
Sustaining Scientific Collections in the Age of AI
Scientific collections play an important but underappreciated role in the American science and technology ecosystem. Their existence has accelerated science by providing repositories for samples, archived information and data. This increases the efficiency of scientific research by mitigating the need to repeat field work while serving as essential information libraries. Collections are particularly important for the study of biological specimens and pathogens, offering significant advantages to human health and food security, but also extend to the physical and geological sciences, reducing the need to develop new observations. The decentralized nature of scientific collections–of which there are more than 10,000 globally and about 2,500 in the United States–increases the value of digital curation technologies and particularly those supported by machine learning and artificial intelligence.
AI companies have identified that one of the most exciting value propositions for their models is the potential acceleration of science by rapidly synthesizing information from disparate sources and gleaning new and undiscovered insights. Accomplishing this mission inherently requires access to public goods and resources, and (in particular) training information that is relevant for scientific discovery. We believe there is a compelling case to be made for AI companies to contribute to the sustainability of that public good, whether it be through direct financial support or through the provision of in-kind tools that improve the management and sustainability of these uniquely important sources of training information.
A scientific collection is typically defined as an organized, curated repository of physical or digital specimens that (a) support scientific research, (b) are maintained according to systematic standards, and (c) enable reuse or reanalysis. Artificial intelligence models seeking to accelerate scientific discovery require stable, curated and maintained sources from which to train and draw information, and are already trained using scientific collections (in addition to other, lower quality data sources). AlphaFold’s Nobel-prize winning efforts, for instance, were supported by information derived from the Protein Data Bank, carefully collected and maintained over decades of scientific experiments.
While operating collections is relatively inexpensive, their position in markets is challenging as the products created by the “goods” in scientific collections tend to be made open and available for the broader scientific community. As a result, collections are often treated by their owners as a non-revenue-generating institutional expense. In order to foster the economic viability of collections while providing accurate outputs that are valuable to the scientific community, collections managers should update their terms of use and require that AI companies play the role of responsible stewards of scientific data and information, consistent with the role other companies play in supporting successful American research infrastructure.
The Cooperative Stewardship Model for research infrastructure, which has served as a reliable template for balancing openness and utilization with commercial interests, offers a possible pathway for collections’ sustainment. Federal agencies should seek to promote high-quality processed information and primary sources wherever possible, including through grantmaking, contracts, and procurement. Given that the primary method by which the general public, and particularly students, engage with scientific information is already mediated by AI (through search engines or otherwise), the trustworthiness of AI platforms and responsible stewardship of collections as a primary data source is paramount.
Challenge and Opportunity
Viability of Collections
Scientific collections are one of the most critical elements of the research ecosystem, supporting everything from food security, like the National Seed Storage Laboratory in Fort Collins, to the Smithsonian’s mosquito collections which enable research on zoonotic pathogens. To adopt the language of the tech world, these are “full stack” research endeavors requiring specialized knowledge, capabilities, and environments to do successfully. Yet despite their relatively low costs, in recent years major scientific collections, like the herbarium at Duke University, have faced significant maintenance and upkeep challenges due to a lack of revenue sources. The challenges and viability of specific collections can vary dramatically due to the fact that collections represent a form of extremely decentralized infrastructure for financial, cultural, and legal reasons. For instance, the operation of the Smithsonian National Museum of Natural History’s collections may be substantially different than privately-owned collections of insects or those representing artifacts, samples, or libraries stewarded by Indigenous Peoples.
Recent federal policy actions, particularly with respect to the introduction of new constraints on indirect costs, threatens to further undermine the business model of collections and force the loss or closure of vital sources of scientific data and information. Collections, which are relatively inexpensive to maintain relative to other scientific infrastructure, still require a significant number of programmatic activities to curate, maintain, and support at a scale similar to other research activities. An example of the types of costs, which can vary widely based on the size of the collection and what is included, associated with collections activities are provided, below:
The cooperative stewardship model for research and development infrastructure has provided the backbone for federal scientific collections for many decades. While most infrastructure is free to use and accessed for scientific purposes, for-profit enterprises are generally charged for access to infrastructure in order to sustain, maintain, and provide new capabilities relevant for industry. Examples include the National Institute of Standards and Technology’s repository of standard reference materials, widely used by industry, which includes everything from $1200 peanut butter reference material to standard cigarettes for ignition resistance testing. Major U.S. scientific facilities generally operate on the basis of full cost recovery for services used by commercial providers as opposed to relying on those providers as a primary source of revenue generation. For collections, this would help reduce pressure or concerns stemming from political pressure on indirect costs from grants.
The AI companies and their leaders have identified science as one of their most exciting areas for development, and suggested new licensing and revenue models for measurable AI outputs. For sure, models have the potential to serve as tools for scientific discovery by providing quick access to massive volumes of information largely derived from both scientific literature and data sources and allowing scientists to rapidly extract novel insights from that information. It is reasonable to imagine a scenario where the primary interaction that scientists have with collections in the future is mediated by training data fed into AI foundation models.
AI models must accurately reflect information from scientific collections
AI model firms, which rely on quality sources of training data, ideally should have an express interest in seeing reliable scientific information sources maintained and managed in a way that improves the performance of models due to the availability of quality data. Good information sources, like collections, must be available and maintained if companies are going to successfully implement the vision of AI for science expressed by their marketing and executives. It requires taking information derived from the physical world, digitizing it in a way that is comprehensible to a computer, and then feeding that data and relevant processed information into an AI model where it may be used to help with the process of scientific discovery.
Some of these data sources are quite large and processing-intensive. For instance, the world’s largest radio wave telescope, the Square Kilometer Array based out of South Africa, is expected to generate approximately 700 petabytes of astronomical data every year–about seven times more than that which is generated by Google Search in the same time period. Models seeking to leverage these data sources for discovery will likely place additional and significant burdens on scientific data infrastructure.
Current AI models are not always the most reliable sources of scientific information, in part due to frequent “hallucinations.” These models do not always preserve scientific information with fidelity, even if trained on high-quality data. For instance, when asked to produce an image of an anatomically correct blue whale skeleton, OpenAI’s ChatGPT model will output images of a strangely toothed (as opposed to baleen) whale skeleton that incorrectly represents the whale’s tail as a single, large bony structure, among other errors. Search engines have similar issues, with regular Google searches in late 2025 producing a humpback whale image when searching for “blue whale,” citing a popular science website as opposed to a scientific collection or other reliable source.

Image generated by ChatGPT using the prompt “Can you draw me an anatomically correct image of a blue whale skeleton?” on April 2, 2026. Note the teeth-like structures on a baleen whale, the bizarre pectoral fin bones, and the hallucination of a bone representing the tail, among other errors. Also note the lack of a clear watermark identifying the image as AI-generated.
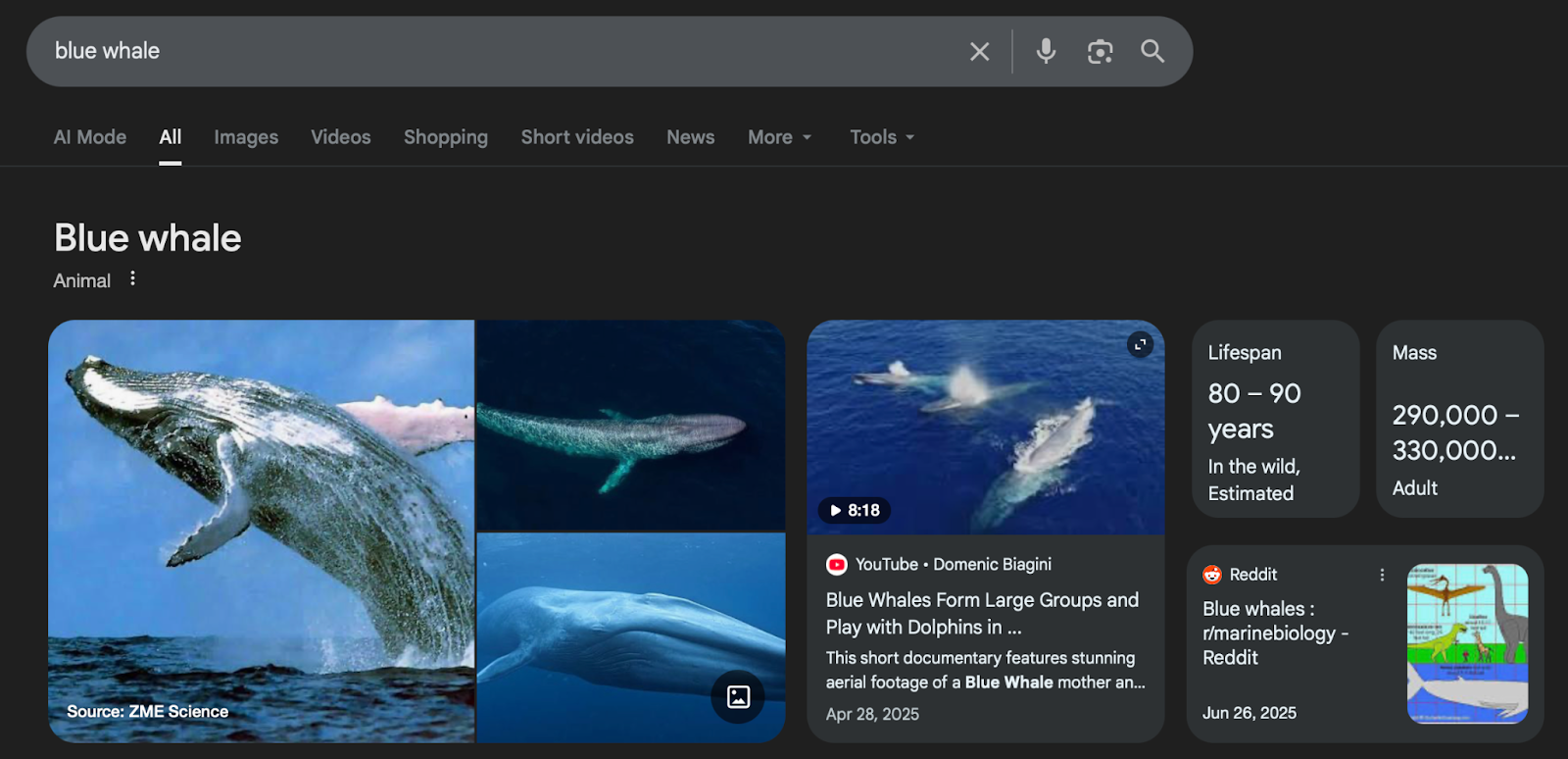
Google search result for “blue whale,” November 12, 2025. Note that the first image, drawn from ZME Science, is actually a photograph of a humpback whale.
The challenge of producing high quality scientific outputs does not (and should not) rest entirely at the feet of model developers. While these data sources provide us with the most complete library of field samples, they are far from perfect, oftentimes tagged with partial, non-standard, and more infrequently incorrect information (for instance, samples collected before 1990 generally are not tagged with latitude and longitude). This makes it more difficult to judge the quality of the inputs, requires human curation, and occasionally additional field work to improve the quality of the collection. This actually presents an opportunity for AI models in science, which could (with appropriate validation) help identify and correct missing, incomplete, or inaccurate information.
There is a general need for improved transparency with respect to training data and the information standards models use to evaluate the quality of data.
Scientific collections are uniquely valuable to foundation models given the high quality of the data and information sources, as distinct from information sourced from the broader internet. Unfortunately, it is difficult to assess whether companies that develop generalized models, like OpenAI or Anthropic, privilege scientific data sources over general information collected from the internet, which may include creative renderings, fantastical artist depictions, and outright falsehoods. Assessing this challenge is not straightforward. Companies frequently do not disclose training information or details about how their models process data and information–if they are even able to explain a model’s output.
Recommendations
Recommendation 1. Scientific collections should update their terms of use to require that data used to train for-profit models be licensed, consistent with existing principles for research and development infrastructure.
Scientific collections, many of which are already struggling, are now faced with an existential threat as a result of the government’s budget cuts and federal policy actions (particularly those related to indirect costs). Modifications to collections’ business models are already inevitable, especially as industry and philanthropy are rapidly reprioritizing their current investments. Rather than attempting to create a new relationship between these companies and institutions that provide this valuable infrastructure, it makes sense to rely on proven public-private partnership infrastructure governance models identified in the National Academies’ cooperative stewardship report, rather than building a new social contract that might threaten the general accessibility (for both AI companies and the broader scientific community) of this critical source of information.
Collections offer a unique and necessary service if artificial intelligence is to realize its full potential for scientific discovery. Rather than attempting to develop or adopt new and more unfamiliar business models, collections should adopt the same cooperative stewardship principles that work for the remainder of the science and technology ecosystem. There is inherent value in making sure that collections serve as the primary basis for information used to train AI models for scientific discovery, as opposed to other sources of information that might be pulled from less reputable sources in the broader internet (including scientific studies that resist replication).
Companies that wish to use the products of research for proprietary and commercial purposes are similarly charged for access to infrastructure. Organizations seeking to produce non-proprietary models for scientific purposes, similarly, should be given the same access advantages conferred to other parts of the scientific community to ensure dissemination and broad utilization.
It is reasonable to assume that AI companies could respond to fee-for-access by simply not accessing data or information from collections. Efforts to derive information from papers or other sources are likely to be incomplete and less useful for the creation of high-quality models useful to science. It is reasonable to ask–as is the case for every other industry that utilizes R&D infrastructure–for companies that stand to profit from the products of collections to pay for their sustainment.
Alternatives, including the provision of in-kind tools or resources to assist with the curation and management of scientific collections (and thereby increasing the efficiency of collections and improving the quality of the services they provide the broader community), may also be explored.
Recommendation 2. Science agencies should prioritize development of specialized tools to curate information and data housed in scientific collections and assist in the development of data and information standards. These tools should continue to rely on cooperative stewardship principles (i.e.,allowing open access for non-commercial use while maintaining fee-based access for profit-seeking entities).
Given that today’s generalized LLMs, image generators, and search engines cannot be counted on to reliably output accurate scientific information, science agencies should continue to invest in specialized models that are designed and developed to address critical mission needs. This would likely require investment in models that are designed to curate, compare, and manage samples which are frequently tagged with non-standardized or lower-quality information.
Recommendation 3. The government should show preference when procuring solutions for science and technology purposes for AI models that are trained on data and information in scientific collections. This should include investment in R&D to help develop models that appropriately privilege high-quality training information.
Government procurement can provide an important tool for increasing the quality of services through the procurement process. As government agencies invest in artificial intelligence for policy purposes, including for the development of technical tools that affect people’s rights and safety, the need for models to output quality information increases substantially.
Government agencies can, through the contracting process, request that providers be held to certain standards and, whenever possible, provide appropriately-licensed images drawn from primary sources. Such requirements could also substantially reduce the compute requirements produced by models, which could simply offer a reference image, video, or other information source as opposed to generating (and possibly hallucinating) a lower-quality output produced by the model itself.
Conclusion
The 2020 Economic Analyses of Federal Scientific Collections produced by the Smithsonian and National Science and Technology Council notes the conception of collections by some authors as a “global public good” underpinning much of the science and technology enterprise. As scientists’ and the publics’ interactions with collections and the knowledge contained within them becomes primarily mediated by AI platforms, and as AI platforms seek to profit from content created from their use, the role of those platforms as stewards of these resources should correspondingly increase. Collections are ideal “senses” through which AI platforms can collect high quality information about the world, enabling the most exciting implementations of AI to be realized. Supporting the infrastructure that enables that realization is crucial for the success of the technology.
Thank you to Dr. Oliver Stephenson for his contributions to the text.
Good information sources, like collections, must be available and maintained if companies are going to successfully implement the vision of AI for science expressed by their marketing and executives.
Nestled in the cuts and investments of interest to the S&T community is a more complex story of how the administration is approaching the practice of science diplomacy.
By structuring licensing-and-talent deals that replicate mergers while avoiding antitrust scrutiny, dominant technology firms are reshaping AI labor markets, venture financing, and the future of U.S. innovation.
It is in the interests of the United States to appropriately protect information that needs to be protected while maintaining our participation in new discoveries to maintain our competitive advantage.