SOURCE CODE: A Policy Agenda for Fostering Trust and Fairness in AI
AI systems are rapidly becoming part of the machinery of public life, but they sit on shaky foundations. We have seen AI being deployed for cancer screening, assisting people with disabilities, and even to address complex environmental challenges. Yet as these systems are deployed in increasingly consequential settings, the promise of AI to expand opportunity and increase effectiveness and boost productivity has been accompanied by harms that are no longer hypothetical. These harms fall into several recurring categories: systems can misallocate resources, misrepresent groups, fail to function reliably, or be deployed for illegitimate purposes, even when the technology works as intended.
For example, AI has affected who gets allocated critical resources. A widely used healthcare algorithm underestimated the needs of Black patients, limiting access to care. In finance, algorithmic decision-making has produced discriminatory outcomes in lending and underwriting.
Another observed harm is that failures in AI rollout can affect how people and communities are represented. AI systems have been shown to reinforce harmful stereotypes or render certain groups invisible altogether, particularly when they are trained on incomplete or biased data. A well known example is how facial recognition technologies are shown to perform significantly worse on darker-skinned individuals, raising concerns about misidentification and disproportionate surveillance.
Still, other harms are failures of basic system functionality. Gunshot detection systems have generated large numbers of false alerts, manipulating how evidence is used in criminal proceedings. The Michigan Integrated Data Automated System (MiDAS), which was used to find instances of fraud in state unemployment benefits, was incorrect in 85% of its fraud determinations.
Another category of concern arises not from failures in system design or performance, but from how AI systems are built and used in practice. These harms arise not from system failure but from how situations in which systems operate as intended yet still produce harmful outcomes. For example, algorithmic management tools in the workplace could intensify worker surveillance, destabilize scheduling, or reduce worker autonomy, even when operating accurately.
These harms explain why AI is facing a crisis of public trust. A June 2025 Pew study found that half of U.S. adults feel “more concerned than excited about the growing use of AI”, with only a small minority expressing optimism. AI cannot deliver broad public benefits, such as improved public services, if the people affected by it do not trust the systems shaping their lives. The public will not trust abstract statements of fairness, transparency, responsibility, or legitimacy. It will be rebuilt only if those commitments are translated into procedural institutional mechanisms: procurement rules, public engagement processes, sector-specific safeguards, and holistic remedies. Such commitments will mean that AI can be used legitimately in the public interest.
In many cases, the concern is whether the technology should even be used. This question raises deeper considerations around the concentration of power, human dignity, and the conditions under which innovation actually benefits the public. While AI can be used to support societal benefits, such as helping overworked healthcare practitioners, it can also be used in ways that harm human dignity, such as through surveillance or by restricting fair access to benefits or create new vulnerabilities like cybersecurity and data privacy risks. Building fairness and trust in AI requires more than improving system performance. Policymakers and the public must ask whether particular uses are legitimate, who benefits, who bears the risks, and what limits they should set and enforce.
Because these questions cannot be answered by abstract principles alone, the Federation of American Scientists worked with experts and practitioners across civil society and academia to bring together a policy agenda with ten actionable and high-impact solutions. We did this through our SOURCE CODE: AI Trust and Fairness Policy Sprint. When problems are urgent, institutions are uncertain, and traditional policymaking moves too slowly, our policy sprints create space to bring together experts across disciplines, from academics to technologists, advocates, and practitioners, and empower them to move quickly from diagnosis to action. Instead of debating what trust and fairness mean in the abstract, this sprint focused on what they look like in practice, and how it can be operationalized through specific policy levers.
This paper proceeds in three parts. First, we examine how fairness and trust are understood across different contexts, and why that creates friction in how we map the space. Second, we explore the challenges of implementing policy designed to install fairness guardrails. We highlight how gaps in policy, capacity, and real-world conditions can undermine even well-intentioned systems. Finally, we present a set of policy strategies across these key levers, offering actionable pathways for building fairer and more trustworthy AI systems.
What do we mean by ‘trust and fairness’ in AI?
Fairness and trust are often invoked as key components of AI governance and policy, but they can seem nebulous depending on the context and the community at hand. In general, we consider public trust to be the extent to which people see systems and institutions as reliable, accountable, and responsive to harms. AI fairness broadly concerns whether AI systems distribute benefits and burdens in ways that can be justified within a particular social, legal, and institutional context. Together, fairness and trust point to a broader question of legitimacy: whether an AI system should be used at all, for what purpose, and under what auspices.
This section will reflect on how different stakeholders view fairness and public trust to examine each perspective before turning to existing legal instruments, policy gaps, and what is needed for effective policy implementation in this field.
On fairness
Fairness in AI is not a single concept but is defined differently across technical, legal, and social domains. This plurality reflects how AI systems are “sociotechnical systems”: their effects depend not only on data and algorithms but also on the institutions, incentives, rules, and human decisions that shape their deployment.
In examining how society in general views fairness, literature shows that individuals often understand fairness not as a clearly defined principle but in contrast to experiences of unfairness– that is, the absence of harm. This means that individuals, communities, and different cultures perceive fairness differently based on their own lived experiences. In terms of AI fairness, society views fairness as specifically related to terms such as “equity, consistency, non-discrimination, impartiality, justice, honesty, and reasonableness.”
When evaluating fairness in AI systems, technical literature often distinguishes between two broad concepts. The first, individual fairness, asks whether similar individuals are treated comparably for a given task. This approach requires defining which characteristics are relevant to the task and what it means for two people to be meaningfully similar. The second, group fairness, examines whether outcomes are distributed unequally across groups. For example, in hiring, one group fairness approach might ask whether candidates from different demographic groups are selected at similar rates, while other approaches might focus on whether error rates or predictive accuracy differ across groups.
There are differences of opinion about what actually constitutes equal or similar outcomes in these definitions and how to predict them. On the one hand, historical data may be treated as a valid basis for predicting future outcomes. On the other hand, historical data itself could be shaped by historical and structural inequities, causing systems trained on it to reproduce existing patterns of discrimination. These competing considerations around historical data can create situations where an AI system is meeting one definition of fairness, but the actual outcome is creating unequal harms to a group or individual. The ProPublica investigation of the COMPAS risk assessment tool, an algorithm used to support criminal justice officials’ decisions on bail, sentencing, and early release, found that Black defendants were twice as likely to be labeled as high risk as white defendants. In theory, COMPAS satisfied one fairness criterion, in this case predictive parity, which means that risk scores are equally accurate across groups, but it also propagated the systemic inequalities of the U.S. criminal justice system.
Fairness cannot be understood as a fixed technical standard, but rather as a contested concept shaped by social, institutional, and legal contexts. Determining which definition of fairness should govern a particular AI system is a nuanced decision, one that requires a deep understanding of the sectoral context, stakeholders, and other elements within the scope of the AI system’s deployment. This becomes even more challenging when relying on existing legal frameworks that may only partially address the complexities of AI-driven decision-making.
On public trust
What does it mean for technology itself to be worthy of trust and, in turn, of adoption? Public trust in AI is not generated by technical performance alone. It is built when people can see that an AI system serves a legitimate purpose, works reliably in its deployment context, and remains subject to meaningful human oversight, public accountability, and remedies when things go wrong. We also explicitly see fairness as a component of public trust, and that the public will not trust AI if they view that its allocations of opportunities and burdens are unfair. Ultimately, public trust is dependent on the public seeing the use of AI as justified and legitimate. If it falters, then AI use will be seen as negative to society. For example, the prospect of AI-driven worker substitution is a major source of public concern, raising questions about whether the use of AI to replace human labor is legitimate. If such a substitution occurs at scale, it could further erode public trust in AI systems and their deployment.
Public sector adoption of AI is where governance approaches are first tested in practice, shaping both regulatory norms and broader public expectations. When government agencies deploy AI systems, they are effectively signaling what responsible use looks like. As a result, failures in public sector systems can have outsized consequences. When government use of AI leads to unfair outcomes, unreliable decisions, or a lack of accountability, it can erode trust not only in AI but in the government itself. For example, the use of automated prior authorization systems in Medicare Advantage has been associated with higher denial rates and barriers to medically necessary post-acute care, something that could directly affect public attitudes towards AI adoption in government services.
Across the federal government, different administrations have relied on the discourse that public trust in AI systems is essential to ensuring that the technology is disseminated across the public sphere. For example, Executive Order 13859 under the first Trump administration explicitly called for the use of AI in a manner that “fosters public trust and confidence,” a sentiment that carried over into Biden-era executive actions and remains in the current Trump administration OMB guidance, which defines how the federal government uses and acquires AI. These efforts have generally focused on identifying broad, high-risk uses of AI in the federal government and then pairing them with risk-mitigation requirements, leaving federal agencies to define implementation details and build the internal capacity to identify and enforce protections against AI uses that could erode public trust.
How can existing law be used as a tool for trust and fairness?
Existing anti-discrimination law provides an important, but incomplete, set of tools for addressing AI-related harms. In employment, Title VII of the Civil Rights Act of 1964 prohibits discrimination based on race, color, religion, sex, and national origin. Later case law and statutory amendments, including the Civil Rights Act of 1991, developed a framework that distinguishes between disparate treatment, where a person is intentionally treated differently because of a protected characteristic, and disparate impact, where a facially neutral practice causes unjustified adverse effects for a protected group. This framework is highly relevant to AI systems, which may produce unequal outcomes even when they do not explicitly use protected characteristics.
Existing statutory tools are also directly applicable to AI-related consumer harms that occur in specific sectors. The Equal Credit Opportunity Act (ECOA), for instance, remains a powerful tool for addressing bias and discrimination in financial services, especially in cases where discrimination arises from algorithmic decision-making outputs playing a determinative role in financial outcomes such as loan decisions. Recent enforcement actions clearly demonstrate how these existing laws can be applied in practice to algorithmic harms to build the much-needed public trust in AI systems. In 2025, the Massachusetts Attorney General’s Office fined a financial services company that used AI for student loan underwriting after determining that its algorithmic outputs were discriminatory. As part of the legal remedy, the company was required to inventory its models and retrain them to comply with anti-discrimination, consumer protection, and fair lending laws. Similarly, the Federal Trade Commission has already used its authority to address harmful AI deployments. Its settlement with Rite Aid over the use of facial recognition technology included an unfairness claim, underscoring that discriminatory or harmful AI practices can fall squarely within existing prohibitions on “unfair” conduct. These examples illustrate that while regulators are able to act, such interventions are reactive, occurring after harms have already materialized, and may not provide detailed guidance for how systems should be designed or governed in advance.
Yet, without statutory reform, the contemporary reliance on existing law and legal frameworks is out of necessity rather than choice. This is in part because legal frameworks typically do not define fairness in the abstract. Instead, the law operationalizes it through established doctrines, standards, and enforcement mechanisms. Many emerging AI concerns can be partially mapped onto well-established legal principles with effective recourse and remedies for consumers. This continuity becomes especially apparent in consumer-facing contexts.
For example, trust and fairness in consumer-facing technologies such as AI closely align with longstanding notions of consumer product safety. As such, public concerns about whether AI systems are reliable, transparent, and non-harmful mirror traditional expectations that the physical products consumers purchase should not pose undue risks or potential harms. In addition to notions of what constitutes product safety, the American legal system has long articulated what constitutes “unfair” conduct through statutes such as the Federal Trade Commission Act and the Dodd-Frank Act’s prohibition on unfair, deceptive, or abusive acts or practices (UDAAP).
In the absence of clear enforcement and interpretive guidance, however, legal gaps can translate into diffuse or ambiguous accountability, undermining public confidence in both the technologies themselves and the institutions responsible for overseeing them. One such example of this dynamic leading to widespread unease and declining public trust in technology is the bipartisan frustration over digital payment apps. Apps that use AI tools for automated content moderation or fraud detection can unknowingly “debank” and terminate the accounts of otherwise welcome clients.
Policymakers therefore face a difficult bind: without more deliberate efforts to operationalize fairness and accountability, public trust will remain elusive. Legal standards alone are not enough; they must be translated into systems that people experience as fair, reliable, and responsive to harm.
In the absence of new laws that directly address the challenges posed by artificial intelligence, practitioners must rely on existing legal frameworks that offer only partial mechanisms for accountability and redress when harm arises. This creates particular challenges in areas where concepts such as “trust” and “fairness” in AI systems are not explicitly codified, and where legal precedent is still limited or emerging. Existing legal frameworks may provide an important starting point for building public trust, but they do not fully capture the range of concerns raised by AI systems or the conditions needed to sustain public trust over time.
The challenge of implementation: why good intentions fail to produce trusted outcomes
In a rapidly evolving policy climate, governments across jurisdictions have implemented or proposed to create fairer, more trustworthy algorithmic systems and to protect people from harms. When designing policy interventions, it is important to take into account how prepared institutions are in taking on these responsibilities, and what resources, such as talent, processes, and even data availability, exist to ensure that a new policy has a fighting chance to succeed.
Take, for example, federal agencies’ implementation of OMB Memorandum M-24-10, a government-wide guidance document on how the federal government uses and acquires AI. Agencies are supposed to publicly publish a compliance plan describing the processes they will undertake to follow said guidance. In our analysis of these compliance plans, we found that agencies vary in technical expertise, staffing capacity, and institutional resources, which leads to inconsistent compliance and fragmented oversight practices. In this case, governance frameworks alone are insufficient; effective implementation depends on sustained investment in technical talent and administrative capacity.
At the state level, California’s implementation of Assembly Bill 302 illustrates a similar challenge of translating AI governance policies into accountability mechanisms. Although the law required the state to inventory high-risk automated decision systems used by agencies, California’s first public use-case inventory incorrectly stated that no such systems were in use, despite numerous publicly documented examples. This failure stemmed from weak implementation practices, including an informal reporting process that relied largely on agency self-reporting through email surveys.
New York’s Local Law 144, which codified bias auditing requirements for automated decision-making systems, has also faced its own constraints. For example, an audit of the law found that implementation challenges were compounded by limited mechanisms for leveraging expertise through interdepartmental collaboration. In addition, limitations in data quality and availability significantly constrain the ability to evaluate explicit bias or disparate impact. In New York, this challenge was particularly evident during implementation, as agencies struggled with both limited test data and the widespread absence of key demographic information needed to assess bias. In many cases, employers had not collected demographic data on applicants at all, and where such data did exist, it was often incomplete, leaving more applicants without demographic information than with it. This made it difficult to evaluate potential bias in automated decision-making systems used in employment decisions.
These barriers to implementation are a key motivation for the SOURCE CODE: AI Trust and Fairness Policy Sprint. In each of our memos, we take into account the resources, the stakeholders, and the capacity of each institution in bringing a policy idea to fruition. In developing our policy agenda, we have worked with experts across civil society and academia to identify solutions that are responsive to public concerns while remaining attentive to the realities of policy implementation. Across the policy memos, we outline actionable proposals that address several core policy levers that can help move AI governance from principle to practice.
Policy Levers to Advance AI Fairness and Build Public Trust
In undertaking this sprint, our focus is on how policy proposals can be implemented in light of current institutional and political realities. We recognize that broader debates over the values and governance of AI, including recent federal actions, have created uncertainty around the durability and implementation of comprehensive AI governance frameworks. Rather than concentrating on a single theory of AI governance, our sprint examines ten targeted ideas that can influence outcomes across different jurisdictions to provide trustworthy and fair outcomes for AI use. Our ideas can be categorized across four policy levers: government use of AI, public engagement, sector-specific interventions, and remedies.
Guardrails in Government Use of AI
Government use of AI represents one of the most immediate and consequential opportunities to shape how these systems function in practice. When public agencies adopt AI, they are not merely deploying tools but also setting precedents that can influence how systems are designed and governed more broadly. Public procurement, in this context, emerges as a critical but underexamined lever. The terms governments set when acquiring AI systems shape what vendors disclose, how systems are assessed, and what safeguards are built in from the outset. Several of the memos look at how AI is acquired across many sectors of public service, such as education, law enforcement, and healthcare, specific risk mitigation tools, and what final procurement agreements between governments and vendors should consider. Here are the policy ideas that specifically look at guardrails for government use of AI:
- How State Governments Should Purchase AI to Ensure Fair, Transparent, and Accountable Use by Jae Yeon Kim and Aniket Kesari
- How State Leaders Can Put People First in AI Decision-Making by Nicole Ozer and Brady Hirsch
- Prioritize Student Safety in K-12 Education By Establishing AI Procurement Guardrails by J.B. Branch
- The Federal Government Should Pilot a Decision Subject Representative Program for AI Systems Inspired by the FDA by Anna Lenhart
- How to Safely Bring AI into Law Enforcement AI-Generated Police Reports by Jon M. Peha
Public Engagement
Public engagement is treated as an afterthought in policymaking, in part because it is difficult to execute well. Policymakers and affected communities operate in different technical and cultural languages, making sustained dialogue challenging. Yet, meaningful public engagement in AI deployment can be a critical step to ensuring that AI use is both appropriate and trustworthy. Systems developed and deployed without concrete input from affected communities risk entrenching harm and undermining trust. Therefore, we have looked at practical ways that public engagement can be institutionalized at both the federal, state and local levels, as well as deployed to bring in underrepresented communities, such as rural populations, into the policy-making context. Here are policy ideas that move through what public engagement should like in practice:
- The Federal Government Should Pilot a Decision Subject Representative Program for AI Systems Inspired by the FDA by Anna Lenhart
- Empowering Communities through Community Benefit Agreements in AI-Fueled Data Center Development by Liza Paudel
- FairCare Verification Offers a Human-Centered Path for AI in Medicaid by Y. Tony Yang
- How State Leaders Can Put People First in AI Decision-Making by Nicole Ozer and Brady Hirsch
- Making Rural Communities Visible in Artificial Intelligence Through Rural Proofing in Kansas and Beyond by Ziwei Qi, Tatiana Lin, and Ayokunle Olagoke
Sector-Specific Interventions
AI does not operate in a vacuum, and neither should its governance. Each sector presents distinct risks, regulatory landscapes, and implementation challenges that must be accounted for in policy design. In K-12 education, procurement processes must consider privacy measures for underage individuals, surveillance, and the outsourcing of pedagogical judgment. Systems used to draft police reports risk introducing unverified or fabricated information into official records, underscoring the need for defined standards on use, human oversight, and disclosure. In labor markets, AI systems are reshaping wages, working conditions, job protections, and income stability. Healthcare has long been a contested space for automated decision-making systems because of its direct impact on access to care and quality of life. Existing sectoral protections will need to address algorithmic management, including requirements for transparency, notification, and avenues for contesting automated decisions. Here are policy proposals , spanning healthcare, education, labor and law enforcement:
- FairCare Verification Offers a Human-Centered Path for AI in Medicaid by Y. Tony Yang
- Move Algorithmic-Driven Pay and Scheduling Systems From Surveillance Pay to Fair Wages by Wilneida Negrón
- How to Safely Bring AI into Law Enforcement Through AI-Generated Police Reports by Jon M. Peha
- Making Rural Communities Visible in Artificial Intelligence Through Rural Proofing in Kansas and Beyond by Ziwei Qi, Tatiana Lin, and Ayokunle Olagoke
- Prioritize Student Safety in K-12 Education By Establishing AI Procurement Guardrails by J.B. Branch
Redress and Remedies
Although much of AI governance focuses on preventing harm, no system of safeguards will be perfect. This raises a critical question: what does redress look like when harms do occur? Existing approaches to recourse often fall short when applied in the real world, and incentives do not always align with accountability, and agencies or vendors may face legal, financial, or operational constraints that limit the availability or effectiveness of recourse mechanisms. These gaps point to the need to think more expansively about redress; we need to encode the individual right to contest decisions and insert it within a broader system of accountability. What institutional structures are needed to support meaningful recourse? And what forms of remedy, whether procedural, financial, or community-based, are appropriate? Here are two ideas that make harms structurally correctable:
- Settlement Wins Against Big Tech Should Underwrite Digital Resilience Funds by Gaurav Laroia and Charlotte Slaiman
- Empowering Communities through Community Benefit Agreements in AI-Fueled Data Center Development by Liza Paudel
From Ideas to Action
Our SOURCE CODE: AI Trust and Fairness Policy Sprint aims to advance the detailed policy solutions needed to foster public trust and implement fairness in the adoption of AI across diverse domains, from healthcare and government benefits to rural access, education, and worker protections.
We hope readers will engage deeply with these proposals, help bring them into practice, and build on them, developing new ideas that push this work even further. These ten proposals are not comprehensive, nor do they capture the full landscape of challenges that AI governance must address, from market concentration and labor displacement to infrastructure impacts and frontier-model risks. Rather, they are intended as an actionable starting point, an effort to illustrate what a detailed, implementable policy can look like.
The next step is to test these ideas in practice, learn from their successes and shortcomings, and translate those lessons into stronger governance frameworks. We hope this work serves as a foundation for a growing coalition of policymakers, practitioners, and communities committed to building AI systems that are fair, trustworthy, and accountable.
How State Leaders Can Put People First in AI Decision-Making
How State Leaders Can Put People First in AI Decision-Making is a framework to ask and answer the right foundational questions about artificial intelligence (AI) from the beginning. The public wants the government to take action to ensure the power of AI technology is used for good. In the current political climate, the work of state leaders is critical. The recommendations in this memo are focused on helping state leaders across the country ground decision-making about AI use in fairness, accountability, evidence-based inquiry, and inclusive governance so that AI can work for people.
Many state agencies have already deployed or are considering using AI in consequential decisions related to healthcare, housing, education, policing, finance, and other highly sensitive areas. While a few states have taken steps to implement decision-making mechanisms for certain AI systems, too many leaders are simply accepting narratives about AI’s purported public benefit at face value – jumping to the “how” of AI implementation before thoroughly vetting potential systems and deciding whether they are appropriate to use at all.
State officials may be eager, and even feel pressure, to tap into the potential benefits of AI in the hopes of better serving their constituents. But the personal, political, and operational risks of AI use should not be underestimated. People across the political spectrum are deeply concerned about the impact of AI on their lives and these concerns are well-founded. There have already been numerous examples where the failure to center people in AI decision-making and use has resulted in government systems that range from inefficient and wasteful to disruptive and downright dangerous, causing significant harm to, and backlash from, community members.
For AI’s potential benefits to be realized, state leaders need to implement consistent, inclusive people-first AI decision-making structures. Crucially, this process should ask the foundational question of whether to use AI in the first place. This policy memo provides timely guidance on:
- Why policymakers should adopt a people-centered AI decision-making process;
- What consistent process to follow as the foundation of any AI decision-making policy;
- How to operationalize this process through a flexible set of options designed to meet specific needs, structures, and opportunities in different states.
Rather than offering a one-size-fits-all approach, this memo provides a suite of mechanisms for engaging thoughtful AI decision-making with examples of how different state governments have tackled emerging AI issues. We give recommendations for how state leaders can implement the AI decision-making process for whichever path they choose, including methods to promote accountability so that the decision-making process is followed and can truly work to put people first.
Challenge and Opportunity
The use of AI by state agencies is growing. By 2024, 59% of state and local government employees reported that their agency had already made an AI application available for use and a majority of public sector employees reported using AI applications either several times a week or daily.
Generative AI (GenAI) systems and agentic AI systems are now joining machine learning and automated decision-making systems (ADS) that have been in use for many years – with the lines between the types of systems blurring as AI products become increasingly integrated.
AI is also being applied in many high-stakes situations where mistakes or bias can have life-altering ramifications. AI systems now make decisions that can affect the lives of tens of millions of low-income people in the United States, from determination of SNAP benefits, to Medicaid enrollment, to Social Security disability payments. Sixty percent of people in the United States live in a jurisdiction that employs some sort of pretrial risk assessment tool that uses AI. According to one AI surveillance vendor, thousands of police departments in the United States are using face surveillance.
While many policymakers may be enticed by the promise of AI, people across the country and political spectrum have deep concerns. As of 2025, only 17% of the general public believes AI will positively impact the United States. Americans broadly oppose AI being used in high-stakes decision-making, like health insurance, loan applications, and job screening. A 2025 poll of U.S. voters found that 82% said they do not trust technology leaders to tackle regulation independently. A supermajority – 69% – of the U.S. public does not think the government is doing enough to regulate AI.
How does the public feel about AI?
More than 50% of people in the U.S, and 65% of low-income people, fear being left behind by AI. Only 4 in 10 people ages 18-34 in the U.S. say that they “trust” AI and only 23% of people in the U.S. over age 55 trust AI systems. As AI advances, public anxiety grows. Polling reveals that 77% of people in the U.S. want companies to “take AI creation slowly to get it right the first time.”
Public concerns with AI are well-founded. Former high-profile staffers at several AI companies have warned that companies are moving too fast and minimizing AI’s deficiencies, with new AI systems “generating more errors, not fewer.” While the technology industry is pushing the pedal on AI, the public would like to hit the brakes and for leaders to “do something before it goes too far.”
In the rush to adopt AI, some government officials have been making mistakes. The most impacted communities, including low income and communities of color, often end up excluded from public deliberation about government use of technology. There are already numerous examples of how these same communities bear the brunt when there is a lack of people-centered AI decision-making:
- The state of Michigan abandoned a $47-million automated unemployment fraud detection system after it was found to have a false positive rate of 93%. Michigan had to pay $20 million to settle a civil rights class action lawsuit and spend an additional $78 million to install a new system.
- Automated systems caused delays in obtaining critical unemployment benefits for people in several states, including in California where a fraud detection algorithm system improperly flagged 600,000 people as having potentially fraudulent characteristics.
- Issues of discrimination related to AI algorithm use has been documented across numerous jurisdictions, including a family screening system used in Pennsylvania that gave more racially disparate recommendations than child welfare workers.
- AI errors are also creating dangerous interactions between police and community members. Police have wrongfully arrested people, many Black community members, because of AI-powered face surveillance. Maryland police also swarmed out of eight squad cars and surrounded a 16-year old and held him at gunpoint after his school’s AI security system mistakenly identified his bag of potato chips as a gun.
There are high costs for improper AI use – for the people whose lives are impacted, in the state dollars that are invested, and in how these actions can further undermine trust in government.
At their best, AI systems can help improve government functions. They have the potential to be used to triage community feedback, provide translation services that make government more accessible, facilitate emergency preparedness, or aid scientific research, among other uses. For example, Maryland’s Department of Labor is partnering with academic researchers to help test how AI can train staff and assist caseworkers with compliance regulations and other complex paperwork.
People want government leaders to take action to ensure AI technology is used for the public good. As the current administration has undermined safeguards at the federal level and issued executive orders attempting to stifle state action on AI, the continuing work of state leaders to safeguard rights and center people in AI decision-making has become even more critical.
A few states have already taken some steps to implement process mechanisms for AI decision-making and potential use. These include: Connecticut’s Act Concerning Artificial Intelligence, Automated Decision-Making and Personal Data Privacy and AI Responsible Use Framework; California’s State Guidelines for Evaluating Impacts of Generative AI on Vulnerable and Marginalized Communities; Maryland’s Responsible AI Policy; New York State’s 2024 LOADinG Act; and Texas’ Responsible Artificial Intelligence Governance Act.
While these steps are an important start, more needs to be done given what is at stake with AI use and its potential impact on people’s rights, livelihoods, and personal safety. For the potential benefits of AI to actually be realized for community members, strong state leadership in this moment is needed to pierce through the hype. This memo lays out a plan of action for state leaders to implement consistent, inclusive people-first AI decision-making structures that do not skip over the foundational questions of why and whether to use AI in the first place.
Plan of Action
State leaders should establish a people-centered decision-making process that consistently and thoughtfully considers why and whether to use AI before jumping to use policies or other safeguards. This process should be followed whenever a state is considering the acquisition or use of an artificial intelligence system, whether through formal procurement, partnerships, in-kind donations, or other means. This decision-making process should be utilized when considering any AI system that has the potential to impact people’s rights, opportunity, well-being, safety, and security.
In the following section we provide:
- The four key steps a people-first AI decision-making process should follow.
- Examples of AI uses that should be prohibited.
- Recommendations for how to operationalize the decision-making process via executive or legislative action, depending on the needs and structure of a given state government.
- Methods to ensure that the people- centered decision-making process is followed and enforceable.
The Four Key Steps for People-First AI Decision-Making

Step 1. Articulate a specific and inclusive “why” for AI use that centers the interests and voices of diverse community members to identify problems and needs.
State leaders should ensure that the first step in decision-making about any existing or potential use of an AI system is for an agency to articulate a specific and inclusive “why” that centers the interests and voices of a wide range of community members. Particular attention should be paid to historically marginalized communities. This community engagement should happen pre-procurement or use of any AI system.
Key considerations for centering diverse community members include, but are not limited to:
Inclusivity and representation: Use multiple strategies to support participation from diverse stakeholders, including funding and support for state agency outreach. Develop potential partnerships with trusted local organizations such as community groups, faith-based organizations, schools, and neighborhood associations who can help spread the word, organize meetings, and share information and surveys with diverse community members.
Accessibility: Make it possible for diverse community members to be actively engaged through a combination of in-person and remote engagement mechanisms. Also provide asynchronous paper and online surveys distributed in multiple languages in easy-to-understand formats. Information about any proposed AI systems should describe how a system would work and what it would do in ways that the general public can understand. Schedule any in-person meetings in places and times when diverse community members will be able to attend and provide necessary support for participation, like childcare and transportation. Remote meetings should also be scheduled at a time in the day when working people and people with families can attend.
Power sharing: Centering diverse voices means meaningful collaboration, not token consultation. Community members should have genuine influence on determining what are the most important issues facing them and how they should be addressed. You should listen to community members about any non-AI solutions that they would prefer and why.
Transparency and Accountability: Be clear about the engagement process and ensure it allows for serial feedback. Make sure materials are publicly published and easily accessible on a government website in a timely manner to allow public engagement with the process. Articulate how community input will be incorporated and have a mechanism to report back to the community on how their input influenced the ultimate decision.
California took important steps to promote effective community consultation when it issued the State Guidelines for Evaluating Impacts of Generative AI on Vulnerable and Marginalized Communities. Authored by the state Government Operations Agency, Office of Data and Innovation, and California Department of Technology, the guidelines recognize the need for a systematic approach that leads with meaningful engagement with diverse communities and how critical it is to specifically consider potential impacts on vulnerable and marginalized communities. Appendix B of California’s guidelines provides some additional helpful guidance on key principles, structures, activities, and focus questions for community consultation.
Step 2. Conduct an AI Impact Assessment that evaluates public benefits and risks, including how the AI system would use people’s information, its impact on rights, and risks of discrimination and bias.
Technology vendors often tout the benefits and downplay costs and risks. It is crucial that amidst the hype state leaders create the structures and processes to support evidence-based decisions about a potential system’s public benefit and risks and avoid AI “snake oil” that wastes state resources and does more harm than good.
State leaders should ensure that there is an AI Impact Assessment (AIIA) to evaluate and explain how the proposed AI system will work, the evidence for its effectiveness and potential public benefit, and its potential for harm (for implementation advice, see below section, “Mechanisms to Operationalize People-Centered AI Decision-Making”). The process should include a public comment period for engagement with the AIIA so people can bring up additional information and concerns. Leaders should also ensure that any company they potentially contract with provides them with the necessary information to conduct an AIIA. Don’t let vendor claims, including claims about potential trade secrets, prevent meaningful review of its products and services.
An AI Impact Assessment (AIIA) should include:
- The intended use cases of the AI system, including its potential public benefits.
- The people and groups most likely to be impacted by the AI use.
- Information about:
- How the AI system was built and trained, including the information used.
- The kind of information that the AI system would collect, use, and output.
- How the public would be informed when they are interacting with the AI system.
- Evidence demonstrating the effectiveness of the proposed AI system at directly addressing and solving the stated purpose and achieving the desired public benefit.
- Report with specificity on the potential public harms of the AI system related to:
- Civil liberties and civil rights, including privacy and surveillance, free speech, due process, human autonomy, and bias and discrimination.
- Equitable access to education, health, housing, employment, and other public services and benefits.
- Energy consumption, carbon emissions, water usage, electronic waste, and other similar environmental impacts.
- Financial impacts, including initial purchase, personnel and other ongoing costs, and any current or potential sources of funding.
- What alternative interventions have been considered to address the stated purpose for the AI system.
- How the AI system would be monitored and regularly evaluated as to public benefit and harms, including the feasibility of meaningful human oversight.
- The public comment period and how people can engage with the content of the AIIA.
Step 3. Use a decision-making standard that is based on diverse community considerations and an evidence-based inquiry that the public benefit justifies the proposed use and substantially outweighs the potential harms.
Decisions about why and how to deploy AI should be driven by the real needs and interests of impacted communities. Using the AI Impact Assessment and the input and preferences of potentially impacted communities, the agency or department should apply a public benefit standard, assessing whether such a purpose for the AI has been demonstrated and whether the evidence-based benefits of the particular use of AI substantially outweigh the potential harms.
This decision-making standard should give strong weight to the opinions of those who will be impacted by the technology, especially historically marginalized communities. Steps to accomplish this include:
- Reviewing comments, survey responses, and meeting notes from the community engagement.
- Summarizing community support and concerns in a report.
- Explaining how community input shaped the decision.
Decisions should clearly articulate what quantitative and qualitative evidence was relied on for the decision. These considerations should be memorialized in a publicly accessible document.
Step 4. Conduct timely, ongoing evaluation of AI systems to determine whether they should continue to be used.
If a state entity moves forward with use of a particular AI system, state leaders should require timely review that centers impacted communities in the qualitative and quantitative evaluation of whether the system is achieving the intended public benefit. This review should also identify any harms arising from the AI use. If public benefits of the particular use of AI do not continue to substantially outweigh the harms, the AI use should end.
The review and evaluation processes should ensure:
- Ongoing feedback loops with people using the AI system with channels for community members to reach out about the benefits and problems related to the AI system.
- Proactive efforts to gather evidence of AI efficacy in meeting its original stated public benefit goals.
- Proactive efforts to assess whether the AI system has impacted people’s rights or otherwise affected equal opportunities to government services.
- Initial evaluation should be planned for no later two years after initial use and then regularly thereafter.
Recommendation 1. Some uses of AI are simply too dangerous. Get ahead by taking them off the table.
Putting people first in AI also means proactively prohibiting uses of AI systems and applications that are simply incompatible with democratic, civil, and human rights. Numerous evaluations from government leaders, academics, technologists, civil rights organizations, and groups representing vulnerable and marginalized communities have found that the threats stemming from the below applications of AI significantly outweigh the benefits. Your AI decision-making process should preclude the following:
- Social scoring systems
- Emotional Recognition systems
- Facial surveillance or other biometric surveillance
- AI use in predictive policing or family policing
- AI control over a person’s life and liberty, including in criminal justice and immigration
Many prudent city and state government officials have already preemptively taken some dangerous AI uses off the table. Maryland’s AI policy prohibits AI that violates fundamental rights, such as social scoring and emotional recognition. Montana’s AI law bans using AI for cognitive behavioral manipulation and sets hard limits on dragnet mass surveillance. And many cities have prohibited government use of face surveillance.
Recommendation 2. Mechanisms to Operationalize People-Centered AI Decision-Making
How to best implement the AI decision-making framework depends on the particular needs, opportunities, and structure of each state government. States that have taken steps to create a consistent process for AI evaluation and adoption have done so through different legal and legislative mechanisms. Which option to pursue – executive action, legislation, agency guidelines, or a combination of the three – is a decision that should be made by those most familiar with the contours of their particular state.
Executive Action – A Governor can issue an executive order requiring all executive agencies to follow a people-centered AI decision-making process. This executive order can identify an agency, or a subset of existing agencies, to develop the process itself and coordinate among different department leaders and staff to provide expertise and oversight that ensures compliance. If relying on an existing agency or state department, state leaders may find that an agency or department already focused on technology, information services, operations, or administrative service might be most well-suited to this role. Or an executive order can create a new entity to provide support.
- California’s Executive Order on AI provided for the Government Operations Agency, the California Department of General Services, the California Department of Technology, and the California Cybersecurity Integration Center to develop guidelines for government procurement and use of AI systems, including guidelines that agencies should follow for evaluating equity concerns of generative AI and its impact on marginalized communities.
- Maryland’s Executive Order created an AI subcabinet charged with facilitating statewide coordination on the responsible, ethical, and productive use of AI. Its work included recommending approaches and state policies.
Legislation – State lawmakers can enact legislation to require state entities to create and follow an AI decision-making process, either through direct statutory language or by tasking a state agency to develop policy and implementation guidelines.
- The New York state LOADinG Act required legal authorization for the use of automated decision-making systems by state agencies and required the publication of an impact assessment for any authorized AI use.
- Connecticut’s Public Act No. 23-16 directed the state’s Office of Policy and Management to develop Connecticut’s AI Responsible Use Framework. It also instructed the Department of Administrative Services to inventory all AI systems.
- Maryland enacted the Artificial Intelligence Governance Act of 2024 and required each executive agency to appoint an AI lead and for the State Department of Information Technology (DoIT) to work with the new AI subcabinet. The DoIT then issued the State of Maryland’s Responsible AI Policy and implementation guidance.
Recommendation 3. Provide Support Structures for State Agencies
State leaders should ensure that there are structures to support state agencies to operationalize the people-centered decision-making process, including conducting diverse community outreach, evidence-based AI Impact Assessment, and quantitative and qualitative evaluation.
This support can come from a variety of sources. State leaders should provide funding for existing staff or agencies to serve as point people, creating a diverse AI board, partnering with academic institutions to provide expertise, or a combination of these strategies.
- In California, the Governor designated multiple state agencies to work on AI implementation. The state government also partnered with academic institutions including UC Berkeley and Stanford to convene an AI Summit bringing together stakeholders from labor, business, nonprofit, academia, and technology companies. This summit convened a series of workshops with grassroots organizations and diverse community members to gather input on AI use and potential policies for assessing impact on vulnerable communities. In December 2025, the Governor also launched the California Innovation Council, an initiative to tap “California’s best and brightest to advance responsible AI.”
- In Maryland, the Governor established an AI subcabinet by executive order and state leaders enacted legislation for the state Department of Information Technology (DoIT) to work with the new AI subcabinet. The state issued a Responsible AI Policy that includes roles and responsibilities for the DoIT, the AI subcabinet, and each executive agency. The DoIT implementation guidance also helps state agencies understand, operationalize, and follow the AI Policy. Each agency has a designated AI Lead and the DoIT has an AI team that holds weekly office hours and answers questions that agencies may have about using AI and following the state’s AI policy.
Recommendation 4. Ensure the Process is Followed Through with Transparency, Accountability, and Oversight
It is also essential for state leaders to make sure the decision-making process does not just work on paper, but truly translates into people-centered transparency, accountability, and oversight of AI systems.
Any legislation, executive order, or agency guidelines should provide for public and private enforcement mechanisms so people can take action if rules are not followed. State leaders should also require a public inventory, updated at least annually, of all AI systems so the public knows what is in use. As discussed earlier, all assessment materials need to be publicly published in a timely manner during the process.
After the decision-making process is completed, state leaders should ensure that any agency that moves forward with an AI system is required to establish a robust use policy that will help protect people from abuse, misuse, and mistakes, with ongoing evaluation of the benefits and harms of the AI system. Developing a robust use policy is outside the scope of this memo, but please see the FAQ section for some resources.
Conclusion
State leaders can make AI work for people.
The future of government use of AI is still being written, and state governments have a powerful role to play. What we do now will help determine whether the power of AI will work for or against people’s rights and dignity.
If AI is to serve rights, justice, and democracy, leaders at the state level must act to implement a people-first process that centers diverse community members and asks and answers foundational questions about “why” and “whether” to use AI before skipping to the “how” of AI implementation. The recommendations in this memo help state leaders meet this moment and ground decision-making about AI use in fairness, accountability, evidence-based inquiry, and inclusive governance.
The views and opinions expressed herein are solely those of the author and do not necessarily reflect the views, positions, or policies of any organization, employer, board, institution, client, or other entity with which the author is affiliated.
- Connecticut’s 2023 Act Concerning Artificial Intelligence, Automated Decision-Making and Personal Data Privacyrequired each state agency to inventory all uses of AI systems and mandated a process for evaluation. The state developed an AI Responsible Use Framework that requires each agency to conduct an AI impact assessment before implementing an AI system. It also created an Advisory Board that evaluates agency adoption of AI systems.
- California issued State Guidelines for Evaluating Impacts of Generative AI on Vulnerable and Marginalized Communities in December 2024 and directs state agencies to use these guidelines early in the AI consideration process, when assessing readiness and prior to initiating a procurement process. The guidelines provide an equity evaluation checklist where state agencies identify the communities potentially impacted by the AI system, conduct community outreach, and identify the potential forms of bias, mechanisms of oversight, and a process for transparency. These guidelines currently only apply to Generative AI systems, not all AI systems, and many of the provisions are recommendations, not requirements. On March 30, 2026, California Governor Newsom issued Executive Order N-5-26 that provides stipulations for AI procurement and contracting to prevent discrimination and harm to civil rights, among other issues.
- Maryland issued a Responsible AI Policy in 2025 that creates a governance framework for all AI systems, which includes an intake process, impact assessment, and other processes. It also prohibits real time biometric surveillance, social scoring, emotion analysis, fully automated decision-making procedures, and behavioral manipulation.
- New York State’s 2024 LOADinG act requires that all existing AI systems be disclosed and prohibits the future or ongoing use of any AI system that has not been evaluated using an impact assessment and found to be safe and free from discrimination.
- Colorado’s Consumer Protections for Artificial Intelligence took effect on February 1, 2026, and requires both developers and deployers of artificial intelligence to disclose and preempt potentially dangerous use of the system in question through variety of stipulations, including the completion of an impact assessments.
- The Texas Responsible Artificial Intelligence Governance Act limits dangerous AI practices like social scoring, behavioral manipulation, discrimination, and biometric identification.
There have already been marked gaps in how “high risk” is interpreted. California enacted a law mandating annual inventory reports on all high-risk automated decision systems in use by the state. The report that the California Department of Technology issued identified no high-risk systems in use, despite publicly available examples of potentially worrisome ADS systems employed by different California agencies.
- AI Now – Algorithmic Impact Assessments Report: A Practical Framework for Public Agency Accountability
- Carnegie Endowment for International Peace – How Cities Use the Power of Public Procurement for Responsible AI
- Center for Democracy and Technology – AI Governance Checklist for Elected Officials: Advancing Responsible AI Adoption and Use in the Public Sector
- Data & Society – Democratizing AI: Principles for Meaningful Public Participation and Driving Change in Public Sector Technology through Community Input
- GovAI Coalition – Policy Templates and Knowledge-Sharing Tools
- Federal Office of Management and Budget – Advancing Governance, Innovation, and Risk Management for Agency Use of Artificial Intelligence
- Local Progress Impact Lab and AI Now – Local Leadership in the Era of Artificial Intelligence and the Tech Oligarchy
Empowering Communities through Community Benefit Agreements in AI-Fueled Data Center Development
The United States is experiencing an unprecedented surge in data center construction driven by AI infrastructure demand. Over 5,000 facilities are operating today, with investments of $400 billion in 2025 and an estimated $1.8 trillion in between 2024 and 2030. This capital is arriving faster than environmental review processes, utility planning cycles, and community engagement frameworks were designed to accommodate. The consequences for communities are serious and well-documented: rising electricity bills, massive water consumption, e-waste, noise and light pollution, and billions in tax subsidies to some of the world’s most profitable corporations — often without meaningful public disclosure. These harms do not fall evenly, with communities of color and low-income neighborhoods already carrying disproportionate burdens.
Community Benefit Agreements (CBAs) are a legally binding, enforceable tool that allows communities to secure real commitments from data center developers before development proceeds. When properly structured — with specific numeric targets, secured financial obligations, independent monitoring, and meaningful enforcement — CBAs transform data center deals into durable community partnerships. Drawing on practitioner expertise from dozens of negotiations across sectors, emerging AI data center agreements, and new research on community harm and regulatory gaps, this memo makes the case for CBAs and provides a practical policy playbook for using them effectively, including potential provisions and considerations like enforceable harm mitigations, meaningful community investment, and lasting accountability mechanisms, to surface broad community needs while remaining adaptable to local contexts.
Challenge and Opportunity
Harms to Communities from Rapid Expansion of AI Infrastructure
U.S. data centers consumed 183 TWh of electricity in 2024 – more than 4% of total national consumption and roughly equivalent to the annual electricity demand of Pakistan, with it only projected to grow larger – roughly 17% more by 2030. A typical AI-focused hyperscaler consumes as much electricity as 100,000 households; the largest under construction are expected to use 20 times as much. The scale is such that AI data center demand in Virginia alone contributed to an 833% increase in regional capacity market auction prices – what electricity utilities and grid operators pay to ensure there will be enough power generation available during peak demand periods – for 2025–2026. These pressures do not just translate directly into costs for ordinary ratepayers but because these are structural costs baked into the grid, they also make it harder for communities to see, contest, or hold anyone accountable for the surge. Electricity prices in some data center-heavy regions have surged over 250% in five years, with estimates predicting data center electricity demand could double–or even triple–by 2028.
The scale of harm to nearby communities extends beyond electricity prices: increased water usage, e-waste, air and noise pollution, and adverse health effects. A single large data center can use up to 5 million gallons of water a day (with about a quarter of the usage from direct cooling), equivalent to a city of 50,000 people. Additionally, hardware disposal is projected to generate 1.2–5 million metric tons of e-waste from generative AI alone between 2020 and 2030. Diesel backup generators – utilized at almost every facility – emit particulate matter classified by the EPA as a likely human carcinogen. Diesel generators emit harmful nitrogen oxides 200–600 times more than natural gas plants per unit of electricity produced. Researchers estimate that data center backup generators in Virginia, operating at just 10% of permitted levels, could already cause 14,000 asthma symptom cases and 13-19 deaths annually, with public health costs of $220–$300 million per year spreading across multiple states – and communities of color, low income communities and rural communities paying the bulk of that price.
But perhaps the most underappreciated community harm from the data center boom is fiscal: the extraordinary scale of tax subsidies that state and local governments have extended to some of the world’s most profitable companies, frequently without meaningful public disclosure or community input. Good Jobs First, which tracks corporate subsidies nationally, found that in 10 of the 20 states disclosing data center subsidy costs, programs cost over $100 million per year. Further, the opacity of these arrangements is striking: of 36 states with data center subsidy programs, only 11 publicly disclose which companies receive benefits. Virginia, the world’s largest data center market, for example, forgoes nearly $1 billion annually in state and local revenue without telling the public which companies receive the money or how much each receives. Not to mention, data centers, once fully built and operational, employ on average only 157 permanent workers – an extraordinarily low jobs return on billions in public subsidy – averaged $1.4 million to $2.1 million in subsidies per permanent job. Additionally, companies frequently hide behind non-disclosure agreements (NDAs) avoiding public input and scrutiny, especially on critical details about energy use, water consumption, and sometimes even the identity of the data center operator.
Centering Community Needs in AI Infrastructure Development
As data centers have proliferated and these harms are starting to be documented, so has grown the backlash against new developments. Data Center Watch, which tracks grassroots opposition to large-scale projects across 28 U.S. states, found that between May 2024 and March 2025, $64 billion worth of data center projects were blocked or delayed by local opposition. In Q2 2025 alone, more project disruptions occurred than in the previous two years combined. Opposition is bipartisan and geographically broad. Recent nationwide polling found that a whopping 70% of Americans oppose a data center construction nearby, with nearly half “strongly” opposed – a far lower acceptance rate than for gas plants, wind farms, or nuclear facilities.
This issue is an urgent priority now because while public concern over rising energy rates, water usage, and unchecked development is growing, no comprehensive mechanism currently exists to align the interests of communities, developers, and local governments.
As AI companies promise us the large-scale and incredible societal benefits to come from AI, they can show they are serious by starting with making sure the data centers they are building to power the AI future benefits the communities they’re in.
Why Community Benefit Agreements?
CBAs are legally binding agreements, negotiated between developers and community stakeholders, that secure enforceable commitments before development proceeds. Adapted from their successful use in bank merger oversight (under the Community Reinvestment Act) and clean energy project approvals, CBAs can:
- Establish environmental monitoring and reporting requirements more stringent than applicable permits.
- Secure financial contributions to community investment funds, backed by letters of credit that allow enforcement without costly litigation.
- Lock in local hiring commitments with specific numeric targets and apprenticeship pipelines.
- Create Community Advisory Boards with real authority and ongoing oversight throughout the life of the project.
- Make transparent what would otherwise remain hidden: water consumption, energy use, tax benefits, and environmental commitments.
In the absence of broader legislative and regulatory protections, CBAs offer a promising, underutilized and legally binding tool to ensure adequate harm mitigation and potential for communities to share in the opportunities, and not just the costs, of AI infrastructure; with the additional benefit of being able to be tailored specifically to a community’s needs.
For instance, in late 2025, the city of Lancaster negotiated a legally binding CBA with the developers of the Lancaster AI Hub before construction was finalized, securing $20 million in community contributions. Key wins include a hard cap of 20,000 gallons per day of municipal water use per campus, a 100% clean energy requirement backed by tiered financial penalties of up to $10 million per building, strict noise limits tied to pre-construction ambient levels, and full public records transparency.
The agreement also commits developers to a local hiring plan, free first-responder training, and ongoing community engagement — demonstrating that municipalities can extract meaningful, enforceable protections from data center developers when they engage before key approvals are locked in. Of note, the city is the negotiator of the CBA in this case, but the same negotiations and provisions can be won in a legally binding CBA through communities themselves as well – working with community leaders, community-based organizations, and local policymakers with enforcement mechanisms woven in for effectiveness.
Importantly, CBAs do not require communities to support a project. They are negotiated exchanges. If a developer will not make commitments adequate to the community’s concerns, opposition — including calls for moratoriums — remains a legitimate and more appropriate response. The credibility of that alternative is precisely what gives CBA negotiations their teeth.
Especially while policymaking, legislation and other broader reforms can take time; in their absence, CBAs can be a particularly useful interim governance mechanism to meet the urgency of this moment.
Why now?
Hyperscalers are urgently racing to secure sites, power contracts, and permits to meet AI demand. Given that the time to power is crucial for the data center companies, it gives communities and municipalities genuine leverage right now, alongside the need, urgency, and tools/resources to be able to engage. Data center developments face political opposition that is delaying billions of dollars in projects. They need community support, or at minimum community acquiescence, to move through permitting processes that would require public hearings, board votes, and environmental reviews .
With the scale of projected and current investments in the billions of dollars, and their effects in communities already being felt with more to come, and especially as broader reforms that are slower to move are not yet in place, CBAs are not just a useful interim governance policy tool that can fill this currently urgent need, but now is also the time of maximum policy leverage.
Plan of Action
States should not rely on voluntary developer promises. They should create a statutory and regulatory framework that makes robust CBAs a condition for approval or subsidy in high-impact data center projects.
We recommend CBAs be utilized as a potential policy tool for facilitation and solutions-building to meet community, developers’, and local governments’ tripartite objectives, under defined conditions. Local policymakers should treat CBAs as a lever that enables communities to provide direct input, occupy an established space to negotiate impacts and mitigations, and secure reinvestment in ways that benefit the community.
Local governments can require CBAs (working alongside community-based organizations and other community leaders) if developers apply for permits, zoning, or other approvals to build out data centers – such that planning departments, zoning boards, or city councils can condition approval on compliance and can then impose penalties, delay permits, or revoke approvals if terms aren’t met.
The following recommendations highlight specific ways and provisions that policymakers at the local governmental level (like the City of Lancaster for the Lancaster data center CBA) and community-based organizations advocating and negotiating on behalf of communities can utilize in their efforts to protect communities from harm and establish some fairness, transparency and accountability in the data center development process. As others like the Brookings Institute and National Association for the Advancement of Colored People (NAACP) have substantially outlined and advocated for, they represent emerging best practices at this juncture. Key provisions alongside their criticality are also summarized in Summary Table 1 at the end of this proposal.
Recommendation 1. Policymakers (and CBOs and community leaders negotiating on behalf of communities) should utilize specific provisions to address harms and provide mitigations, to increase transparency, and to steward ongoing governance and accountability.
Harm Remediation
- Prohibit cost-shifting of energy rates to ratepayers. The impacts on electricity affordability, grid infrastructure, and ratepayers resulting from the proposal’s energy demand are some of the harms that are closest to communities. Measures intended to prevent or offset disproportionate burdens on residential customers and frontline communities, including developers fronting the costs of any infrastructure upgrades and interconnection, or creation of a new rate class (like in Oregon or Virginia) for data centers.
- Require developers to go beyond regulatory compliance on environmental protections. The Lancaster CBA specifically with data center developers requires selective catalytic reduction on generators. In California, the California Environmental Quality Act (CEQA) required and negotiated mitigations have included fence-line monitoring, health risk assessments, and restrictions more stringent than state permits. Every CBA should include independent real-time air monitoring with publicly available data, a community health fund financed by the developer, and diesel emission standards that go beyond what permits require.
- Require prioritization and usage of clean energy. Lancaster CBA, for instance, requires 100% clean sourcing required, with tiered penalties of $2.5M–$10M per building backed by a $10M Letter of Credit, and penalty proceeds directed to a Sustainable Development and Clean Energy Fund. Add third-party Renewable Energy Certificates (RECs) verification and prohibit characterizing REC purchases as equivalent to direct clean energy generation without explicit disclosure. In the absence of full clean energy sourcing, energy ratcheting over time should be utilized.
- Set a hard numeric cap on water usage with public reporting. Given the documented conflicts over water in drought-prone regions, water provisions are increasingly among the most contentious and most important elements of data center CBAs. Lancaster CBA’s 20,000-gallon-per-day municipal water cap per campus, combined with closed-loop cooling requirements, is a strong model. Add quarterly public consumption reporting and a renegotiation trigger if operations expand beyond the scope contemplated at execution.
Transparency, Governance & Accountability
- Mandate public dashboards with ongoing reporting. These should include water usage, energy usage, as well as pollution metrics like the amount of time spent on backup diesel generators or noise decibels.
- Require full public disclosure of all tax incentives, Payments in Lieu of Taxes (PILOTs), and government subsidies received by the developer. Given that 25 of 36 states with data center subsidy programs do not disclose recipients, communities must insist on transparency in the CBA itself.
- Conduct impact assessments, including equity impact assessments.
- Create a Board with real enforcement authority. Every CBA needs a Community Advisory Board (CAB) with seats for environmental justice representatives and community residents (not just officials), with the authority to commission independent audits, defined financial penalties for violations, and a right to seek injunctive relief directly, as well as the responsible entity for the community fund.
- Make enforcement penalties for violations clear and escalating. Community negotiators should insist on specific, escalating financial penalties for violations — not vague remediation language — with enforcement authority vested in the CAB.
- Include sunset and renegotiation triggers. Include mandatory renegotiation at five-year intervals or upon material changes in facility scope, ownership, or energy consumption. There should also be clear processes outlining any potential decommissioning and long-term liability to avoid stranded assets with locals being left footing the bill. These could look like, including decommissioning bonds (tied to facility footprint or power draw) posted at execution, a funded remediation escrow, and a specific site restoration timeline.
Recommendation 2. Policymakers and CBOs negotiating on behalf of communities should require investment in communities as a baseline condition for any equitable agreement.
Beneath the gold rush of data centers and AI lies real places, real people, and real resources being quietly consumed in service of extraordinary profits. The companies cashing in are among the wealthiest in history — and that wealth is being built, quite literally, on local communal foundations: their land, their water, their power grids, their roads, their first responders, and their environment. The economic rewards generated need to reflect that. Communities supplying these resources and shouldering associated burdens cannot be sidelined as the immense profits generated flow elsewhere.
Aside from harm remediation, CBA, in its associated prep and processes, can serve as a platform to uncover, understand, and platform broad community needs. There should be specific provisions that specifically seek to address these needs, to ultimately move towards a more balanced and equitable distribution of the costs and benefits associated with AI development in the community, given the wide ramifications of data center developments in host communities.
- Establish a Community Fund: CBA community funds can support locally-determined priorities such as broadband access, AI and digital literacy programs, just transition pathways with apprenticeships and training, healthcare, quality of life upgrades like parks and art ensuring that the wealth generated by AI infrastructure is reinvested in the communities hosting it. They can also be utilized to offset any ratepayer costs of infrastructure upgrades that are spread outside of the data center developers. Critically, Nondisclosure agreements (NDAs) on government incentive terms must be prohibited, ensuring that subsidy arrangements are publicly accessible and communities can assess whether tax concessions are being offset by CBA commitments.
- Set Numeric Workforce Targets and Prohibit Misclassification: Workforce provisions should include specific local hiring targets – typically 30–50% of construction labor hours from defined geographies – written into the CBA itself rather than deferred to post-execution plans. Because operational data centers average only 157 permanent employees, workforce provisions should focus primarily on the construction phase, while leveraging the developer’s long-term presence to fund broader workforce training initiatives, including AI just transition opportunities, in the community.
- Secure Financial Commitments with Letters of Credit: Payments should be secured by a Letter of Credit or corporate guarantee from a sufficiently capitalized entity, with payment triggers tied to specific construction and operational milestones. For example, Lancaster commits $20M total, secured by a $20M Letter of Credit or corporate guarantee from a $100M+ net-worth entity, with payments triggered at construction financing and operations commencement per building.
- Explore Diverse Community Wealth-Sharing Mechanisms: Beyond direct cash funds, CBAs can incorporate a range of wealth-sharing tools such as community land trusts, local equity stakes in the facility, revenue-sharing agreements tied to facility profits, or dedicated funds for affordable housing and small business development – ensuring communities build lasting economic power rather than receiving one-time payments.
- Address AI-Specific Infrastructure Concerns: Although not as common yet, CBAs can also consider specific provisions addressing AI operations, data sourcing practices, and the risks of long-term infrastructure lock-in associated with AI systems.
Recommendation 3. Policymakers (and/or community negotiators) should proactively identify and put the supporting mechanisms in place for meaningful representation, negotiation, enforcement, and accountability.
The most common CBA failures are not in the provisions communities demand – they are in process and enforcement structure. When poorly structured, or negotiated after key approvals are in hand, they can give the appearance of community benefit while delivering very little.
There are certain necessary conditions, dependencies, and actionable sub-recommendations for CBAs to be effective such as investing in and strengthening community-level organizing and coalition-building, providing training and workshops on provisions and negotiations, and critically, providing thoughtful representation to prevent takeover, and building robust enforcement mechanisms for delivery of benefits in practice. Looking back at the legal history and utilization of CBAs in the bank merger approval process and CEQA “Opt-In” process in CA that requires a CBA, we have gleaned some important lessons about levers, enforceability, and accountability, as well as recommendations on the negotiation and power-building process, listed below.
- Negotiate Early. Treat CBA execution as a precondition of permitting support as negotiating leverage is greatest before approvals are granted. Work with local government officials to make clear to developers that permitting support is conditioned on a satisfactory CBA. The Lancaster CBA was negotiated after zoning opinions had been issued and demolition had begun, and its gaps (no specific hire targets, no independent community board, no air monitoring) directly reflect that reduced leverage.
- Build a United Coalition. Organize internally before engaging the developer, presenting a united front through a Community Advisory Board and a mediator if necessary – the coalition should exclude both intractable opponents and members prepared to support the project without a CBA.
- Establish Ground Rules First. Before negotiating specifics, use a memorandum of understanding (MOU) to set the terms for timeline, information-sharing, representation, and dispute resolution. This also prevents developers from selectively engaging sympathetic stakeholders while sidelining community members most directly affected.
- Secure Legal and Technical Representation, ideally with cost-recovery agreement with the developers. Hire legal counsel with energy and environmental expertise and a technical expert to interpret site assessments, emissions modeling, and energy projections – unrepresented communities are structurally disadvantaged at the negotiating table. Negotiate a cost-recovery agreement requiring the developer to pay for community-selected legal counsel and technical experts, a practice well-established in permitting and utility interconnections that should become standard in CBA negotiations.
- Require Developer-Funded Community Review. Ask the developer to fund community technical review – a precedent well-established in CEQA practice. It can be coupled with the negotiation including a due diligence phase, where documentation is provided to the community coalition to review and provide recommendations.
- Demand Numeric Targets, Not Aspirational Language. Replace “good faith efforts” and vague commitments with specific, measurable targets subject to annual reporting and financial penalties for non-compliance, as bank merger advocates successfully did with dollar-denominated, geo-specific lending commitments.
- Prohibit NDAs on Environmental and Financial Data. Do not allow nondisclosure agreements on monitoring data, permits, consumption reports, or government incentive terms – the notorious Memphis xAI case, in which more than 30 unpermitted turbines operated in secret with health and environmental consequences for the community, illustrates the consequences of unchecked secrecy. Lancaster’s CBA also correctly designates the CBA as a public record under Pennsylvania’s Right-to-Know Law.
- Negotiate CBAs and PILOT Agreements Together. CBA and payment-in-lieu-of-tax agreements (PILOT) must be negotiated in tandem with a cap on total payments, ensuring community investment funds supplement, and do not substitute for, any expected tax revenue.
- Specify Any Fund Governance in the Agreement. Ambiguous collective fund governance renders financial commitments meaningless – specify committee composition, voting rules, permitted uses, and annual reporting directly in the CBA.
- Frame Agreements Around Impact Mitigation, Not Approval. Require developers to first identify community concerns and propose mitigation before discussing payments. Framing money as the price of approval produces smaller commitments and less community ownership of outcomes.
- Know When CBAs Are Not the Right Tool. CBAs cannot substitute for strong environmental permitting, transparent subsidy disclosure, or robust utility regulation, and should not be pursued when permits are already in place, transparency has been denied, or a developer-backed document is being falsely presented as a community agreement. There are plenty of situations where opposition or moratorium might be more appropriate. Know the limitations of CBAs – their scope is limited to what the contracting parties agree to, and their enforceability depends on clear terms, specific metrics, secured financial obligations, and parties with the legal standing and resources to enforce them.
Conclusion
The extraordinary wealth generated by the AI data center boom is being built on community land, water, electricity, and environmental capacity. Yet, the communities bearing these burdens are seeing little of the benefit. The hyperscalers behind this buildout are among the most valuable companies in human history, and the AI services running on this infrastructure will generate billions in revenue. None of this wealth is created in a vacuum: it is created in specific places, using specific community resources, and the communities providing those resources deserve a meaningful share of the value they help create.
The current pattern in which vulnerable communities absorb the largest burdens, profitable companies receive the largest subsidies, and benefits flow primarily to shareholders, is neither inevitable nor acceptable. It reflects choices being made right now, as the buildout accelerates and the patterns of harm and benefit are being set. CBAs are a tool to make different choices: to insist that the communities hosting AI infrastructure share genuinely in its benefits, and that the costs of that infrastructure – to air quality, water systems, grid reliability, and community character – are borne by those who profit from it, not by those who simply happen to live nearby. The time to act is now.
Lancaster, PA, 2025
- The City of Lancaster negotiated a legally binding CBA with the developers of the Lancaster AI Hub before construction was finalized, securing $20 million in community contributions. Key wins include a hard cap of 20,000 gallons per day of municipal water use per campus, a 100% clean energy requirement backed by tiered financial penalties of up to $10 million per building, strict noise limits tied to pre-construction ambient levels, and full public records transparency. The agreement also commits developers to a local hiring plan, free first-responder training, and ongoing community engagement — demonstrating that municipalities can extract meaningful, enforceable protections from data center developers when they engage before key approvals are locked in.
Nashville MLS Soccer, Nashville, TN, 2018
- A coalition called Stand Up Nashville successfully advocated for this CBA in connection with a soccer stadium development project. The CBA includes, among other things, commitments on jobs that pay a living wage, hiring priorities, affordable housing, and a childcare center. As part of this CBA, Stand Up Nashville’s committed to support rezoning legislation for the stadium, which was widely opposed before the CBA. Nashville’s Mayor eventually supported the stadium project in large part due to the CBA.
Facebook Campus Expansion CBA, Menlo Park, CA, 2016
- This CBA, associated with an office expansion, is between Facebook and a coalition of community groups. In this agreement, Facebook made an almost $20 million commitment to affordable housing in the area, which led to an additional $60 million in other donor commitments.
Brookings: Why community benefit agreements are necessary for data centers | Brookings
NAACP: CBA Template for Data Centers
Good Jobs First: Key Reforms: Community Benefits Agreements
Kapor Foundation: The Unequal Burden of Data Centers
AI Now Institute: North Star Data Center Policy Toolkit: State and Local Policy Interventions to Stop Rampant AI Data Center Expansion
From NAACP’s CBA Guide
In practice, this can mean: 1. The initial agreement pays for legal counsel and technical support, selected by and managed by the community coalition. 2. The next phase is either: (1) an agreement to establish binding requirements for transparency, impact studies, labor standards, and equity protections, which is contained in Article 3 of the template; OR (2) a due diligence phase, which requests information provided in Article 3. 3. An amendment is negotiated after the community has access to impact information on electric, environmental, housing, and infrastructure demands, which could be an amendment specifying the exact dollar amounts and project-specific mitigation measures. This approach allows communities to understand the scale and type of impacts before finalizing the financial structure of the Community Benefits Agreement, while maintaining leverage and ensuring that non-opposition is tied to a complete, enforceable package of commitments.
From PolicyLink CBA Toolkit:
Unless developers face significant public pressure and/or legal leverage that jeopardizes public
approval, developers are unlikely to compromise. A coalition may exert leverage to bring the developer to the table in a variety of ways: direct lobbying of elected officials and city staff, notifying any reporters covering the issue that the community has significant concerns, using social media to amplify the community’s voice and raise support, protests at the worksite or at City Hall, or artist-led community responses, like chalk art at the site or near City Hall.
Stakeholders & Roles:
A community coalition can include stakeholders such as: Individual residents, Neighborhoods councils, Faith groups, Local non-profits, Local businesses, PTAs, Housing advocates, City administration staff and elected leaders can demonstrate inclusive leadership by (i) providing transparency around the project; (2) insisting on broad community support for project approval; (3) encouraging CBA negotiations, without trying to influence them. 2-4 coalition representatives should contact the elected officials (or city council staff) most involved in the proposed project and brief them on the coalition, its priorities, and any engagement it has had or plans to have with the developer. The coalition representatives should ask that the officials condition a vote in favor of the project upon the developer’s support for the coalition’s priorities.
Elected officials can be an important ally in a CBA negotiation because they can persuade their colleagues on council to delay a vote on the project to allow more time for the coalition to negotiate with the developer. They can also apply pressure on the developer to reach an agreement with the Coalition. The coalition should assess whether it can count on commitments of support from a majority of the committee and/or council members. Particularly if a coalition new, support from key elected officials will help bring developers to the table. It may be necessary to take legal action against objectionable aspects of the development to inspire a willingness to negotiate.
Settlement Wins Against Big Tech Should Underwrite Digital Resilience Funds
Historically large penalties have been insufficient in crafting durable and effective deterrence against corporate wrongdoing. A better approach has bedeviled regulatory enforcers, legislators, attorneys general, and the judiciary. This challenge has been especially acute as enforcers have attempted to rein in the worst violations of the largest technology companies as we transition from the social media era to the AI era. Company scale and market power allow them to absorb even historic penalties as the cost of doing business, blunting the effectiveness of civil litigation and regulatory fines.
The stakes for more effective deterrence and a more robust remedies toolkit are rapidly compounding. Many emerging AI related harms, including AI induced psychosis, maladapted socialization, deepfake driven bullying and harassment, suicide coaching, and declines in children’s literacy bear the hallmarks of a public health crisis or environmental disaster rather than just discrete consumer injuries. The scale of these externalities invites greater prosecutorial and regulatory scrutiny but also demands a more creative enforcement playbook. When historic fines against these companies and their predecessors disappear into general treasuries those funds remain largely inert instead of helping the public defend itself.
Injunctive relief and headline fines are important enforcement mechanisms but if enforcement is to reach its deterrent potential and protect the public in the advanced algorithmic era, we must recognize that penalizing corporate misconduct is only half the battle. By allocating funds from tech settlements to investments in broad-based consumer education, digital literacy, independent researchers, or new enforcement and investigatory infrastructure, state attorneys general and the judiciary can transform these otherwise inert dollars into a sustained and active defense against digital harms.
Challenge and Opportunity
The Federal Trade Commission’s historic $5 billion settlement with Facebook in 2019 is perhaps the clearest example of a broken enforcement model. At the time of its announcement, the penalty was the largest ever imposed by the FTC on a company for violating consumer privacy. Even as a majority of the Commission approved the settlement Commissioners Rebecca Slaughter and Rohit Chopra warned in their dissents that the penalty was unlikely to meaningfully deter the company or the broader market. They were right. The settlement imposed some compliance obligations, but none challenging its underlying business model of aggressive data harvesting. The company’s stock price rose after the announcement. Within a few years the FTC sought to reopen its privacy orders against Meta over subsequent alleged privacy violations, illustrating the failure of the penalty to sustainably alter corporate behavior.
The Facebook settlement was hopefully the high watermark of a certain kind of enforcement paradigm. Fines should be larger. Behavioral and structural remedies should be stronger and imposed more often. Vital work has been done to turn that page and institute meaningful controls on data abuses and exploitative design. But, as we continue to use fines and penalties we have to confront a limitation in the enforcement model. When those dollars disappear into state or federal treasuries they do little to address systemic technological disruption. To protect the public, enforcers can put settlement dollars to work. We need to invest directly in the public so our society is prepared to handle this wave of technological disruption.
Inert Fines, Federal Constraints, and State Action
What if the $5 billion Facebook settlement had been put to better use?
Imagine if even a portion of those funds had supported a sustained nationwide consumer education effort on the harms of social media use and digital literacy? A fraction of that money could support public education campaigns teaching about manipulative design practices and how we can take our autonomy back. The fine itself only punished the company’s past conduct on the supply side; investing that money in public education could have helped shift the demand side, changing the user behavior in the market that made these products profitable.
Instead, like most federal settlements, by law that money flowed straight from Facebook directly into the federal treasury. Federal enforcers have limited ability to direct those funds towards targeted public education or resilience efforts (with the notable exception of the Consumer Finance Protection Bureau (CFPB) which is allowed to direct civil penalties to a special consumer education fund).
While Federal regulators like the Federal Trade Commission and the Department of Justice have obtained some landmark penalties, state attorneys general have increasingly become the primary defenders of Americans’ digital rights. In recent years the states have secured billions of dollars through aggressive enforcement: A $700 million settlement over Google’s app store practices; $391.5 million in a multistate effort over deceptive location tracking; $1.4 billion from Meta for “using facial recognition without users’ permission”. The list goes on.
Crucially, state attorneys general have different constraints on how civil penalty funds may be used. Many states have their own Unfair or Deceptive Acts or Practices (UDAP) statutes, in addition to a variety of consumer protection laws. Under common law practice and state statutes many AGs have more leeway in directing their settlement funds to organizations and causes “consistent with the objectives and purposes of the underlying cause of action”. Through multistate settlements, AGs have repeatedly demonstrated their ability to coordinate enforcement and reshape industry practices on a national scale.
But, it’s fair to ask: how much will even a $1.4 billion payout change a company’s underlying market incentives and consumer behavior? What might that $1.4 billion accomplish if even a portion were invested in changing consumer behavior through consumer education, digital literacy, independent research, and resilience building?
Crafting forward looking structural and behavioral remedies in a fast-changing industry is important and difficult. It was only in the past few years, decades into the internet era, that the Federal Trade Commission embraced data minimization and algorithmic deletion as the appropriate remedies for data abuses. Finding the appropriate remedies for AI related harms is crucial work, but will take time. If we put the dollars to work, negotiated settlements can help build deterrence and prevention right now.
Successful Lawsuits Against Defective Algorithms, Addictive Product Design
Recent state-level actions prove we can change the enforcement paradigm. Two recent cases target the root of these digital harms: defective algorithms and addictive product design. By framing these platforms as defective products engineered to exploit children, enforcers have bypassed the traditional tech liability shield. This breakthrough could open the floodgates for systemic accountability.
In March, a California jury awarded a 20 year old plaintiff $6 million after finding that Meta and YouTube negligently designed their platforms and caused severe mental health crises under a theory of defective products liability. In the same month a New Mexico jury levied a historic $375 million penalty against Meta for violating the state’s Unfair Practices Act by misleading parents about the safety of their products thereby enabling child exploitation.
These verdicts could be bellwethers for a wave of impending litigation and settlements. Currently, a historic and “sprawling” set of consolidated lawsuits, known as Multidistrict Litigation (MDL) 3047 is proceeding in Federal Court. This lawsuit includes 41 attorneys general, hundreds of school districts, thousands of individual personal injury suits, all consolidated and contesting the “‘unreasonably dangerous’ design of social media platforms.”
These cases, and others, mean billions of dollars may soon be changing hands. The critical policy question for state enforcers is whether those funds, after class members and direct victims are made whole through restitution, will disappear into general treasuries or be used to address the real problems at hand.
Plan of Action
Putting Settlement Dollars to Work
We propose putting settlement dollars to work through the creation of a Digital Resilience Fund. This is not a radical departure from current enforcement norms. Rather, it’s a call to accelerate adoption of a model, such as the Truth Initiative, which informs this proposal, that’s been successfully deployed across other industries, as seen in Table 1.
In each of the cases in Table 1 enforcers recognized that penalties alone weren’t sufficient to ameliorate the harm from the underlying legal violations. Settlement dollars disappearing into general treasuries would have been a disservice. As victim advocates frequently note, one of the most profound ways to honor victims is by preventing others from becoming victims, whether the threat is from opioids, unlawful financial practices, smoking, or pollution.
Further, the time to act is now. The public is already convinced there’s a problem with AI accountability. Recent Gallup polling reveals a fascinating paradox regarding the next generation of consumers. While over half of Generation Z uses generative AI on a weekly basis, their optimism about the technology is plummeting. They are increasingly anxious about the technology’s impact, with majorities expressing fear that AI will come at a high cost to human creativity, critical thinking, and learning. The public can feel the ground shifting, but lacks the tools to fight back.
Recommendation 1. Establish a Digital Resilience Fund
The previous examples of settlement agreements all exemplify an important principle: settlement dollars ought not to be inert. Directing the spend on those dollars is an additional tool in the toolkit of deterring corporate wrongdoing, mitigating digital and AI harms, and hardening society to deal more effectively against disruptive technology. An educated public acts as a deterrent and could help steer the market towards deploying technologies that serve, rather than exploit their users.
State AGs alone, or in concert with each other, or with legislators, can begin redirecting a portion of major technology settlement proceeds into a fund focused on education, research, and harm mitigation related to AI. These funds could be administered through an independent nonprofit (like the Truth Campaign), through an existing public foundation structure, or through state-level grant programs (like the Opioid Abatement funds). The precise institutional form is less important than the principle that settlement or fine dollars tied to AI related harms ought to be used to build society’s capacity to stop or withstand those harms.
What a Digital Resilience Fund Could Do
Depending on the size of the settlement and the scope of the underlying harm enforcers and lawmakers could scale these funds across a range of initiatives:
- Fund Counter-Marketing and Awareness Campaigns: A fund could drastically modernize consumer education around technology. The Truth Initiative showed that a well funded and sophisticated campaign can change behavior. To compete against billion-dollar engagement engines, we need compelling communications that resonate with the public. We envision a “touch grass” message delivered with cultural fluency on the social platforms where harms occur – meeting the moment and helping people make different, more informed, choices.
- Support Independent Research and Monitoring: Money for research means we’ll be equipped with a better understanding of how these tools affect behavior and mental well-being. Researchers could also identify evidence-based interventions that help save lives. The research could then be translated into public education materials and materials for evidence-based remedies, regulation, and legislation.
- Support Digital Literacy and AI Education at Scale: Counter marketing can raise awareness, digital literacy can build skills for this media era. This could mean grants to schools, libraries, or community organizations to teach students, educators, and families how AI systems can shape behavior, how to navigate a changing information environment, or how deepfakes can erode trust. As documented by the OECD, a whole-of-society approach to media literacy can be extremely effective against disinformation.
- Act as a Nimble Response Mechanism: As AI tools become more autonomous and agentic, new risks will emerge faster than legislation or litigation can mitigate them. A resilience campaign could launch educator toolkits or literacy campaigns as a first step while legislative efforts and litigation strategies are ongoing.
- Educate and Protect the Labor Force: AI and algorithmic harms will extend beyond social media. For settlements involving hiring software, worker surveillance, or discriminatory models, public education campaigns could also educate workers about their rights. Do professionals who work primarily on computers know that by “using AI” in their daily work, they may be training their replacements? Do they know how to communicate with their coworkers without being surveilled so they can take collective action?
- Establish a multistate investigatory and research apparatus: As comprehensive federal tech regulation remains stalled by gridlock, state enforcers have become the primary defenders of consumer rights. By pooling settlement resources, a coalition of states could establish shared or parallel investigatory infrastructure. Recent initiatives like the Governor’s Public Health Alliance shows that states already have the logistical framework to pool expertise and coordinate parallel responses when federal infrastructure is lacking. This would provide state regulators, AGs, and legislators the dedicated technical expertise, auditing capacity, and ongoing monitoring of the market needed to support future litigation and evidence-based regulation without waiting for federal action.
Together, these recommendations all work to influence cultural change about how our society views AI and evaluates corporate harms. Luckily, we have evidence that this kind of investment can be successful.
The Evidence for Culture Change Efficacy
It’s easy to look back at the 1980s “Just Say No” era and wonder if public education campaigns can actually do anything to change entrenched consumer behavior. But the data tells a different story. Well-funded and targeted campaigns have made a difference.
The Truth Initiative is the gold standard. Instead of dryly lecturing teenagers, the campaign exposed the manipulative marketing tactics of tobacco executives and helped cause a collapse in teen smoking – dropping from nearly 23% in 2000 to less than 2% today. Peer reviewed studies have shown that in just one year the campaign prevented 300,000 kids and young adults from becoming smokers.
The collapse in smoking is a generational public health accomplishment, but other interventions around the world have shown that public education works:
- Finland has used a whole of society education approach for decades to combat disinformation.
- The Real Cost: The FDA has used digital and social media advertising to drive declines in teen vaping.
- This Girl Can: The UK tackled the gender gap in sports, inspiring over 1.6 million women to start exercising by dismantling cultural stigmas.
- Time to Change & It’s Not OK: The UK and New Zealand successfully used massive awareness campaigns to measurably reduce mental health discrimination and shift community norms around family violence.
- Dumb Ways to Die: Australia used a humorous digital campaign to secure a 20 percent drop in transit accidents.
When combined effectively, litigation, regulation, and education have a proven track record of changing social behavior. Protecting the public from the tech industry’s predatory business models and the next wave of AI harms is an enormous challenge, but we have the evidence that trying to build a healthier digital culture is absolutely worth the effort.
Guardrails and Guidance
To maintain public trust and to prevent the misuse of funds any Digital Resilience Fund or similar initiative collects, it must operate under a narrow mandate focused on the remediation and prevention of AI-related harms and follow the best practices set forward in previous settlements. For example, the National Opioid Settlement Agreement provided a list of approved uses for funds focused solely on abatement. Other states have instituted public dashboards to track spending of settlement dollars in a transparent way.
While many AGs already have the authority to direct these funds through settlement agreements, ultimately codifying them through state legislative frameworks may provide greater predictability and transparency for their long-term operation. Legislation may also be necessary to allow fines and penalties, not just settlements, to contribute to the fund in some states.
Conclusion
An informed public is a valuable partner in deterring corporate malfeasance.
Fines must be large enough to penalize lawbreaking, and structural and behavioral remedies must aggressively dismantle harmful corporate practices, especially with regards to the growing power of AI companies. These are the core instruments of any effective enforcement toolkit. However, if we really want to change these companies’ behavior, we have to change the market they operate in.
A well funded digital literacy and culture campaign could step into this chasm. By giving ordinary people the skills to spot deepfakes, resist manipulative algorithms, and protect their mental health, we empower them to demand safer products.
State attorneys general have an incredible opportunity to build on the historic work they have already done. From the Tobacco Master Settlement to the Opioid abatement funds, the states have proven themselves as the primary architects of massive, society saving interventions.
As algorithmic harms increasingly mirror environmental disasters and public health crises, our response must be equally systemic. The next wave of technology settlements offers a generational opportunity to look beyond the standard playbook. Rather than treating historic recoveries as a simple windfall for state treasuries, enforcers must deploy these funds to protect our communities and build a stronger foundation for our democracy.
Yes, it was. Colorado requested the establishment of a “public education fund” as one of the remedies in the Google search monopoly case. Judge Amit Mehta declined to sign off on it noting 1) the states did not draw any connection between Google’s distribution agreements and the public’s perceptions of other search engines as a prong of the Sherman Act allegations and 2) the state’s “lack of specifics [about the potential program] is fatal”. Helpfully, this lays out a guide for future litigants to win a public education fund by drawing this connection and providing those specifics. In cases relating to consumer protection, deceptive practices, and product liability, consumer perceptions are central, so it will be even easier to demonstrate a connection to public education. The first enforcer to win such a remedy would serve as a model for others, creating a snowball effect. Note: This decision was regarding a court ordered remedy, and does not limit settlements.
Prioritize Student Safety in K-12 Education By Establishing AI Procurement Guardrails
Artificial intelligence (AI) tools are rapidly entering K–12 education, influencing discipline, grading, placement, attendance monitoring, tutoring, and school safety. While these systems claim to promote efficiency and innovation, adoption has outpaced oversight. Opaque and insufficiently tested tools are increasingly shaping student outcomes without consistent transparency, civil rights review, or technical safeguards.
This presents material legal and operational risks. AI systems affecting discipline, eligibility, and monitoring may implicate education civil rights laws such as Title VI, Title IX, Section 504, and the Individuals with Disabilities Education Act (IDEA), particularly where disparate impacts arise from biased historical data. Tools that collect or process sensitive student information also raise compliance concerns under the Family Educational Rights and Privacy Act (FERPA) and related state laws. At the same time, many districts lack the capacity to evaluate vendor efficacy claims or negotiate contracts that protect against bias, privacy breaches, or vendor lock-in.
States and the U.S. Department of Education can address these risks using procurement and oversight tools already within their authority. This memo proposes six actionable steps: (1) establish statewide AI procurement guardrails; (2) require Algorithmic Impact Assessments for high-risk systems; (3) prohibit or strictly limit predictive-policing and law-enforcement-derived analytics in schools; (4) encourage ongoing performance monitoring and incident response; (5) create a state-level technical assistance and vendor accountability programs; and (6) invest in leadership-level capacity building for superintendents and senior administrators. Together, these measures support safer adoption, reduce discrimination and privacy risks, strengthen fiscal stewardship, and build public trust.
Challenge and Opportunity
Recent incidents demonstrate that AI deployment in K–12 settings can create serious risks when implemented without adequate safeguards, transparency, or oversight. In one widely reported example, the Los Angeles Unified School District entered a contract with an education-tech startup that ultimately misused student data and put sensitive information at risk. In another case, an AI-enabled security camera system used in a Baltimore County Public Schools school misidentified a bag of chips as a firearm, illustrating the potential for inaccurate automated threat detection systems to trigger unnecessary panic, disciplinary responses, or law enforcement intervention. These incidents underscore that AI systems deployed in schools can materially affect student privacy, safety, disciplinary outcomes, and civil rights, particularly when systems are introduced without sufficient testing, human oversight, or clear accountability mechanisms.
In some contexts, AI may present genuine opportunities for K–12 education when deployed thoughtfully and within appropriate limits. Certain tools may help educators identify students who need additional academic support, expand access to tutoring, streamline administrative tasks, and improve language accessibility for multilingual learners and families. Used as decision-support rather than decision-making systems, AI can help schools direct limited resources more efficiently and support individualized learning in ways that traditional software often cannot.
At the same time, the benefits of these systems depend heavily on how they are selected, designed, governed, and monitored in practice. Educational institutions are increasingly being asked to evaluate unproven products, some costing in the tens of millions, that make probabilistic inferences, adapt over time, and operate with limited transparency. These are features that differ substantially from conventional education technology. These distinctions matter because systems introduced to improve efficiency may also shape high-stakes educational outcomes in ways that are difficult to detect without structured oversight, and some can even be harmful to students and school communities.
The core challenge is not simply AI adoption, but that it is occurring through procurement systems designed for conventional software—not probabilistic tools that may influence discipline, placement, and safety. Most districts rely on standard ed-tech purchasing processes that rarely require structured review of training data, demographic performance, or long-term equity impacts, leaving high-stakes decisions without proportionate risk analysis.
This governance gap is amplified by fragmentation. Local school boards can adopt procedures to aid decision making. Meanwhile, thousands of districts negotiate independently with sophisticated vendors, often lacking the expertise to assess claims about accuracy, bias, data security, or simply accept “off-the-shelf” AI products and terms of service. Contracts can limit audit rights, assent to harmful data practices, and create vendor lock-in, with smaller districts particularly vulnerable to unverified assurances. In worst case scenarios, oversight begins only after harm occurs, leaving districts reactive rather than preventative. In short, decentralized procurement, uneven capacity, and opaque vendor practices create structural risks that, absent coordinated state standards, may entrench inequities and erode public trust.
While the challenges are significant, states possess clear authority to address them. States retain primary responsibility for K–12 governance, including procurement standards, contracting requirements, and oversight of local education agencies. State legislatures and departments of education can issue guidance, promulgate regulations where authorized, condition funding on compliance, and coordinate with procurement offices, CIOs, and attorneys general to establish uniform contracting expectations.
In practice, states can establish baseline procurement checklists and disclosure requirements; mandate better processes that promote better informed decision making; develop model contract clauses addressing data minimization, audit rights, and termination; require pre-deployment review for high-risk systems; condition technology funding on governance criteria; and provide centralized technical assistance. The U.S. Department of Education plays a complementary role through civil rights enforcement, FERPA guidance, and grant-making authority under relevant statutes.
Importantly, not all AI use in schools is harmful. Tutoring systems that scaffold reasoning, or tools that identify students for additional support, can expand opportunity when transparent and used as decision-support rather than automated decision-making systems. The goal then is not to halt innovation, but to channel it responsibly.
Procurement is a high-leverage intervention point that can foster responsible innovation and technology integration. Rather than framing AI governance as a choice between bans and unregulated adoption, guardrails focus on conditions of purchase and deployment, preventing harms upstream before litigation, remediation, or public controversy arise. A statewide framework reduces fragmentation and strengthens negotiating leverage. Consistent standards lower compliance costs and incentivize vendors to compete on transparency, fairness testing, and privacy protections. By acting now, states and federal education leaders can shape procurement norms before harmful practices become entrenched thereby supporting innovation while safeguarding students’ rights and trust.
Plan of Action
Recommendation 1. Establish Statewide AI Procurement Guardrails for K–12 Purchasing
Statewide procurement guardrails are the most feasible and immediate way to reduce risk in school-based AI adoption. Rather than requiring each district to independently develop technical and legal expertise, state departments of education can establish uniform, scalable standards grounded in existing authority and assist schools with product analysis resources. State departments of education already regulate contracts for textbooks, transportation, and student data systems. AI introduces new technical considerations, but these can be addressed through structured disclosure requirements, risk classification, and standardized contract provisions led by state departments of education.
Centralizing guardrails reduces duplication, strengthens negotiating leverage with vendors, and addresses civil rights and privacy risks upstream. A modest investment in templates and oversight can significantly reduce long-term legal, fiscal, and reputational exposure.
Classify and Define “High-Risk” AI Uses
States should classify AI systems by risk level so that safeguards are proportionate to the stakes involved. High-risk systems would include those that implicate rights found in the 2022 White House “Blueprint for an AI Bill of Rights.” Within an education context that would include decisions that impact discipline or expulsion, affect placement or eligibility decisions (including gifted or special education), generate behavioral risk scores or threat assessments, enable surveillance or facial recognition, impact grading or graduation eligibility, or predict student performance in ways tied to consequential outcomes.
These uses are high-risk because they directly affect educational access, safety, liberty interests, and protected status under federal civil rights law, potentially implicating due process protections and civil rights statutes such as Title VI, Title IX, Section 504, and the IDEA. State guidance should also clarify that systems qualify as high-risk when they materially influence high-stakes decisions or process highly sensitive data such as disability or biometric information. For example, in the K–12 education setting, systems that recommend student discipline, identify students as potential safety threats, determine eligibility for advanced academic programs, monitor student mental health or behavior, or evaluate students for special education interventions can influence school administrator’s decisions and substantially shape student educational opportunities, outcomes, and civil rights protections, and therefore warrant heightened oversight. It is important to underscore that AI that may materially influence high-stakes decisions should always be subject to human oversight and never be the sole basis for a decision.
Require a Pre-Purchase Review Checklist and Minimum Vendor Disclosures
For high-risk systems, states should require a structured pre-purchase review to ensure that key legal, technical, and operational risks are addressed before contracts are executed.
A standardized AI Procurement Review Checklist should require districts to document:
- Purpose and Use Case: The specific problem addressed, whether the system supplements or replaces human decision-making, and which student populations are affected including the risk that certain groups of students may be adversely impacted and how.
- Accuracy and Validation: Identity of the validation tester and any conflicts of interest including financial interest in the sale of the product being evaluated, documented error rates, validation studies (including demographic performance where available), and known system limitations.
- Disparate Impact and Treatment Monitoring: Whether the system has been tested for disparate impact and disparate treatment across protected groups, the methodology used, and plans for ongoing monitoring. Other legal indicia of discrimination would ideally be considered as well, including whether a system has been tested for: selective enforcement, hostile learning environment, proxy discrimination, failures to provide accommodation, amongst others.
- Human Oversight and Contestability: Who reviews outputs, whether AI influences adverse decisions, and the process for student or parent appeals.
- Data Governance and Security: Categories of data used, retention timelines, subcontractor involvement, encryption standards, access controls, and incident response protocols.
Overall Safety Declaration: A declaration that determines whether the product is safe or too dangerous for school access.
Vendors, but ideally independent evaluators, should also provide minimum disclosures, including general descriptions of training data sources, audit summaries (if available), subgroup performance metrics, data retention policies, subprocessor lists, server locations, and cybersecurity certifications (e.g., SOC 2). For example, subgroup performance metrics can help identify whether a tool performs differently for students with disabilities or students from different racial or linguistic backgrounds; data retention and server location disclosures help districts evaluate compliance with student privacy laws and data governance obligations; and cybersecurity certifications and subprocessor information help schools assess risks related to student data security and third-party access. These requirements do not mandate disclosure of proprietary algorithms, but they do require sufficient transparency for schools to conduct procurement diligence, evaluate potential harms, and ensure accountability for systems that may materially affect students’ educational experiences and opportunities.
Establish Standard Contract Clauses
Procurement guardrails are only effective if embedded in enforceable contracts. States should develop model AI contract provisions that districts are required or strongly encouraged to adopt.
Core clauses should include:
- Data Minimization and Use Limits: Collection limited to what is necessary as determined by the school district; prohibition on secondary uses (e.g., model training or resale) without parental consent; clear data deletion timelines upon termination of the contract.
- Security and Breach Notification: Encryption at rest and in transit; defined breach notification timelines; vendor liability for negligence-related breaches.
- Audit and Transparency Rights: District, state, or independent evaluator access to performance and compliance documentation; right to independent audit; annual performance updates.
- Termination and Exit Protections: Termination rights for material failures or civil rights concerns; data portability; certified data deletion or media sanitization upon termination of contract.
- Subcontractor and Data Location Controls: Full subprocessor disclosure; equivalent data protections; restrictions on undisclosed offshore data transfers; U.S.-based storage where feasible.
Embedding these provisions strengthens district leverage, reduces vendor lock-in, and creates enforceable accountability if harms occur.
Recommendation 2. Require an Algorithmic Impact Assessment (AIA) Before Deployment of High-Risk Systems
States, with the assistance of independent evaluators, should require districts to complete and publicly post an Algorithmic Impact Assessment (AIA) before deploying any high-risk AI system. An AIA is a structured evaluation of a system’s purpose, risks, legal implications, and mitigation strategies conducted prior to deployment.
By requiring AIAs, states shift governance upstream and identify civil rights, due process, privacy, and safety risks before systems affect students, rather than responding after harm occurs. This approach reinforces that educational innovation must comply with civil rights law, protect student data, and meet defined safety standards. AIAs do not prohibit AI use. They ensure that AI adoption is deliberate, transparent, and accountable.
When an AIA Is Required
An AIA should be mandatory for AI systems classified as high-risk under Recommendation 1, including systems that:
- Influence discipline or safety interventions
- Affect placement, eligibility, or grading decisions
- Conduct behavioral monitoring or surveillance
- Generate risk scores tied to adverse actions
The AIA must be completed prior to contract execution or system activation.
Core Contents of the AIA
To be meaningful, an AIA must provide sufficient detail to inform decision-makers and the public without requiring disclosure of proprietary source code. States should issue a standardized template to ensure consistency. An AIA should include:
- Purpose and Use: The problem addressed, how AI outputs will be used (advisory or determinative), and which student populations are affected.
- Data Inputs and Governance: Categories of data used; whether protected characteristics or proxies are included; sources of training data; retention timelines; data sharing practices (including subcontractors and cross-border transfers); and whether student data are used for ongoing model training. This enables risk evaluation under FERPA and civil rights law without requiring disclosure of proprietary datasets.
- Accuracy and Validation: Error rates, subgroup performance where feasible, validation methods, and known limitations. Where subgroup testing has not occurred, that must be disclosed.
- Disparate Impact, Disparate Treatment, and Oversight: Results of disparate-impact and treatment testing, ongoing monitoring plans, mitigation strategies, and confirmation that AI will not serve as the sole basis for adverse decisions without human review. The assessment should also identify which agency, department, or designated internal team is responsible for ongoing oversight, whether dedicated staff capacity exists to carry out that responsibility, and who will be accountable for responding if discriminatory outcomes, safety failures, or other material harms emerge after deployment.
- Due Process Protections: Notification procedures, appeal processes, review timelines, and mechanisms for correcting erroneous records.
- Privacy and Security Safeguards: Encryption standards, access controls, incident response protocols, breach notification timelines, and FERPA compliance.
Transparency and Public Posting Requirements
AIAs should balance meaningful transparency with protection of proprietary information. States should require a two-tiered structure:
- Public version: Narrative descriptions of the system’s purpose, data categories, data and privacy protections, performance metrics, limitations, safeguards, and high-level demographic testing results where feasible, accompanied by a plain-language summary that is accessible to parents and guardians.
- Regulator-facing appendix (as needed): More detailed technical documentation, validation studies, and contractual data governance materials.
Raw datasets and proprietary algorithms do not need to be disclosed. However, vague assurances (e.g., “tested for bias”) are insufficient. AIAs must include independent testing, documented metrics, and clear descriptions of methodologies.
Each AIA should be publicly posted on the district website prior to acquisition, including a parent-friendly summary (2–3 pages), contact information for questions or complaints, and a clear explanation of appeal rights. States can reduce administrative burden by providing standardized templates and maintaining a centralized statewide repository.
Public transparency strengthens trust, enables independent review, promotes vendor accountability, and supports cross-district learning.
Recommendation 3. Prohibit or Strictly Limit Predictive-Policing and Law-Enforcement-Derived Analytics in School Settings
Certain AI uses in schools pose heightened civil rights, due process, and safety risks that procurement safeguards alone cannot mitigate. Systems that replicate predictive-policing models or rely on law-enforcement-derived data warrant clear statutory limits.
Define and Prohibit High-Risk Predictive Discipline and Law-Enforcement-Derived Systems
The increasing use of AI-driven behavioral analytics, predictive monitoring tools, and school surveillance technologies raises significant concerns for student privacy, civil rights, due process, educational equity, and student safety. Systems that predict future misconduct, generate behavioral threat scores, or rely on law-enforcement-derived data risk replicating historical patterns of bias, normalizing heightened surveillance, and increasing unnecessary disciplinary or law enforcement intervention, particularly for students of color, students with disabilities, LGBTQ+ students, and other historically marginalized groups. Because these technologies can materially influence disciplinary outcomes states should prohibit or strictly limit AI systems within the education setting that:
- Generate forward-looking risk scores used to justify discipline, suspension, expulsion, or law enforcement referral.
- Produce behavioral threat scores like “aggression” or “threats” to school safety absent specific, individualized evidence.
- Rely primarily on law enforcement datasets or predictive policing models.
- Use facial recognition or other biometric surveillance.
- Identify or label objects as weapons.
- Integrate student data into external law enforcement analytics systems without explicit statutory authorization.
Predictive Discipline Risk Scoring
Due to discrepancies in school discipline, for example, the well-documented research showing Black students are disproportionately disciplined compared to White students for similar behaviors, the same AI risk score may lead to very different interventions, which would exacerbate existing disparities. Therefore, assigning students algorithmic “risk scores” for future misconduct raises serious equity concerns. Systems that aggregate attendance records, prior disciplinary history, or behavioral indicators risk replicating documented racial disparities embedded in historical data. Even if statistically predictive, such tools may institutionalize biased baselines and normalize heightened surveillance of certain students.
Accordingly, states should prohibit AI systems that use forward-looking misconduct predictions to justify disciplinary action or automated referrals without individualized human evaluation.
Law-Enforcement-Derived Analytics
AI systems adapted from policing contexts introduce additional risks. Law enforcement datasets often reflect patterns of over-policing and incorporating them into school decision-making can import external bias into educational settings. States should prohibit systems that integrate criminal justice databases into student risk scoring, share student behavioral data with predictive law enforcement platforms absent a specific incident, or use facial recognition tied to law enforcement watchlists in routine school operations.
Schools are educational institutions—not extensions of the criminal justice system. Clear statutory boundaries are necessary to prevent normalization of predictive surveillance in learning environments.
Allow Narrow Exceptions Only with Heightened Safeguards
There may be limited scenarios where data analytics support school safety planning or student support interventions. In such cases, use should be permitted only under strict conditions:
- AI outputs may not serve as the sole basis for adverse action.
- All outputs must be reviewed by trained personnel.
- Clear documentation of evidentiary basis must accompany any intervention.
- Systems must undergo an Algorithmic Impact Assessment prior to deployment.
- Annual disparate impact and disparate treatment analysis must be conducted.
These safeguards increase the likelihood that technology supplements, not replaces, professional judgment.
Recommendation 4. Governance, Ongoing Performance Monitoring, Public Reporting, and Incident Response
AI systems evolve and update over time, interact with changing student populations, and may degrade in accuracy or fairness after deployment. Effective governance therefore requires a lifecycle oversight model that includes continuous monitoring, transparent reporting, and structured response mechanisms. This recommendation establishes that high-risk AI systems in schools are not “set and forget” technologies. They must be evaluated regularly against performance, equity, and safety benchmarks.
Ongoing Testing and Annual Public Reporting Requirements
States should require districts using AI systems to submit annual public reports summarizing system performance and impact, using a standardized template provided by the state education departments to ensure consistency and reduce burden. Continuous oversight reflects four core principles: accuracy can degrade over time; equity requires ongoing monitoring; transparency builds trust; and accountability must be enforceable through mechanisms such as sunset or reauthorization. This recommendation does not presume failure; rather it ensures responsible innovation through measurable outcomes and structured review.
Annual reporting should include:
- Performance Metrics: Error rates (false positives/negatives), misclassification rates, trends over time, and testing methods. For example, security systems should report alerts versus confirmed threats; grading systems should report educator overrides.
- Demographic Disparities: Disaggregated data on flagging rates across high-impact use cases, AI-linked disciplinary actions, and override rates across race, disability status, English learner status, and other relevant categories. Ongoing disparity monitoring supports compliance with federal civil rights obligations.
- Human Oversight: Frequency of overrides, instances where AI influenced adverse actions, and documentation of review processes to ensure systems are not functioning as automated decision-makers.
- Complaints and Resolution: Volume and type of complaints (accuracy, bias, privacy), resolution timelines, and corrective actions taken, which together serve as an early warning mechanism.
Embedding monitoring and reauthorization into state governance ensures AI systems remain tools for student support rather than unexamined sources of risk.
Rapid Incident Response Protocol
In addition to annual reporting, states should require districts to adopt a rapid incident response protocol for significant AI-related harms, including major student data breaches, unsafe outputs such as erroneous security alerts that trigger law enforcement involvement, systemic bias identified through internal review or complaint, and widespread false positives and negatives affecting multiple students. The protocol should recommend immediate containment—including suspension of system use where necessary—prompt notification to affected families and the state education department within a defined timeframe (such as 48–72 hours), a documented root cause analysis conducted in coordination with the vendor, and a corrective action plan with clear mitigation steps, accompanied by a public summary.
Districts should not hesitate to pause or suspend deployment when student safety, civil rights, or liability risks are implicated. In high-stakes environments, it is prudent to err on the side of intervention rather than adopt a “wait and see” approach. This framework aligns with established cybersecurity incident response standards and minimizes the risk of prolonged or compounded harm.
Sunset and Reauthorization Requirement
To prevent long-term entrenchment of ineffective or harmful systems, states should require periodic reauthorization of AI tools. Authorization should automatically sunset after three years unless renewed based on demonstrated accuracy, absence of unexplained demographic disparities, documented educational benefit, and compliance with reporting and audit requirements. This approach creates accountability without imposing permanent bans and incentivizes continuous system improvement.
Recommendation 5. Create a State-Level Technical Assistance and Vendor Accountability Program
Procurement guardrails, AIAs, and monitoring will only succeed if districts have the capacity to implement them. Many, especially rural districts, lack high speed internet, expertise in AI evaluation, data governance, contract negotiation, and receive less funding than their urban peers. A state-level technical assistance and vendor accountability program, buttressed with support from universities and independent evaluators, can close this gap and shape stronger market standards.
Without practical support, reforms risk becoming procedural rather than protective. Modest centralized investment can reduce duplication, strengthen negotiating leverage, reinforce civil rights and privacy compliance, and promote responsible innovation at far lower cost than reactive remediation after harm occurs.
Statewide Technical Assistance and Training
States should establish targeted training for procurement staff, technology leaders, and administrators overseeing AI adoption. Training should cover risk classification, completion of AIAs, evaluation of vendor claims and accuracy metrics, disparate impact and treatment analysis, contract negotiation best practices, and incident response obligations. Delivery can leverage existing professional development structures such as webinars, regional workshops, online modules, and standardized toolkits. To limit costs, states can partner with public universities, education service agencies, or nonprofit research centers with expertise in education technology and civil rights compliance.
Optional Statewide “Approved Vendor” Pathway
States may establish an optional pre-vetted or “approved vendor” pathway for AI systems, structured as conditional certification tied to transparency and compliance standards. Under this model, vendors voluntarily submit documentation demonstrating compliance with state disclosure, testing, and contract requirements. The state conducts a structured review. If approved, vendors are listed in a public registry. Districts may still procure other vendors but must complete full independent review.
States should also consider pairing any approved-vendor pathway with targeted compliance assistance, particularly for smaller or emerging vendors that may lack dedicated legal or regulatory staff but offer promising educational tools. This could include technical workshops, model disclosure templates, and guidance on meeting state testing, documentation, privacy, and contract expectations. Providing this support helps ensure that approval pathways do not inadvertently favor only large incumbent ed-tech companies with extensive compliance infrastructure, while still preserving rigorous standards for safety, transparency, and civil rights protections.
This approach reduces duplicative review, strengthens bargaining leverage through uniform standards, and incentivizes vendors to compete on transparency and validated performance rather than marketing claims. Approval should remain conditional, subject to ongoing compliance monitoring and revocation if standards are not met.
Independent Evaluation and Privacy-Preserving Audit Options
To strengthen accountability, states should mandate independent evaluation of high-risk AI systems that balance transparency with student privacy and vendor intellectual property protections. Options include secure data enclaves, aggregated performance reviews under confidentiality agreements, de-identified or differential privacy testing environments, and partnerships with public universities for validation studies. Independent evaluation helps test vendor claims, detect disparate impacts and treatment, inform evidence-based policymaking, and build public trust. Where feasible, states may offer grants to support validation of widely used systems.
Ensuring Effective Transmission of State Guidance to Districts
State guidance does not always translate cleanly into local practice. Differences in district capacity, staffing, and procurement autonomy can result in uneven compliance. To improve implementation, states should integrate AI oversight into existing compliance or accreditation cycles, provide standardized templates and model contract language, designate a clear AI governance lead within the State education departments, and phase implementation beginning with high-risk systems. Experience from data privacy, IDEA, and Title IX compliance shows that clear documentation and centralized technical assistance significantly improve consistency between state policy and district practice.
Recommendation 6. Leadership-Level Capacity Building for Superintendents and Senior District Officials
Procurement reform is insufficient without leadership capacity. Superintendents and senior administrators often make AI adoption decisions based on vendor presentations or innovation pressures, yet may lack training in algorithmic risk, civil rights implications, and technology contract governance. States should establish targeted AI governance training for superintendents, cabinet leaders, CTOs, chief academic officers, and school board members.
Core Training Components
Leadership-level training should cover core legal and governance competencies, including civil rights risks under Title VI, IDEA, Section 504, FERPA, and due process standards. Training should include strategic procurement literacy such as avoiding vendor lock-in and understanding critical audit and data provisions. Training should distinguish supportive from punitive AI use cases and build skills to recognize overpromising in vendor marketing. Lastly, training must contain sections on crisis preparedness, including how to respond to discriminatory or unsafe outcomes and communicate transparently with families and the public.
Delivery Mechanisms
States can integrate this leadership capacity-building into existing professional development structures. Some examples could include: annual superintendent conferences, certification renewals, school board association trainings, and regional education service agency programs. Leveraging established forums avoids creating new bureaucratic layers while using trusted professional networks to promote consistent implementation.
Why Leadership Capacity Matters
State guidance does not always translate cleanly into district practice. Implementation is shaped by resource disparities, competing priorities, leadership turnover, and vendor influence. When superintendents understand the governance framework and its rationale, they are more likely to demand compliance with procurement guardrails, resist premature adoption, dedicate staff time to meaningful review, and support transparency and public reporting. Effective leadership now also requires understanding how to manage AI-enabled systems in practice including how automated outputs interact with existing administrative processes, where human judgment must remain central, and how risks may emerge over time after deployment. Because AI governance is inherently cross-functional, district leaders must be prepared to coordinate legal, procurement, technical, and ethical considerations rather than treat AI as a purely technical issue delegated to IT staff alone. The goal is not to turn superintendents into technical specialists, but to ensure they can exercise informed oversight over AI-enabled decision environments. Without leadership buy-in, even well-designed safeguards risk remaining underutilized.
Conclusion
States must ensure AI integration supports student safety and well-being.
This is possible by adopting procurement guardrails, requiring Algorithmic Impact Assessments, limiting high-risk predictive uses, and mandating ongoing oversight. This framework relies on existing state authority over procurement, contracting, and oversight. By leveraging these tools, policymakers can focus on responsible implementation. Modest investments in technical assistance and leadership capacity can create clear, workable standards for districts and predictable expectations for vendors.
Done well, this approach delivers safer technology deployment. Specifically, it lowers discrimination risk and builds stronger data governance. Doing so ensures better stewardship of public funds, and greater public trust. AI in schools should expand opportunity, not erode it. Acting now, while adoption norms are still forming, allows education leaders to ensure innovation and student rights advance together.
This memo does not comprehensively address several important and distinct issues that warrant separate, dedicated analysis. For example, while this memo references students with disabilities, it does not fully examine the unique legal, educational, accessibility, and civil rights implications AI systems may pose for students protected under the IDEA and Section 504. Similarly, this memo does not comprehensively address the particular risks and considerations affecting English language learners, immigrant students, or multilingual families, each of which raises important questions related to language access, equity, and data governance. The memo does not broadly explore AI literacy or training needs for teachers, students, parents, or school administrators, despite the growing importance of ensuring school communities understand how these technologies function and affect educational environments. Given the confines of this memo, the analysis is intentionally focused on procurement guardrails and governance mechanisms for high-risk AI systems in K–12 education. Nevertheless, the issues not addressed here remain critically important and warrant substantial future analysis and policymaker attention.
FairCare Verification Offers a Human-Centered Path for AI in Medicaid
A wheelchair user with complex care needs submits a prior-authorization request that her physician supports. An algorithm-generated denial arrives with no meaningful explanation, only that her condition “does not meet medical necessity.” Her appeal languishes for weeks. By the time a human reviewer sees the case, her condition has deteriorated, confirming the algorithm’s prediction that she was “high-risk.” This scenario reflects concerns documented across automated denial systems in commercial insurance and other coverage settings, where algorithms have been used to guide or accelerate utilization review and prior-authorization decisions. In Medicaid managed care, similar dynamics are playing out as algorithmic systems make high-stakes decisions about patient care. These decisions include prior authorizations, risk scoring, triage, and fraud detection. Too often, affected patients, clinicians, and regulators cannot see how the system works, why a decision was made, or whether meaningful human oversight occurred. Growing evidence suggests these systems may systematically disadvantage low-income patients, people with disabilities, and racial and ethnic minorities, perpetuating health inequities at scale. Their deployment is broadly unpopular with the general public and with frontline healthcare workers, particularly nurses, whose clinical judgment is routinely overridden by opaque automated systems.
This memo focuses primarily on Medicaid because it is where vulnerable beneficiaries are already exposed to opaque automated decision systems through managed care organizations (MCOs). It also focuses on Medicaid because existing federal and state authorities can be used now, without waiting for new legislation. The memo proposes a policy framework (“FairCare Verification”) built around two core reforms: Community Algorithmic Impact Statements (CAIS) and Nursing-Led AI Audit Brigades (N-LABs). These reforms would be supported by patient-facing appeal and explainability protections and by contract-based limits on exploitative secondary uses of safety-net data.
These reforms can be advanced through guidance from the Centers for Medicare & Medicaid Services (CMS), enforcement by the HHS Office for Civil Rights (OCR), certification standards from the Office of the National Coordinator for Health Information Technology (ONC), and state Medicaid managed care contracts. Because managed care organizations and vendors often build products to the highest applicable compliance standard, Medicaid-focused guardrails can shape broader market behavior across healthcare.
Challenge and Opportunity
This section addresses the central problem created by growing reliance on algorithmic tools in Medicaid managed care and explains why the current policy moment creates an opening for targeted intervention. The core issue is not simply that AI is entering healthcare; it is that high-impact decisions about coverage and care are increasingly being shaped by systems that affected patients, clinicians, and regulators cannot meaningfully scrutinize.
Accountability Structures
Current accountability frameworks were built for human decision-makers. They assume that decisions can be explained, questioned, appealed, and attributed to a responsible actor. Algorithmic systems strain each of those assumptions. Civil rights enforcement is still largely organized around individual complaints, but algorithmic harms often emerge at the population level through statistical patterns that are difficult for any single patient to detect or prove, a challenge well documented in emerging legal analyses of algorithmic discrimination.
Medicaid is especially important because it is a joint federal-state program in which the federal government sets baseline rules while states administer benefits and contract with managed care organizations. That structure creates multiple adoption points for algorithmic systems, but it also creates multiple intervention points. This memo therefore focuses on Medicaid managed care, especially prior authorization and utilization management. Similar issues are emerging elsewhere in healthcare. For example, CMS’s Wasteful and Inappropriate Service Reduction (WISeR) Model is a traditional Medicare model that uses enhanced technologies, including AI and machine learning, along with human clinical review, to review selected services before or around payment. That initiative is distinct from this memo’s principal Medicaid focus, but it illustrates why automated review is becoming a broader policy concern.
Automated Accountability Risks
AI tools are already embedded across prior authorization, risk scoring, triage, patient communications, and fraud detection. Proponents argue that these systems can speed processing, reduce administrative delays, standardize decision-making, and detect fraud more efficiently than manual review. In a system with substantial administrative waste, those goals are not trivial. But the case for efficiency is often asserted rather than independently validated, and internal safeguards are rarely transparent to the communities most affected.
The concern is not limited to explicit use of race, disability, or other protected traits. High-impact systems can generate discriminatory effects through proxy variables such as prior healthcare spending, geographic indicators, housing instability, or employment status. Under Section 1557 of the Affordable Care Act, Medicaid programs may not discriminate on the basis of race, color, national origin, age, disability, or sex, yet algorithmic systems may produce exactly such differential outcomes through indirect pathways. The Optum algorithm controversy showed how a widely used population health tool could systematically under-identify Black patients for additional care even when they were equally sick. Patients with disabilities may be especially vulnerable to extended automated reviews or wrongful denials when algorithms fail to account for the complexity and variability of disability-related care needs. Separately, reporting on automated insurance denials has raised concern that the speed and scale of algorithmic review can sideline meaningful clinical judgment.
Population Differences and High-Impact Use
A related concern is the gap between the population on which a system was trained and the population on which it is deployed. One problem arises when a model is trained on national claims data that does not capture the disease burden, disability prevalence, language needs, or care-access barriers of a specific state Medicaid population. A second problem arises when a model trained in one hospital system is deployed in a different care environment with different workflows, staffing patterns, and patient needs. Both problems should be treated as core governance issues, not afterthoughts. A central purpose of Community Algorithmic Impact Statements is to force disclosure of source populations, deployment settings, and subgroup validation before high-impact use.
Existing legal tools already provide a starting point. Section 1557 of the ACA, Medicaid managed care regulations under 42 CFR Part 438, health IT certification authorities, and state utilization-management oversight all create avenues for oversight. The problem is not total absence of authority. The problem is that existing authority has not been translated into a practical governance framework for algorithmic systems before those systems become entrenched.
Public trust is also fragile. A 2023 Pew Research Center survey found that 60 percent of Americans would feel uncomfortable if their healthcare provider relied on AI for diagnosis and treatment. Frontline workforce opposition reinforces this concern. In a 2024 National Nurses United survey of more than 2,300 registered nurses, many respondents reported that AI tools undermined patient safety, conflicted with clinical judgment, or could not be modified when nurses disagreed with the output. Nurses are therefore well positioned to identify when automated systems conflict with bedside realities, create avoidable delays, or shift burdens onto patients and care teams. For that reason, this memo treats nurses not just as affected stakeholders, but as central participants in accountability.
The Strategic Window
There is a near-term opportunity to act because state Medicaid contracts are periodically renewed and routinely used to add new performance, reporting, and quality requirements. Several large states, including Texas, Florida, Ohio, and Illinois, have active or upcoming Medicaid managed care procurement cycles. These cycles create natural insertion points for algorithmic transparency, audit cooperation, and appeal safeguards. States do not need to wait for Congress to begin acting through procurement and contract oversight.
At the same time, policymakers are paying closer attention to adjacent problems in Medicare. CMS’s WISeR prior-authorization model has heightened concern about automated review and delayed care, even though CMS describes the model as combining enhanced technology with human clinical review. Bipartisan congressional inquiries into automated denial systems in both Medicare Advantage and Medicaid also signal growing political interest in this space. This proposal remains centered on Medicaid managed care, where states and federal administrators have especially clear opportunities to set guardrails for high-impact systems already being used in coverage and care management.
The political environment also calls for a realistic implementation strategy. The current federal administration has expressed skepticism toward disparate-impact frameworks, and a proactive federal push framed solely in those terms may face resistance. For that reason, the most durable near-term pathway is to emphasize patient protection, clinical accountability, fair process, transparency, and state contract authority, while preserving civil-rights enforcement as an essential backstop rather than the only implementation lever. This proposal protects patient autonomy through the right to appeal and receive an explanation. It supports clinical judgment by empowering nurses to challenge opaque algorithms. It also creates accountability without expanding government bureaucracy by leveraging existing external review infrastructure and state authority. These principles resonate across the political spectrum.
The urgency of this window is heightened by the introduction of new Medicaid work-reporting requirements. States are rushing on expedited timelines to build algorithmic systems for eligibility and compliance determinations, creating additional risks of erroneous benefit terminations and increased vendor lock-in. While this proposal focuses on AI in clinical and utilization management decision-making rather than eligibility processing, the governance frameworks proposed here, particularly CAIS transparency requirements, could be extended to eligibility determination systems as well.
Plan of Action
The recommendations below are designed to be mutually reinforcing, but the memo places greatest weight on two core interventions: Community Algorithmic Impact Statements and Nursing-Led AI Audit Brigades. The remaining proposals are narrower supports intended to make those two primary reforms workable in practice.
Recommendation 1. Require Community Algorithmic Impact Statements and establish Nursing-Led AI Audit Brigades.
Any Medicaid managed care organization, subcontractor, or vendor should be required to file a public Community Algorithmic Impact Statement before deploying AI for high-impact Medicaid decisions. Covered uses should include prior authorization, utilization management, care coordination prioritization, fraud flagging, triage, and other decisions that materially affect access to care. The filing should occur before deployment and annually thereafter.
CAIS should be modeled in part on the logic of environmental impact review, which requires public assessment of potential effects, alternatives, and mitigation before major federal actions. The goal is not to create a generic disclosure form. A CAIS should require a plain-language description of the system, its intended use, the population affected, the decisions it can influence, the data sources on which it relies, the source population on which it was trained, known limitations, plausible risks of harm, mitigation steps, monitoring plans, and available alternatives. For high-impact uses, it should also disclose subgroup performance testing and whether performance was evaluated on a population meaningfully similar to the state Medicaid population in which the tool will be deployed.
CAIS should classify systems as high-impact, moderate-impact, or advisory. High-impact systems would include prior-authorization denials, utilization-management restrictions, fraud flagging with downstream care consequences, and triage systems that materially affect access. These risk tiers draw on existing frameworks such as the NIST AI Risk Management Framework, adapted to Medicaid decision-making. High-impact systems should require pre-deployment filing, state review, and a public comment period before use. Moderate-impact systems should require annual reporting and post-deployment monitoring. Advisory tools should still be documented, but with lighter obligations.
Testing for disparate impact across all protected characteristics presents measurement challenges, particularly for disability status. Unlike race and ethnicity, for which inference methodologies such as Bayesian Improved Surname Geocoding (BISG) exist when self-reported data is unavailable, no comparable inference methodology currently exists for disability status. RAND describes BISG as a method that combines surname and geocoded address information to estimate race and ethnicity when direct data are missing or incomplete. Medicaid claims data and eligibility categories may provide some basis for identifying disability-related disparities, but this remains an area requiring further methodological development. CAIS filings should document these measurement limitations transparently and describe the best available approaches for subgroup testing.
At the same time, states should establish Nursing-Led AI Audit Brigades, or N-LABs, as independent audit teams. These teams should include registered nurses but also data scientists, health law or civil-rights experts, and at least one patient advocate or community health worker with lived Medicaid experience. The American Association of Colleges of Nursing reports more than 5 million registered nurses in the United States, making nursing the nation’s largest healthcare profession. Recent nursing scholarship on clinical AI auditing similarly emphasizes that assurance frameworks should include nursing leadership, not merely technical validation. The purpose of the N-LAB model is not to have nurses perform technical validation alone, nor to have data scientists audit systems without clinical grounding. The point is to create a multidisciplinary audit process in which each discipline evaluates the same system from a different but complementary vantage point. Including patient advocates ensures that audit priorities and scorecard criteria reflect beneficiary perspectives alongside clinical and technical expertise; beneficiary input can also be channeled through existing Community Advisory Boards (required under 42 CFR 438.110) and Federally Qualified Health Center governing boards (which include patient majorities).
In practice, an N-LAB would operate in six steps. First, it would review the CAIS and underlying documentation. Second, it would obtain case samples, denial rationales, override data, and subgroup outcomes from the managed care organization or vendor. Third, data scientists would test for accuracy, subgroup disparities, calibration, and training-versus-deployment mismatch. Fourth, nurse auditors would assess clinical plausibility, workflow burden, appropriateness of overrides, and whether the system appears to displace rather than support professional judgment. Fifth, legal reviewers would analyze whether observed patterns raise concerns under Medicaid managed care rules, civil-rights obligations, grievance requirements, or contract terms. Sixth, the team would publish a public scorecard and, where necessary, require a corrective action plan.
N-LAB scorecards should rate systems on accuracy, subgroup performance, explainability, human-override capacity, documentation quality, and post-deployment monitoring. Systems rated “needs improvement” should be required to submit corrective action plans within 60 days. Systems rated “fails” for high-impact use should be suspended by the state Medicaid agency until corrective action is verified. State agencies, not N-LABs themselves, should retain final suspension authority.
Estimated cost remains modest relative to Medicaid program scale. A team costing roughly $500,000 to $750,000 annually, assuming roughly 1.25 to 1.9 million beneficiaries per audit team, would amount to approximately $0.40 per Medicaid beneficiary. This is an illustrative estimate based on comparable external quality review organization (EQRO) staffing models. A large state may require two to four teams depending on MCO and system volume. The stronger argument, however, is institutional: N-LABs translate abstract oversight into a repeatable operational process.
Implementation can proceed through existing authority. CMS can issue model CAIS guidance and encourage incorporation into managed care contracts. States can require filing and audit cooperation through requests for proposals and contract terms. ONC can reinforce these expectations by embedding documentation and audit-readiness requirements into certification-related pathways, building on ONC’s existing role coordinating EHR certification under the 21st Century Cures Act. The HHS Office for Civil Rights can use filings and scorecards as triggers for proactive review. If current political conditions make explicit Affordable Care Act Section 1557 (protecting individuals from sex discrimination) framing difficult, alternative language focusing on “differential outcomes based on personal characteristics” or “equitable access to care” can maintain legal force while being politically adaptive. These timelines are realistic based on comparable regulatory actions: CMS issued comprehensive Medicaid managed care rules (42 CFR Part 438) with 18-month implementation; ONC implemented 21st Century Cures Act certification criteria within 24 months; state insurance commissioners routinely issue bulletins with 6–12 month effective dates.
Recommendation 2. Add algorithm-specific explainability and appeal protections for high-impact adverse decisions.
Some Medicaid rules already require plans to provide denial reasons to requesting providers (42 CFR § 438.404). This proposal does not duplicate that baseline. It adds a more usable and enforceable framework for algorithmic decisions by requiring patient-facing explanations, clinician-usable explanation materials, auditor documentation, and an independent review pathway when an automated or algorithmically informed adverse decision affects care. The following standards are adapted from emerging model documentation and explanation frameworks, including model cards for model reporting and post-hoc explanation tools such as LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations).
For patients, explanations should be plain-language, translated as needed, and specific enough to explain what decision was made, what key factors drove it, and what information could change the outcome. Boilerplate language such as “not medically necessary” is not enough when the decision was materially shaped by an algorithmic system. Patients should receive a short contestability notice with the adverse decision that explains the decision, the right to appeal, the timeline, and how to submit additional information. For complex models, post-hoc counterfactual explanations using methods such as LIME or SHAP can translate opaque outputs into patient-accessible language.
For clinicians, the standard should be more operational. If a model materially shaped a denial or restriction, the responsible entity should be able to identify what inputs were used, which factors were most influential, what uncertainty surrounds the output, and how the case compares with relevant benchmarks or similar cases. The goal is not to force disclosure of source code or trade secrets. It is to provide enough information for meaningful clinical contestation and review.
For regulators and auditors, the system should be documented well enough to reconstruct individual decisions, evaluate subgroup performance, review validation methods, and identify known failure modes. A system that cannot generate meaningful patient-facing, clinician-facing, and auditor-facing explanations should not be used as the sole basis for a high-impact denial or restriction. That is the operative limit on insufficiently explainable systems. ONC should add these requirements to health IT certification where systems fall within certification-related pathways, specifying that certified systems must demonstrate capability to generate explanations meeting these standards.
This memo also establishes an enforceable appeal right for adverse algorithmic decisions, preserving at least the existing 60-day appeal period under federal Medicaid managed care rules while adding algorithm-specific notice and expedited independent review by an appropriately qualified clinician not employed by the plan. This mirrors the logic of existing external review structures, at comparable cost ($500-$700 per review), but makes clear that algorithmic involvement triggers heightened transparency, documentation, and reversal tracking. The process: (1) patient receives an adverse decision with a plain-language contestability card explaining the decision, the algorithmic factors involved, and appeal rights, available in multiple languages; (2) patient files appeal within the applicable appeal period; (3) independent clinician conducts de novo review; (4) binding decision issued within 15 business days; (5) reversals reported to the relevant N-LAB; (6) patterns of reversals for a particular system trigger automatic audit.
These appeal rights should be understood as complements to, not substitutes for, bright line regulatory rules where appropriate. A bright-line rule is a clear rule that draws a firm boundary and leaves little room for case-by-case balancing. For certain categories of decisions, such as prior authorizations for treatments meeting established clinical criteria, regulators should consider prohibiting automated denial without clinical review altogether, as has been proposed in the Medicare Advantage context. Audits and transparency mechanisms are most valuable for the many algorithmic applications where bright-line prohibitions are impractical.
Finally, safety-net data should not be treated as a free raw material for secondary commercial exploitation. Vendors using Medicaid and other safety-net data should be required to sign Community Data Covenants restricting secondary uses through purpose limitation, data minimization, retention limits, transparency, and benefit-sharing where appropriate. Existing education-sector data-use agreements provide a workable precedent for this kind of contractual approach, including the U.S. Department of Education’s Model Terms of Service and state-level models such as Alabama’s SDPC Alliance.
Recommendation 3. Use state Medicaid contracts as the primary near-term implementation pathway.
Because Medicaid is jointly governed, states do not need to wait for new federal actions. State Medicaid agencies can incorporate FairCare Verification (CAIS filing, N-LAB cooperation), minimum explanation requirements, and appeal obligations directly into managed care requests for proposals and contracts. These mechanisms fit naturally alongside existing reporting, quality, and utilization-management provisions. For example, a state could require: “Contractor shall file CAIS documents for all high-impact AI systems 90 days before deployment and cooperate with state-designated N-LAB audits. Failure to comply constitutes material breach.”
A state-based pathway is also more feasible in the current moment. It allows policymakers to frame the issue in terms of accountability, patient protection, fair process, and clinical integrity rather than relying exclusively on expansive new federal directives. It also creates opportunities for coalition-building among states that want to avoid fragmented vendor compliance and regulatory arbitrage.
To reduce patchwork harms, states should work through a consortium model. A coalition of large states could develop shared contract language, common filing templates, reciprocal recognition of audit findings, and aligned minimum standards for high-impact systems. This approach mirrors the National Association of Insurance Commissioners (NAIC) model law development process and multi-state pharmaceutical supplemental rebate agreements. Benefits include reducing compliance burden, increasing leverage over vendors, and accelerating de facto national standard-setting through market pressure. Where stronger requirements are desired, states can pass legislation, with Colorado’s SB 21-169 and Illinois’s AI Video Interview Act providing useful models.
Enforcement should sit inside this state-contract architecture rather than operate as a disconnected apparatus. Failure to file a required CAIS, cooperate with audit review, produce required explanation materials, or implement corrective action should count as a material contract breach. States can then use cure notices, financial penalties, suspension authority, and procurement consequences already familiar in managed care oversight. Federal agencies, including CMS through Medicaid matching-fund conditions, ONC through certification standards, and OCR through independent Section 1557 authority, should reinforce, not replace, this state-centered pathway.
Conclusion
The strongest immediate case for action is not that every healthcare AI use can be solved at once. It is that Medicaid beneficiaries are already exposed to high-impact algorithmic systems in coverage and care-management decisions, and that existing law and contract authority can be used now to make those systems more visible, more contestable, and more accountable.
“FairCare Verification”, or Community Algorithmic Impact Statements and Nursing-Led AI Audit Brigades, are the memo’s central reforms because they address the first-order governance problem: systems are being deployed without adequate public disclosure or credible independent review. Explainability rules, appeal rights, and data covenants matter, but they work best as supporting mechanisms around those two core interventions. No new legislation is required for initial implementation. CMS could issue initial guidance quickly; state Medicaid directors can add clauses at the next MCO contract renewal; state Medicaid agencies and MCOs can adopt policies at their next meeting. What is required is a practical governance strategy that fits current institutional realities, focuses clearly on Medicaid managed care, and gives patients, nurses, regulators, and community stakeholders structured ways to detect and correct harm before opaque systems become entrenched. The next 18-24 months may be a critical window before harmful practices become deeply embedded. The question is whether policymakers seize this opportunity or face far more difficult remediation after extensive harm accumulates.
Medicaid beneficiaries are especially vulnerable to opaque administrative systems and often have the least practical power to absorb delays, navigate appeals, or switch coverage arrangements. Similar concerns also exist in Medicare, including in traditional Medicare pilots, but Medicaid managed care offers especially clear and immediate levers for contract-based intervention. Medicaid requirements can also influence commercial insurers, shape vendor products, and set precedent across sectors because vendors and MCOs often build products to satisfy the strictest large-market contract standard rather than maintaining separate systems for every payer.
Existing requirements under 42 CFR § 438.404 generally address the obligation to provide a denial reason. This proposal goes further by requiring algorithm-specific disclosure, patient-facing contestability materials, clinician-usable explanation content, independent review for adverse algorithmic decisions, and systematic feedback from reversals into ongoing audit oversight.
The proposal does not require disclosure of source code or proprietary architecture. It requires disclosure of inputs, intended use, validation, subgroup performance, explanation capacity, and monitoring results—enough to evaluate what the system does and whether it can lawfully and safely be used in high-impact Medicaid decisions. Post-hoc explainability techniques (LIME, SHAP, counterfactual explanations) provide transparency without revealing trade secrets.
N-LAB audits cost approximately $0.40 per Medicaid beneficiary annually. CAIS filing requires staff time, not new technology. The appeal right leverages existing external review infrastructure and timelines. These costs are modest compared with remediating entrenched algorithmic discrimination years later.
The Federal Government Should Pilot a Decision Subject Representative Program for AI Systems
AI systems are regularly used to make decisions that directly impact individuals, from who gets a housing voucher to who gets a job, to bail—contexts with a long history of social disparities, facilitating encoded discrimination. The designs of these consequential AI decision systems are shaped by corporations and increasingly overseen by governments with little input from the public, specifically from users and individuals impacted by these decisions.
Executive branch agencies frequently engage the public in policy decisions via requests for comment and town halls. For decades, the Food and Drug Administration (FDA) has gone beyond traditional agency engagement processes via the Patient Representative Program (PRP), which recruits, trains, and embeds patients into oversight of the pharmaceutical industry, including decisions regarding clinical trial design, endpoints (evaluation metrics), risk/benefit analysis, product labeling, etc. This memo proposes creating a Decision Subject Representative Program inspired by the FDA’s Patient Representative Program.
While pharmaceutical drugs and consequential AI decision systems vary in scope and impact, both technologies need to be safe and effective to be trusted by the public and consumers. Public engagement has long been a tool for building trust and legitimacy in governance decisions while providing a complement to expertise associated with elite institutions. Three decades of FDA experience in systematizing patient engagement offer valuable inspiration for AI governance. Specifically, the General Services Administration (GSA) should pilot embedding Decision Subject Representatives into the procurement process for consequential AI decision systems, the National Institute of Standards and Technology (NIST) should pilot engaging Decision Subject Representatives in efforts to shape standards, and Congress could add a flexible Decision Subject Representatives Program (DSRP) to new regulatory proposals.
Challenge and Opportunity
Technologists have attempted to address concerns regarding bias and discrimination in consequential AI decision systems (AI systems that serve as a basis for a decision or judgment in consequential contexts such as education, employment, essential utilities, financial services, legal services, etc.) by analyzing statistical outcomes or applying fairness metrics. The challenge with this approach is that there are a variety of ways to conceptualize and measure fairness that can not be encoded at the same time. Additionally, fairness metrics often rely on the availability of sensitive category data, which may be restricted by privacy laws and historic human rights laws. Instead, scholars offer that the application context matters and those directly affected should be engaged in the selection and formation of fairness metrics.
More recently, scholars have advocated for a more holistic view of fairness that takes into account the sociotechnical context and the whole process of coming to a certain decision. This approach underscores the need for decision subjects to be included in the entire process of AI system design and deployment, with an emphasis on the assessment of risks and harms broadly, processes for contestability, and transparency measures. As consequential AI decision systems proliferate, it is imperative that the U.S. government pilot systems for engaging decision subjects.
Engaging decision subjects in AI governance faces many challenges. Efforts risk looking like participation washing or engaging decision subjects for theatrical purposes without real power or influence over the final decision. Participatory AI projects can also be inaccessible or exploitative—challenges the FDA’s Patient Representative Program has grappled with.
FDA’s Patient Representative Program
Officials at the FDA woke up to the power of lay expertise in pharmaceutical drug development in the wake of the AIDS epidemic when patients advocated to have their experiences considered in disputes pertaining to the design and methodology of drug trials.
In 1988, the FDA initiated the patient engagement process through the Office of AIDS Coordination. By 1993 the first Patient Representative served on an FDA Advisory Committee. Since then, the FDA has greatly expanded patient engagement with over 200 Patient Representatives, dedicated offices and programs, reporting systems, and regular public guidance aimed at incorporating patient experience data into regulatory decision-making.
The program has been largely implemented at the direction of FDA leadership. In 2012, Congress enacted the Safety and Innovation Act. The act’s language is the first “official” codification of the FDA Patient Representative Program and other patient liaison activities. The law provided greater stability to the program and opened the door for more staff and educational programs.
Patient Representatives include patients, patient advocacy group members, family and/or caregivers, and health care providers. The FDA recruits Patient Representatives through open applications, patient organizations, and staff outreach. Selected participants are vetted and onboarded as Special Government Employees (a category of federal worker for individuals that serve the government temporarily while maintaining employment elsewhere). They consult with FDA review divisions, serve on advisory committees, present at workshops, participate in the Patient Engagement Collaborative which shapes practices in clinical trials, and in other regulatory activities where the patient perspective is needed. Patient Representatives receive training in FDA regulatory processes and can work with FDA staff to prepare to meaningfully participate in advisory committees meetings along with other stakeholders. The FDA covers travel costs and forgone salary for Patient Representatives participating in meetings and training.
FDA employees describe Patient Representatives’ expertise as “a street sense” based on personal experience, describing their views as “a value judgment overlay on top of measurable, empirical clinical trial evidence.” Participants often ask “questions [that] would never be raised” and push for clarity. When Patient Representatives engage with expert stakeholders, learning “works both ways” with clinicians altering their way of thinking based on what Patient Representatives share, and Patient Representatives gaining a better understanding of the science which they can share with their communities.
Over the years, FDA’s Patient Representative program has faced challenges. The drug-specific nature of engagement makes it difficult for patients to engage on cross-cutting issues, conflict of interest rules have made it hard for patients to engage with both drug companies and the FDA, and patients have expressed concerns about not actually knowing the impact they have on decisions. The FDA continues to address these concerns. In 2017, it initiated a Patient Affairs Staff to centralize support for Patient Representatives, and has launched new communication and transparency efforts to help patients understand their influence. While the degree to which patient representative views should be weighted alongside clinical trial data and processes for measuring patient influence will long be contested, the FDA’s program represents a model in which Patient Representatives are remunerated for their time and continually shape FDA processes.
How may the FDA’s Patient Representative Program inspire similar efforts for AI governance?
AI systems are different from pharmaceutical drugs. They are deployed cross-sector and individuals can unknowingly be impacted by an automated decision, whereas drug patients often know they are taking a drug. These differences will impact the way a Decision Subject Representative Program would be deployed, but the types of decisions Patient Representatives consult on are analogous to important decisions in AI governance today. The table below describes the types of governing decisions Patient Representatives have engaged in via the FDA’s drug approval and monitoring process and how those areas correspond with governing consequential AI decision systems. Similar to the FDA, federal agencies could engage Decision Subject Representatives throughout the lifecycle of consequential AI decision systems development including pre-market approval (most comparable to procurement), and the development of testing, evaluation, and transparency standards for deployers and developers (both voluntary and mandated by regulation).
Similar to the way the FDA engages patients in specific drugs (or categories of drugs) as needed, decision subject engagement would work best on applied systems where they can be assessed within a sociotechnical context – particularly in contexts where fairness may be an issue (e.g., education, employment, essential utilities, financial services, legal services). Similar to the FDA, Decision Subject Representatives could consult directly with agency staff on decisions described in Table 1 or serve on advisory committees with other relevant stakeholders.
Recruitment for a Decision Subject Representative Program will vary based on the context and likely include partnering with civil society organizations and community groups that can recommend Decision Subject Representatives. For example, agencies governing (i.e., procuring, drafting standards, issuing testing mandates) hiring software could recruit workers who have experience navigating AI systems to obtain a job or individuals from communities that are historically discriminated against in hiring by partnering with workforce development programs (e.g., American Job Centers, local libraries). Whereas agencies governing (i.e., procuring, drafting standards, issuing mandates) education technology could recruit students, parents and teachers, particularly those from lower-income school districts, to serve as Decision Subject Representatives.
Similar to the FDA, a Decisions Subject Representative Program must include extensive training for Decision Subject Representatives that covers agency (e.g., GSA) processes, why decision subject views are important, and training to combat feeling intimidated by academic and industry expertise. Host agencies should also communicate the importance of decision subject perspectives to other stakeholders. Any pilot should be accompanied by an evaluation of the Decision Subject Representatives’ experience and impact on final decisions.
Plan of Action
Recommendation 1. GSA should consult Decision Subject Representatives when procuring consequential AI decision systems
Recent procurement guidance issued by the Trump administration and the Biden administration directs GSA to identify risks in high-impact AI systems (including what this memo refers to as consequential AI decision systems), conduct pre-award testing, and monitor performance, including quantitative success metrics. GSA should pilot onboarding Decision Subject Representatives as Special Government Employees to consult on these activities as they apply to consequential AI decision systems.
One benefit of engaging decision subjects in the procurement process is that private companies that build systems for the government and for industry may choose to adopt the practices and standards required to meet government requirements for their commercial offerings.
Decision Subject Representatives will have connections to a broader community of individuals impacted by consequential AI decision systems and can serve as a bridge to a wider set of experiences. Additionally, Decision Subject Representatives can consult on new agency programs aimed at engaging decision subjects more broadly over time.
Recommendation 2. NIST should engage Decision Subject Representatives in future Zero Draft development
Risk management, assessment, metrics, and documentation of AI systems will likely be shaped by international standards, especially as the International Standards Organization (ISO) responds to the European Union’s AI Act and similar efforts globally. International standards have traditionally focused on objective guidance and been shaped by industry actors. The need to consider context-specific harms in AI risk assessment has necessitated a recent shift towards sociotechnical standards, creating an imperative for broader stakeholder representation.
NIST, recognizing this shift, recently launched a “Zero Drafts” pilot with the express interest of engaging stakeholders in NIST proposals that are eventually submitted to standards bodies. The two initial topics: AI testing, evaluation, verification, and validation (TEVV) and transparency documentation, are horizontal standards (i.e., not specific to an applied AI system or specific AI use case) and therefore not as well suited to decision subject engagement. But the NIST zero draft program is designed to be responsive to AI workstreams within the international standards bodies, which means they should eventually work on context-specific risk guidance such as AI in hiring, AI in education, AI in financial systems, AI in criminal justice, etc.
As context specific or applied zero draft efforts begin, NIST should pilot engaging Decision Subject Representatives in stakeholder meetings and on edits to draft text. While standards are not regulatory, they can be referenced by regulators worldwide, including U.S. states. In this way, they represent a potential central point of influence over the design and assessment of consequential AI decision systems.
Recommendation 3. Congress should add flexible Decision Subject Representatives Programs to new regulatory proposals
With some exceptions, AI systems do not have to meet transparency or testing requirements to demonstrate they are safe or effective in order to enter or remain on the market. While transparency and testing guidance are currently the domain of NIST (and therefore voluntary), Congress is considering proposals to mandate risk assessment and transparency requirements for consequential AI decision systems (e.g., Algorithmic Accountability Act of 2025). Additionally, Congress has introduced proposals for a comprehensive new digital regulator that would issue regulations, oversee codes of conduct councils or advisory boards, and weigh in on decisions such as those listed in Table 1 (e.g., Digital Consumer Protection Commission Act, Digital Platform Commission Act).
Similar to the Food and Drug Administration Safety and Innovation Act (FDASIA) (2012) Section 1137, Congress could add legislative text to proposals such as those listed above that provides flexibility for agencies to onboard Decision Subject Representatives when they can contribute to decisions related to consequential AI decision systems.
An Example of Legislative Text
Inspired by FDASIA 2012 Section 1137
‘‘(a) IN GENERAL.—The Secretary [or Commission] shall develop and implement strategies to solicit the views of decision subjects during [procurement decisions] or [standards development] or [regulatory discussions] related to consequential AI decision systems including by –
(1) fostering participation of decision subjects who may serve as a special government employee in appropriate agency meetings with consequential AI decision systems developers, deployers, assessors, and investigators; and
(2) exploring means to provide for identification of decision subjects who do not have any, or have minimal, financial interests in companies that provide consequential AI decision systems”
Where DECISION SUBJECT means the person or party to whom the decision applies in a specific context.
Where CONSEQUENTIAL AI DECISION SYSTEMS means “any system, software, or process (including one derived from machine learning, statistics, or other data processing or artificial intelligence techniques and excluding passive computing infrastructure) that uses computation, the result of which serves as a basis for a decision or judgment” [followed by a list of critical contexts such as education, employment, essential utilities, financial services, legal services, etc)]
(definition inspired by the Algorithmic Accountability Act of 2022 and lineages therein, exact definition may be adjusted based on the bill context)
Conclusion
As AI systems are increasingly integrated into government and entrusted with decision-making roles, we risk further embedding bias and mistakes into AI-assisted decisions and outcomes. Existing tools from other domains, such as existing robust public engagement processes in drug development, when applied to AI deployment can help strengthen public trust in these systems and enhance perceptions of their legitimacy and the decisions they produce. Embedding Decision Subject Representatives in the procurement of consequential AI systems, regulatory processes, and agency decision-making represents a gold-standard approach. With minimal additional oversight and support, this practice can help drive the development of high-quality systems that are informed by real-world needs.
Similar to the pharmaceutical context, both companies designing and deploying consequential AI decision systems and governments procuring and overseeing consequential AI decision systems should engage decision subjects. Corbet and colleagues recently (2023) assessed participatory approaches to AI development and found that many projects struggle to provide decision subjects with meaningful influence over AI governance decisions.
As the FDA has worked to engage patients over the years, it has shared its learnings back with the pharma industry, leading to overall improvements in patient engagement related to both regulatory decisions and company drug development decisions. A Decision Subject Representative Program accompanied by rigorous evaluation could help inform best practices for industry public engagement efforts.
Engaging the public in science and technology policy involves building bridges between communities with different levels of power and access in society. It will be challenging, require time, financial resources, and rigorous evaluation. AI fairness advocates should push for these activities both in industry and within government agencies.
Ensuring proper representation of viewpoints in science and technology policy is a perpetual challenge (democracy is hard). FDA Patient Representatives often serve because of their passion for representing their community (individuals living with a health condition) and often engage in online communities and forums. They can bridge not only their own experience but that of others in their community.
While there are only a few hundred Patient Representatives, the agency has several other efforts to engage patients including:
- Patient-Focused Drug Development: Processes for collecting and referencing qualitative patient and caregiver data in drug evaluations.
- Clinical Outcome Assessment: Efforts to integrate patient-reported outcomes, clinician-reported outcomes, and observer reported outcomes into clinical trials.
- Patient testimony offered at workshops, advisory meetings, listening sessions, or via open comment periods on FDA guidance.
- FDA Adverse Event Reporting System (FAERS) database: Provides a way for patients to report adverse events.
These programs are often developed with input from Patient Representatives and create less time- and resource-intensive pathways for patient voices to be included in drug development and oversight. These programs also serve as entry points for recruiting Patient Representatives. Additionally, the existence of these programs has spurred an ecosystem of patient advocacy organizations, creating additional non-governmental pathways for engaging patients in drug development.
Americans Would Trust AI More if Policies Ensuring Fairness Were Implemented. Here are Ten Ways to Start.
By now, you’ve probably heard that most Americans do not trust AI. This distrust is especially concerning given how deeply these systems are already shaping access to healthcare, education, housing, jobs, and public benefits. Too often, these decisions happen without transparency, oversight, or meaningful avenues for recourse. At the same time, confidence in both technology companies and government institutions to manage AI responsibly remains low.
The stakes are clear, and the policy choices we make today will make or break society’s view of AI. We are currently at a critical opportunity to shape how AI is governed before harmful practices and inequities become further entrenched. To meet this moment, the Federation of American Scientists, with the support of the Kapor Foundation, launched a policy sprint, which is an intensive, time-bound effort designed to tackle complex challenges quickly and collaboratively. Policy sprints bring together experts from across disciplines, from academics, technologists, advocates, and practitioners, to develop practical, actionable solutions.
For our SOURCE CODE AI Trust and Fairness Sprint, we’ve developed 10 memos with leading experts that are detailed, implementable policy solutions. We have delved into why fairness is so hard to define and implement, and what is needed to promote public trust in our essay that frames this new policy agenda. These memos are not exhaustive; we know the landscape of challenges and potential solutions is far broader. Instead, we offer them as a starting point: ideas that we hope will not only serve as smart and actionable tools for policymakers, but also inspire the community to build out and advance new, detailed approaches.
- Jae Yeon Kim and Aniket Kesari show how government procurement can be a powerful but underused lever to require transparency, fairness, and accountability in AI systems.
- Nicole Ozer and Brady Hirsch emphasize that in order for AI to work for the people, state leaders must adopt people-centered AI decision making frameworks. hey explain how to ask and answer foundational questions about why and whether to use AI before skipping to the how of implementation.
- JB Branch highlights similar risks in K–12 education, proposing procurement guardrails and impact assessments to protect students’ rights and safety.
- Liza Paudel advances Community Benefit Agreements as a tool for ensuring that communities, especially those disproportionately impacted, secure enforceable protections as AI-driven data center development accelerates.
- Wilneida Negrón examines the rise of “surveillance pay,” calling for stronger regulatory safeguards to protect workers from opaque, data-driven compensation systems.
- Anna Lenhart proposes embedding “Decision Subject Representatives” into AI governance, giving impacted individuals a formal role in shaping high-stakes systems.
- Y. Tony Yang focuses on Medicaid and safety-net healthcare, proposing community-centered oversight, nurse-led audits, and patient protections to ensure AI improves rather than undermines care.
- Ziwei Qi, Tatiana Lin, and Ayokunle Olagoke highlight the risks of “algorithmic invisibility” in rural communities and call for “rural AI proofing” to ensure these populations are not overlooked in AI system design, governance, and implementation.
- Jon M. Peha explores the risks of AI-generated police reports and proposes coordinated federal and local strategies that foster innovation and prevent unsafe deployments.
- Gaurav Laroia and Charlotte Slaiman argue that enforcers must look beyond standard monetary penalties to truly protect communities from algorithmic harms. They show how historic tech settlements can be transformed into an active defense, building societal resilience and preparing the public for the next wave of technological change.
To structure our policy agenda, we have considered how these ideas have employed targeted mechanisms, which we call policy levers, to ensure legitimate use, fair outcomes, and public trust in AI. These levers include government use of AI, public engagement, sectoral considerations, and redress in legal remedies; many of our policy ideas use several of them.
This work was shaped by a multidisciplinary advisory working group of 17 experts from academia, civil rights organizations, think tanks, and beyond. Their insights helped refine the project’s focus, identify the most pressing policy opportunities, and strengthen each memo through expert review. Advisory members provided input in an individual capacity; their participation does not imply endorsement of the findings or recommendations. We are grateful for their support and expertise throughout this process.
- Quinn Anex-Ries, Center for Democracy & Technology
- Alex Ault, Lawyers’ Committee for Civil Rights Under Law
- Annette Bernhardt, UC Berkeley Labor Center
- Miranda Bogen, Center for Democracy & Technology
- Leah Frazier, Lawyers’ Committee for Civil Rights Under Law
- Sanmi Koyejo, Stanford University
- Sarah Myers West, AI NOW
- Tejas N. Narechania, UC Berkeley School of Law
- Cathy O’Neil
- Asad Ramzanali, Vanderbilt Policy Accelerator
- Cody Venzke, ACLU
- Jonathan Walter, Leadership Conference on Civil and Human Rights
The ideas generated through this sprint are practical, actionable, and grounded in existing authority. They demonstrate that policymakers already have many of the tools needed to govern AI effectively; they simply need to be deployed with urgency and intention. There is a narrowing window to shape the integration of AI systems into society. With thoughtful policy action, it is still possible to build systems that are fair, transparent, and accountable, and to earn the public trust that will ultimately determine AI’s future. We hope policymakers are ready to act.
Making Rural Communities Visible in Artificial Intelligence Through Rural Proofing in Kansas and Beyond
A road can show connection, but not access. Rural communities might appear in data and public systems, yet still remain invisible when AI systems do not reflect distance, transportation barriers, service gaps, workforce constraints, smaller data sets, and local strengths. Rural proofing gives Kansas and other rural states a practical way to make these realities visible in the AI-driven decisions already shaping health and social services.
Artificial intelligence (AI) is increasingly shaping decisions across public health systems, including how needs are identified, how resources are distributed, and how services are delivered. As a result, AI will play an important role in the future of healthy rural communities. When designed and governed carefully, AI can improve access, resource planning, coordination, and service delivery. When rural contexts are overlooked, AI systems can reproduce uneven outcomes and risk deepening existing disparities. In rural areas, where health systems often operate with fewer providers, thinner infrastructure, and less margin for error (meaning fewer backup resources when something goes wrong), these risks can be especially significant.
This memo examines rural invisibility in AI-related health systems, defined as the underrepresentation of rural communities in data, system design, validation, and governance. It explains why these gaps matter and why AI should be developed, tested, and governed with rural communities in mind. The term “rural” can be defined in a variety of ways, but this memo leans on the shared understanding of rural places as those with fewer people, less population density, and greater distance to services. While each rural community has a different history, strengths, resources and challenges, this memo – and the concept of “rural-proofing”, explained within – recognizes there are many shared challenges commonly faced by rural communities.
At both the national and state levels, there is an opportunity for more intentional action to recognize rural invisibility in AI systems as a policy issue. States can position themselves as proactive leaders in rural AI governance by aligning with federal frameworks while developing practical, state-level approaches. Kansas can become a leader in developing and implementing practical rural-proofing approaches that can serve as a model for other rural states. To do so, the state should take five connected steps: 1) make rural context a required part of any Kansas AI task force; 2) require rural proofing before agencies adopt or expand high impact AI tools; 3) institutionalize rural listening through trusted local partners; 4) document the Kansas model as a public blueprint other states can adapt; and 5) build a statewide rural AI literacy framework for residents,students, frontline workers, and public agencies.
Challenges and Opportunities
Rural communities have strong social connectedness, local knowledge, community leadership, and deep relationships that support resilience and innovation. Yet, they often face lower population density, greater geographic dispersion, and more limited access to services and infrastructure. In these settings, AI decisions in one domain can quickly affect others, making locally grounded context and community-level oversight especially important. As AI adoption grows, its effects on rural communities reach well beyond any single tool or system. What’s at stake is broader: how rural needs are represented in data, who has a voice in how AI decisions are made and governed, and how the benefits and burdens of AI systems and infrastructure are distributed across communities. These dynamics raise important questions about whether AI systems adequately account for rural conditions, populations, and lived experiences.
Rural Invisibility in AI Systems
Rural invisibility in AI systems occurs when rural communities are underrepresented in the data, assumptions, design, validation, and governance that shape how systems are built and used. That can make rural needs harder to see and rural harms harder to detect. In practice, it means that AI systems may be built on assumptions that do not reflect rural realities, leaving rural communities overlooked in decisions about resources, services, and policy.
The body of evidence, including the 2025 scoping review, illustrates how this invisibility carries into practice. It highlights that rural AI research is underdeveloped and that models underperform in rural settings, and the consequences of those failures are rarely studied where they are felt most. As the 2025 National Rural Health Association policy brief notes the challenge is not simply whether rural systems use AI, but whether technologies reflect the realities of fragmented records, thin staffing, and delayed care pathways. When those realities remain invisible in design and implementation, the consequences can include missed, delayed, or incorrect diagnosis, misallocation of resources, and greater strain on rural providers.
Gaps in AI Governance Frameworks
It is important to assess how well current governance approaches perform across different contexts. Current AI governance frameworks, including the National Institute of Standards and Technology Artificial Intelligence Risk Management Framework and Organization for Economic Co-operation and Development (OECD), provide a strong foundation by emphasizing fairness, transparency, accountability, and risk mitigation, but they provide limited guidance on how to operationalize these principles in rural environments. These frameworks often do not fully account for differences across settings. For example, communities and organizations vary in data availability, institutional capacity, and service infrastructure. They also differ in their ability to evaluate and govern AI tools, especially when staffing, technical expertise, and resources are uneven. Most frameworks do not require testing across small or geographically distinct populations, which can make it harder to see how AI performs in rural areas and allow disparities to go unnoticed.
In addition, current frameworks do not specify how local knowledge, professional judgment, or community perspectives, particularly those from rural communities, should be incorporated into AI oversight and decision-making, which can both algorithmic invisibility and broader forms of rural invisibility in AI. While they emphasize stakeholder engagement, they leave implementation largely undefined, which can limit the ability to identify context-specific risk. These gaps also matter because AI already shapes public benefits, legal navigation, housing, and service coordination. When trained on data shaped by past inequities, AI can deepen disparities rather than reduce them. This is why AI governance must move beyond general principles and explicitly incorporate rural proofing, accountability, and meaningful community involvement.
Federal policy remains an important lever because it can help push state policy forward by signaling priorities, shaping governance expectations, and giving states a stronger foundation for action.Current federal guidance provides a foundation for responsible AI use but offers more limited practical direction for rural settings, where sparse data, limited staffing, and fragmented service systems can affect how AI works in practice. Even though the recommendations in this memo focus primarily on actions at the state level, federal guidance on addressing rural invisibility in AI across health, education, and social systems can help create the conditions for states to act more effectively and equitably on behalf of rural communities.
The White House Office of Science and Technology Policy (OSTP) or the Domestic Policy Council (DPC) is well positioned to lead coordination across federal agencies, ensuring that rural AI implementation challenges are recognized in efforts affecting health, education, and social systems. Building on that coordination, the Office of Management and Budget (OMB) is well positioned to reinforce this work through its existing governance and procurement role to clarify how existing expectations for artificial intelligence procurement, validation, monitoring, oversight, and accountability apply in rural-serving settings. The Department of Health and Human Services (HHS), the Department of Agriculture (USDA), and the Department of Education (ED) should then help translate that guidance into practice for artificial intelligence systems and programs that directly affect rural communities. The National Institute of Standards and Technology (NIST) should provide supplemental examples showing how artificial intelligence risks can present differently in rural settings. This would strengthen implementation under existing frameworks without requiring the development of a separate framework.
Federal agencies should use existing programs to strengthen rural data infrastructure, technical assistance, and workforce readiness, and governance capacity needed for responsible AI implementation in rural communities. HHS, USDA, and ED can support rural-serving institutions directly, while NIST and other federal partners can provide tools, guidance and practical examples to help organizations implement AI responsibly and effectively.
The Need for Rural Proofing
Rural proofing is the process of systematically checking whether policies, tools, and investments reflect rural realities, avoid unintended rural harms, and support fair outcomes for rural communities. In practice, it means asking early and explicitly how a policy or AI system will function in places with lower population density, greater distance from services, thinner infrastructure, smaller administrative capacity, and different patterns of need and service use.
When applied to AI, rural proofing makes rural conditions visible across system design, data, deployment, and oversight. This includes defining clear use cases, keeping communities involved in decisions about AI, explaining what the system does and does not do, and regularly reviewing whether it creates unequal results. It also means regularly reviewing system performance, checking for weak results in small or low-volume populations, documenting when rural data is limited, and being transparent about how those limitations affect outcomes. Rather than treating rural impact as an afterthought, rural-proofing makes rural context and rural strengths a core part of design, implementation, oversight, and evaluation. Within governance processes, it also helps ensure that policies and decisions are informed by rural needs, contexts, and strengths rather than assumptions developed elsewhere.
Because many rural systems operate with limited staff, tight budgets, and shared regional responsibilities, AI governance requirements must be practical. Federal and state agencies should give rural-serving organizations the time, funding, and support needed to review systems, raise concerns, and participate in oversight. They should also provide plain-language documentation so local leaders, frontline staff, and community members can understand how decisions are being made. Finally, rural proofing requires clear accountability. When AI systems cause harm or fail to work fairly in rural communities, agencies and vendors should have a clear process to identify the problem, respond to it, and fix it (see Figure 1).
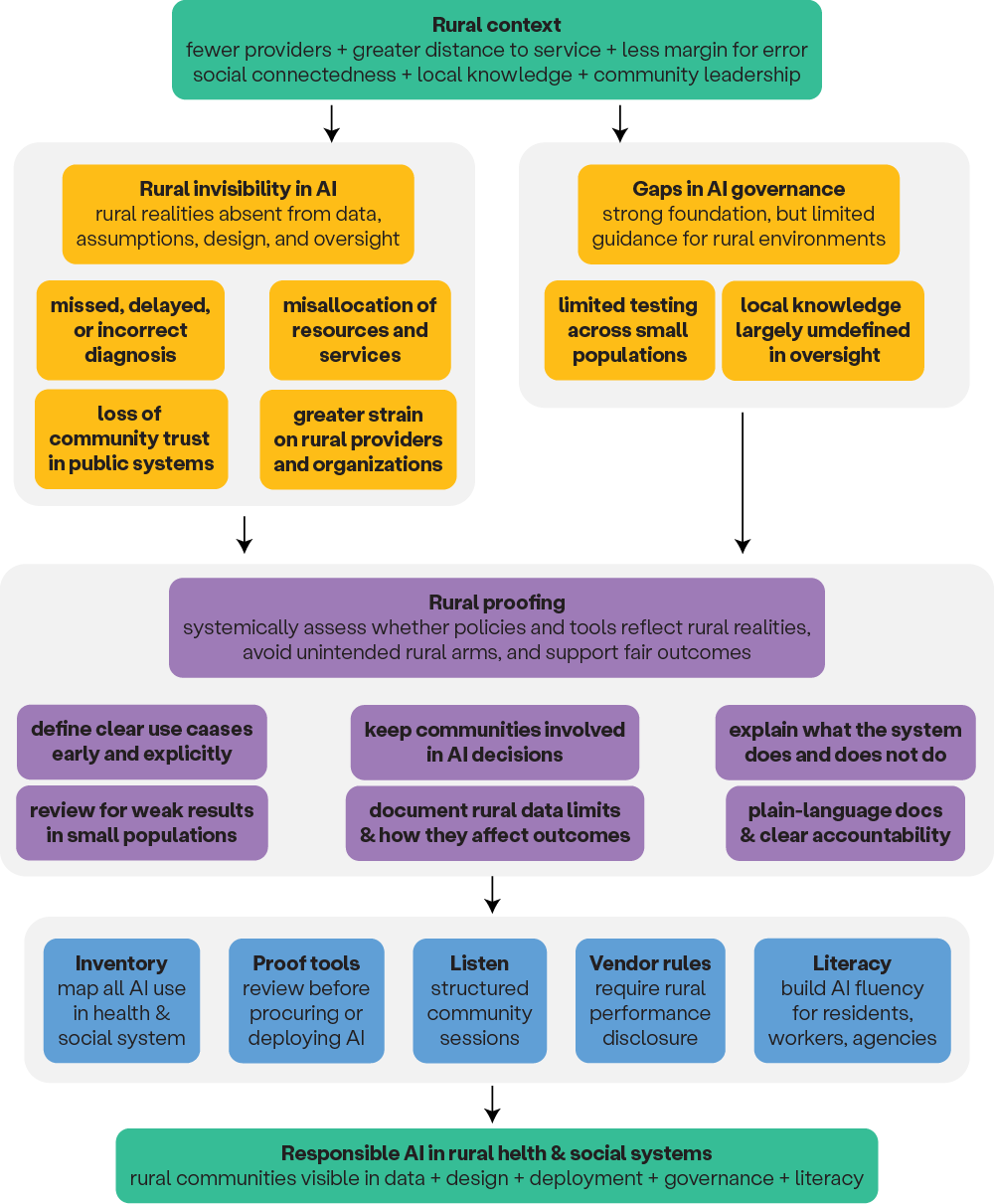
Plan of Action
Addressing rural invisibility in AI algorithms and systems across health and social sectors requires coordinated national attention and action, including the integration of rural proofing into national AI governance efforts. Because national frameworks often serve as guidance for states, progress at the national level is needed to provide the standards, expectations, and resources that support states in adapting AI governance to their specific contexts.In the meantime, states can begin building their own pathways by aligning with existing frameworks, piloting approaches in priority areas, and strengthening internal capacity.
Kansas as a Blueprint
As one of the nation’s rural states, Kansas has a strong interest in ensuring that AI systems work effectively for rural communities. As AI becomes increasingly integrated into sectors that are important to rural Kansan, including health care, education, transportation, agriculture, emergency response, public benefits, and other public services, rural-proofing can help ensure that AI tools are responsive to rural contexts.
For Kansas, this could include leveraging existing rural health infrastructure, engaging local stakeholders, and testing practical approaches that can be scaled as clearer national direction emerges. The Center for Medicare and Medicaid Services (CMS)’s Rural Health Transformation Program offers one practical pathway for aligning rural technology investment and technical assistance in Kansas with rural AI proofing principles. The Kansas Legislative Artificial Intelligence Task Force should explicitly include rural context as a defined part of its charge, membership, and workplan. The Kansas Office of Information Technology Services (OITS), the Information Technology Executive Council (ITEC), the Kansas Department of Health and Environment (KDHE), the Kansas Department for Aging and Disability Services (KDADS), and the Kansas Department for Children and Families (DCF) should work collectively to translate broad AI governance principles into practical oversight and implementation for rural health and social systems.
Furthermore, implementation of these recommendations can be staged based on current capacity, allowing agencies to begin with foundational actions and progressively build toward a more coordinated, statewide approach over time (see Figure 2).

Recommendation 1. Ensure The Kansas Legislative Artificial Intelligence Task Force and Any Future State-Level Task Forces Explicitly Include a Focus on Rural Context and Health
The Kansas Legislative Artificial Intelligence Task Force, given its role in shaping AI policy and direction, should explicitly include rural context as a defined part of its charge, membership, and workplan. The current task force already includes legislators, executive branch leadership, universities, health systems, agriculture, and private sector technology members. The taskforce’s scope could include reviewing AI use in rural contexts, incorporating rural and frontline voices into decisions around AI procurement and deployment, and issuing guidance on procurement, oversight, and accountability in rural health and social systems.
In practice, Kansas can build on the existing role of OITS by extending its coordination function to include AI-specific responsibilities, such as setting standards for evaluation, interoperability, and responsible use across agencies. ITEC can provide statewide governance direction by aligning AI efforts with broader IT strategy and policy. Service agencies, including KDHE, KDADS, and DCF would implement these efforts within health and social systems. This structure gives Kansas a practical model that other states can adapt by pairing a statewide IT authority with the agencies that directly manage public benefits, care, and social services.
- Define Scope. State-level Kansas AI task forces, working groups, and advisory bodies should explicitly include AI use and governance in rural contexts as a core scope of work, embedding rural considerations directly into the charge, membership, and workplan rather than treating them as secondary or optional.
- Coordinate Governance. Cross-agency coordination should occur through OTIS with statewide governance direction set through ITEC, while agencies including KDHE, KDADS, and DCF should identify and document where AI affects health and social service access.
- Establish Structure. Kansas should establish a clear governance structure that translates national AI principles into practical oversight, procurement, and implementation decisions tailored to rural conditions.
Recommendation 2. Require Rural Proofing for AI Used in Kansas Health and Social Service Programs
AI-enabled tools are expanding across eligibility decisions, care coordination, analytics, and service delivery. Because of this, Kansas should strengthen AI governance within the agencies that directly shape health and social outcomes. In practice, this work should begin with KDHE, KDADS, and DCF with cross-agency coordination support from OITS. Rather than relying only on broad fairness principles, these agencies should use a practical rural-proofing process to assess whether AI tools work reliably in rural settings with different staffing levels, service access, broadband conditions, data volume, and administrative capacity. Taking these steps now would help Kansas clarify oversight responsibilities, procurement standards, and rural risk before AI becomes more deeply embedded in public systems.
- Inventory. KDHE, KDADS, and DCF should identify and document current and planned uses of automated decision tools and AI systems used in decision-making that affect eligibility, benefits, care access, case management, service coordination, navigation, and enforcement. Agencies should require vendors to inventory AI used in care management, prior authorization, utilization management, member outreach, and provider network decisions. Kansas can then expand this inventory approach to other agencies that shape health, including housing, transportation, workforce, education, justice, and environmental systems.
- Rural AI Proofing. Agencies should apply rural-proofing review before they procure, renew, expand, modify, or deploy high-impact AI systems. This review should assess whether the tool performs reliably in rural settings, whether rural data are sufficient for validation, whether lower service use is being misread as lower need, and whether the system creates added burdens in places with limited staff, broadband, transportation, or service infrastructure.
Governance and Coordination. Kansas should establish a centralized cross-agency approach to AI governance to ensure consistency and avoid fragmented implementation across agencies. A coordinated structure—led jointly by OITS and state procurement—should define statewide oversight, reporting expectations, and minimum standards for the use of AI and automated decision tools. - Strengthen and Formalize AI Governance. Within this structure, agencies should strengthen and formalize AI governance by assigning clear oversight responsibility, documenting risk management and vendor review practices, incorporating transparency and explainability requirements, and building internal and community-level AI literacy. Agencies should also implement consistent oversight and reporting expectations for vendor AI use, including requirements for rural proofing, audit, and review mechanisms. OITS, in coordination with state procurement, should provide cross-agency technical guidance, ensure consistency in procurement standards, and align AI use with state IT and data governance policies. Individual agencies should retain program-level oversight within their statutory authority while operating within this coordinated governance framework.
- Vendor Requirements. Require vendors to explain how their AI tools perform in rural settings, disclose known data and performance limits, identify human review points, and provide plain-language documentation on system purpose, intended use, and potential failure points.
Recommendation 3. Institutionalize Rural Listening through Trusted Intermediaries
Meaningful engagement with rural communities is especially important in this context because AI systems are often designed and evaluated far from the places where their effects will be felt. However, engagement alone is insufficient. This recommendation draws a deliberate distinction between consultation, where agencies ask communities what they think, and co-governance, where rural communities hold real influence over AI decisions that affect them. Kansas should aim for co-governance, not just input collection In rural areas, where access to care, public services, transportation, broadband, and legal support may already be limited, even small design flaws or inaccurate assumptions can have outsized consequences. Regular listening with rural residents and trusted local partners can help surface needs, barriers, and unintended harms that may otherwise remain invisible in statewide decision-making.
- Support. OTIS or the Governor’s Office should coordinate recurring AI listening sessions, with participation from KDHE, KDADS and DCF, and with research and facilitation support provided by Kansas public universities.
- Leverage Partners. OITS and KDHE, KDADS, DCF should engage Kansas public universities to support session design, facilitation, documentation, synthesis of findings, and evaluation to ensure structured feedback and continuity across sessions.
- Conduct Sessions. KDHE, KDADS, DCF in partnership with county and local public health agencies, behavioral health providers, university extension networks, libraries, legal aid and court self-help programs, and community-based organizations, should conduct sessions using a shared calendar and unified feedback process.
- Apply Findings. KDHE, KDADS, DCF should use listening sessions as a rural-proofing mechanism to assess how AI-enabled tools in health, benefits, and social service programs affect access to care, legal protections, and social determinants of health in rural settings.
- Integrate Oversight. OITS and KDHE, KDADS, DCF should integrate findings into state oversight by documenting recurring rural issues, flagging systems for review, and using insights to strengthen procurement, monitoring, and accountability for AI systems used in Kansas programs.
Recommendation 4. Establish a Kansas ‘Rural AI Health Governance Blueprint’ for Other Rural States to Replicate
Clear leadership at the state level matters because rural proofing is unlikely to be applied consistently if agencies and vendors are left to interpret it on their own. A statewide approach creates shared expectations, strengthens accountability, and makes clear that rural context should be built into procurement, oversight, and evaluation from the beginning. This approach is also replicable because it relies on documented processes, practical tools, review steps, and implementation lessons that other rural states can adapt to fit their own governance structures, service systems, and community conditions. The framework should also incorporate AI infrastructure impacts, including data center siting, to ensure rural-proofing standards address the distribution of resource, environmental, and land use burdens associated with AI development.
- Document Framework. OITS, in coordination with the Information, ITEC and participating agencies such as KDHE, KDADS, and DCF, should document Kansas’s rural AI governance framework in a public implementation guide, including rural-proofing standards, shared workflows, listening session models, and transparency practices.
- Assess and Evaluate. KDHE, KDADS, DCF should partner with Kansas public universities to assess outcomes, identify lessons learned, and produce evidence-based recommendations to strengthen rural AI governance over time.
- Share and Scale. OITS and participating agencies should share implementation tools, templates, rural-proofing checklists, and model policies through interstate networks such as the National Governors Association, the National Conference of State Legislatures, and state rural health associations so other states can adapt the Kansas model.
- Pilot Collaboration. OITS, with support from Kansas public universities and partner agencies, should pilot cross-state collaboration with at least two predominantly rural states to test whether the Kansas workflow can transfer across different governance structures, agency arrangements, and service systems.
- Demonstrate Practice. OITS, state service agencies, and university partners should position Kansas as a practical demonstration state by showing how rural proofing can translate broad AI governance expectations into workable state practice that reflects rural conditions, administrative limits, and community realities.
Recommendation 5. Establish a Standardized and Contextualized Kansas Rural AI Health Literacy Framework
Kansas should complement the upstream AI governance framework with a statewide Rural Health AI Literacy Framework to ensure residents, students, and frontline workers can engage AI systems critically. Unlike general AI literacy, which often focuses on basic awareness of AI tools and digital skills, rural health AI literacy should prepare residents, students, frontline workers, and public institutions to understand how AI can shape health access, eligibility, referrals, triage, service coordination, and related decisions in rural communities. Governance structures alone are insufficient if communities lack shared standards for understanding how AI affects eligibility, health access, agriculture, transportation, and legal services in rural settings. The Kansas State Department of Education (KSDE), in coordination with the Kansas Board of Regents (KBOR) and the Kansas Office of Information Technology Services (OITS), should lead development of tiered, age-appropriate AI literacy competencies spanning K–12, postsecondary education, and public-sector roles.
To operationalize this framework, Kansas should:
- Integrate Curriculum. KSDE should integrate AI literacy into digital literacy, civics, agricultural education, and career and technical education standards, with support from Regional Education Service Centers for teacher training.
- Embed in Higher Education. KBOR should embed AI literacy modules into general education requirements and first-year seminars across public universities and community colleges, aligning with Higher Learning Commission expectations.
- Establish Rural Hubs. Kansas State University and Cooperative Extension should serve as rural AI literacy hubs delivering applied programming for health, agriculture, and local government sectors.
- Expand Community Delivery. State agencies and education partners should collaborate with public libraries, Tribal education departments, workforce development boards, and community-based organizations to deliver multilingual AI literacy programming statewide.
- Train Public Workforce. State agencies should implement baseline AI literacy training for employees in health, eligibility, and human service roles.
Conclusion
As AI becomes more embedded in public systems affecting health and social outcomes, it is important to account for rural context, particularly in Kansas, where many communities operate under conditions that differ from those assumed in typical AI development and deployment environments. These conditions include greater data sparsity, lower service density, and constrained institutional capacity for oversight. The proposed recommendations aim to operationalize responsible AI principles through coordinated cross-agency governance, integration of rural proofing into existing structures, and stronger community engagement in AI decision-making. By acting now, Kansas can build a more accountable model for rural AI governance and offer other rural states a practical path forward.
Rural health refers to the health outcomes, service access, and community conditions that shape well-being in rural communities. It includes access to healthcare, behavioral health, substance use treatment, prevention, workforce capacity, transportation, and the social determinants of health that affect whether rural residents can receive timely and appropriate care.
Common federal rural definitions include those developed by the U.S. Census Bureau, the Office of Management and Budget, and the U.S. Department of Agriculture Economic Research Service. The ideas, challenges and recommendations presented here within, but are not limited by, common rural definitions used across public health and health care. While rurality exists on a spectrum, definitions often use some combination of population thresholds, population density, housing density, and proximity to dense urban areas to define levels of rurality and urbanicity.
They should establish AI governance structures and policies, inventory current and planned AI use, assess whether tools are necessary and can function effectively in rural settings, document rural data limitations and oversight responsibilities, require vendor disclosure, and provide plain-language information about how systems work and how human review and oversight are incorporated into decision-making.
AI vendors should explain how their systems perform in rural settings, disclose known data and performance limitations, identify human review points, and provide plain-language documentation on system purpose, intended use, and conditions under which performance may vary.
Listening sessions help state agencies hear directly from rural residents, frontline workers, and local organizations about how AI affects access to care, benefits, legal navigation, and other services in practice. The memo recommends using those findings to improve procurement, monitoring, and accountability.
“Going Back to Cali” for AI Governance Lessons as States Take the Lead on AI Implementation
Imagine you are a state-level technology leader. Recent advancements in artificial intelligence promise to make approving small business licenses faster, or improve K-12 student learning, or even standardize compliance between agencies. All of which promise to improve the experience of your state’s constituents. Eager to deploy this new technology responsibly, you look to peers in other states for guidance. Their answers vary wildly, and in the absence of federal guidance, it quickly becomes clear that there is no standardized playbook. You must chart the path forward on your own, with far more limited resources.
This scenario is becoming increasingly common as AI systems are moving rapidly into consumer-facing services. Without federal action on AI, state government leaders are increasingly shouldering the responsibility for both protecting consumers from potential algorithmic harms and also supporting responsible innovation to improve service delivery to their constituents. States have structural advantages that position them to experiment with regulatory approaches: shorter legislative cycles that allow for quicker course corrections, authority to pilot programs, and the use of sunset provisions that make it easier to revise or retire early-stage governance models. This often places states as the most agile regulators who can swiftly set up guardrails for rapidly evolving AI technologies that impact their residents.
But this regulatory agility must be matched with the necessary government capacity in order to be a success. The current lack of federal action is forcing states not only to pass new AI laws, but also to take on huge implementation challenges, without the AI expertise typically found in federal agencies or major private employers. Building this capacity within state governments will demand resources and technical expertise that most states are only just starting to chart . Without deliberate investment in transparency and talent, even the most well-crafted legislation might not achieve their intended goals. As State legislative cycles start back up for the 2026 year, state policymakers should move forward with proposals that increase transparency, accountability, and bring new technical experts directly into government to meet the scale of need in the current moment.
Increased Transparency to Build Public Trust
One of the most immediate ways that state legislatures can move forward with transparency-improving legislation is with the passage and successful implementation of use-case inventories. A use-case inventory is a public-facing publication of algorithmic tools and their specific uses. They disclose when and where state governments are utilizing algorithmic tools in consumer-facing transactions such as applications for social programs and public assistance benefits. They are typically conducted by governments as a mechanism for transparency and to facilitate third-party auditing of outcomes.
The benefits of public-facing AI use-case inventories are far reaching: they increase government transparency into automated decision-making outcomes, can provide valuable insights to private-sector product vendors, facilitate third-party auditing and bias-testing, and can even increase interagency sharing of best practices when AI tools are effectively used. They are particularly important in high-risk decisions such as those related to government benefits and services. Alternatively, a lack of transparency in expensive acquisitions from private and third party vendors can mean that an agency or entity is unaware of what tools they have acquired and whether or not they are safe to deploy in consumer-facing settings without bias or other inaccuracies.
When increasing numbers of Americans are growing skeptical of the practical uses of AI tools, it is doubly important to design public systems that encourage transparency when algorithmic tools are deployed in the public and private sectors alike.
Despite a lack of federal legislation regulating responsible AI usage, one area where the federal government has led is in the production of regular AI use-case inventories since 2021. First requested via Executive Order 13960 in 2020 during the first Trump administration, and implemented in the Summer of 2021, the federal government provides a relatively transparent accounting of where AI is adopted within the federal enterprise. This policy has had bipartisan appeal, and the Biden administration continued the production of regularly updated inventories for the public. The Trump administration with its recently updated inventory now has the opportunity to use this tool to deliver increased public trust in AI, a clear administration priority.
Case Study: Implementation Challenges in California
While the federal experience demonstrates that AI use-case inventories can work, it also reveals an important limitation: transparency mechanisms rely on technical talent and focused implementation to be successful. California offers a cautionary example. In 2023, the state legislature passed Assembly Bill 302 requesting the State Department of Technology to “conduct a comprehensive inventory of all high-risk automated decision systems [ADS] being used by state agencies and submit a report to the Legislature by January 1, 2025, and annually thereafter.” Importantly, the bill covered systems that are “used to assist or replace human discretionary decisionmaking.” The bill was envisioned as a critical first step in gaining insight into the ways AI was being deployed in consumer-facing interactions by state government agencies. It was also in reaction to public reporting of biased technology being used on those applying for public services and benefits.
However, the initial implementation deadline for the bill passed in early 2025 and the only report provided to the public was a single document stating that there are “no high-risk ADS [tools] being used by State agencies”—a fact that is easily disputed by a simple Google search. For example, the state healthcare exchange uses automated document processing tools to gauge eligibility for affordable health insurance policies, the state unemployment insurance program uses an algorithmic tool developed by a private company to rate applicants on the likelihood of their application being fraudulent, and the state Department of Finance even plans to use generative AI tools as part of fiscal analysis and state budgeting work. These are significant decisions that can have real repercussions for California residents. Rather than creating a transparent use-case inventory that can tell Californians where AI is being used in consumer-facing interactions, we instead have a letter which incorrectly states —based on examples above—that there are no algorithmic tools being used. The table below has additional examples of publicly disclosed automated decision-making system use cases in California state government.
Results like this underscore the urgent need to embed technical talent within state governments to ensure that laws are implemented as designed. When implementing its use case inventories, the federal government provided guidance to reporting agencies and publicly released a final inventory for a majority of agencies. Even with substantial support during the federal government’s collection process, there were still notable implementation challenges faced when creating a federal use-case inventory. Most notably, many agencies initially failed to disclose all use-cases, and a promised template for agencies to use has yet to come to fruition. The State of California, by contrast, instead relied on an ad hoc process, polling state agency officials through two successive emails to conduct its inventory evaluation.
Scaling Government Talent to Bridge the Technical Capacity Gap
California’s experience implementing a use-case inventory is, unfortunately, not unique. Across the country, well-intentioned legislation is often passed into law only to falter during implementation. Once enacted, agency staff are tasked with operationalizing complex policies, often without the necessary technical expertise, staffing capacity, or financial resources to succeed. Without deliberate investment in these areas, the responsibility of properly regulating emerging technologies and protecting consumers from harm is shifted to government employees that are poorly equipped to handle the growing scope and technical complexity of their workloads. That is why, in addition to transparency, states need to find ways to quickly bring in technical talent and expertise in digital technologies to drive forward effective implementation of the coming onslaught of bills.
In the midst of massive layoffs within the federal government and private sector, individual states now have access to historic levels of human capital and can bring forward some of the innovations developed within the federal government in recent years. Methods like skills-based hiring to rapidly bring in technical talent and scale new teams within government have also been developed and thoroughly tested in recent years through entities like the United States Digital Service (USDS) and the Consumer Financial Protection Bureau’s in-house technologists. These initiatives brought skilled workers into government at less than half the recruiting cost of private sector hiring and saved hundreds of millions of dollars through reimbursable agreements with agencies in lieu of costly private sector consultancy contracts.
During periods of financial uncertainty it can be deeply challenging for state leaders to make the investments necessary to hire additional staff and build robust government teams. One other method to bridge the gap between policymakers and those who implement it is through the development of modernized policy fellowships that utilize endowments or other private funds to bring cutting-edge researchers and experts directly into government. California has most recently unveiled a revamped science and technology fellowship that will place additional AI experts within state agencies or the legislature to propel forward-thinking and informed policymaking.
Conclusion
With no federal framework in place, state governments will be the primary drivers of accountability and transparency needed to ensure AI serves the public rather than erodes democratic norms. This presents us with a crucial window for state policymakers to establish both processes that further transparency and robust talent pipelines that can manage responsible deployment in order to restore public trust and prevent harms before AI systems become further entrenched in critical public services. States that build transparent AI use-case inventories and invest in technical expertise will be best positioned to translate lofty regulatory principles into real protections for their citizens—while also fostering a fairer, more trustworthy environment for innovation to thrive.
The FAIR in Education Act: Federal coordination to support responsible AI deployment
Artificial Intelligence (AI) has the potential to enhance education systems by personalizing student learning, providing real-time feedback, and streamlining administrative tasks to optimize teachers’ time and focus on instruction. AI, like other classroom technologies, can expand access to educational resources and when used properly, support student engagement. However, no long-term studies on the impacts of generative AI on student learning outcomes and the cognitive abilities of early learners exist and issues around algorithm transparency and data security persist. To meet these challenges, we propose a Framework for AI Responsibility (FAIR) in Education Act, a Governor’s Conference, and the establishment of a national center to support AI deployment in K-12.
Challenge and Opportunity
No Guardrails or Guidance
Successful integration of classroom technologies relies on the availability and stability of infrastructure as well as the readiness of the end users. The United States AI Action Plan and Advancing Artificial Intelligence Education for American Youth Executive Order aim to promote streamlined pathways for AI adoption. However, neither provide any practical implementation guidance for the responsible deployment of AI in educational settings nor allocate funds to support the local infrastructure necessary. Current actions also fail to address longstanding concerns regarding data privacy, the establishment of guardrails to mitigate algorithm bias, and efforts to reduce the digital divide which are increasingly more important upon interactions with minors.
AI competency is becoming a necessary skill for the future, much like knowing how to use a search engine effectively to navigate online information. Students who understand how AI works, its limitations, and its potential biases will be better equipped to navigate the technology driven world we live in. Establishing guardrails and guidance is not meant to restrict student access to AI, but aims to ensure students can use these tools safely and responsibly. Proper guardrails, transparency, and guidance allow students to leverage AI as a learning aid while minimizing risks to privacy, fairness, and well being.
In the absence of guardrails and guidance, AI can increase inequities, introduce bias, spread misinformation, and risk data security. These negative impacts are often exacerbated in communities that are marginalized or economically disadvantaged. Simply put, the current posture towards AI puts the cart before the horse. The United States needs a better understanding of the impact of AI on student learning and clear guardrails before introducing it large-scale.
More Data Needed
Reeling from the impacts of the COVID-19 pandemic on student learning, such as learning loss and widening achievement gaps, the most recent National Assessment of Educational Progress asserts a clear decline in K-12 science, reading, and mathematics proficiencies compared to 2019. The results of the study will be used to inform educational reforms, however, educators and policymakers should be cautious in framing AI as the cure-all for America’s educational challenges. The promises of similar tech-driven advances foreshadow a likely failed result if the policy does not adapt accordingly .
Currently, there are no federal guidelines that govern AI usage in the classroom and there are no longitudinal studies on AI’s impact on student learning and cognitive development. Short-term studies have demonstrated that AI can have a positive effect on student learning, however, results are highly variable and context specific. In addition, there are significant risks, such as student overreliance on the technology, especially generative AI chatbots. Early learners are particularly at risk for negative impacts and it is unknown how AI use impacts deeper learning and information retention and synthesis. Studies indicate that technology use among school-aged children can negatively affect attention spans, self-control, cognitive development, and problem-solving skills. Moreover, AI chatbots may pose psychological impacts or “empathy gaps” in children that are not well understood. Only recently has the Federal Trade Commission launched an inquiry into the impact of AI chatbots on children. We need more data on the long-term impacts of AI in the classroom in order to develop coherent policies that support educators and learners.
These shortcomings do not imply that AI cannot have a place in the classroom. Instead it demonstrates that a comprehensive understanding of AI’s impact is necessary before its use is scaled up. Furthermore, algorithm transparency is paramount for minimizing bias, ensuring student psychological safety, and promoting data security. Organizations like TeachAI, acknowledge some of these risks and provide resources for schools and universities developing AI policy, however, there is still much to learn.
Federal Support and Coordination are Paramount
Uncertainty around the future of federal support for education and education research is also a key challenge. The Department of Education (DoEd) is currently responsible for addressing national educational issues by setting federal policy, supporting equal access to education, protecting civil rights, collecting educational data, and analyzing trends. The DoEd also works to hold institutions and States accountable for educational outcomes. The current administration, however, has a stated goal of abolishing the DoEd and sending those powers to States. While States should be empowered to support policy development and implementation, federal coordination and oversight is vital for protecting civil rights and understanding long-term national education trends.
If the DoEd is abolished, it is uncertain what government agency would assume responsibility for the development, monitoring, and evaluation of educational standards at the precipice of the AI age. If States are tasked with this responsibility, it will require sustained financial federal support. Proposed cuts to the National Science Foundation (NSF) STEM Education Directorate and other STEM education federal funders would limit the ability for education researchers to effectively assess the impact of AI on the educational and psychological development of students or develop tools for the effective use of AI.
Implementation Requires Community Involvement
While current federal initiatives are in place promoting the role of AI in education, their ultimate success depends on meaningful training experiences for educators and strong collaboration with State and local stakeholders. Federal frameworks, such as the April 2025 Advancing Artificial Intelligence Education for American Youth Executive Order (E.O. 14277), addresses the critical need to provide America’s youth with opportunities to cultivate AI competency, but it does not express the major value of having States and local districts leading the implementation effort to ensure that AI integration meets community needs, supports student achievement, and strengthens workforce development.
State and local communities could potentially draw on federal resources under this E.O. (if available) and work collaboratively with education-focused professional societies, such as the National Science Teachers Association (NSTA) and the Computer Science Teachers Association (CSTA) to help develop community-created standards, define clear metrics, and continuously evaluate what works within their specific contexts. Initiatives such as NSF’s EducateAI and the National AI Research Resource (NAIRR) offer curriculum models, research infrastructure, and other resources that can complement any locally developed approaches. These federal programs can also support collaborative networks among educators, researchers, and industry partners to share best practices and insights. However, realizing the full potential of these federal programs first requires providing teachers with professional development and training to use AI tools effectively and confidently in the classroom, because even the most advanced resources are only as impactful as the educators who apply and understand them.
Recommendations
Framework for AI Responsibility (FAIR) in Education Act
Congress should propose legislation on the responsible use of AI in education. This comprehensive act, known as the Framework for AI Responsibility in Education Act or the FAIR in Education Act, would support a large-scale study on the impact of AI on education, provide funding for education research, support State leadership in AI in education, require greater algorithm transparency for algorithms influencing minors, and provide infrastructure for ongoing monitoring and assessment of a community-centered implementation of AI technologies in the classroom. This legislation should address both K-12 use and higher education.
First, the FAIR in Education Act should instruct the National Academies of Science, Engineering and Mathematics (NASEM) to conduct a study and report on the impact of AI in K-12 schools, higher education, and informal learning settings such as libraries and museums. This landscape study should address student learning, the impact on cognitive abilities, psychological impacts, the ethical use of AI, and provide recommendations for how the federal, state, and local governments can support AI literacy and teacher education.
Next, the use of AI in the classroom raises several academic integrity and scientific integrity issues, including plagiarism, authorship and credit, accuracy, reliability of AI outputs, reproducibility, and data bias. The FAIR in Education Act should instruct the Committee on STEM Education (CoSTEM), a subcommittee of the National Science and Technology Council under Office of Science and Technology Policy (OSTP), to within 270 days of passage of the act provide guidance to assist educational institutions in thoughtfully updating their own definitions of academic integrity in light of AI and other technologies used in educational settings. This guidance would help institutions uphold ethical standards while enabling the responsible use of AI in learning and assessment.
The Act should also require transparency in how AI algorithms used in education are trained, what data was used, and how the guardrails were tested. Educators should be aware of the design decisions and development processes that engineers made for the algorithms and how those decisions might affect the use of AI as a tool to enhance student learning. Such transparency will enable educators to guide students effectively in using AI as a learning tool, particularly supporting equitable outcomes among disadvantaged communities.
The Act will direct federal funds to support the requisite infrastructure and security needed to safely use AI. There are examples from previous administrations of funding opportunities and convenings through the Federal Communications Commission (FCC) to support school district cybersecurity and the infrastructure required to support AI and high speed internet use. Additionally, the Act would support streamlined implementation of the Broadband Equity, Access, and Deployment Program to address high speed internet access across the country.
The responsible use of AI requires not only federal engagement, but State engagement as well. The FAIR in Education Act will require Federal, State, and local coordination on AI use in the classroom and facilitate continued monitoring and evaluation. The Act will also increase funding for teacher professional development, with emphasis on development and training for STEM fields. We envision these goals will be accomplished through the funding and development of a “Supporting Pedagogy and AI Readiness in K-12” (SPARK) Center, which will be informed by an inaugural country-wide Governor’s conference.
Governor’s Conference – State-Led Design of the SPARK Center
The creation of the SPARK Center should be conducted in cooperation with state and local officials, as well as parents, educators, and students. The education system in the United States is heavily dependent on state and local government to provide leadership in the implementation of new initiatives or educational practices, and thus it is essential that they are involved in the decision making. To begin incorporating these essential voices, we recommend hosting a“Governor’s Conference” with a primary focus on AI in education, and specifically the community driven design of the SPARK Center. The National Governor’s Association (NGA) Center for Best Practices has a program area focused on K-12 education and previously led a Governor’s convening on a K-12 education agenda in 2023. NGA can utilize these existing networks to drive a new focus on the use of AI in education, and preparation and design of the SPARK Center.
As of September 2025, thirty States have issued guidance on AI in Education. At the conference, Governors can share the successes and challenges of their current AI policies as they relate to education, engage in real-time conversations with teachers, students, and parents, and inspire policy action in States which may not yet have infrastructure in place to support the responsible deployment of AI in their own education systems. Attendees should include all state Governors (or their proxies, such as Secretaries of Education or people in similar positions), representatives from the American Federation of Teachers, the National Education Association, the Association of American Educators, the Superintendents Associations, possible NGOs such as the leadership from CSTA and NSTA, administrators of TeachAI, and relevant NSF funded researchers and academics conducting pedagogical studies on AI impacts on education and childhood development. In addition to representatives from state Governor offices, educators from local school districts must be an essential part of this process to garner buy-in and receive guidance from the final users.
The event organizer should consider the best way to integrate parent and student feedback into the outcomes of the conference, such as dedicating one day of the conference specifically to receive their feedback through Track 1.5 roundtables, or stakeholder prepared presentations. The goal of the conference is to create an opportunity for state governments to learn where there are insurmountable challenges in the deployment of AI in education for States to address independently, and where students could benefit from federal standardization of the U.S. approach. The outcome of the conference should lead to a deployable roadmap and fulsome design of the SPARK Center, including the accumulation of educational training resources for teachers and teachers associations. It could also lead to the percolation of new initiatives for the federal government, such as drafted federal guidelines for AI in K-12 education, a new country-wide grand challenge, or an increase in funding or resources provided to the States. It could also lead to the design of a new research and potential pilot projects conducted by the NGA’s Center for Best Practices. These are solely illustrative examples, and will ultimately be determined by the involved participants.
A community-created approach, paired with federal resources, enables a two-way exchange in which federal guidance informs local practice, while lessons learned from schools will feed back into federal research, policy, and frameworks. This partnership will ensure AI is integrated responsibly, equitably, and effectively across the education system in America.
Supporting Pedagogy and AI Readiness in K-12 (SPARK) Center
For AI to truly benefit classrooms, communities must create, establish, and embrace standards to help guide responsible AI use and effectiveness. These efforts, such as CSTA’s AI Learning Priorities, will be bolstered through the establishment of the SPARK Center per the FAIR in Education Act.
To maximize AI benefits and minimize risks, AI use in the classroom must be guided by community-created standards. Education stakeholders including students, teachers, and families need to be involved with defining how AI is used in the classroom to ensure it aligns with local values, protects student data, and supports student-centered, teacher-facilitated learning. State and local leadership, creating essential policies for these standards, is critical in order to adapt practices to local contexts and to monitor effective classroom use. What works in one district or school may not work elsewhere; standards must be flexible and informed by the community stakeholders because a one-size-fits all approach will not work in every school across America.
Effective AI use requires ongoing monitoring and evaluation. At a local level, schools should track learning outcomes, student experiences, teacher workload, and overall engagement and productivity with the technology. Feedback from students, teachers, and education stakeholders should be a part of every assessment monitoring and evaluation cycle to help improve AI adoption in the classroom. Implementing routine monitoring and evaluation cycles will enable schools to adjust AI practices, identify unintended consequences, and ensure AI is supporting the learning objectives established in the curriculum instead of creating new challenges in the classroom.
This work overall can be burdensome across teachers and school districts. If a community realizes that the deployment of AI in their educational infrastructure is not reaching anticipated goals, or potentially even causing unintended negative consequences across students, there are few places for educators to turn for answers. The SPARK Center will be designed to be a federally managed resource which manages the monitoring and evaluation capacities across the country, and compiles best practices for educators to pull from based on their analyses. Other functions of the center will be determined through a community-driven approach, and informed by a Governor’s Conference convened at the federal level.
Conclusion: Connecting Federal Support to Advance Community-Created Approaches
AI has enormous potential to enhance teaching and learning but only if its adoption is guided by communities, led locally, and continuously monitored. By combining student-centered, teacher-facilitated classroom practices with State and local guidance and federal support, schools can ensure AI empowers both educators and students while safeguarding equity, ethics, and critical thinking. Federal support should strengthen these community centered approaches, providing resources and guidance without replacing local decision making.
The views contained in this memo reflect the personal views of the authors.
Analytical Literacy First: A Prerequisite for AI, Data, and Digital Fluency
As digital technologies reshape every aspect of society, students must be equipped and proficient in not only specialized literacies (such as digital literacy, data literacy, and AI literacy), but with a foundational skill set that allows them to think critically, reason logically, and solve problems effectively. Analytical literacy is the scaffolding upon which more specialized literacies are built. Students in the 21st century need strong critical thinking skills like reasoning, questioning, and problem-solving, before they can meaningfully engage with more advanced domains like digital, data, or AI literacy. Without these skills, students may struggle to engage critically with the technologies shaping their lives. We urge education leaders at the federal, state, and institutional levels to prioritize development of analytical literacy by incentivizing integration across disciplines, aligning standards, and investing in research and professional development.
Introduction
As society becomes increasingly shaped by digital technologies, data-driven decision-making, and artificial intelligence, the ability to think analytically is no longer optional, it’s essential. While digital, data, and AI literacies focus on domain-specific skills, analytical literacy enables students to engage with these domains critically and ethically. Analytical literacy encompasses critical thinking, logical reasoning, and problem-solving, and equips students to interpret complex information, evaluate claims, and make informed decisions. These skills are foundational not only for academic success but for civic engagement and workforce readiness in the 21st century.
Despite its importance, analytical literacy remains unevenly emphasized in K–12 education. These disparities are often driven by systemic inequities in school funding, infrastructure, and access to qualified educators. According to NCES’s Education Across America report, rural schools and those in under-resourced communities frequently lack the professional development opportunities, instructional materials, and technology needed to support analytical skill-building. In contrast, urban and well-funded districts are more likely to offer inquiry-based curricula, interdisciplinary projects, and formative assessment tools that foster deep thinking. Additionally, while some schools integrate analytical thinking through inquiry-based learning, project-based instruction, or interdisciplinary STEM curricula, there is no consistent national framework guiding its development at this time. Instructional strategies vary widely by state or district, and standardized assessments often prioritize procedural fluency over deeper cognitive engagement like analytical reasoning.
Recent research underscores the urgency of this issue. A 2024 literature review from the Center for Assessment highlights analytical thinking as a core competency for future success, noting its role in supporting other 21st-century skills such as creativity, collaboration, and digital fluency. Similarly, a systematic review published in the International Journal of STEM Education emphasizes the need for early engagement with analytical and statistical thinking to prepare students for a data-rich society.
There is growing consensus among educators, researchers, and policy advocates that analytical literacy deserves a more central role in K–12 education. Organizations such as NWEA and Code.org have called for stronger integration of analytical and data literacy skills into curriculum and professional development efforts. However, without coordinated policy action, these efforts remain fragmented.
This memo builds on that emerging momentum. It argues that analytical literacy should be treated as a skill that underpins students’ ability to engage meaningfully with digital, data, and AI literacies. By elevating analytical literacy through standards, instruction, and investment, we can ensure that all students are prepared to participate, innovate, and thrive in a complex and rapidly changing world.
To understand why analytical literacy must be prioritized, we examine the current landscape of specialized literacies and the foundational skills they require.
Challenges and Opportunities
In today’s interconnected world, digital literacy, data literacy, and AI literacy are no longer optional, they are essential skill sets for civic participation, economic mobility, and ethical decision-making. These literacies enable students to navigate online environments, interpret complex datasets, and engage thoughtfully with emerging technologies.
- Digital literacy encompasses the ability to use technology effectively and critically, including evaluating online information, understanding digital safety, and engaging ethically in digital environments.
- Data Literacy involves the capacity to understand, interpret, evaluate, and communicate data. This includes recognizing data sources, identifying patterns, and drawing informed conclusions.
- AI Literacy entails understanding the basic concepts of artificial intelligence, its applications, ethical implications, and how to interact with AI systems responsibly.
Together, these literacies form a cognitive toolkit that empowers students to be not just consumers of information and technology, but thoughtful participants in civic and digital life.
While these literacies address specific domains, they all fundamentally rely on what should be called Analytical Literacy. Analytical literacy, at its core, involves the ability to:
- Ask insightful questions. Identifying the core issues and seeking relevant information.
- Evaluate information critically. Assessing the credibility, bias, and relevance of sources.
- Identify patterns and relationships. Recognizing connections and trends in complex information.
- Reason logically. Constructing sound arguments and drawing valid inferences.
- Solve problems effectively. Applying analytical skills to find solutions and make informed decisions.
Yet, without structured development of these foundational skills, students risk becoming passive consumers of technology rather than active, informed participants. This presents an urgent opportunity: by centering Analytical Literacy in standards and assessment, instruction, and professional learning, we can create enduring pathways for students to participate, innovate, and thrive in an increasingly data-driven world.
Examples of implementation must include:
- In Standards and Assessment. States should revise academic standards to include grade-level expectations for analytical reasoning across disciplines. For example, middle school science standards might require students to construct evidence-based arguments using data, while high school civics assessments could include open-ended questions that ask students to evaluate competing claims in news media.
- In Instruction. Teachers should embed analytical skill development into daily practice through inquiry-based learning, Socratic seminars, or interdisciplinary projects. A math teacher could guide students in analyzing real-world datasets to identify trends and make predictions, while an English teacher might use argument mapping to help students deconstruct persuasive texts.
- In Professional Learning. Districts should offer workshops that train educators to use formative assessment strategies that surface student reasoning such as think-alouds, peer critiques, or performance tasks. Coaching cycles should focus on how to scaffold questioning techniques that push students beyond recall toward deeper analysis.
By embedding these practices systemically, we move from episodic exposure to analytical thinking toward a coherent, equitable framework that prepares all students for the demands of the digital age.
Addressing these gaps requires coordinated action across multiple levels of the education system. The following plan outlines targeted strategies for federal, state, and institutional leaders.
Plan of Action
To strengthen analytical literacy in K–12 education, we recommend targeted efforts from three federal offices, supported by state agencies, educational organizations, and teacher preparation programs.
Recommendation 1. Federal Offices
Federal agencies have the capacity to set national priorities, fund innovation, and coordinate cross-sector efforts. Their leadership is essential to catalyzing systemic change. For example:
White House Office of Science and Technology Policy (OSTP)
OSTP now chairs the newly established White House Task Force on Artificial Intelligence Education, per the April 2025 Executive Order on Advancing AI Education. This task force is charged with coordinating federal efforts to promote AI literacy and proficiency across the K–12 continuum. We recommend that OSTP:
- Expand the scope of the Task Force to explicitly include analytical literacy as a foundational competency for AI readiness.
- Ensure that public-private partnerships and instructional resources developed under the order emphasize reasoned decision-making as a core component, not just technical fluency.
- Use the Presidential Artificial Intelligence Challenge as a platform to showcase interdisciplinary student work that demonstrates analytical thinking applied to real-world AI problems.
This alignment would ensure that analytical literacy is not treated as an adjacent concern, but as a central pillar of the federal AI education strategy.
Institute of Education Sciences (IES)
IES should coordinate closely with the Task Force to support the Executive Order’s goals through a National Analytical Literacy Research Agenda. This agenda could:
- Fund studies that explore how analytical thinking supports AI literacy across grade levels.
- Evaluate the effectiveness of instructional models that integrate analytical reasoning into AI and computer science curricula.
- Develop scalable tools and assessments that measure students’ analytical readiness for AI-related learning pathways.
IES could also serve as a technical advisor to the Task Force, ensuring that its initiatives are grounded in evidence-based practice.
Office of Elementary and Secondary Education (OESE)
In light of the Executive Order’s directive for educator training and curriculum innovation, OESE should:
Prioritize analytical literacy integration in discretionary grant programs that support AI education.
Develop guidance for states on embedding analytical competencies into AI-related standards and instructional frameworks.
Collaborate with the Task Force to ensure that professional development efforts include training on how to teach analytical thinking—not just how to use AI tools.
National Science Foundation (NSF)
The National Science Foundation plays a pivotal role in advancing STEM education through research, innovation, and capacity-building. To support the goals of the Executive Order and strengthen analytical literacy as a foundation for AI readiness, we recommend that NSF:
- Establish a dedicated grant program focused on developing and scaling instructional models that integrate analytical literacy into STEM and AI education. This could include interdisciplinary curricula, project-based learning frameworks, and performance-based assessments that emphasize reasoning, problem-solving, and data interpretation.
- Fund research-practice partnerships that explore how analytical thinking develops across grade levels and how it supports students’ engagement with AI concepts. These partnerships could include school districts, universities, and professional organizations working collaboratively to design and evaluate scalable models.
- Support educator capacity-building initiatives, such as fellowships or professional learning networks, that equip teachers to foster analytical literacy in STEM classrooms. This aligns with NSF’s recent Dear Colleague Letters on expanding K–12 resources for AI education.
- Invest in technology-enhanced learning tools that provide real-time feedback on student reasoning and support formative assessment of analytical skills. These tools could be piloted in diverse school settings to ensure equity and scalability.
By positioning analytical literacy as a research and innovation priority, NSF can help ensure that K–12 students are not only technically proficient but cognitively prepared to engage with emerging technologies in thoughtful, ethical, and creative ways.
Note: Given the evolving organizational landscape within the U.S. Department of Education—including the elimination of offices like Educational Technology—it is critical to identify stable federal anchors. The agencies named above have longstanding mandates tied to research, policy innovation, and K–12 support, making them well-positioned to advance this work.
Recommendation 2. State Education Policymakers
While federal agencies can provide vision and resources, states hold the levers of implementation. Their role is critical in translating policy into classroom practice.
While federal agencies can provide strategic direction and funding, the implementation of analytical literacy must be led by states. Each state has the authority—and responsibility—to shape standards, assessments, and professional development systems that reflect local priorities and student needs. To advance analytical literacy meaningfully, we recommend the following actions:
Elevate Analytical Literacy in Academic Standards
States should conduct curriculum audits to identify where analytical skills are currently embedded—and where gaps exist. This process should inform the revision of academic standards across disciplines, ensuring that analytical literacy is treated as a foundational competency, not an ancillary skill. California’s ELA/ELD Framework, for example, emphasizes inquiry, argumentation, and evidence-based reasoning across subjects—not just in English language arts. Similarly, the History–Social Science Framework promotes critical thinking and source evaluation as core civic skills.
States can build on these models by:
- Developing cross-disciplinary analytical literacy frameworks that guide integration from elementary through high school.
- Embedding analytical competencies into STEM, humanities, and career technical education standards.
- Aligning revisions with the goals of the Executive Order, which calls for foundational skill-building to support digital and AI literacy.
Invest in Professional Development and Instructional Capacity
States should fund and scale professional learning ecosystems that equip educators to teach analytical thinking explicitly. This includes:
- Training on inquiry-based learning, Socratic dialogue, and formative assessment strategies that surface student reasoning.
- Development of microcredential pathways for educators to demonstrate expertise in fostering analytical literacy across content areas.
- Support for instructional coaches and teacher leaders to model analytical practices and mentor peers.
California’s professional learning modules aligned to the Common Core State Standards and ELA/ELD frameworks offer a useful starting point for designing scalable, standards-aligned training.
Redesign Student Assessments to Capture Deeper Thinking
States should move beyond traditional standardized tests and invest in assessment systems that measure analytical reasoning authentically. States can catalyze this innovation by issuing targeted Requests for Proposals (RFPs) that invite districts, assessment developers, and research-practice partnerships to design and pilot new models of assessment aligned to analytical literacy. These RFPs should prioritize:
- Performance tasks that require students to analyze real-world problems and propose solutions.
- Portfolio assessments that document students’ growth in reasoning and problem-solving over time.
- Open-ended questions that ask students to evaluate claims, synthesize evidence, and construct logical arguments.
- Scalable models that can inform statewide systems over time.
By using the RFP process strategically, states can surface promising practices, support local innovation, and build a portfolio of assessment approaches that reflect the complexity of students’ analytical capabilities.
Recommendation 3. Professional Education Organizations
Beyond government, professional education organizations shape the field through resources, advocacy, and collaboration. They are key partners in scaling analytical literacy.
Professional education organizations play a vital role in shaping the landscape of K–12 education. These groups—ranging from subject-specific associations like the National Council of Teachers of English (NCTE) and the National Science Teaching Association (NSTA), to broader coalitions like ASCD and the National Education Association (NEA)—serve as hubs for professional learning, policy advocacy, resource development, and field-wide collaboration. They influence classroom practice, inform state and federal policy, and support educators through research-based guidance and community-building.
Because these organizations operate at the intersection of practice, policy, and research, they are uniquely positioned to champion analytical literacy as a foundational skill across disciplines. To advance this work, we recommend the following actions:
- Develop Flexible, Discipline-Specific Resources. Create adaptable instructional materials—such as lesson plans, assessment templates, and classroom protocols—that help educators integrate analytical thinking into diverse subject areas. For example, NCTE could develop resources that support argument mapping in English classrooms, while NSTA might offer tools for teaching evidence-based reasoning in science labs.
- Advocate for Analytical Literacy as a National Priority. Publish position papers, host public events, and build strategic partnerships that elevate analytical literacy as essential to digital and civic readiness. Organizations can align their advocacy with the federal directive for AI education, emphasizing the role of analytical thinking in preparing students for ethical and informed engagement with emerging technologies.
- Foster Cross-Sector Collaboration. Convene working groups, research-practice partnerships, and educator networks to share best practices and scale effective models. For example, AERA could facilitate studies on how analytical literacy develops across grade levels, while CoSN might explore how digital tools can support real-time feedback on student reasoning.
By leveraging their convening power, subject-matter expertise, and national reach, professional education organizations can accelerate the adoption of analytical literacy and ensure it is embedded meaningfully into the fabric of K–12 education.
Recommendation 4. Teacher Preparation Programs
To sustain long-term change, we must begin with those entering the profession. Teacher preparation programs are the foundation for instructional capacity and must evolve to meet this moment.
Teacher preparation programs (TPPs) are the gateway to the teaching profession. Housed in colleges, universities, and alternative certification pathways, these programs are responsible for equipping future educators with the knowledge, skills, and dispositions needed to support student learning. Their influence is profound: research consistently shows that well-prepared teachers are the most important in-school factor for student success.
Yet many TPPs face persistent challenges. Too often, graduates report feeling underprepared for the realities of diverse, data-rich classrooms. Coursework may emphasize theory over practice, and clinical experiences vary widely in quality. Critically, few programs offer explicit training in how to foster analytical literacy—despite its centrality to digital, data, and AI readiness. In response to national calls for foundational skill-building and educator capacity, TPPs must evolve to meet this moment.
While federal funding for teacher preparation has become more limited, states are stepping in through innovative models like teacher residencies, registered apprenticeships, and microcredentialing pathways. These initiatives are often supported by modified use of Title II funds, state general funds, and workforce development grants. To accelerate this momentum, federal programs like Teacher Quality Partnership (TQP) grants and Supporting Effective Educator Development (SEED) grants could be adapted to prioritize analytical literacy, while states can issue targeted RFPs to redesign coursework, practicum experiences, and capstone projects that center reasoning, problem-solving, and ethical decision-making. To ensure that new teachers are ready to cultivate analytical thinking in their students, we recommend the following actions:
- Integrate Analytical Pedagogy into Coursework and Practicum. Embed instructional strategies that center analytical literacy into pre-service coursework. This includes training in inquiry-based learning, argumentation, and data interpretation. Practicum experiences should reinforce these strategies through guided observation and practice in real classrooms.
- Ensure Faculty Model Analytical Thinking. Faculty must demonstrate analytical reasoning in their own teaching—whether through modeling how to deconstruct complex texts, facilitating structured debates, or using data to inform instructional decisions. This modeling helps pre-service teachers internalize analytical habits of mind.
- Strengthen Field Placements for Analytical Instruction. Partner with districts to place candidates in classrooms where analytical literacy is actively taught. Provide structured mentorship from veteran teachers who use questioning techniques, performance tasks, and formative assessments to surface student reasoning.
- Develop Capstone Projects Focused on Analytical Literacy. Require candidates to complete a culminating project that demonstrates their ability to design, implement, and assess instruction that builds students’ analytical skills. These projects could be aligned with state standards and local district priorities.
- Align Program Outcomes with Emerging Policy Priorities. Ensure that program goals reflect the competencies outlined in federal initiatives like the AI Education Executive Order. This includes preparing teachers to support foundational literacies that enable students to engage critically with digital and AI technologies.
Together, these actions form a coherent strategy for embedding analytical literacy across the K–12 continuum. But success depends on bold leadership and sustained commitment. By reimagining teacher preparation through the lens of analytical literacy, we can ensure that every new educator enters the classroom equipped to foster deep thinking, ethical reasoning, and problem-solving—skills that students need to thrive in a complex and rapidly changing world.
Conclusion
Analytical literacy is not a nice-to-have, it is a prerequisite for the specialized proficiencies students need in today’s complex world. By embedding critical thinking, logical reasoning, and problem-solving across the K–12 continuum, we empower students to meet challenges with curiosity and discernment. We urge policymakers, educators, and institutions to act boldly by demanding analytical literacy be established as a cornerstone of 21st-century education. and co-create a future where every student has the analytical tools essential for meaningful participation, innovative thinking, and long-term success in the digital age and beyond.