
Strengthening the Federal Cycle of Learning and Adaptation by Closing the Loops
The federal government has a feedback-loop problem.
Regularly generated information, including evidence, performance information, and qualitative insights from implementation, too often fails to shape decisions. Evidence may be reviewed without changing priorities; performance data may be tracked without clarifying what it informs, and implementation feedback may reach leadership without surfacing what works for whom and why, or suggesting next steps. The components of a cyclical learning system linking priorities, questions, evidence, decisions, and implementation information exist in theory and on paper, but the connective tissue that turns all of these components into a functioning cycle of learning and adjustment is lacking. Information and artifacts alone don’t necessarily facilitate learning and adaptation; strengthening federal feedback loops requires embedding translation and use into decision-making from the start.
This memo is not a case for new infrastructure. The Evidence Act, learning agendas, evaluation plans, performance frameworks, and customer experience authorities already exist; what they do not yet add up to is a learning system. The translation this memo proposes is turning the infrastructure we have into the learning system we need, and it’s addressed to federal program leaders, policy officials, evaluation and evidence staff, performance officers, and strategic planning teams who already sit inside it and are best positioned to make it function as intended.
Challenge and Opportunity
The federal government already operates within a broad cycle of goal-setting, evidence generation, performance review, implementation, and reporting. On paper and in principle, this cycle should allow for learning, adjustment, and improvement to federal programs over time. In practice, however, agencies vary in how consistently they translate such information into planning, decision-making, or course-correction. Federal agencies have made progress in building and using evidence, but translating that information into timely operational or policy revisions remains uneven.
The core problem isn’t production; it’s translation, and the translation failure shows up as “so what” gaps on both sides of the information pipeline. On the input side, receivers of information are often left asking what they’re supposed to do, and on the output side, a second question appears – “is it my job to act on this, and if so, how?”. Research findings are often too slow, too caveated, or too disconnected from immediate policy and management questions. Performance data may show quantitative changes in outputs, costs, or enrollment without revealing the mechanisms behind them or the practical implications for implementation, or cueing the design apparatus that could apply these insights. Feedback from frontline service providers and affected users might reach leadership mainly through quantitative indicators, dashboards, or status updates, which don’t always capture lived experience, causal explanation, or informed suggestions for course correction. Without named owners and defined next steps, even the most actionable information tends to circulate rather than convert.
Three gaps sit behind this pattern. First; a context gap – decision-makers often lack the full picture, because qualitative indicators and customer experience research arrive separately, or later than quantitative evidence, leaving them with only a partial view of what’s working well or driving implementation problems. Second, an action gap; even with a complete view of the picture, it’s not always obvious which lever applies, on what timeline, or with what tradeoff. Third, an ownership gap; it’s often unclear who is responsible for translating any given signal into a decision, and this ambiguity means that insights can be observed without being acted on. Together, these three gaps leave evidence and feedback insufficiently integrated into decision-making routines.
The problem is also structural; decision-makers face turnover, competing priorities, time limits, and management pressures, and thus, evidence needs a more robust pathway. Devoid of clear translation, trusted messengers, and defined or mandated use points, even the most relevant information can be too late, too ill-timed, or too jargon-heavy to influence decisions, resulting in missed adaptation opportunities.
The federal government doesn’t need an entirely new learning architecture. It needs to make the one it already has more usable. Agencies can do this in a few ways. First, by building stronger translation functions by creating space for “knowledge brokers” (people or teams whose core function is to translate evidence into decision-relevant language and maintain the required relationships that make the translation trusted). Second, by incorporating the use of evidence, performance, and implementation feedback into policy and program work from the start. Third, by creating better pathways for implementation and lived-experience feedback to reach leadership in ways that resonate with them and support action.
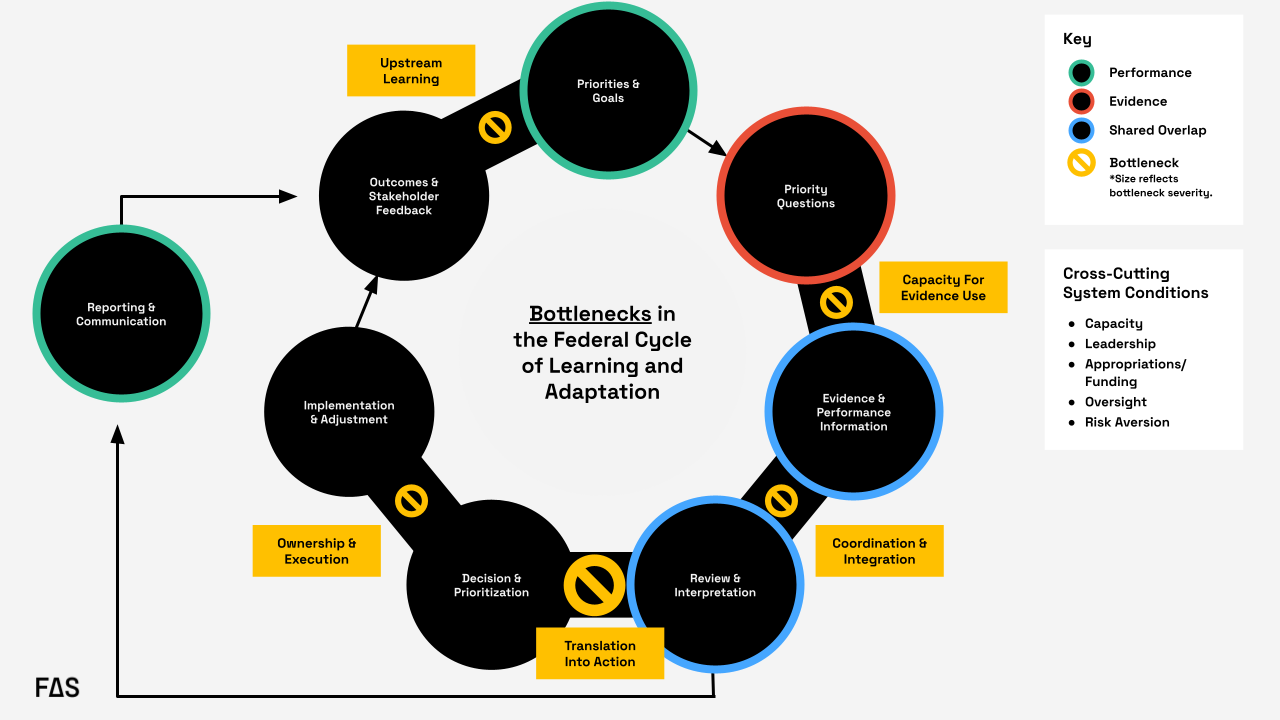
Formal federal guidance envisions a closed “loop” linking goals, priority questions, evidence, and performance information, along with review, decision-making, implementation, reporting, and feedback. In practice, the loop often degrades at key handoffs: evidence-use capacity, coordination and integration, translation into action, ownership and execution, and upstream learning from outcomes. The most significant recurring bottleneck occurs during the transition from review and interpretation to decision and prioritization, where information is generated and reviewed but does not reliably translate into action.
Plan of Action
We need to shift from a system that collects information to a system that uses it.
Agencies should create or strengthen embedded translation functions that connect evidence, performance information, implementation experience, and policy levers at the moment decisions are being made. The key is to move from a dissemination model to a utilization model. Instead of “produce, disseminate, and hope for uptake”, agencies should do the following:
Recommendation 1. Designate a knowledge broker to facilitate regular decision briefs…
or routines that create structured opportunities to clarify what’s known, what’s uncertain, and what actions are available – beginning with a defined set of high priority issues rather than every single decision the agency needs to make.
This recommendation targets the translation into action bottleneck in Figure 1; the handoff from review and interpretation to decision and prioritization, which can be considered the most significant recurring point of failure in the federal cycle of learning and adaptation. In practice, this means assigning this function to a role or small team housed in an existing performance, evaluation, strategy, or program office and requiring that group to support recurring decision points with short decision briefs. Those briefs should identify the decision, synthesize relevant evidence, performance trends, and implementation feedback, and specify available actions, tradeoffs, and owners.
For example, in the rollout of the FAFSA Simplification Act, a knowledge broker tied specifically to this initiative could have translated readiness indicators, beneficiary feedback, and information from financial aid administrators into decision-ready synthesis for the officials with decision authority who were attempting to course correct in real time. Instead, significant delays turned the rollout into a high-profile implementation issue.
Crucially, this function should start narrow. Rather than positioning a knowledge broker as an all-purpose translator for an agency’s full decision load, the initial portfolio could be scoped to a small set of priority issues. Starting narrow lets the broker establish credibility and relationships that make translation trusted and refine what the routine and explicit outputs are before it scales – the portfolio can scale later. This gives agencies a defined mechanism for turning reviewed information into decisions rather than leaving that handoff informal. Within the federal government, the Office of Evaluation Sciences has modeled how an embedded team of evidence translators can work alongside program offices rather than from a silo.
Recommendation 2. Start policy initiatives and evaluation planning with a real question…
or decision, identify the user, specify the lever, and clarify – in advance – what different findings would imply. Incorporating this thinking upstream changes the role of evidence from a retrospective input to an operational tool.
This recommendation mainly addresses the translation into action bottleneck, and secondarily, the evidence-use capacity bottleneck. Agencies can operationalize this by building decision framing into existing learning agenda and evaluation planning processes, both of which are already required under the Evidence Act. Before an evidence product is commissioned or a performance indicator is selected, program offices can be required to answer four questions on the record: What decision is this for? Who will use it? What lever would change as a result? What finding would lead to what action?
In a hypothetical example, say that USDA’s Food and Nutrition Service (FNS) wants to commission a new evaluation or analysis regarding SNAP redetermination churn (the pattern of households losing SNAP benefits at recertification and then re-enrolling, often for procedural reasons rather than eligibility). The four questions noted above can be answered on the record before the work begins. The decision is whether to issue new guidance to state agencies on recertification practices and what that guidance should encourage. The user is the FNS administrator and the relevant policy office, with state level SNAP directors as the implementing audience. The lever is subregulatory guidance. The early thinking regarding mapping findings to actions would specify, in advance, which patterns or insights would trigger which associated response. This way, when the findings arrive, USDA wouldn’t be starting from scratch with the “what do we do with this” question; the decision architecture would already be in place.
Pre-specifying these conditions in a short decision-framing memo that travels with the work turns evidence from a retrospective deliverable into a tool scoped to a specific decision or policy window. The same logic extends to decision memo templates themselves, which can include standing prompts such as “what evidence informed this decision?” and “how will we learn about this in real time?”, so that utilization is built in.
Recommendation 3. Create pathways for easier access to mixed methods evidence and insights from lived experience.
Recommendation 3 targets the coordination and integration, and upstream learning bottlenecks; the gap where evaluation, performance, administrative, qualitative, and customer experience data move at different speeds, live in different places, and reach decision-makers as parallel streams. Insights from lived experience – what programs actually look and feel like to the people using them – are particularly likely to be separated from information that reaches leadership, arriving as anecdotes, if they arrive at all. Because these problems are distinct; the recommendations can be broken down and addressed at the agency level.
Recommendation 4. Standardize decision-ready formats that consolidate quantitative and qualitative evidence.
Agencies should build standardized decision templates and briefs that present quantitative indicator-level data alongside narrative summaries of lived experience and implementation conditions, so decision-makers aren’t expected to synthesize across disparate sources on their own timelines. The resulting artifacts should be tied to recurring decision moments (budgeting, guidance revisions, program reauthorization) so that they can be used in real time.
In the FAFSA Simplification Act rollout, the Department of Education leadership faced this problem: application data, technical readiness indicators, information from financial aid administrators, and user feedback existed separately, and moved at different speeds. A standardized decision-ready format could have pulled those streams together; pairing completion trend data with brief narratives or exemplary quotes regarding what applicants and financial aid offices were actually encountering, rather than leaving leaders alone to assemble the picture in real time
Recommendation 5. Actively use existing general clearance mechanisms for rapid qualitative and user experience research.
Agencies should make use of standing generic clearance mechanisms that allow them to fast-track small qualitative and user experience studies (for example, up to 100 respondents, completed within a fixed time window) when unexpected findings need rapid explanation. This would allow for the ability to run a tightly scoped evaluation in weeks rather than months, which is the operational timescale at which decisions frequently move. Without it, the qualitative evidence needed to explain any type of performance anomaly often arrives after the decision or policy window has closed.
For SNAP redetermination churn, this would let FNS turn around a short, scoped evaluation of why participants are dropping off at a specific step in the recertification cycle in weeks rather than months. The insights could then inform the next round of guidance rather than coming in after the fact.
Recommendation 6. Build customer-first indicators built into existing federal reporting requirements.
Beneficiary and frontline experience should become part of the evidence base by default rather than by exception. Most federal programs already have reporting infrastructure, and layering in a modest set of customer-first indicators that use the existing infrastructure rather than building new information collection requirements ensures that user perspectives are consistently available as routine inputs.
Within the federal government, the customer experience and life experience work coordinated through OMB and performance.gov has demonstrated that lived experience can be collected and used at scale within existing authorities, which can be considered a foundation to build from rather than reinvent. At the state level,Minnesota’s Story Collective, housed within Minnesota Management and Budget (MN MMB), pairs administrative and performance data with qualitative, lived-experience narratives to give decision-makers a richer view of what their programs are actually producing.
These recommendations also address a common weakness in the federal system: evidence and performance information sit within the same broad ecosystem but move at different speeds, use different tools, and often reach different audiences. This is all the more reason to create a translation layer that can synthesize across them. Agencies need staff and routines that can connect evaluation, administrative data, performance indicators, qualitative input, and implementation realities into decision-relevant guidance. Without that connective tissue, agencies are left with parallel streams of information that don’t consistently converge at the point where action occurs.
Conclusion
The federal government already generates a great deal of information about what it’s doing and how it’s performing, but information isn’t the same as learning, and learning isn’t the same as adaptation. The gap between them is where the “so what” goes unanswered, and where the federal feedback loop breaks down.
Closing these loops doesn’t require new infrastructure or authority. It requires three shifts in how the existing system is used: designating knowledge brokers to carry translation across the handoff from review to decision-making, building decision framing into policy and evaluation work from the start so that evidence is scoped to the decisions it’s meant to inform, and creating pathways that move mixed-methods and lived experience into decision-makers’ hands in formats and timeframes that match how decisions actually happen in the federal environment. Whether the question is about USDA responding to SNAP redetermination churn or the Department of Education learning from an application rollout in real time, the underlying pattern is the same: the signals exist, but the translation that turns signals into actionable insights doesn’t reliably happen.
If the government wants a system of learning and adaptation that improves results in real time, it has to treat translation, utilization, and adaptation as core functions of governance rather than as afterthoughts.
We’ve identified the key ingredients of successful moonshots that meet the moment, and developed recommendations about what future efforts can and should look like.
Complex systems – from ecological to political to socio-technical – rarely change the way we expect.
Federal data is a diverse ecosystem with well over 500,000 datasets – including those tackling Alzheimer’s disease and related dementias (ADRD).
This is a tremendous opportunity to redefine what people expect from government, and in doing so, inspire cities across the country to raise their own ambitions. We are excited to see this initiative lead the way and look forward to cheering your success.