined above. At this scale, the FFRDC could also take the lead in shaping international standards. For comparison, the Software Engineering Institute (SEI) operates as an FFRDC with a staff of roughly 700 and an annual budget of about $130 million.
The figure in Appendix B lists all current FFRDCs and their annual budget in 2023.
The budget of the FFRDC would need to cover several different costs:
- Research staff. This would consist of experienced researchers who would lead fundamental research and oversee shorter term technical work.
- Research support staff. This would include experienced developers, many with experience in data collection and cleaning, model training and evaluation.
- Administrative support.
- Policy experts skilled in interfacing with industry and other government agencies.
- Computer staff, with experience in supporting large scale computing resources.
- Computing resources, including funds to purchase GPU clusters or to obtain them through cloud services.
- Other expenses such as travel, office space, and miscellaneous overhead.
Recommendation 4. Make NAIL the Backbone of a Broader AI Ecosystem at Commerce.
While an FFRDC offers a unique combination of technical depth and recruiting flexibility, other institutional approaches could also expand Commerce’s AI expertise. One option is to expand the Center for AI Standards and Innovation (CAISI) within NIST, leveraging its standards and measurement mission, though it remains bound by federal hiring and funding rules that slow recruitment and limit pay competitiveness.
A separate proposal envisions a NIST Foundation—a congressionally authorized nonprofit akin to the CDC Foundation or the newly created Foundation for Energy Security and Innovation (FESI)—to mobilize philanthropic and private funding, convene stakeholders, and run fellowships supporting NIST’s mission. Such a foundation could strengthen public-private engagement but would not provide the sustained, large-scale technical capacity needed for Commerce’s AI responsibilities.
Taken together, these models could form a complementary ecosystem: an expanded CAISI to coordinate standards and technical policy within government as well as providing oversight over the FFRDC; a NIST Foundation to channel flexible funding and external partnerships; and an FFRDC to serve as the enduring research and engineering backbone capable of executing large-scale technical work.
Conclusion
The Trump administration has set ambitious goals for advancing U.S. leadership in artificial intelligence, with the Department of Commerce at the center of this effort. Ensuring America’s continued leadership in AI requires technical expertise that existing institutions cannot provide at scale.
NAIL, a new Federally Funded Research and Development Center (FFRDC) offers Commerce the capacity to:
- Push forward our fundamental understanding of frontier AI models along axes that are central to Commerce’s mission, including measurement and evaluation.
- Build the trusted benchmarks and standards that can become the global default.
- Rapidly respond to new technical and security challenges, ensuring the U.S. stays ahead of competitors.
- Provide authoritative analysis for export promotion and control, ensuring U.S. technologies are widely adopted abroad while protected from adversaries, and strengthening America’s hand in international negotiations and trade forums.
By sponsoring this FFRDC, Commerce can secure the talent, flexibility, and independence needed to deliver on the Administration’s commercial AI agenda. While CAISI provides the technical anchor within NIST, the FFRDC will enable Commerce to act at the necessary scale—ensuring the U.S. leads the world in AI innovation, standards, and exports.
Appendix A. References to the Department of Commerce in America’s AI Action Plan
Appendix B. FFRDC Budgets
Appendix C. Further Background on FFRDCs
FFRDCs in Practice: Successes and Pitfalls
FFRDCs have been supporting US government institutions since World War II. Overviews can be found here and here. In this appendix we briefly describe the functioning of FFRDCs and lessons that can be drawn for the current proposal.
In a paper by the Institute for Defense Analyses (IDA) a panel of experts “expressed their belief that high-quality technical expertise and a trusting relationship between laboratory leaders and their sponsor agencies were important to the success of FFRDC laboratories” and felt that “The most effective customers and sponsors set only ‘the what’ (research objectives to be met) and allow the laboratories to determine ‘the how’ (specific research projects and procedures).” Frequent personnel exchange programs between the FFRDC and its sponsor are also suggested.
This and the experience of successful FFRDCs suggests that the proposed FFRDC be closely linked to relevant ongoing efforts in NIST, especially CAISI, with frequent exchanges of information and even personnel. At the same time, the proposed FFRDC should have the freedom to explore very challenging research questions that lie at the heart of its mission.
As an example of the relationship between agencies and associated FFRDCs, the Jet Propulsion Laboratory supports many of NASA’s priorities, addressing long-term goals such as understanding how life emerged on earth, along with more immediate goals such as catalyzing economic growth and contributing to national security. Caltech manages operations of JPL. In general, NASA sets strategic goals, and JPL aligns its long-term quests with these goals. NASA may solicit proposals and JPL may compete to lead or participate in appropriate missions. JPL may also propose missions to NASA. As an example, in 2011 the National Academies recommended that NASA begin a mission to return samples from Mars. NASA decided to launch a new Mars rover mission. NASA then tasked JPL to build and manage operations of Perseverance, to accomplish this mission.
On a less positive note, after concerns about the Department of Energy’s (DOE) management of FFRDCs, DOE shifted from a “transactional model to a systems-based approach” offering greater oversight, but also leading to concerns of loss of flexibility and micromanagement. Concerns have also previously been raised about the level of transparency and assessment of alternatives when agencies renew FFRDC contracts, as well as mission creep of existing FFRDCs
Existing FFRDCs Relevant to AI Work
One of the most important criteria for establishing a new FFRDC is to demonstrate that this will fill a need that cannot be filled by existing entities. Many current FFRDCs are conducting work on AI, but this work does not adequately address the needs of Commerce, especially in light of the requirements of the AI Action Plan. For example, the Software Engineering Institute (SEI) run by CMU has deep expertise in the development of AI systems, along with software development and acquisition. However, their mission is to “execute applied research to drive systemic transition of new capabilities for the DoD.” Its AI work focuses on defense related capabilities, and not on the comprehensive evaluation of frontier models needed by NIST.
NIST does support the National Cybersecurity FFRDC (NCF) operated by MITRE. This unit focuses on security needs, not on general model evaluation (although it will be important to clearly delineate the scopes of a new Commerce FFRDC and the NCF). Other FFRDCs, such as Los Alamos or Lawrence Berkeley have significant AI efforts aimed at using AI to enhance scientific discovery. Industry AI labs address some of the questions central to the proposed FFRDC, but it is important that the government have access to deep technical expertise that is able to act in the public interest.
Establishing a New FFRDC
A precedent on the establishment of FFRDCs comes from the Department of Homeland Security (DHS). Under Section 305 of the Homeland Security Act of 2002, DHS was authorized to establish one or more FFRDCs to provide independent technical analysis and systems engineering for critical homeland security missions. In April 2004, DHS created its first FFRDC, the Homeland Security Institute. Four years later, on April 3, 2008, it issued a notice of intent to establish a successor organization, the Homeland Security Systems Engineering and Development Institute (HSSEDI), and in 2009 selected the MITRE Corporation to operate it. HSSEDI—along with DHS’s other FFRDC, the Homeland Security Operational Analysis Center—is overseen by the Department’s FFRDC Program Management Office. This case illustrates both a procedural pathway (statutory authorization, public notice, operator selection) and the typical timeline for standing up such an entity: roughly 12–18 months from notice of intent to full operation. Similarly, the National Cybersecurity FFRDC had its first notice of intent filed April 22, 2013, with the final contract to operate the FFRDC awarded to MITRE on September 24, 2014, about 17 months later.
Appendix D. Requirements for Establishing an FFRDC
Establishing a new FFRDC requires the sponsoring organization (Commerce in this case) to satisfy the criteria laid out in the Federal Acquisition Regulations (48 CFR 35.017-2) for creating a new FFRDC.
These include:
- Requirement: Existing alternative sources for satisfying agency requirements cannot effectively meet the special research or development needs.
- Meeting the Requirement: The special research or development need for improved understanding, measurement and reliability of AI models is clearly highlighted by the Trump Administration’s AI Action plan, and will only increase with more capable AI systems. As detailed in Appendix C, existing FFRDCs do not focus on problems central to Commerce’s mission, including the promotion of AI exports through model understanding and evaluation, model measurement to promote international standards, and identifying security issues central to export controls. Some work on this is done in industry and universities, but as noted, this is not comprehensive or sufficient to address Commerce’s mandate and the goals of the AI Action Plan.
- Requirement: There is sufficient Government expertise available to adequately and objectively evaluate the work to be performed by the FFRDC.
- Meeting the Requirement: CAISI would serve as a source of expertise within the government that can evaluate the work performed by the FFRDC.
- Requirement: A reasonable continuity in the level of support to the FFRDC is maintained, consistent with the agency’s need for the FFRDC and the terms of the sponsoring agreement.
- Meeting the Requirement: Satisfying this requirement may require ongoing support from Congressional appropriations committees, depending on the level of support needed.
- Requirement: The FFRDC is operated, managed, or administered by an autonomous organization or as an identifiably separate operating unit of a parent organization, and is required to operate in the public interest, free from organizational conflict of interest, and to disclose its affairs (as an FFRDC) to the primary sponsor.
- Meeting the Requirement: The DOC and NIST must identify the appropriate contractor to run the FFRDC. There are many non-profits and universities with relevant expertise, including non-profits devoted to AI measurement.
The establishment of an FFRDC must follow the notification process laid out in 48 CFR 5.205(b). The sponsoring agency must transmit at least three notices over a 90-day period to the GPE (Governmentwide point of entry) and the Federal Register, indicating the agency’s intention to sponsor an FFRDC, and its scope and nature, requesting comments. This plan must be reviewed by the Office of Federal Procurement Policy (OFPP) within the White House Office of Management and Budget (OMB).
A sponsoring agreement (described in 48 CFR 35.017-1) must be generated by Commerce for the new FFRDC. This agreement is required by regulations (48 CFR 35.017-1(e)) to last for no more than five years, but may be renewed. It outlines conditions for awarding contracts and methods of ensuring independence and integrity of the FFRDC. FFRDCs initiate work at the request of federal entities, which would then be approved by appropriate units within DOC. The proposed FFRDC should align its mission closely with Commerce and NIST, obtaining contracts from these sponsoring agencies that will determine its priorities. The FFRDC would hire top tier researchers who can both execute this research and provide bottom-up identification of important new research topics.
On the Precipice: Artificial Intelligence and the Climb to Modernize Nuclear Command, Control, and Communications
The United States’ nuclear command, control, and communications (NC3) system remains a foundational pillar of national security, ensuring credible nuclear deterrence under the most extreme conditions. Yet as the United States embarks on long-overdue NC3 modernization, this effort has received less scholarly and policy attention than the modernization of nuclear delivery systems. This paper addresses that gap by providing a critical assessment of the U.S. NC3 enterprise and its evolving role in a rapidly transforming strategic environment.
Geopolitically, U.S. NC3 modernization must now contend with issues including China’s rise as a nuclear near peer, Russia’s deployment of increasingly threatening hypersonic and counterspace capabilities, and the erosion of norms restraining limited nuclear use.
Technologically, the shift from legacy analog to digital architectures introduces both great opportunities for enhanced speed and resilience and unprecedented vulnerabilities across cyber, space, and electronic domains.
Bureaucratically, modernization efforts face challenges from fragmented acquisition responsibilities and the need to align with broader initiatives such as Combined Joint All-Domain Command and Control (CJADC2) and the deployment of hybrid space architectures.
This paper argues that successful NC3 modernization must do more than update hardware and software: it must integrate emerging technologies, particularly artificial intelligence (AI), in ways that enhance resilience, ensure meaningful human control, and preserve strategic stability. The study evaluates the key systems, organizational challenges, and operational dynamics shaping U.S. NC3 and offers policy recommendations to strengthen deterrence credibility in an era of accelerating geopolitical and technological change.
Read the complete publication here.
This publication was made possible by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.
AI Implementation is Essential Education Infrastructure
State education agencies (SEAs) are poised to deploy federal funding for artificial intelligence tools in K–12 schools. Yet, the nation risks repeating familiar implementation failures that have limited educational technology for more than a decade. The July 2025 Dear Colleague Letter from the U.S. Department of Education (ED) establishes a clear foundation for responsible artificial intelligence (AI) use, and the next step is ensuring these investments translate into measurable learning gains. The challenge is not defining innovation—it is implementing it effectively. To strengthen federal–state alignment, upcoming AI initiatives should include three practical measures: readiness assessments before fund distribution, outcomes-based contracting tied to student progress, and tiered implementation support reflecting district capacity. Embedding these standards within federal guidance—while allowing states bounded flexibility to adapt—will protect taxpayer investments, support educator success, and ensure AI tools deliver meaningful, scalable impact for all students.
Challenge and Opportunity
For more than a decade, education technology investments have failed to deliver meaningful results—not because of technological limitations, but because of poor implementation. Despite billions of dollars in federal and local spending on devices, software, and networks, student outcomes have shown only minimal improvement. In 2020 alone, K–12 districts spent over $35 billion on hardware, software, curriculum resources, and connectivity—a 25 percent increase from 2019, driven largely by pandemic-related remote learning needs. While these emergency investments were critical to maintaining access, they also set the stage for continued growth in educational technology spending in subsequent years.
Districts that invest in professional development, technical assistance, and thoughtful integration planning consistently see stronger results, while those that approach technology as a one-time purchase do not. As the University of Washington notes, “strategic implementation can often be the difference between programs that fail and programs that create sustainable change.” Yet despite billions spent on educational technology over the past decade, student outcomes have remained largely unchanged—a reflection of systems investing in tools without building the capacity to understand their value, integrate them effectively, and use them to enhance learning. The result is telling: an estimated 65 percent of education software licenses go unused, and as Sarah Johnson pointed out in an EdWeek article, “edtech products are used by 5% of students at the dosage required to get an impact”.
Evaluation practices compound the problem. Too often, federal agencies measure adoption rates instead of student learning, leaving educators confused and taxpayers with little evidence of impact. As the CEO of the EdTech Evidence Exchange put it, poorly implemented programs “waste teacher time and energy and rob students of learning opportunities.” By tracking usage without outcomes, we perpetuate cycles of ineffective adoption, where the same mistakes resurface with each new wave of innovation.
Implementation Capacity is Foundational
A clear solution entails making implementation capacity the foundation of federal AI education funding initiatives. Other countries show the power of this approach. Singapore, Estonia, and Finland all require systematic teacher preparation, infrastructure equity, and outcome tracking before deploying new technologies, recognizing, as a Swedish edtech implementation study found, that access is necessary but not sufficient to achieve sustained use. These nations treat implementation preparation as essential infrastructure, not an optional add-on, and as a result, they achieve far better outcomes than market-driven, fragmented adoption models.
The United States can do the same. With only half of states currently offering AI literacy guidance, federal leadership can set guardrails while leaving states free to tailor solutions locally. Implementation-first policies would allow federal agencies to automate much of program evaluation by linking implementation data with existing student outcome measures, reducing administration burden and ensuring taxpayer investments translate into sustained learning improvements.
The benefits would be transformational:
- Educational opportunity. Strong implementation support can help close digital skill gaps and reduce achievement disparities. Rural districts could gain greater access to technical assistance networks, students with disabilities could benefit from AI tools designed with accessibility at their core, and all students could build the AI literacy necessary to participate in civic and economic life. Recent research suggests that strategic implementation of AI in education holds particular promise for underserved and geographically isolated communities.
- Workforce development. Educators could be equipped to use AI responsibly, expanding coherent career pathways that connect classroom expertise to emerging roles in technology coaching, implementation strategy, and AI education leadership. Students graduating from systematically implemented AI programs would enter the workforce ready for AI-driven jobs, reducing skills gaps and strengthening U.S. competitiveness against global rivals.
In short, implementation is not a secondary concern; it is the primary determinant of whether AI in education strengthens learning or repeats the costly failures of past ed-tech investments. Embedding implementation capacity reviews before large-scale rollout—focused on educator preparation, infrastructure adequacy, and support systems—would help districts identify strengths and gaps early. Paired with outcomes-based vendor contracts and tiered implementation support that reflects district capacity, this approach would protect taxpayer dollars while positioning the United States as a global leader in responsible AI integration.
Plan of Action
AI education funding must shift to being both tool-focused and outcome-focused, reducing repeated implementation failures and ensuring that states and districts can successfully integrate AI tools in ways that strengthen teaching and learning. Federal guidance has made progress in identifying priority use cases for AI in education. With stronger alignment to state and local implementation capacity, investments can mitigate cycles of underutilized tools and wasted resources.
A hybrid approach is needed: federal agencies set clear expectations and provide resources for implementation, while states adapt and execute strategies tailored to local contexts. This model allows for consistency and accountability at the national level, while respecting state leadership.
Recommendation 1. Establish AI Education Implementation Standards Through Federal–State Partnership
To safeguard public investments and accelerate effective adoption, the Department of Education, working in partnership with state education agencies, should establish clear implementation standards that ensure readiness, capacity, and measurable outcomes.
- Implementation readiness benchmarks. Federal AI education funds should be distributed with expectations that recipients demonstrate the enabling systems necessary for effective implementation—including educator preparation, technical infrastructure, professional learning networks, and data governance protocols. ED should provide model benchmarks while allowing states to tailor them to local contexts.
- Dedicated implementation support. Funding streams should ensure AI education investments include not only tool procurement but also consistent, evidence-based professional development, technical assistance, and integration planning. Because these elements are often vendor-driven and uneven across states, embedding them in policy guidance helps SEAs and local education agencies (LEAs) build sustainable capacity and protect against ineffective or commodified approaches—ensuring schools have the human and organizational capacity to use AI responsibly and effectively.
- Joint oversight and accountability. ED and SEAs should collaborate to monitor and publicly share progress on AI education implementation and student outcomes. Metrics could be tied to observable indicators, such as completion of AI-focused professional development, integration of AI tools into instruction, and adherence to ethical and data governance standards. Transparent reporting builds public trust, highlights effective practices, and supports continuous improvement, while recognizing that measures of quality will evolve with new research and local contexts.
Recommendation 2. Develop a National AI Education Implementation Infrastructure
The U.S. Department of Education, in coordination with state agencies, should encourage a national infrastructure that helps and empowers states to build capacity, share promising practices, and align with national economic priorities.
- Regional implementation hubs. ED should partner with states to create regional AI education implementation centers that provide technical assistance, professional development, and peer learning networks. States would have flexibility to shape programming to their context while benefiting from shared expertise and federal support.
- Research and evaluation. ED, in coordination with the National Science Foundation (NSF), should conduct systematic research on AI education implementation effectiveness and share annual findings with states to inform evidence-based decision-making.
- Workforce alignment. Federal and state education agencies should continue to coordinate AI education implementation with existing workforce development initiatives (Department of Labor) and economic development programs (Department of Commerce) to ensure AI skills align with long-term economic and innovation priorities.
Recommendation 3. Adopt Outcomes Based Contracting Standards for AI Education Procurement
The U.S. Department of Education should establish outcomes based contracting (OBC) as a preferred procurement model for federally supported AI education initiatives. This approach ties vendor payment directly to demonstrated student success, with at least 40% of contract value contingent on achieving agreed-upon outcomes, ensuring federal investments deliver measurable results rather than unused tools.
- Performance-based payment structures. ED should support contracts that include a base payment for implementation support and contingent payments earned only as students achieve defined outcomes. Payment should be based on individual student achievement rather than aggregate measures, ensuring every learner benefits while protecting districts from paying full price for ineffective tools.
- Clear outcomes and mutual accountability:. Federal guidance should encourage contracts that specify student populations served, measurable success metrics tied to achievement and growth, and minimum service requirements for both districts and vendors (including educator professional learning, implementation support, and data sharing protocols).
- Vendor transparency and reporting. AI education vendors participating in federally supported programs should provide real-time implementation data, document effectiveness across participating sites, and report outcomes disaggregated by student subgroups to identify and address equity gaps.
- Continuous improvement over termination. Rather than automatic contract cancellation when challenges arise, ED should establish systems that prioritize joint problem-solving, technical assistance, and data-driven adjustments before considering more severe measures.
Recommendation 4. Pilot Before Scaling
To ensure responsible, scalable, and effective integration of AI in education, ED and SEAs should prioritize pilot testing before statewide adoption while building enabling conditions for long-term success.
- Pilot-to-scale strategy. Federal and state agencies could jointly identify pilot districts representing diverse contexts (rural, urban, and suburban) to test AI implementation models before large-scale rollout. Lessons learned would inform future funding decisions, minimize risk, and increase effectiveness for states and districts.
- Enabling conditions for sustainability. States could build ongoing professional learning systems, technical support networks, and student data protections to ensure tools are used effectively over time.
- Continuous improvement loop. ED could coordinate with states to develop feedback systems that translate implementation data into actionable improvements for policy, procurement, and instruction, ensuring educators, leaders, and students all benefit.
Recommendation 5. Build a National AI Education Research & Development Network
To promote evidence-based practice, federal and state agencies should co-develop a coordinated research and development infrastructure that connects implementation data, policy learning to practice, and global collaboration.
- Implementation research partnerships. Federal agencies (ED, NSF) should partner with states and research institutions to fund systematic studies on effective AI education implementation, with emphasis on scalability and outcomes across diverse student populations. Rather than creating a new standalone program, this would coordinate existing ED and NSF investments while expanding state-level participation.
- Testbed site networks. States should designate urban, suburban, and rural AI education implementation labs or “sandboxes”, modeled on responsible AI testbed infrastructure, where funding supports rigorous evaluation, cross-district peer learning, and local adaptation.
- Evidence-to-policy pipeline. Federal agencies should integrate findings from these research-practice partnerships into national AI education guidance, while states embed lessons learned into local technical assistance and professional development.
- National leadership and evidence sharing. Federal and state agencies should establish mechanisms to share evidence-based approaches and emerging insights, positioning the U.S. as a leader in responsible AI education implementation. This collaboration should leverage continuous, practice-informed research, called living evidence, which integrates real-world implementation data, including responsibly shared vendor-generated insights, to inform policy, guide best practices, and support scalable improvements.
Conclusion
The Department’s guidance on AI in education marks a pivotal step toward modernizing teaching and learning nationwide. To realize the promise of AI in education, funding should support both the acquisition of tools and the strategies that ensure their effective implementation. To realize its promise, we must shift from funding tools to funding effective implementation. Too often, technologies are purchased only to sit on the shelf while educators lack the support to integrate them meaningfully. International evidence shows that countries investing in teacher preparation and infrastructure before technology deployment achieve better outcomes and sustain them.
Early research also suggests that investments in professional development, infrastructure, and systems integration substantially increase the long-term impact of educational technology. Prioritizing these supports reduces waste and ensures federal dollars deliver measurable learning gains rather than unused tools. The choice before us is clear: continue the costly cycle of underused technologies or build the nation’s first sustainable model for AI in education—one that makes every dollar count, empowers educators, and delivers transformational improvements in student outcomes.
Clear implementation expectations don’t slow innovation—they make it sustainable. When systems know what effective implementation looks like, they can scale faster, reduce trial-and-error costs, and focus resources on what works to ultimately improve student outcomes.
Quite the opposite. Implementation support is designed to build capacity where it’s needed most. Embedding training, planning, and technical assistance ensures every district, regardless of size or resources, can participate in innovation on an equal footing.
AI education begins with people, not products. Implementation guidelines should help educators improve their existing skills to incorporate AI tools into instruction, offer access to relevant professional learning, and receive leadership support, so that AI enhances teaching and learning.
Implementation quality is multi-dimensional and may look different depending on local context. Common indicators could include: educator readiness and training, technical infrastructure, use of professional learning networks, integration of AI tools into instruction, and adherence to data governance protocols. While these metrics provide guidance, they are not exhaustive, and ED and SEAs will iteratively refine measures as research and best practices evolve. Transparent reporting on these indicators will help identify effective approaches, support continuous improvement, and build public trust.
Not when you look at the return. Billions are spent on tools that go underused or abandoned within a year. Investing in implementation is how we protect those investments and get measurable results for students.
The goal isn’t to add red tape—it’s to create alignment. States can tailor standards to local priorities while still ensuring transparency and accountability. Early adopters can model success, helping others learn and adapt.
Federation of American Scientists and 16 Tech Organizations Call on OMB and OSTP to Maintain Agency AI Use Case Inventories
The first Trump Administration’s E.O. 13859 commitment laid the foundation for increasing government accountability in AI use; this should continue
Washington, D.C. – March 6, 2025 – The Federation of American Scientists (FAS), a non-partisan, nonprofit science think tank dedicated to developing evidence-based policies to address national challenges, today released a letter to the White House Office of Management and Budget (OMB) and the Office of Science and Technology Policy (OSTP), signed by 16 additional scientific and technical organizations, urging the current Trump administration to maintain the federal agency AI use cases inventories at the current level of detail.
“The federal government has immense power to shape industry standards, academic research, and public perception of artificial intelligence,” says Daniel Correa, CEO of the Federation of American Scientists. “By continuing the work set forth by the first Trump administration in Executive Order 13960 and continued by the bipartisan 2023 Advancing American AI Act, OMB’s detailed use cases help us understand the depth and scope of AI systems used for government services.”
“FAS and our fellow organizations urge the administration to maintain these use case standards because these inventories provide a critical check on government AI use,” says Dr. Jedidah Isler, Chief Science Officer at FAS.
AI Guidance Update Mid-March
“Transparency is essential for public trust, which in turn is critical to maximizing the benefits of government AI use. That’s why FAS is leading a letter urging the administration to uphold the current level of agency AI use case detail—ensuring transparency remains a top priority,” says Oliver Stephenson, Associate Director of AI and Emerging Tech Policy at FAS.
“Americans want reassurances that the development and use of artificial intelligence within the federal government is safe; and that we have the ability to mitigate any adverse impacts. By maintaining guidance that federal agencies have to collect and publish information on risks, development status, oversight, data use and so many other elements, OMB will continue strengthening Americans’ trust in the development and use of artificial intelligence,” says Clara Langevin, AI Policy Specialist at FAS.
Surging Use of AI in Government
This letter follows the dramatic rise in the use of artificial intelligence across government, with anticipated growth coming at a rapid rate. For example, at the end of 2024 the Department of Homeland Security (DHS) alone reported 158 active AI use cases. Of these, 29 were identified as high-risk, with detailed documentation on how 24 of those use cases are mitigating potential risks. OMB and OSTP have the ability and authority to set the guidelines that can address the growing pace of government innovation.
FAS and our signers believe that sustained transparency is crucial to ensuring responsible AI governance, fostering public trust, and enabling responsible industry innovation.
Signatories Urging AI Use Case Inventories at Current Level of Detail
Federation of American Scientists
Beeck Center for Social Impact + Innovation at Georgetown University
Bonner Enterprises, LLC
Center for AI and Digital Policy
Center for Democracy & Technology
Center for Inclusive Change
CUNY Public Interest Tech Lab
Electronic Frontier Foundation
Environmental Policy Innovation Center
Mozilla
National Fair Housing Alliance
NETWORK Lobby for Catholic Social Justice
New America’s Open Technology Institute
POPVOX Foundation
Public Citizen
SeedAI
The Governance Lab
###
ABOUT FAS
The Federation of American Scientists (FAS) works to advance progress on a broad suite of contemporary issues where science, technology, and innovation policy can deliver dramatic progress, and seeks to ensure that scientific and technical expertise have a seat at the policymaking table. Established in 1945 by scientists in response to the atomic bomb, FAS continues to work on behalf of a safer, more equitable, and more peaceful world. More information about FAS work at fas.org.
ABOUT THIS COALITION
Organizations signed on to this letter represent a range of technology stakeholders in industry, academia, and nonprofit realms. We share a commitment to AI transparency. We urge the current administration, OMB, and OSTP to retain the policies set forth in Trump’s Executive Order 13960 and continued in the bipartisan 2023 Advancing American AI Act.